コンペに参加した理由
同じ研究室の大学4年生と大学院1年生の2人で、データ分析を行う練習のために参加した。目標はあくまでも、高精度分析ではなくコードを書いて、考察をしてみるというものである。そのため、練習用に準備されているデータの分析を行なった。(国勢調査からの収入予測)
今後パート2、3、4、と続いていく予定です。この記事は分析をしてきた足跡を残す気持ちで書きます。
データの可視化(数値データだけ)
・全体の値を描画

何故かわかりませんが、ヒストグラムのyの値が小さくなってしまいました。
・収入に応じてプロットの色を変更
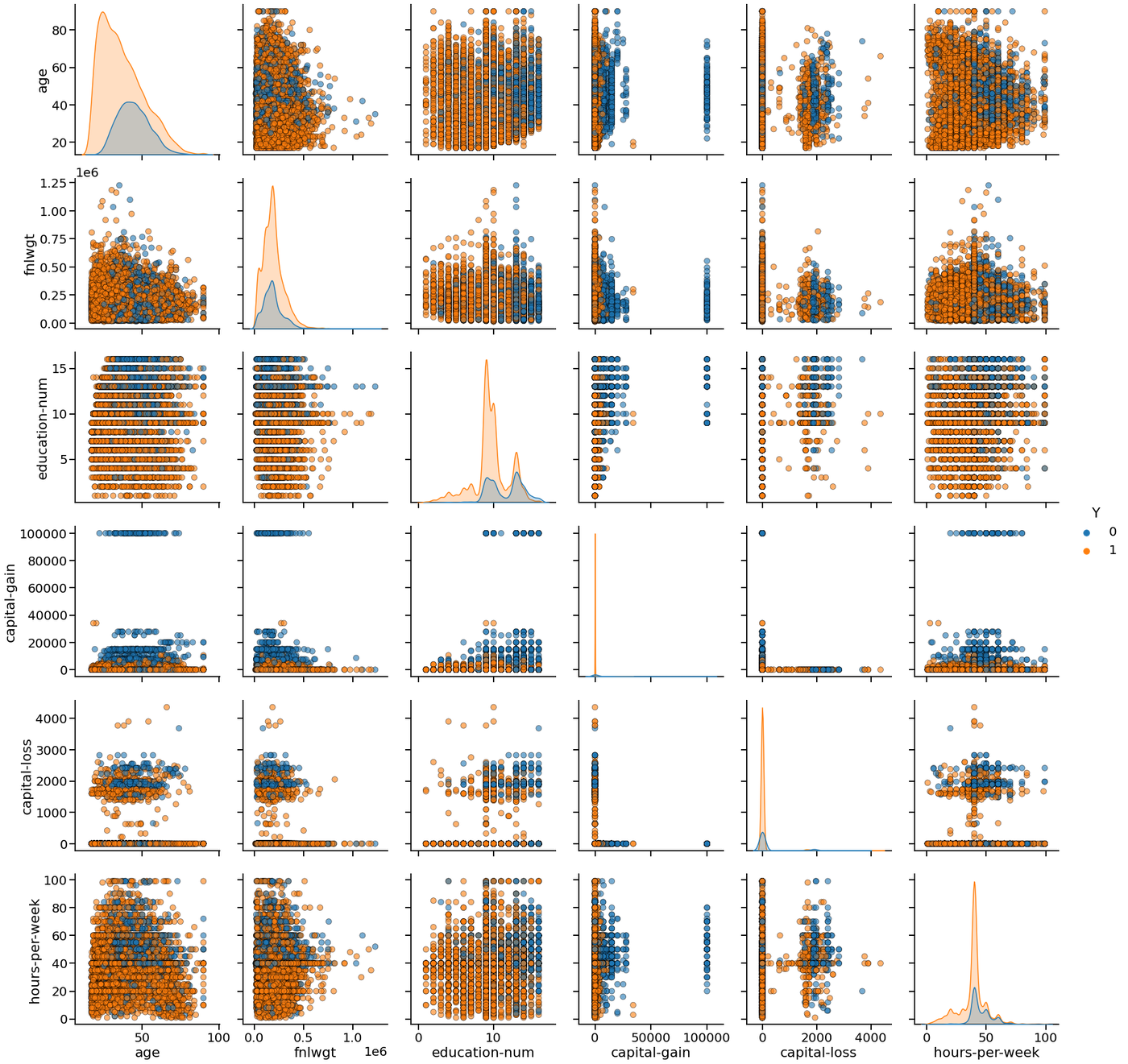
キャピタルゲインとの関係が大きくありそうな予感がします。うまく、分けることができそうなデータもありますが、全てをうまく分けることができなさそうなので、目で見るだけでなく数値を出してみます。
