これまでの経緯
芸能人の画像がブラウザに表示されるまで
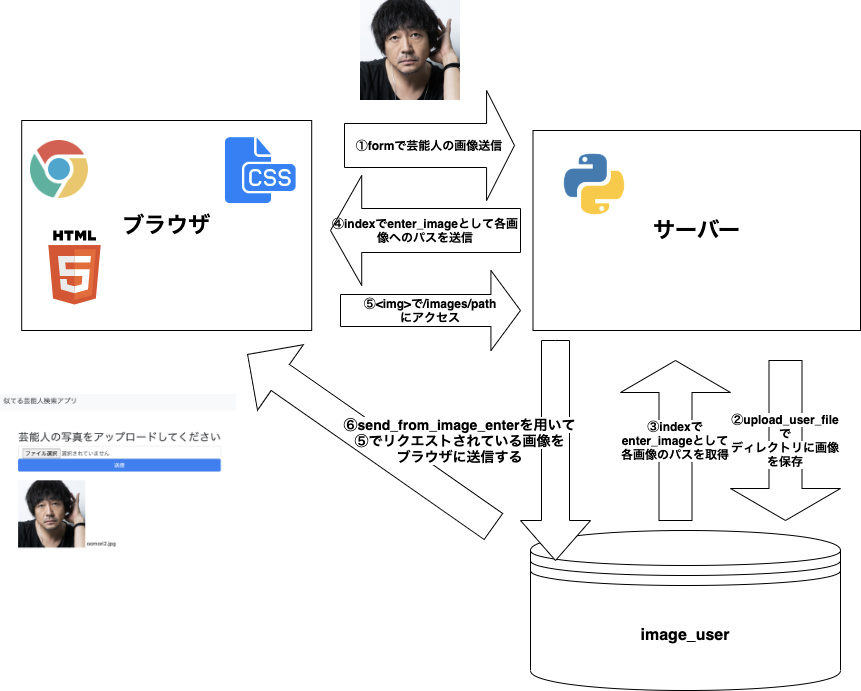
- サーバー側のAPIは以下のようになっています。
import os
from flask import (
Flask,
request,
redirect,
render_template,
send_from_directory)
app = Flask(__name__)
UPLOAD_FOLDER_ENTER = './image_enter'
UPLOAD_FOLDER_USER_FACE = './image_user'
@app.route('/')
def index():
return render_template(
'index.html',
enter_images=os.listdir(UPLOAD_FOLDER_ENTER)[::-1],
user_images=os.listdir(UPLOAD_FOLDER_USER_FACE)[::-1]
)
@app.route('/images/<path:path>')
def send_from_image_enter(path):
return send_from_directory(UPLOAD_FOLDER_ENTER, path)
@app.route('/upload', methods=['GET', 'POST'])
def uploads_file():
# リクエストがポストかどうかの判別
if request.method == 'POST':
# ファイルがなかった場合の処理
if 'upload_files' not in request.files:
print("ファイルなし")
return redirect(request.url)
#画像へのパスを格納するリストを用意
image_paths = []
#ブラウザから送られてきた
uploads_files = request.files.getlist('upload_files')
for uploads_file in uploads_files:
img_path = os.path.join(UPLOAD_FOLDER_ENTER, uploads_file.filename)
uploads_file.save(img_path)
return redirect('/')
if __name__ == "__main__":
app.run(host='0.0.0.0', port=5000)
自分の顔画像を送信する
前回は芸能人の写真を複数受け取り、ブラウザ上で表示することに成功しました。
今回は自分の画像をブラウザから送信してディレクトリに保存することを考えます。
基本的な手順は前回と同じです。
ブラウザから自分の写真を送る
ブラウザ側
- 芸能人の画像と同様にブラウザから自分の写真を送って
image_userディレクトリに保存できるようにしましょう。 - まずブラウザ側からユーザーの写真を受け取れるようにします。
index.htmlにのclass="enter_btn"の下に以下を書き加えてください。
<div class="user_btn">
<h2>Step2</h2>
<h3>あなたの写真をアップロードしてください</h3>
<form action = "/upload_user" method="post" enctype="multipart/form-data">
<!-- <p><input type="file" id = "upload_uesr_file" name = "upload_uesr_file" multiple="multiple">
<input type="submit" class="form-control btn btn-primary"> -->
<div class="custom-file">
<input type="file" id = "upload_uesr_file" name = "upload_uesr_file" multiple="multiple" class="custom-file-input" required>
<label class="custom-file-label" for="validatedCustomFile">Choose your face image...</label>
<div class="invalid-feedback">Example invalid custom file feedback</div>
