CUDA11以降でしか使えないなんて聞いてないよ
うきうきで新しいgpuを買ったものの、手元のコードが動かない・・・そんな経験をした方、他にもいるのではないでしょうか。
そう、RTX30シリーズなどのampere architectureは、CUDA11以降でないとまともに動かないのです。
私はpytorch0.4.1のFaster-RCNN実装をベースとしたコードを使用しているのですが、さすがに0.4.1は古すぎてCUDA9くらいまでのバイナリしかなく、一旦諦めておりました。(turingのgpuも所持していたのでそっちでしのいでいた)
ただ、せっかく買ったgpuをいつまでも遊ばせておくのもアレだし、コード書き直すのも面倒なんで、一念発起してソースのビルドにチャレンジしました。なんとか動かすことができたので備忘録も兼ね記しておきます。
とりあえず使えればいいよという人へ
こちらに出来上がったソースを上げております。
Pytorch0.4.1-cuda11.0
ただし、サブモジュールにも少し修正箇所があるため。ダウンロード後に少しご自分で作業いただく必要があります。
以下実行後、下記手順の⑧以降に従っていただければと思います。
git clone https://github.com/monotaro3/pytorch0.4.1-cuda11.0.git
cd pytorch0.4.1-cuda11.0
git submodule update --init --recursive
注意点として、ビルドを通すために後述のとおり一部関数を無効にしているため、一部機能(スパース関係)が使えない可能性があります。ご了承ください。
動作確認環境
- ubuntu20.04(WSL2,docker,Win11)
- cuda11.0
- RTX A4000
RTX A4000はCompute Capability8.6であり、CUDA的には11.1以降の対応になるらしいのですが、手元環境(11.0)を変えるのが面倒でそのまま作業しました。そのため、CUDA11.1以降だとカバーしきれていないエラーが出る可能性があります。
手順
主にはCUDAの仕様変更に対応するための修正等になります。
①ソースのダウンロード
まずはソースを用意します。サブモジュールのnervanagpuというのが不要らしく、削除します。
git clone --branch v0.4.1 https://github.com/pytorch/pytorch.git pytorch-0.4.1
cd pytorch-0.4.1
git rm --cached third_party/nervanagpu
ルートにある、.gitmoduleの19-21行(下記)を削除します。
[submodule "third_party/nervanagpu"]
path = third_party/nervanagpu
url = https://github.com/NervanaSystems/nervanagpu.git
以下実行し、サブモジュールを読み込みます。
git submodule update --init --recursive
②CUDA_cublas_device_LIBRARY の削除
ビルド時にCUDA_cublas_device_LIBRARYというのをリンクしようとするのですが、deprecatedになっているためエラーになります。
これはcmake/Modules_CUDA_fix/upstream/FindCUDA.cmake 中で指定されているため、該当箇所からCUDA_cublas_device_LIBRARYのみ削除します。(下記1793行目の他計3か所。unsetやsetの行はそのままでいいです)
if (do_obj_build_rule)
add_custom_command(
OUTPUT ${output_file}
DEPENDS ${object_files}
# COMMAND ${CUDA_NVCC_EXECUTABLE} ${nvcc_flags} -dlink ${object_files} ${CUDA_cublas_device_LIBRARY} -o ${output_file}
COMMAND ${CUDA_NVCC_EXECUTABLE} ${nvcc_flags} -dlink ${object_files} -o ${output_file}
...
③struct cudaPointerAttributesのメンバー名変更
memoryTypeというメンバの名前がtypeとなっており、下記(39行目)がエラーとなるため、修正します。
#ifndef THD_GENERIC_FILE
static PyObject * THPStorage_(isPinned)(THPStorage *self)
{
HANDLE_TH_ERRORS
#if defined(USE_CUDA)
cudaPointerAttributes attr;
cudaError_t err = cudaPointerGetAttributes(&attr, THWStorage_(data)(LIBRARY_STATE self->cdata));
if (err != cudaSuccess) {
cudaGetLastError();
Py_RETURN_FALSE;
}
// return PyBool_FromLong(attr.memoryType == cudaMemoryTypeHost);
return PyBool_FromLong(attr.type == cudaMemoryTypeHost);
...