・相関関係のヒートマップ
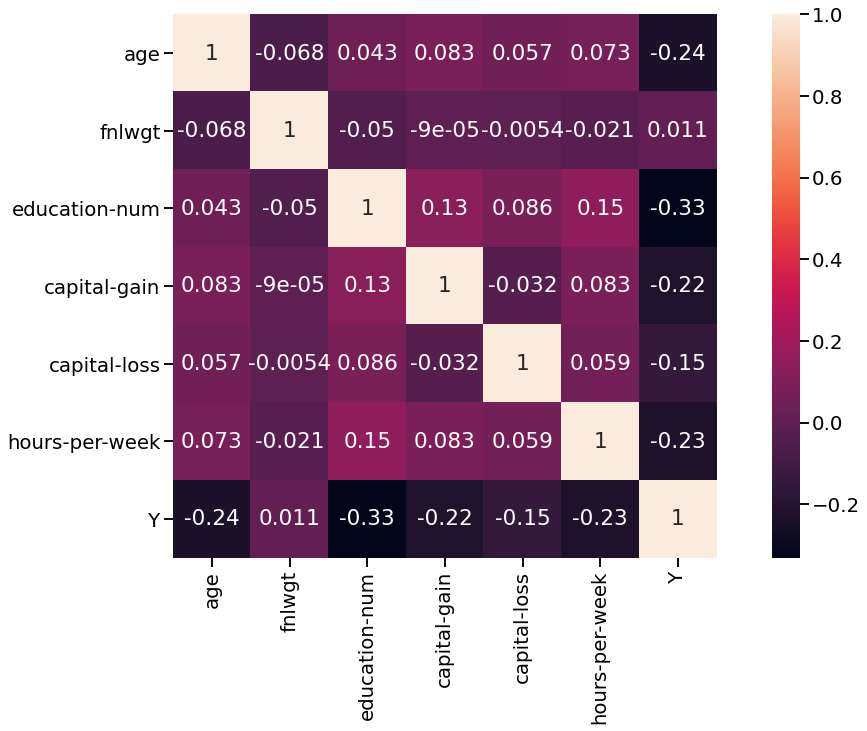
y(年収)との相関が強い説明変数がいくつかありますね。というよりもfnlwgt以外は相関がありそうな予感がします。0が高収入のカテゴリになっているので負の相関があるということは年収と正の相関があるということになります。
このヒートマップを見ても教育年数と年収は相関が強いことがわかります。イメージ通りです。
データの前処理
回のデータはほとんどのデータが質的変数だったので、ダミー変数にして解析を行なっていきま。
数値データは標準化か正規化をしていきます。
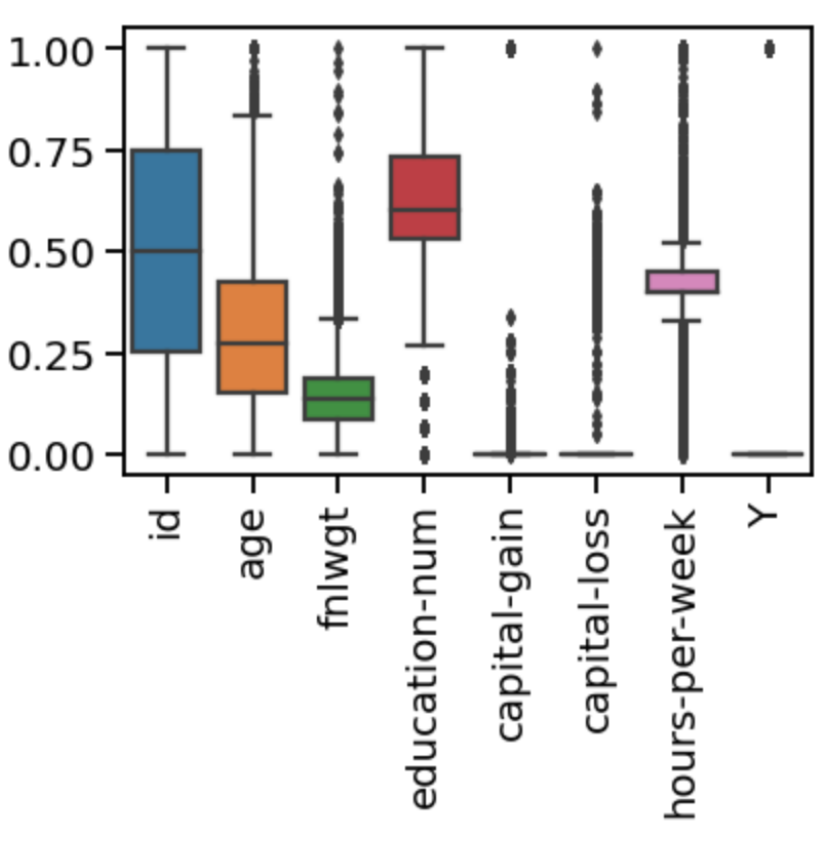
箱ヒゲ図を見てみるとid以外は外れ値が存在しており、正規化をすると重要な情報が潰される可能性があるので、今回は標準化を採用します。