</div>
<input type="submit" class="form-control btn btn-primary">
</form>
</div>
- 基本的な内容は芸能人の画像を送る時と変わりません。ファイルを送信するので
formタグを使って画像を送信します。 - 送信する画像は
upload_user_fileという名前でサーバー側に渡されることになります。
サーバー側
- ブラウザ側で受け取った画像を
image_userディレクトリに保存する処理を/upload_userに書いていきます。
@app.route('/upload_user', methods=['GET', 'POST'])
def upload_user_files():
if request.method == 'POST':
upload_file = request.files['upload_uesr_file']
img_path = os.path.join(UPLOAD_FOLDER_USER_FACE,upload_file.filename)
upload_file.save(img_path)
return redirect('/')
芸能人の場合とほぼ同じ処理なので理解できると思います。
ブラウザから受け取った画像ファイルはrequest.filesオブジェクトのupload_uesr_fileというキーでアクセスできることが確認できると思います。
これでブラウザから芸能人の画像、ユーザーの画像を受け取れるようになりました。
次章からは受け取った画像をAIに渡して実際に似てる顔の芸能人を探す処理を書いていきたいと思います。
画像が似ているとは?
ここからは実際にAIに芸能人の画像とユーザーの画像を渡して一番似ている芸能人の画像を探す処理を書いていきたいのですが、その前にそもそもAIはどうやって画像と画像が「似ている」ことを判断するのでしょうか?
というか、そもそも「似ている」というぼんやりとした指標をどうやって数字に落とし込むのでしょうか.
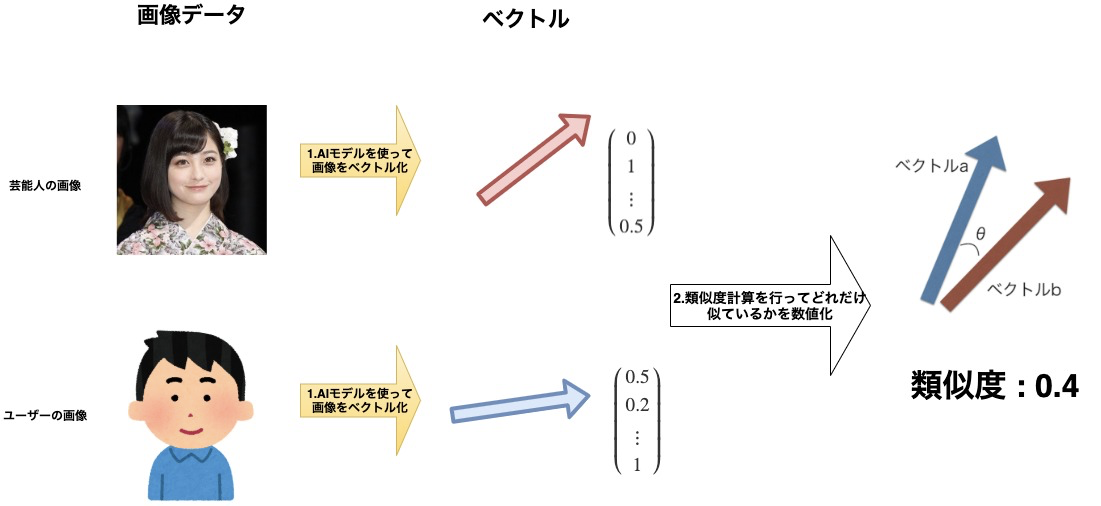
実際に受け取った画像をAIが処理をして自分と一番似ている画像を見つけ出すためには以下の二つのステップを踏む必要があります。
1.ブラウザから受け取った画像をAIモデルを用いてベクトルに変換する。
2.変換した芸能人とユーザーの画像ベクトルの類似度を計算する。

画像のベクトル化
まずは最初のステップ、AIモデルに画像を入力して画像をベクトルに変換することを考えていきます。
今回画像をベクトルに変換するAIモデルにはPart1で学習したVGG16モデルを用います。

上記のVGG16モデルは画像の分類問題のためのモデルでしたが、今回は出力は 顔画像を固定長の(ベクトルの次元数が一定の)ベクトルに変換することが目的なのでVGGfaceという顔認識に特化して学習されたモデルをあらかじめ用意して使うことにします。
実際にサーバー側でVGGfaceモデルが使用できるようにするためにapp.pyにvggfaceや画像の処理に必要なモジュールをインポートしておきましょう。
# 顔認識用のvggモデル
from keras_vggface import vggface
# 画像の前処理に用いるモジュール
from keras.preprocessing import image
from keras import backend as K
これでAIモデルを使う準備が整いました。
画像の前処理
AIモデルでは、AIモデルに画像を入力する前に画像データをAIモデルが受け取れる形式に加工する必要があります。
この処理のことを機械学習では前処理と呼んだりします。
今回は入力画像を224×224×3のサイズに整形します。画像データサイズの整形にはkerasのimage_load関数を用いて行います。
ブラウザから受け取った芸能人の画像を処理していきましょう。app.pyのuploads_fileを以下のように書き換えます。
@app.route('/upload', methods=['GET', 'POST'])
def uploads_file():
# リクエストがポストかどうかの判別
if request.method == 'POST':
# ファイルがなかった場合の処理
if 'upload_files' not in request.files:
print("ファイルなし")
return redirect(request.url)
image_paths = []
