はじめに
AI(人工知能)が流行っていますが、人工知能・機械学習・ディープラーニングがそれぞれどんなものなのか、実際に動かしながら理解していきます。
ただし、どんなものかを実感するだけなので、ゼロから実装するのではなくライブラリ・フレームワークを活用します。
対象読者
- これから人工知能を勉強する人
- 人工知能・機械学習・ディープラーニングの違いを知りたい人
ゴール
- 人工知能・機械学習・ディープラーニングの関係を理解できる
- 人工知能・機械学習・ディープラーニングがどんなものかなんとなくイメージできる
人工知能とは
そもそも人工知能とは何なのかについて考えます。
「人工知能は人間を超えるか」では、以下のように説明されています。
本当の意味での人工知能 -つまり、「人間のように考えるコンピュータ」はできていないのだ。
つまり、今は人間のような活動をしているようにみえる技術を総じて人工知能と呼んでいることになります。
さらには、人工知能自体の定義も専門家の間で定まっていません。
レベル別人工知能
世の中で人工知能と呼ばれる物は4つのレベルに分けることができると「人工知能は人間を超えるか」では言われています。
-
レベル1:単純な制御プログラム(制御工学)
- マーケティング的に「AI」と名乗っている
- 制御工学やシステム工学の分野に属する
-
レベル2:古典的な人工知能
- 人工知能として研究されているのはこのレベルから
- 振る舞いのパターンが多彩なもの
- 推論・探索・知識ベースなど
- 自ら学習しない
-
レベル3:機械学習
- 入力と出力の関係づけがデータを元に学習されている
- 自ら学習する
-
レベル4:ディープラーニング
- データから学習するための特徴量も学習する
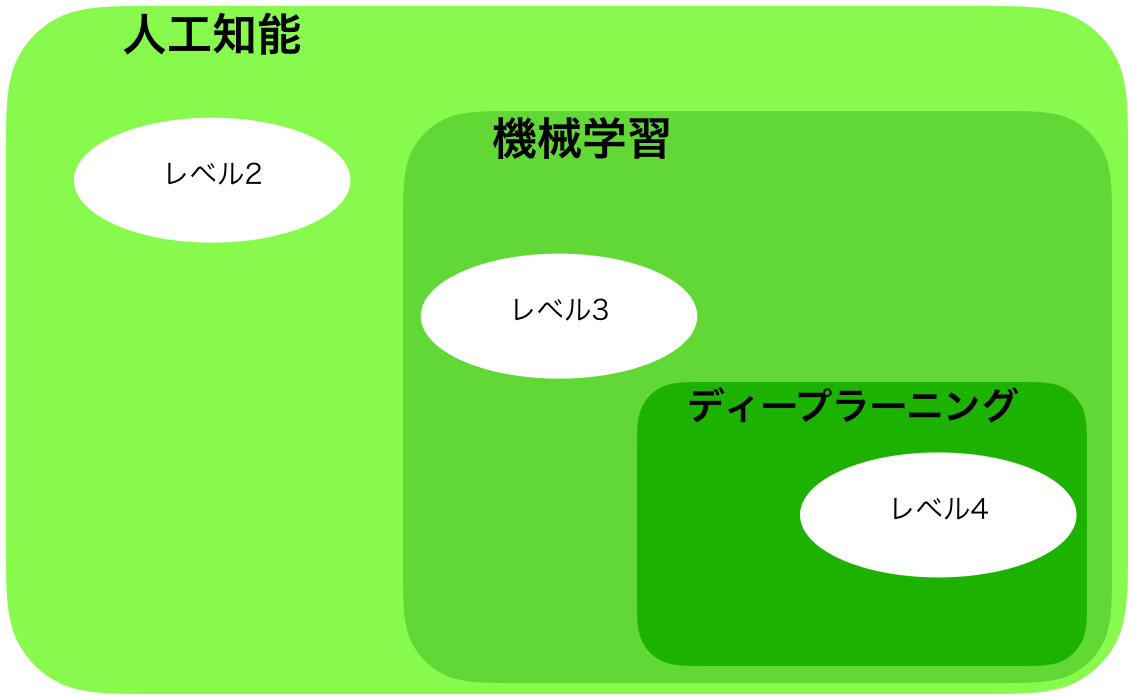
人工知能・機械学習・ディープラーニングの違い
人工知能・機械学習・ディープラーニングはそれぞれ以下のようになります。
- 人工知能:1つの分野(定義自体は曖昧)
- 機械学習:プログラム自身が学習する人工知能を実現する手法の集まり
- ディープラーニング:機械学習の手法の一つであるニューラルネットワークの層を深くしたもの
人工知能・機械学習・ディープラーニングとレベル別の人工知能の関係は図の通りになります。
実装して試す
実際に動かしてみましょう。実装するのは、レベル2・レベル3・レベル4の人工知能になります。
それぞれのレベルにて、正答率(0.0 ~ 1.0)をスコアとして計算しています。
まずは、人工知能が予測するデータについて説明します。
scikit-learnのアヤメのデータセットを利用します。
人工知能は、インプットされたデータ(特徴量)から結果を予測します。今回は、予測するアヤメは3品種あり、どのアヤメかを予測します。
予測するための特徴量は以下の通りです。
- 萼片の長さ
- 萼片の幅
- 花弁の長さ
- 花弁の幅
データの中身を少し見てみます。最後のtarget列がアヤメの名前になります。
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) target
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosa
5 5.4 3.9 1.7 0.4 setosa
6 4.6 3.4 1.4 0.3 setosa
7 5.0 3.4 1.5 0.2 setosa
8 4.4 2.9 1.4 0.2 setosa
9 4.9 3.1 1.5 0.1 setosa
古典的な人工知能(レベル2)
まずは古典的な人工知能を実装します。
今回はデータから傾向を見つけ、簡単な知識を入れました。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# データのインポート
iris = load_iris()
# 特徴量と目的変数に分ける
X = iris['data']
y = iris['target']
# 学習させるデータと学習したモデルの精度を測るデータに分ける
# レベル2の実装では自ら学習しないため精度を測るデータのみを利用する
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# 予測するためにルール(知識)を埋め込んだ関数
# 特徴量の値で分岐して予測する
def predict_iris(feature):
if feature[2] < 2 and feature[3] < 0.6:
return 0
