はじめに
タイトルの内容を検証してみたので記事にしました。
使うデータとして Sakila Sample Database を利用
Sakila Sample Database をご存知でしょうか?
簡単にいうとMySQL開発チームが提供しているMySQLの機能を検証したりする用のサンプルデータベースです。
こちらのGitHubレポジトリからダウンロードすればMySQL以外のRDBMSへのデータ取り込みも可能です。
本記事では、このサンプルデータベースの一部テーブルらを利用します。
本記事で扱うクエリで得たいデータ
このSakila Databaseにはざっくり説明するとレンタルビデオ店のシステム用データがあります。
レンタルビデオの在庫、ユーザー会員、レンタルトランザクションが格納されています。
そんなデータである前提で、本記事で扱う欲しいデータが以下です。
特定の期間にてレンタルをしたカスタマーにおいてカスタマーIDが若い順の上位5人分のみのそのレンタルトランザクションを表示したい
今回、特定の期間をSakila Databaseにあるデータから2005年5月28日から2005年6月2日までとしました。
その条件の場合、欲しいデータ結果は以下になります。
+-----------+---------------------+-------------+
| rental_id | rental_date | customer_id |
+-----------+---------------------+-------------+
| 573 | 2005-05-28 10:35:23 | 1 |
| 830 | 2005-05-29 22:43:55 | 3 |
| 731 | 2005-05-29 07:25:16 | 5 |
| 1085 | 2005-05-31 11:15:43 | 5 |
| 1142 | 2005-05-31 19:46:38 | 5 |
| 577 | 2005-05-28 11:09:14 | 6 |
| 916 | 2005-05-30 11:25:01 | 6 |
| 748 | 2005-05-29 09:27:00 | 7 |
| 975 | 2005-05-30 21:07:15 | 7 |
| 1063 | 2005-05-31 08:44:29 | 7 |
+-----------+---------------------+-------------+
MySQL(8.0)でのSQLで実現する場合
MySQLに入ったSakila Databaseで検証します。
MySQLにおいてはウィンドウ関数はversion8.0にて初めて導入されました。
利用するバージョンは以下になります。
mysql> select version();
+-----------+
| version() |
+-----------+
| 8.0.27 |
+-----------+
本記事ではウィンドウ関数以外でのクエリ取得から見ていきます。
ウィンドウ関数を使わないクエリ その1
ウィンドウ関数関数を利用せずに目的の結果を得るクエリとして始めに以下のクエリがあります。
select rental.rental_id, rental.rental_date, rental.customer_id
from sakila.rental rental
inner join (
select r.customer_id from sakila.rental r
where r.rental_date between '2005-05-28 00:00:00' and '2005-06-03 00:00:00'
group by r.customer_id
order by r.customer_id asc
limit 5
) top_n_c
on rental.customer_id = top_n_c.customer_id
where rental.rental_date between '2005-05-28 00:00:00' and '2005-06-03 00:00:00'
order by rental.customer_id, rental.rental_date asc
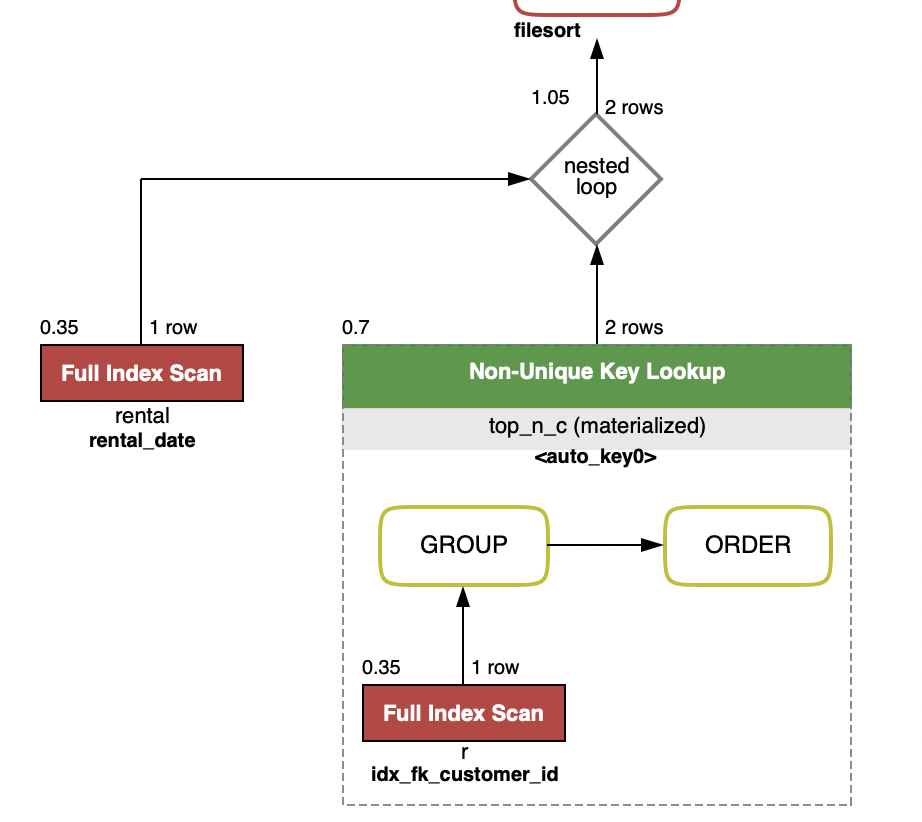
上記のように愚直に書く場合、サブクエリとしてレンタルトランザクションの条件を絞りGroup Byで対象カスタマーを絞ったものに対して再度同じ条件でクエリしレンタルトランザクションを得ることになります。
このSQLの実行計画を見てみるとGroup ByしたテーブルへのJoinになりあまり効率がよくないことがわかります。
+----+-------------+------------+------------+-------+--------------------------------+--------------------+---------+---------------------------+------+----------+------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+--------------------------------+--------------------+---------+---------------------------+------+----------+------------------------------------------+
| 1 | PRIMARY | rental | NULL | index | rental_date,idx_fk_customer_id | rental_date | 10 | NULL | 1 | 100.00 | Using where; Using index; Using filesort |
| 1 | PRIMARY | <derived2> | NULL | ref | <auto_key0> | <auto_key0> | 2 | sakila.rental.customer_id | 2 | 100.00 | Using index |
| 2 | DERIVED | r | NULL | index | rental_date,idx_fk_customer_id | idx_fk_customer_id | 2 | NULL | 1 | 100.00 | Using where |
+----+-------------+------------+------------+-------+--------------------------------+--------------------+---------+---------------------------+------+----------+------------------------------------------+