uploads_files = request.files.getlist('upload_files')
for uploads_file in uploads_files:
img_path = os.path.join(app.config['UPLOAD_FOLDER_ENTER'], uploads_file.filename)
uploads_file.save(img_path)
#------------------------以下を書き足す--------------------------
#image_enter内に保存されている画像へのパスをリストで取得する。
uploads_files_path = [
os.path.join(UPLOAD_FOLDER_ENTER, uploads_file.filename) \
for uploads_file in uploads_files
]
#それぞれの画像のパスから画像サイズを224×224で指定して読み込む
face_imgs = [image.load_img(image_path, target_size=(224,224)) for image_path in uploads_files_path]
#224×224に整形した画像データを行列データに変換する。
face_img_arrays = [image.img_to_array(face) for face in faces]
enter_face_array = preprocess_input(faces_, version=2)
return redirect('/')
付け足した部分に関して一ずつ確認していきます。
まずリストの表記について
uploads_files_path = [
os.path.join(UPLOAD_FOLDER_ENTER, uploads_file.filename) \
for uploads_file in uploads_files
]
face_imgs = [image.load_img(image_path, target_size=(224,224)) for image_path in uploads_files_path]
face_img_arrays = [image.img_to_array(face) for face in face_imgs]
これらは全てpythonのリスト内包表記と呼ばれる記法を用いて書かれています。
詳細はリンクなどを参照して欲しいのですが、ざっくりリスト内の要素に繰り返しの処理を書くときの便利な手法だと考えておければOKです。
uploads_files_path = [
os.path.join(UPLOAD_FOLDER_ENTER, uploads_file.filename) \
for uploads_file in uploads_files
]
ここではimage_enterに保存されている画像へのパスを全てリストに格納しています。
faces = [image.load_img(image_path, target_size=(224,224)) for image_path in uploads_files_path]
ここではkerasのload_img関数を用いて上で獲得した画像へのパスから画像を読み込んでいます。
このとき、引数target_sizeで画像サイズを指定することができます。
この段階ではまだリストに入れられているデータはImageであり、numpyのデータではないことに注意しましょう。
face_img_arrays = [image.img_to_array(face) for face in face_imgs]
ここではimg_to_array関数を用いて Imageデータをモデルが受取可能なnumpyのデータに変換しています。
これでモデルにデータを入力できるぞ!と言いたいところですが、より顔認識の性能を上げるために、以下のような処理をnumpyの配列データに行います。
def preprocess_input(x, data_format=None, version=1):
x_temp = np.copy(x)
if data_format is None:
data_format = K.image_data_format()
assert data_format in {'channels_last', 'channels_first'}
if version == 1:
if data_format == 'channels_first':
x_temp = x_temp[:, ::-1, ...]