サブモジュールにも同様の箇所があるのですが、下でまとめて記載します。
④THCAtomics.cuhの修正
おそらくCUDAの仕様変更によるものだと思うのですが、下記のようなエラーが出ます。
/home/files/pytorch-0.4.1/aten/src/THC/THCAtomics.cuh(100): error: cannot overload functions distinguished by return type alone
/home/files/pytorch-0.4.1/aten/src/THC/THCAtomics.cuh(123): error: return value type does not match the function type
見た感じ半精度に関する機能なので、単に削除しても多くの人は問題ないと思いますが、下記のとおりv1.0.0のコードに置換すると無事ビルドできます。(動作未確認)
//v1.0.0のコード
static inline __device__ void atomicAdd(at::Half *address, at::Half val) {
#if ((CUDA_VERSION < 10000) || (defined(__CUDA_ARCH__) && (__CUDA_ARCH__ < 700)))
unsigned int * address_as_ui =
(unsigned int *) ((char *)address - ((size_t)address & 2));
unsigned int old = *address_as_ui;
unsigned int assumed;
do {
assumed = old;
at::Half hsum;
hsum.x = (size_t)address & 2 ? (old >> 16) : (old & 0xffff);
hsum = THCNumerics<at::Half>::add(hsum, val);
old = (size_t)address & 2 ? (old & 0xffff) | (hsum.x << 16) : (old & 0xffff0000) | hsum.x;
old = atomicCAS(address_as_ui, assumed, old);
} while (assumed != old);
#else
atomicAdd(reinterpret_cast<__half*>(address), val);
#endif
}
⑤スパース関数仕様変更への対処
cusparseScsrmm、cusparseDcsrmmなどといった関数がdeprecatedになっている関係で、以下のようなエラーが出ます。
/home/files/pytorch-0.4.1/aten/src/THCUNN/generic/SparseLinear.cu(96): error: identifier "cusparseScsrmm" is undefined
/home/files/pytorch-0.4.1/aten/src/THCUNN/generic/SparseLinear.cu(195): error: identifier "cusparseScsrmm" is undefined
/home/files/pytorch-0.4.1/aten/src/THCUNN/generic/SparseLinear.cu(98): error: identifier "cusparseDcsrmm" is undefined
/home/files/pytorch-0.4.1/aten/src/THCUNN/generic/SparseLinear.cu(197): error: identifier "cusparseDcsrmm" is undefined
/home/files/pytorch-0.4.1/aten/src/ATen/native/sparse/cuda/SparseCUDABlas.cu(58): error: more than one instance of function "at::native::sparse::cuda::cusparseGetErrorString" matches the argument list:
function "cusparseGetErrorString(cusparseStatus_t)"
function "at::native::sparse::cuda::cusparseGetErrorString(cusparseStatus_t)"
argument types are: (cusparseStatus_t)
/home/files/pytorch-0.4.1/aten/src/ATen/native/sparse/cuda/SparseCUDABlas.cu(128): error: identifier "cusparseScsrmm2" is undefined
/home/files/pytorch-0.4.1/aten/src/ATen/native/sparse/cuda/SparseCUDABlas.cu(152): error: identifier "cusparseDcsrmm2" is undefined
後継の関数はあるようなのですが、大分仕様が変わっており修正が難しそうだったため、当該関数を使用している部分を無効化しています。よって、おそらくスパース関係のモジュールは使えなくなっていると思います。(私の手元のコードはスパース関係のモジュールを使用していないので、問題なく動きます。)
//95行目
// #ifdef THC_REAL_IS_FLOAT
// cusparseScsrmm(cusparse_handle,
// #elif defined(THC_REAL_IS_DOUBLE)
// cusparseDcsrmm(cusparse_handle,
// #endif
// CUSPARSE_OPERATION_NON_TRANSPOSE,
