やること
前回の記事本日出版される本をまとめて表示するサイトをラズパイサーバーで公開するで取得し集積している書籍情報のタイトル・サブタイトルと内容紹介情報をRのRMeCabとwordcloudを利用してテキストマイニングし可視化してみる。
準備
phpmyadminから4月30日以降集めている書籍データ約920件をCSVファイルにしてエクスポートする。
エクスポートしたファイルの必要じゃない列は削除し、タイトル情報と、内容紹介情報のみ残す。
RMeCabをインストールする。(こちらを参考:http://taku910.github.io/mecab/)
こちら(さくっとはじめるテキストマイニング(R言語)スタートアップ編)を参考にプログラムを作って実行してみる。
library(RMeCab)
library(wordcloud)
word<- RMeCabFreq("ファイル名")
word <- subset(word, Info1 == "名詞")
type <- c("数","数詞","非自立","接尾")
word <- subset(word, !Info2 %in% type)
word <- word[order(word$Freq, decreasing=T), ]
word <- head(word, n=100)
patern <- brewer.pal(8, "Dark2")
wordcloud(word$Term, word$Freq, min.freq = 1, colors=patern)
結果

??これあってるのかな??
NULLやbrが入っているのは、除去してないし仕方ないとして、代表表記って何だよ…
マニュアル曰く、
「代表表記
同じ語の表記バリエーションであることを扱うために,代表表記を設定し,これを意味情報に含
めた.これによって,日本語処理の表記揺れの問題を,形態素解析を行うだけである程度取り除く
ことが可能となる.
また,平仮名書き等による曖昧性も,適切な範囲で複数の可能性(代表表記)を挙げるようにし
ており,以後の構文解析・意味解析などへの適切な入力を提供することができる.詳細は付録 B.1
を参照」
「B.1 代表表記
この枠組みの中では,次のような現象を扱っている.
漢字と平仮名,送り仮名
漢字とするか平仮名とするか,また,送り仮名のバリエーション.その組み合わせ.
例)拳銃 けん銃 拳じゅう けんじゅう
表す 表わす あらわす
落とす 落す おとす
漢字別表記
例)狩人/猟人 朝日/旭
色取る/彩る 哀れむ/憐れむ
綺麗だ/奇麗だ 気掛りだ/気懸かりだ
動詞でどこまでまとめるかは微妙な問題であり,一般の国語辞典などでは意味の一致の観点から
はまとめすぎである.例えば「下りる/降りる」「下ろす/降ろす」はまとめないこととした.
カタカナ表記のバリエーション
ソフトウェアとソフトウエアのようなカタカナ表記のバリエーションに対しても代表表記を設け
た.これは,カタカナ語のコーパス中の出現頻度をもとに,表記バリエーションの自動認識と複合
語の自動分割を行い,その結果を人手でチェックして整理した.
日本語固有語のカタカナ表記
動物,植物,食べ物などで,日本語固有語であってもカタカナ表記されるものについて,代表表
記のもとに整理した.
例)大根 だいこん ダイコン
餃子 ぎょうざ ギョウザ ギョーザ (最後はカタカナ表記バリエーション)
上記のカテゴリに関わらず,カタカナ表記があるものをまとめた
例)溝 ミゾ みぞ
眼鏡 メガネ めがね
奴 ヤツ やつ
代表表記は,原則として,新聞記事での高頻度表記としたが,この選択には強いこだわりはない
(妥当性を主張するものではない).重要なことは,同じ語の表記集合がまとめられ,これを通し
てテキストマッチングなどが適切に行われることであり,代表表記はこの集合の ID の役割を果た
すものである.しかし,ID を数字などにすることは人間にとって管理しやすいものではないので
高頻度の表記を採用した.」
日本語形態素解析システムJUMAN++ version 1.01京都大学大学院情報学研究科黒橋・河原研究室
よくわからないけど、あってる…?あってない?
ちょっとよくわからないので、もっと書籍データが集まったらまたやってみます。
8/18 追記
標本数がかなり多くなってきたので、再びテキストマイニングしてみました
4月30日以降から集めている書籍データ15326件の標本から「第*章」,「*章」やNULL,
などのノイズを除去してから実行
頻度の上位100件