x_temp[:, 0, :, :] -= 93.5940
x_temp[:, 1, :, :] -= 104.7624
x_temp[:, 2, :, :] -= 129.1863
else:
x_temp = x_temp[..., ::-1]
x_temp[..., 0] -= 93.5940
x_temp[..., 1] -= 104.7624
x_temp[..., 2] -= 129.1863
elif version == 2:
if data_format == 'channels_first':
x_temp = x_temp[:, ::-1, ...]
x_temp[:, 0, :, :] -= 91.4953
x_temp[:, 1, :, :] -= 103.8827
x_temp[:, 2, :, :] -= 131.0912
else:
x_temp = x_temp[..., ::-1]
x_temp[..., 0] -= 91.4953
x_temp[..., 1] -= 103.8827
x_temp[..., 2] -= 131.0912
else:
raise NotImplementedError
return x_temp
これは正規化と呼ばれる処理で、行列データの各要素の数字がAIモデルにとって扱いやすい範囲の数値に調整しています。
ここで出てくる93.5940や104.7624といった数値は最適化の結果用いられているだけなので今回は特に深く考える必要はありません。
ではこの前処理を各画像行列データに対して行っていきます。実装上ではpreprocess_inputに行列データを渡すだけで完了します。
@app.route('/upload', methods=['GET', 'POST'])
def uploads_enter_files():
# リクエストがポストかどうかの判別
if request.method == 'POST':
# ファイルがなかった場合の処理
if 'upload_files' not in request.files:
print("ファイルなし")
return redirect(request.url)
image_paths = []
uploads_files = request.files.getlist('upload_files')
for uploads_file in uploads_files:
img_path = os.path.join(app.config['UPLOAD_FOLDER_ENTER'], uploads_file.filename)
uploads_file.save(img_path)
uploads_files_path = [
os.path.join(UPLOAD_FOLDER_ENTER, uploads_file.filename) \
for uploads_file in uploads_files
]
face_imgs = [image.load_img(image_path, target_size=(224,224)) for image_path in uploads_files_path]
face_img_arrays = [image.img_to_array(face) for face in face_imgs]
#preprocess_input関数を用いて行列データを正規化
enter_face_array = preprocess_input(faces_, version=2)
これでようやく画像データをAIモデルに入力する準備が整いました。
ここまでは芸能人の顔画像に対して前処理を行ってきましたが、全く同じ手順でユーザーの画像に対しても前処理を行うことができます。upload_user_filesを以下のように書き換えましょう。
@app.route('/upload_user', methods=['GET', 'POST'])
def upload_user_files():
if request.method == 'POST':
upload_file = request.files['upload_uesr_file']
img_path = os.path.join(UPLOAD_FOLDER_USER_FACE,upload_file.filename)
upload_file.save(img_path)
#load_imgを用いて画像を224×224サイズに整形して読み込み
#img_to_arrayを用いて画像データを行列化
user_face = [image.img_to_array(image.load_img(img_path, target_size=(224,224)))]
#行列データの型をfloat32に変換
user_face_array = asarray(user_face, 'float32')
#preprocess_inputを用いて画像行列を正規化
user_face_array = preprocess_input(user_face_array, version=2)
return redirect('/')
これで芸能人画像、ユーザー画像共にモデルに入力可能な形式になりました。
行列データをモデルに渡してベクトルに変換する
ここからはいよいよAIモデルにデータを渡して実際に画像データをベクトルに変換する処理を行っていきます。
モデルをAIモデルをサーバー側で動かすために、モデルのビルド(モデルを使える状態にセットする)を行います。
app.pyに以下を書き加えてください。
graph = tf.get_default_graph()
model = vggface.VGGFace(model='resnet50',
include_top=False,
input_shape=(224, 224, 3),
pooling='avg')
ブラウザから受け取った芸能人の画像をモデルに入力してベクトルに変換していきましょう。
upload_enter_filesを以下のように書き換えます。
@app.route('/upload', methods=['GET', 'POST'])
def uploads_enter_files():
# リクエストがポストかどうかの判別
if request.method == 'POST':
# ファイルがなかった場合の処理
if 'upload_files' not in request.files:
print("ファイルなし")
return redirect(request.url)
image_paths = []
uploads_files = request.files.getlist('upload_files')
for uploads_file in uploads_files:
img_path = os.path.join(app.config['UPLOAD_FOLDER_ENTER'], uploads_file.filename)
uploads_file.save(img_path)
uploads_files_path = [
os.path.join(UPLOAD_FOLDER_ENTER, uploads_file.filename) \
for uploads_file in uploads_files
]
face_imgs = [image.load_img(image_path, target_size=(224,224)) for image_path in uploads_files_path]
face_img_arrays = [image.img_to_array(face) for face in face_imgs]
#preprocess_input関数を用いて行列データを正規化
enter_face_array = preprocess_input(faces_, version=2)
global graph
with graph.as_default():
user_face_vector = model.predict(enter_face_array)
追加された部分を確認してみましょう。
global graph
with graph.as_default():
user_face_vector = model.predict(enter_face_array)
最初の2行はFlaskでkerasを扱う際の定型文だと思えば大丈夫です。
3行目でモデルの推論を行っており、引数に入力テンソルを渡すことで顔画像データをベクトルに変換することができています。
これで顔画像をベクトルに変換することができました!