elif 2 <= feature[2] < 5 and 0.6 <= feature[3] < 1.7:
return 1
else:
return 2
# スコアを計測する関数
def compute_score(pred, ans):
correct_answer_num = 0
for p, a in zip(pred, ans):
if p == a:
correct_answer_num += 1
return correct_answer_num / len(pred)
pred = []
for feature in X_test:
pred.append(predict_iris(feature))
score = compute_score(pred, y_test)
print('Score is', score)
結果
Score is 0.9555555555555556
機械学習(レベル3)
次に機械学習の実装をします。
機械学習は、プログラムがデータから学習します。
今回使うアルゴリズムはロジスティック回帰であり、Pythonの機械学習ライブラリであるscikit-learnを利用します。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
# データのインポート
iris = load_iris()
# 特徴量と目的変数に分ける
X = iris['data']
y = iris['target']
# 学習させるデータと学習したモデルの精度を測るデータに分ける
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# 利用するアルゴリズムをロジスティック回帰とする
model = LogisticRegression()
# 学習
model.fit(X_train, y_train)
# スコア計測
score = model.score(X_test, y_test)
print('Score is', score)
結果
Score is 0.8888888888888888
ディープラーニング(レベル4)
最後にディープラーニングの実装です。
ディープラーニングは、プログラムがデータから特徴量を生成し、学習します。
今回実装するディープラーニングは5層からなるニューラルネットワークになります。使用するライブラリはkerasになります。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from keras import layers
from keras import models
from keras.utils import np_utils
# データのインポート
iris = load_iris()
# 特徴量と目的変数に分ける
X = iris['data']
y = np_utils.to_categorical(iris['target'])
# 学習させるデータと学習したモデルの精度を測るデータに分ける
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# 5層のニューラルネットワークのモデルを定義
model = models.Sequential()
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(3, activation='softmax'))
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 学習
model.fit(X_train, y_train, epochs=10, batch_size=10)
# スコア計測
score = model.evaluate(X_test, y_test)
print('Score is', score[1])
結果
Score is 0.8888888955116272
まとめ
人工知能・機械学習・ディープラーニングは以下のような意味でした。
- 人工知能:分野(定義自体は曖昧)
- 機械学習:プログラム自身が学習する人工知能を実現するため手法の集まり
- ディープラーニング:機械学習の手法の一つ
それぞれのスコアについては、最も単純なルールベースが高いという結果になりました。
ただし、今回はとても単純なデータだったため、機械学習・ディープラーニングの真価が発揮されていないという点に注意してください。
人工知能/AIが最近は話題になっていますが、手段(AIであるかどうか)ではなくて何をしたいか(目的)が大切なのだと感じました。