特徴量選択
特徴量の選択として、ランフダムフォレストとロジスティック回帰を使う。
ロジスティック回帰の結果
accは0.7856265356265356、なので特徴をうまくつかめている可能性が高い。ただ、今回のデータは説明変数が多いので、どの程度説明変数を使おうか考えるために、重要度の高い順でn個説明変数をとってくる(n=5,10,15,...,105)。
重要度をヒストグラムで表示
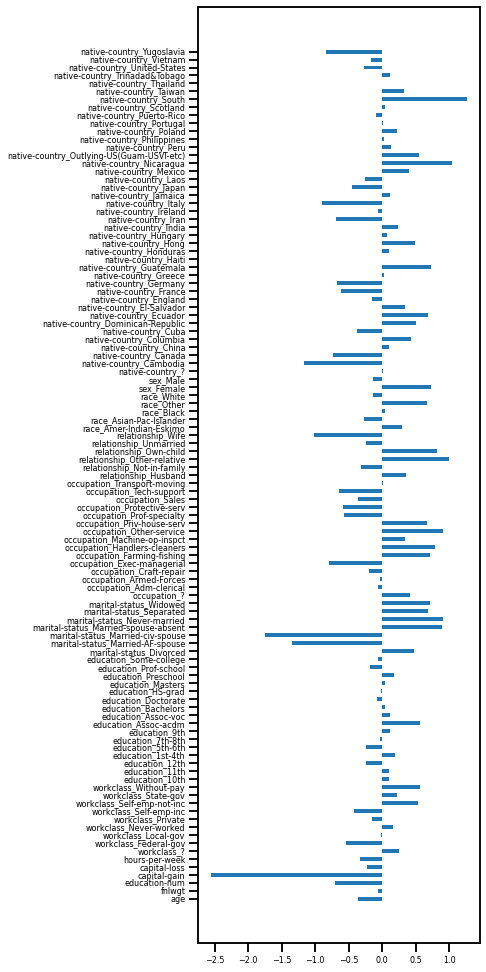
重要度の高い説明変数から順序よくn個とってきて、nを変更させて表示してみる。
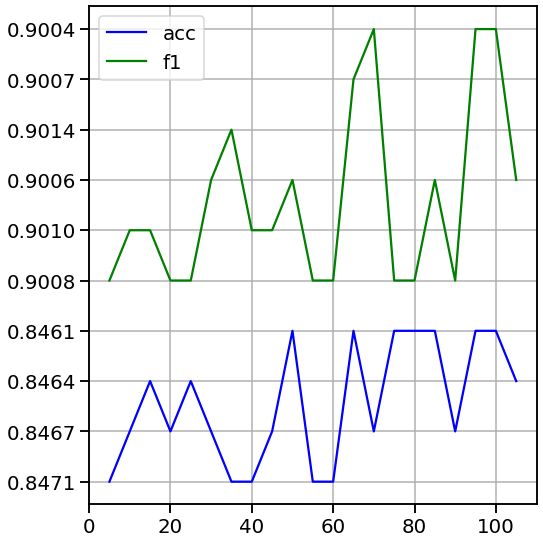
説明変数が多くなっても正答率が変わらないので最初の5個でうまく行くのではないか?