ベクトルの類似度計算
前節ではブラウザから受け取った画像をベクトルに変換することができました。
ここからは変換したベクトル同士がどれだけ似ているかを測る処理について解説していきます。
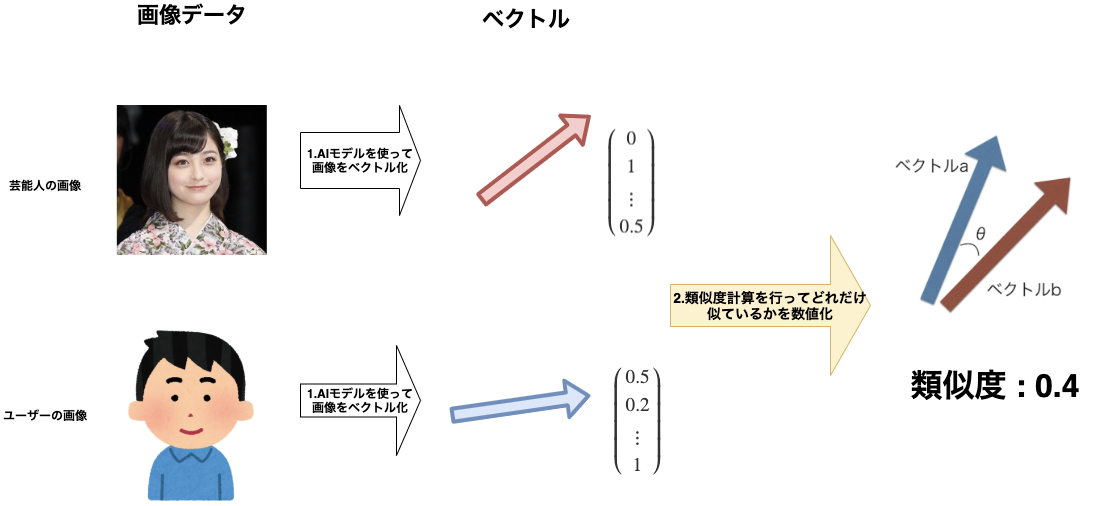
画像同士の類似度を測る
- 画像をベクトルに変換したあとは、ベクトル同士がどれだけ「似ている」かを測る必要があります。
- ベクトル同士がどれだけ「似ている」かを表す指標(類似度という)として今回はコサイン類似度と呼ばれる類似度を使用します。
コサイン類似度とは?