ウィンドウ関数を使わないクエリ その2
次にMySQLにてウィンドウ関数を使わないようにするクエリとしてMySQLのsession variablesを利用する方法があります。
select rental_id, rental_date, customer_id
FROM (
SELECT
r.rental_id,
r.rental_date,
r.customer_id,
@customer_rank:=CASE
WHEN @current_customer IS NULL THEN 1
WHEN @current_customer = r.customer_id THEN @customer_rank
ELSE @customer_rank + 1
END customer_rank,
@current_customer:=r.customer_id
FROM
sakila.rental r
WHERE
r.rental_date BETWEEN '2005-05-28 00:00:00' AND '2005-06-03 00:00:00'
ORDER BY r.customer_id , r.rental_date ASC
) ranked
WHERE customer_rank <= 5
上記のSQLではcurrent_customerというsession variablesを用意することで行間の情報を保持させるようにしています。新規のカスタマーになるごとにインクリメントさせることでGroupされるカスタマーのランキングをcustomer_rankとして持たせます。customer_rankは算出中はwhereに入れることはできないためサブクエリとした後、WHERE customer_rank <= 5として上位5人を取得します。
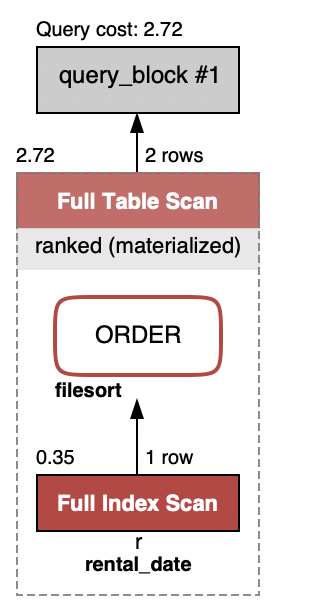
実行計画はサブクエリとして作成されたテーブルへのクエリになり上述のクエリよりはシンプルになります。
+----+-------------+------------+------------+-------+---------------+-------------+---------+------+------+----------+------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+-------------+---------+------+------+----------+------------------------------------------+
| 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 50.00 | Using where |
| 2 | DERIVED | r | NULL | index | rental_date | rental_date | 10 | NULL | 1 | 100.00 | Using where; Using index; Using filesort |
+----+-------------+------------+------------+-------+---------------+-------------+---------+------+------+----------+------------------------------------------+
このクエリの弱点はセッション変数を利用するため結果の一意性が保証できない点です。
この弱点を解消するためには以降でのウィンドウ関数を利用することになります。
ウィンドウ関数を利用したクエリ
SELECT rental_id, rental_date, customer_id
FROM (
SELECT
r.rental_id,
r.rental_date,
r.customer_id,
DENSE_RANK() over(order by r.customer_id) as customer_rank
FROM
sakila.rental r
WHERE
r.rental_date BETWEEN '2005-05-28 00:00:00' AND '2005-06-03 00:00:00'
ORDER BY r.customer_id , r.rental_date ASC
) ranked
WHERE customer_rank <= 5
今回のケースでは、DENSE_RANK()を利用することになりました。RANK()は重複する場合順位をその分飛ばしますが、DENSE_RANK()は順位を飛ばさないランキングを作ります。
実行計画は以下になります。これは上述のクエリ2と全く同じであることがわかります。つまり、今回のケースではウィンドウ関数はsession variableをデータベース内部で持ってもらい行間データ計算をしていると捉えることができそうです。
+----+-------------+------------+------------+-------+---------------+-------------+---------+------+------+----------+------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+-------------+---------+------+------+----------+------------------------------------------+
| 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 50.00 | Using where |
| 2 | DERIVED | r | NULL | index | rental_date | rental_date | 10 | NULL | 1 | 100.00 | Using where; Using index; Using filesort |
+----+-------------+------------+------------+-------+---------------+-------------+---------+------+------+----------+------------------------------------------+
Elasticsearch DSL クエリで実現する場合