説明変数が少なくてもある程度のものが表現されていそう。
ん?縦軸のメモリがおかしい。無視お願いします。
ランダムフォレスト
Grid-Searchを用いてハイパーパラメータを調整した結果、accは85.71で、いい予測ができている。
特徴量の重要度は可視化してないが、上位3つは「キャピタルゲイン」「fnlwgt」「年齢」であった。この3つの説明変数を使って、モデルを構築した。
3つの説明変数を用いたときのモデルのaccは0.8093775593775594となった。
5%下がっっているが、それでも、ロジスティク回帰の精度よりも高いのでいい。

モデルの学習
xgboost
ランダムフォレストで用いた3つの特徴量を用いて、xgboostを試した結果、accは80.18となった。
ランダムフォレストで求めた精度と比較してみても、殆ど変化がなかった。なので、f1_scoreを比べてみると平均で0.88とかなりいいことから、予測モデルとしては優れていると考察できる。
# mod3 = xgb.XGBRegressor(max_depth = 6, learning_rate = 0.1, n_estimators=10, objective='reg:squarederror', gamma=0, min_child_weight=1, subsample=1, colsample_bytree=1)
mod3 = xgb.XGBClassifier(max_depth=6, learning_rate=0.1, n_estimators=10, objective='binary:logistic',gamma=0, min_child_weight=1, subsample=1, colsample_bytree=1, random_state=42)
# モデルを作成。xgb.trainにおけるparamの部分
params3 = {'max_depth': [8, 7, 6, 5, 4, 3], 'learning_rate': [0.1, 0.2, 0.3], 'gamma': [0.1, 0.2, 0.3], 'min_child_weight': [0.8, 1, 1.2], 'subsample': [1, 0.9, 0.8], 'colsample_bytree': [1, 0.9, 0.8]}
gscv3 = GridSearchCV(mod3, params3, cv = 5, refit=True, scoring='accuracy', verbose = 1, n_jobs=-1)
# gscvをこれからやるよっていう宣言だけ。グリッドサーチは.fitで実行される。
# n_jobs=-1にするとCPU100%で全コア並列計算。とても速い。
evallist = [(train_x, train_y)]
gscv3.fit(train_x, train_y, eval_metric='logloss', eval_set=evallist, early_stopping_rounds=100)
# 全データに対して学習を行う。evallistの値に対してloglossで評価を行い、100round後も変化がなければ終了。
print(gscv3.best_params_)
# {'colsample_bytree': 0.9, 'gamma': 0.2, 'learning_rate': 0.3, 'max_depth': 7, 'min_child_weight': 0.8, 'subsample': 0.8}
x_train, x_test, t_train, t_test = train_test_split(train_x, train_y, test_size=0.2, random_state=0)
train_pred = gscv3.predict(x_train)
test_pred = gscv3.predict(x_test)
print('train_accuracy_score_is_{:.4f}, test_accuracy_score_is_{:.4f}'.format(met.accuracy_score(t_train, train_pred), met.accuracy_score(t_test, test_pred)))
# 0.8042, 0.8018
print('train_f1_score_is_{:.4f}, test_f1_score_is_{:.4f}'.format(met.f1_score(t_train, train_pred), met.f1_score(t_test, test_pred)))
# 0.8849, 0.8834
今後の課題、反省
今回の解析は1ヶ月間という短い期間だったので、精度を出せるものではありませんでしたが、解析の流れを通してモデルの結果を提出することができたのでよかったと思います。
解析手法についても、より適切なものを選択する必要があると思いました。後で知りましたが、勾配ブーストを行う手法は、外れ値の影響を受けやすいそうです笑
今後は、もっと長期間で解析をして、精度を求められるようにコーディング力と知識をつけていきたいですね。