- コサイン類似度は一言で表すと「多次元ベクトル同士が表す角度の余弦」を表しています。
二次元では高校数学でもやったようにベクトル同士がなす角のcosは内積を用いて
$$\cos \theta = \dfrac{a_1b_1+a_2b_2}{\sqrt{a_1^2+a_2^2}\sqrt{b_1^2+b_2^2}} $$
とあらわすことができました。
これは二つのベクトル $\vec{a}$と$\vec{b}$ のなす角を表しており、ベクトル同士のなす角が小さい(cosが大きい)と二つのベクトルは「似ている」、なす角が大きい(cosが小さい)と「似ていない」ということができます。

-
このベクトル同士のなす角を多次元(配列の要素の数が2つ以上)のベクトルに対しても同じように定義してやると以下のように表すことができます。
$$\cos \theta = \dfrac{a_1b_1+\cdots +a_nb_n}{\sqrt{a_1^2+\cdots +a_n^2}\sqrt{b_1^2+\cdots +b_n^2}}$$ -
numpyを用いてこのコサイン類似度を実際に実装してみましょう。
import numpy as np
def cos_sim(v1, v2):
return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2))
実際に実行すると以下のようになります。
X = np.array([0.789, 0.515, 0.335,0])
Y = np.array([0.832, 0.555,0,0])
# cos(X,Y) = (0.789×0.832)+(0.515×0.555)+(0.335×0)+(0×0)≒0.942
print(cos_sim(X, Y)) #=> 0.9421693704700748
コサイン類似度を用いて実際に画像の類似度を比較してみる
- それでは実際にコサイン類似度を用いてVGG16によってベクトル化された画像同士の類似度を比較していきます。
- 今回はcosの計算には計算速度や精度がより洗練されたscipyに予め実装されているコサイン類似度を用います。
app.pyに以下のようにコサイン類似度を定義していきましょう。
from scipy.spatial.distance import cosine
def get_similarity(face_vector1, face_vector2):
return 1 - cosine(face_vector1, face_vector2)
ここではどれだけ似ているか、ということを表す指標で使いたいので1からコサインの値を引くことによってベクトル同士が似ていればコサイン類似度が大きくなる仕様にしています。
それでは、ここからはいよいよ類似度を用いて一番似ている芸能人の画像を表示する機能を実装していきましょう。
似ている芸能人の画像を表示する
画像の類似度を比較する際に、ブラウザから受け取った芸能人画像から変換した画像ベクトルを保存しておく必要があります。
APIの中で、画像ベクトルをどうやって扱うかを抑えておきましょう。
-
upload_enter_fileで受け取った芸能人画像をAIベクトルに変換する - 1で変換したベクトルをサーバー側で保存する
-
upload_user_fileで受け取ったユーザー画像をAIを用いてベクトルに変換する upload_user_file内で2で保存したベクトルと3で変換したユーザーの顔写真ベクトルの類似度を計算する- 4で類似度計算した中で一番類似度が大きかった画像を一番似ている芸能人画像として表示する
太字で書かれた部分を今から実装していきます。
まずは2のupload_enter_fileで変換した芸能人画像ベクトルを保存する処理を実装していきましょう。
芸能人の顔画像ベクトルを保存する
ベクトルを保存する際に後から呼び出す必要があり、この時image_enterディレクトリに保存されている芸能人画像と変換されたベクトルを紐つける必要があります。
今回はベクトルの保存にpythonの辞書を用います。
app.pyのupload_enter_file の外に画像パスとベクトルを紐つけるための空の辞書を用意してください。
FROM_PATH_TO_VECTOR = {}
それでは辞書を用いて変換し芸能人顔ベクトルを保存する処理を書いていきます。
@app.route('/upload', methods=['GET', 'POST'])
def uploads_file():
# リクエストがポストかどうかの判別
if request.method == 'POST':
# ファイルがなかった場合の処理
if 'upload_files' not in request.files:
print("ファイルなし")
return redirect(request.url)
image_paths = []
uploads_files = request.files.getlist('upload_files')
for uploads_file in uploads_files:
img_path = os.path.join(app.config['UPLOAD_FOLDER_ENTER'], uploads_file.filename)
uploads_file.save(img_path)
uploads_files_path = [
os.path.join(app.config['UPLOAD_FOLDER_ENTER'], uploads_file.filename) \
for uploads_file in uploads_files
]
face_imgs = [image.load_img(image_path, target_size=(224,224)) for image_path in uploads_files_path]
face_img_arrays = [image.img_to_array(face) for face in face_imgs]
enter_face_array = preprocess_input(faces_, version=2)
score = 0
global graph
with graph.as_default():
user_face_vector = model.predict(enter_face_array)
#---------------以下を書き加える----------------
#face vectorと顔画像パスとのマッピング
for i, vector in enumerate(user_face_vector):
FROM_PATH_TO_VECTOR[uploads_files_path[i]] = vector
return redirect('/')
追加した部分に関して、enumerateはfor文を回す際にリストの要素と同時にその要素のインデックスも同時に取得できる便利な文法です。
参考:enumerateの使い方
これでブラウザから受け取った芸能人画像のベクトルを保存することができました。
芸能人の画像とユーザーの画像の類似度を計算して比較する
次は類似度を計算して一番大きな類似度を持つ芸能人の画像を決定します。
この処理は全てupload_user_filesに書いていきます。ユーザーの画像をブラウザから受け取ったタイミングでもう類似度を計算し一番似ている芸能人の顔画像を決定してしまいます。