頻度の上位200件

頻度分布のグラフも作成してみた
library(ggplot2)
glove <- RMeCabFreq("ファイル名")
word <- subset(word, Info1 == "名詞")
type <- c("数","数詞","非自立","接尾")
word <- subset(word, !Info2 %in% type)
word <- word[order(word$Freq, decreasing=T), ]
word <- head(word, n=30)
word %>%
filter(Freq >=30) %>%
mutate(Term=reorder(Term, Freq)) %>%
ggplot(aes(Term,Freq)) +
geom_col() +
theme_gray (base_family = "IPAMincho") +
coord_flip()
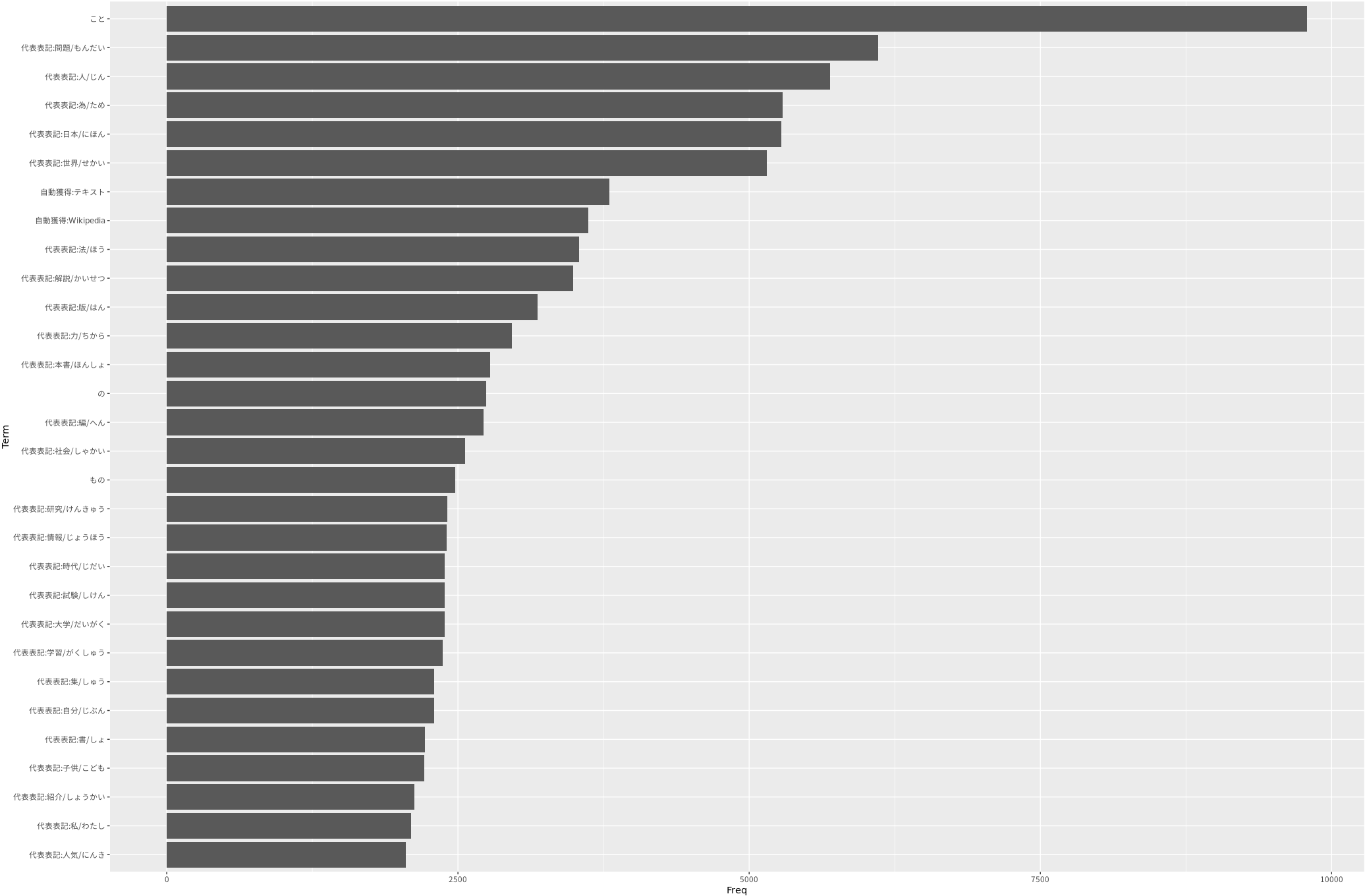
「こと」が突出して多いので、あまり良い結果ではなさそう…
途中の部分で無理やり最頻値の「こと」を削除
word <- word[order(word$Freq, decreasing=T), ]
word <- word[-1,]
word <- head(word, n=30)