// batchnum, outDim, inDim, nnz,
// &one,
// descr,
// THCTensor_(data)(state, values),
// THCudaIntTensor_data(state, csrPtrs),
// THCudaIntTensor_data(state, colInds),
// THCTensor_(data)(state, weight), inDim,
// &one, THCTensor_(data)(state, buffer), batchnum
// );
//195行目
// #ifdef THC_REAL_IS_FLOAT
// cusparseScsrmm(cusparse_handle,
// #elif defined(THC_REAL_IS_DOUBLE)
// cusparseDcsrmm(cusparse_handle,
// #endif
// CUSPARSE_OPERATION_NON_TRANSPOSE,
// inDim, outDim, batchnum, nnz,
// &one,
// descr,
// THCTensor_(data)(state, values),
// THCudaIntTensor_data(state, colPtrs),
// THCudaIntTensor_data(state, rowInds),
// THCTensor_(data)(state, buf), batchnum,
// &one, THCTensor_(data)(state, gradWeight), inDim
// );
//128行目
// CUSPARSE_CHECK(cusparseScsrmm2(handle, opa, opb, i_m, i_n, i_k, i_nnz, &alpha, desc, csrvala, csrrowptra, csrcolinda, b, i_ldb, &beta, c, i_ldc));
//152行目
// CUSPARSE_CHECK(cusparseDcsrmm2(handle, opa, opb, i_m, i_n, i_k, i_nnz, &alpha, desc, csrvala, csrrowptra, csrcolinda, b, i_ldb, &beta, c, i_ldc));
⑥PyYAMLに関する修正
PyYAMLのバージョン6以上を使用している場合は、load()の引数Loaderが必須となったことでエラーが出るので、下記のとおり修正します。
#91行目
declaration = yaml.load('\n'.join(declaration_lines),Loader=yaml.Loader)
#18行目
declaration = yaml.load('\n'.join(declaration_lines),Loader=yaml.Loader)
⑦開発用ライブラリのインストール
これは環境によるかもしれませんが、私の場合ビルド中にCUDA関係のインクルードファイル(****.h)が見つからないと頻繁に怒られ、以下をインストールする必要がありました。必要に応じてインストールしてください。
- cuda-nvrtc-dev
- libcublas-dev
- libcufft-dev
- libcurand-dev
- libcusparse-dev
こちらから、ご自身のディストリビューションとCUDAのバージョンに近いものを検索いただければと思います。
⑧サードパーティーモジュールの修正
サードパーティモジュールのコードを一部修正する必要があります。
Compute capablityの指定
thirdparty/gloo/cmake/cuda.cmakeの冒頭に、gpuのアーキテクチャがハードコーディングされており、古いアーキテクチャのみになっている(特に3.0は非対応になっておりエラーが出る)ため、自分が使用する範囲に修正します。
# Known NVIDIA GPU achitectures Gloo can be compiled for.
# This list will be used for CUDA_ARCH_NAME = All option
# set(gloo_known_gpu_archs "30 35 50 52 60 61 70")
# set(gloo_known_gpu_archs7 "30 35 50 52")
# set(gloo_known_gpu_archs8 "30 35 50 52 60 61")
set(gloo_known_gpu_archs "75 80")
set(gloo_known_gpu_archs7 "75 80")
set(gloo_known_gpu_archs8 "75 80")
こうなど。
struct cudaPointerAttributesのメンバー名変更
③と同様ですが、下記がエラーとなるため、memType→typeに修正します。
template<typename T>
class BuilderHelpers {
public:
// Checks if all the pointers are GPU pointers.
static bool checkAllPointersGPU(std::vector<T*> inputs){
return std::all_of(inputs.begin(), inputs.end(), [](const T* ptr) {
cudaPointerAttributes attr;
auto rv = cudaPointerGetAttributes(&attr, ptr);
// return rv == cudaSuccess && attr.memoryType == cudaMemoryTypeDevice;
return rv == cudaSuccess && attr.type == cudaMemoryTypeDevice;
...