先ほど実装したコサイン類似度を用いて類似度を計算していきましょう。
@app.route('/upload_user', methods=['GET', 'POST'])
def upload_user_files():
if request.method == 'POST':
upload_file = request.files['upload_uesr_file']
img_path = os.path.join(UPLOAD_FOLDER_USER_FACE,upload_file.filename)
upload_file.save(img_path)
user_face = [image.img_to_array(image.load_img(img_path, target_size=(224,224)))]
user_face_array = asarray(user_face, 'float32')
user_face_array = preprocess_input(user_face_array, version=2)
global graph
with graph.as_default():
user_face_vector = model.predict(user_face_array)
#-----------------------------以下を書き加える-----------------------------
#最も似ている芸能人の顔写真へのパスと類似度を保存するための変数
most_similar_img = ''
max_similarity = 0
for path, vector in FROM_PATH_TO_VECTOR.items():
if get_similarity(user_face_vector, vector) > max_similarity:
max_similarity = get_similarity(user_face_vector, vector)
most_similar_img = path
filename = most_similar_img.split('/')[-1]
return redirect('/')
for文を用いて2で保存した芸能人の顔画像ベクトルを順番に取り出して類似度を計算しています。
most_similar_img = ''
max_similarity = 0
for path, vector in FROM_PATH_TO_VECTOR.items():
if get_similarity(user_face_vector, vector) > max_similarity:
max_similarity = get_similarity(user_face_vector, vector)
most_similar_img = path
for path, vector in FROM_PATH_TO_VECTOR.items():は辞書内のキーと値を同時に取り出しています。今回はキーの pathが画像へのパス、値のvectorがその画像の画像ベクトルです。
if文以下ではfor文の各ループにおいてそれまでの最大の類似度より類似度が大きい場合最大の類似度とその画像へのパスを更新するような処理を行っています。
これでユーザー画像と最も似ている芸能人の画像へのパスをmost_similar_img、その時の類似度を max_similarityとして取得することができました。
一番似ている芸能人画像を表示する
最後に、ユーザーと一番似ている芸能人の顔画像をブラウザ上で表示する機能を実装していきます。
まず、一番似ている芸能人画像を表示するページのhtmlを実装します。
<!doctype html>
<html>
<head>
<meta charset="UTF-8">
<title>
API result
</title>
</head>
<body>
<center>
<h1>
あなたに最も似ている芸能人
</h1>
<img src= "images/{{ filename }}" style="margin: 20px; vertical-align: bottom; width: 200px;">
<div>類似度: {{ score }}</div>
<a href="/">トップへ戻る</a>
</center>
</body>
upload_user_fileで求めた最も似ている芸能人画像とその類似度をresult.htmlで受け取れるようにapp.pyを少し修正します。
@app.route('/upload_user', methods=['GET', 'POST'])
def upload_user_files():
if request.method == 'POST':
upload_file = request.files['upload_uesr_file']
img_path = os.path.join(UPLOAD_FOLDER_USER_FACE,upload_file.filename)
upload_file.save(img_path)
user_face = [image.img_to_array(image.load_img(img_path, target_size=(224,224)))]
user_face_array = asarray(user_face, 'float32')
user_face_array = preprocess_input(user_face_array, version=2)
most_similar_img = ''
max_similarity = 0
global graph
with graph.as_default():
user_face_vector = model.predict(user_face_array)
for path, vector in FROM_PATH_TO_VECTOR.items():
if get_similarity(user_face_vector, vector) > max_similarity:
max_similarity = get_similarity(user_face_vector, vector)
most_similar_img = path
#--------------------以下を書き加える--------------------
filename = most_similar_img.split('/')[-1]
return render_template(
'result.html',
filename=filename,
score=max_similarity
)
filename = most_similar_img.split('/')[-1]では、ファイルのパスから最後のファイル名だけをfilenameに格納しています。
/image_enter/画像の名前.jpgの画像の名前.jpgの部分だけ取り出しているというイメージです。
return render_template(
'result.html',
filename=filename,
score=max_similarity
)
ここでは最も似てる画像のファイル名をfilename、 その時の類似度の値をscoreとしてresult.htmlに送りつけています。
これでwebアプリが完成しました!