一応、本題のElasticsearchのDSLクエリの場合の検証をします。
はじめに、Sakila DatabaseのデータをElasticsearchへ引っ張った方法を紹介します。
(補足)データをElasticsearchへrental indexとして入れる
{
"mappings": {
"properties": {
"rental_id": {
"type": "long"
},
"rental_date": {
"type": "date"
},
"customer_id": {
"type": "long"
},
"customer_name": {
"type": "text"
}
}
}
}
レンタルトランザクションと顧客データ用のIndexを作成する。
curl -XPUT -H 'Content-Type: application/json' http://localhost:9200/rental \
--data "@rental.json"
クエリ対象のデータをMySQL Sakila DatabaseからElasticsearchのBulk用ファイルへと生成します。
select concat('{ "index" : { "_index" : "rental", "_id" : "', rental.rental_id, '" } }
{ "rental_id" : "', rental.rental_id
,'" , "rental_date" : "', DATE_FORMAT(rental.rental_date, '%Y-%m-%dT%H:%i:%sZ')
,'" , "customer_id" : "', customer.customer_id
,'" , "customer_name" : "', customer.first_name,'" }')
from sakila.rental rental
join sakila.customer customer on rental.customer_id = customer.customer_id
where rental.rental_date between '2005-05-28 00:00:00' and '2005-06-03 00:00:00'
sakila_data.txtとしてbulk用ファイルにする。
Elasticsearchへデータ投入する。
curl -s -XPOST -H 'Content-Type: application/json' http://localhost:9200/_bulk \
--data-binary "@sakila_data.txt"
Elasticsearch DSL クエリ
Elasticsearchでは今回のケースではCollapse Searchの機能を利用することで欲しいデータが得られます。
curl -H "Content-Type: application/json" -XGET http://localhost:9200/rental/_search\? -d \
'{
"size": 5,
"sort": [
"customer_id"
],
"collapse": {
"field": "customer_id",
"inner_hits": {
"name": "order by rental_date",
"size": 10000,
"sort": [
{
"rental_date": "asc"
}
]
}
}
}'
クエリ実行後結果 (折りたたみ)
{
"took": 31,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 671,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "rental",
"_type": "_doc",
"_id": "573",
"_score": null,
"_source": {
"rental_id": "573",
"rental_date": "2005-05-28T10:35:23Z",
"customer_id": "1",
"customer_name": "MARY"
},
"fields": {
"customer_id": [
1
]
},
"sort": [
1
],
"inner_hits": {
"order by rental_date": {
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "rental",
"_type": "_doc",
"_id": "573",
"_score": null,
"_source": {
"rental_id": "573",
"rental_date": "2005-05-28T10:35:23Z",
"customer_id": "1",
"customer_name": "MARY"
},
"sort": [
1117276523000
]
}
]
}
}
}
},
{
"_index": "rental",
"_type": "_doc",
"_id": "830",
"_score": null,
"_source": {
"rental_id": "830",
"rental_date": "2005-05-29T22:43:55Z",
"customer_id": "3",
"customer_name": "LINDA"
},
"fields": {
"customer_id": [
3
]
},
"sort": [
3
],
"inner_hits": {
"order by rental_date": {
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "rental",
"_type": "_doc",
"_id": "830",
"_score": null,
"_source": {
"rental_id": "830",
"rental_date": "2005-05-29T22:43:55Z",
"customer_id": "3",
"customer_name": "LINDA"
},
"sort": [
1117406635000
]
}
]
}
}
}
},
{
"_index": "rental",
"_type": "_doc",
"_id": "731",
"_score": null,
"_source": {
"rental_id": "731",
"rental_date": "2005-05-29T07:25:16Z",
"customer_id": "5",
"customer_name": "ELIZABETH"