⑨環境変数によるCompute capablityの指定
環境変数TORCH_CUDA_ARCH_LISTを指定することにより、コンパイラにどのアーキテクチャ向けにコンパイルすべきか教えてやります。
export TORCH_CUDA_ARCH_LIST="7.5;8.0+PTX"
自分が使用するgpuに合わせて指定してください。CUDA11.1以降を使用する場合は8.6を足してもいいです。(11.0だと「そんなアーキテクチャは知らない」と怒られます)
PTXは最後だけにつければいいみたいです。
あまり古いアーキテクチャは後方互換性が切られているようでエラーになります。(3.0など)
⑩ビルド&インストール
以下実行します。
python setup.py install
スクショ
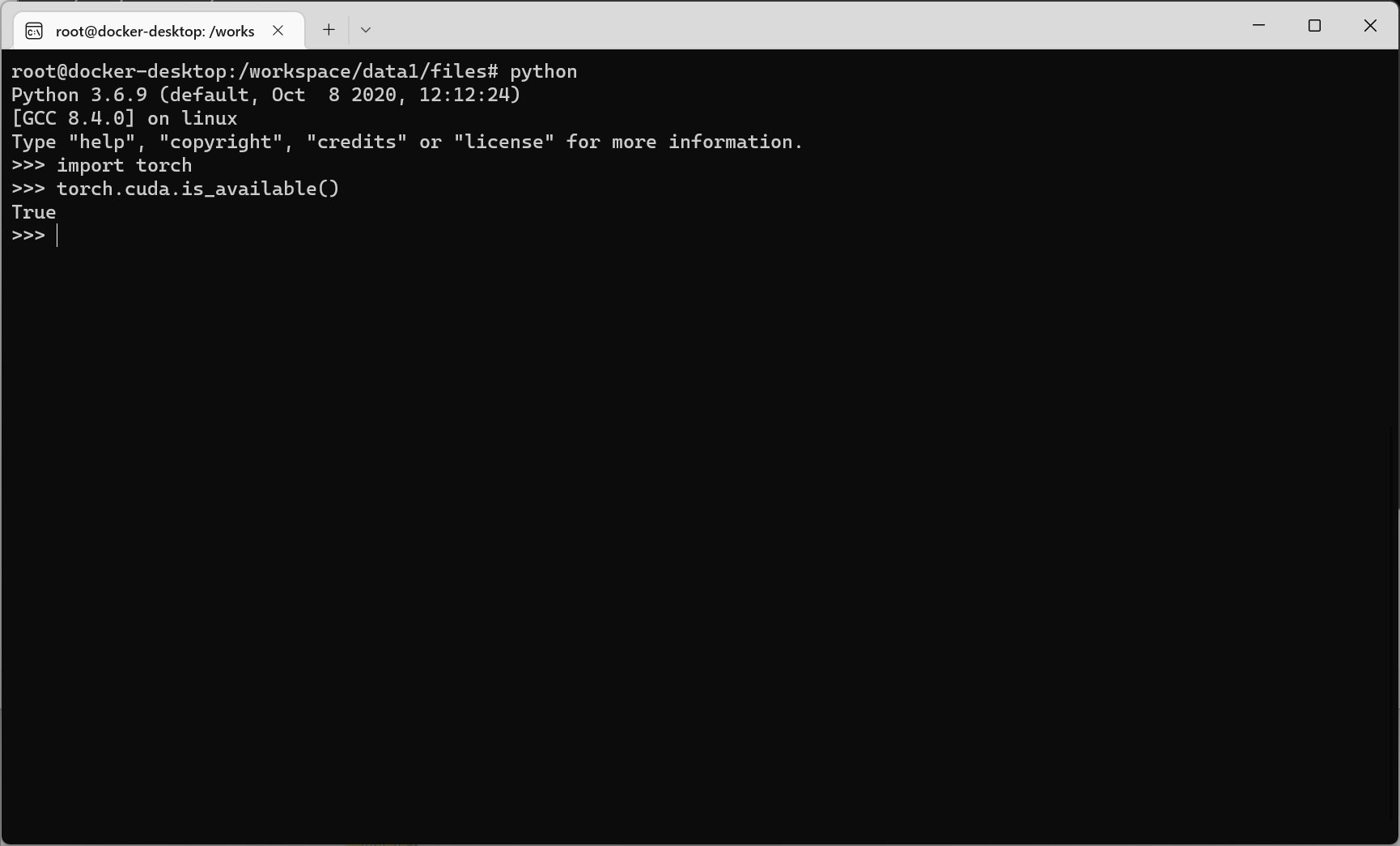
こんな感じです。
参考
- https://github.com/pytorch/pytorch/issues/19457
- https://github.com/NVIDIA/NvPipe/issues/29
- https://stackoverflow.com/questions/64774548/unsupported-gpu-architecture-compute-30-on-a-cuda-5-capable-gpu
- https://mojel.blog.fc2.com/blog-entry-7.html
- https://qiita.com/harmegiddo/items/c1b781c82ab9c1c811bd