},
"fields": {
"customer_id": [
5
]
},
"sort": [
5
],
"inner_hits": {
"order by rental_date": {
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "rental",
"_type": "_doc",
"_id": "731",
"_score": null,
"_source": {
"rental_id": "731",
"rental_date": "2005-05-29T07:25:16Z",
"customer_id": "5",
"customer_name": "ELIZABETH"
},
"sort": [
1117351516000
]
},
{
"_index": "rental",
"_type": "_doc",
"_id": "1085",
"_score": null,
"_source": {
"rental_id": "1085",
"rental_date": "2005-05-31T11:15:43Z",
"customer_id": "5",
"customer_name": "ELIZABETH"
},
"sort": [
1117538143000
]
},
{
"_index": "rental",
"_type": "_doc",
"_id": "1142",
"_score": null,
"_source": {
"rental_id": "1142",
"rental_date": "2005-05-31T19:46:38Z",
"customer_id": "5",
"customer_name": "ELIZABETH"
},
"sort": [
1117568798000
]
}
]
}
}
}
},
{
"_index": "rental",
"_type": "_doc",
"_id": "577",
"_score": null,
"_source": {
"rental_id": "577",
"rental_date": "2005-05-28T11:09:14Z",
"customer_id": "6",
"customer_name": "JENNIFER"
},
"fields": {
"customer_id": [
6
]
},
"sort": [
6
],
"inner_hits": {
"order by rental_date": {
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "rental",
"_type": "_doc",
"_id": "577",
"_score": null,
"_source": {
"rental_id": "577",
"rental_date": "2005-05-28T11:09:14Z",
"customer_id": "6",
"customer_name": "JENNIFER"
},
"sort": [
1117278554000
]
},
{
"_index": "rental",
"_type": "_doc",
"_id": "916",
"_score": null,
"_source": {
"rental_id": "916",
"rental_date": "2005-05-30T11:25:01Z",
"customer_id": "6",
"customer_name": "JENNIFER"
},
"sort": [
1117452301000
]
}
]
}
}
}
},
{
"_index": "rental",
"_type": "_doc",
"_id": "748",
"_score": null,
"_source": {
"rental_id": "748",
"rental_date": "2005-05-29T09:27:00Z",
"customer_id": "7",
"customer_name": "MARIA"
},
"fields": {
"customer_id": [
7
]
},
"sort": [
7
],
"inner_hits": {
"order by rental_date": {
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "rental",
"_type": "_doc",
"_id": "748",
"_score": null,
"_source": {
"rental_id": "748",
"rental_date": "2005-05-29T09:27:00Z",
"customer_id": "7",
"customer_name": "MARIA"
},
"sort": [
1117358820000
]
},
{
"_index": "rental",
"_type": "_doc",
"_id": "975",
"_score": null,
"_source": {
"rental_id": "975",
"rental_date": "2005-05-30T21:07:15Z",
"customer_id": "7",
"customer_name": "MARIA"
},
"sort": [
1117487235000
]
},
{
"_index": "rental",
"_type": "_doc",
"_id": "1063",
"_score": null,
"_source": {
"rental_id": "1063",
"rental_date": "2005-05-31T08:44:29Z",
"customer_id": "7",
"customer_name": "MARIA"
},
"sort": [
1117529069000
]
}
]
}
}
}
}
]
}
}
Collapse SearchはElasticsearch5.3から導入された機能とのことです。ポイントはクエリのinner_hits内の部分で、外側でrentalインデックス中のcustomer_idごとのsortとsizeを指定しながら、inner_hits内部のsizeとsortで各ドキュメントをを引っ張って表示します。
別アプローチとしてはBucket sort aggregationを利用する方法もあります。しかし、こちらはAggregationであるため上述のinner_hitsのように本体も一度のクエリで取ることができず対象となるカスタマーIDのみしか取得できません。そのため、得られたカスタマーID指定で2回目のクエリを実行する必要があり今回の要件ではCollapseが最適でした。