内容
・リアルタイム検索、リアルタイム集計ができるようになる
・MySQLとElasticsearchをリアルタイムに近い時間で同期する方法
・実際のコードはとても複雑なので考え方をダラダラと説明する
・ここでの説明が100%正しいとは思わないで
全体の流れ
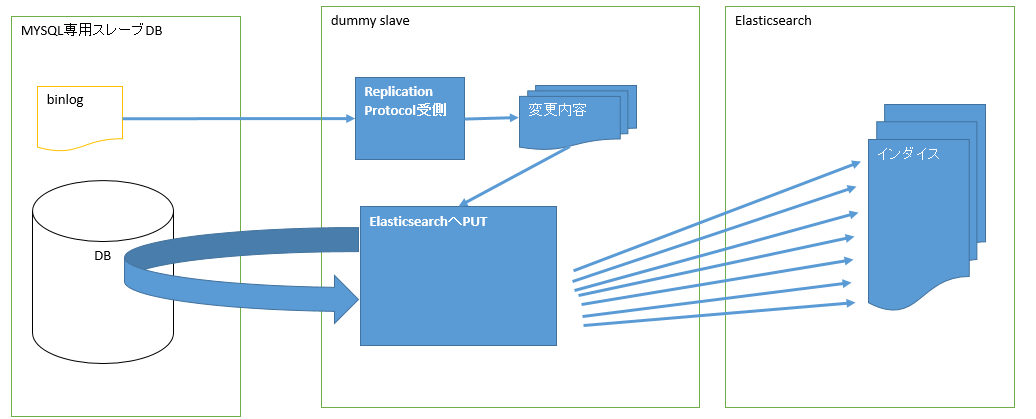
変更の検知
MySqlが変更したことを検知するために「Replication Protocol」を使って疑似的なslave db(以下「dummy slave」とする)を構築する。
dummy slaveは以下の二つに分かれる
・masterからBinLogを受け取って検知した情報を保存する。(1プロセス)→Replication Protocol受側
・情報からドキュメントを作成しElasticsearchにPUTする(複数プロセス)→Elasticsearch PUT
MySQL設定
・専用スレーブを用意する。データを限界のスピードでElasticsearchに叩き込むのでサービスに影響がでないようにするため。
・専用スレーブのbinlog_format = 'ROW';にする。STATEMENTやMIXEDでは変更を検知できてもSQLを解析する必要があるし、現実的ではない。
Replication Protocol受側で行う仕事
・Replication Protocolを受けるプログラムを書くのはとても大変なので「Replication Protocol PHP」「Replication Protocol C」などで検索してライブラリを見つける。
・binlogが流れてくる量はとても多いので、db,table,eventを絞ること。
・イベントをファイルやメッセージqueなどに出力する。
・自動で再接続する必要がある。binlogの接続はsocketを開きっぱなしでデータが流れ込む。このため接続がよく切れてしまう。タイミングとしてはDB負荷が高い時に発生する。
・自動再接続の時に取得済みポジションより前のポジションで接続し直すこと
・・MySQLが落ちた場合はその時発生したポジションがなくなってしまう。(クラッシュリカバリが働くのか?)
・この処理のプロセス・スレッドでElasticsearchにPUTしないこと。binlogの処理が追い付かなくなってリアルタイム性がなくなる。
リソースを絞り込む
「Replication Protocol受側で行う仕事」、「ElasticsearchへPUT」のどちらで行ってもよい
ドキュメントを構成するテーブルが更新されたら、その根元の主キーを特定、取得する。
以下の概念データモデル画像「table_F」が更新された場合その根元(強実体)「table_A」の主キーを取得する。
更新テーブルだけを取得してElasticsearchのドキュメントを更新する場合、更新コストがとても高く複雑になるのであきらめる。
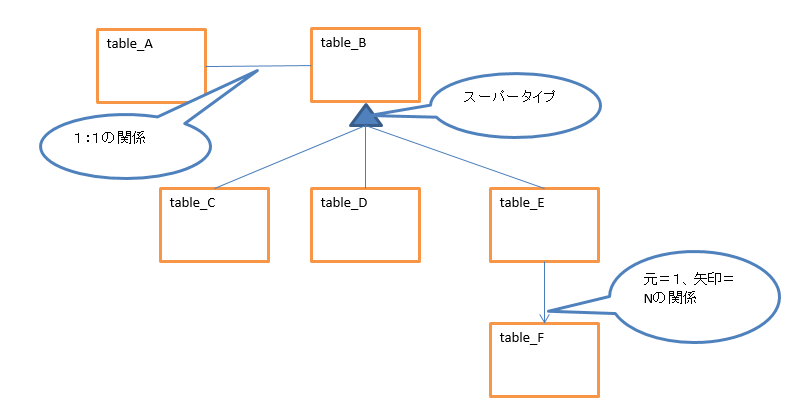
(概念データモデルの表記はIPA)
マスタ tableのようなデータを更新した場合は多くのデータが更新されてしまうので、根元のid数が多くなってしまう。
これはしょうがないのであきらめる。システムにもよるが更新頻度が少ないのでそんなに気ならない。
もしくは、マスタ tableの先の値を保管しないようにして、DBアクセスを利用できないか検討する。
ElasticsearchへPUT
・上記で「根元の主キー」が特定されているので、その根元に関係するドキュメントを構築して、Elasticsearchの「_id」を生成する。「_id」は確実に重複しない&そのidは何度でも生成可能であること(冪等性を使ってドキュメントの更新をするため)。例えば、会員番号01234がありこの番号は「会員」ドキュメントでは重複されないことが保証されている場合、idは「member_01234」とする。こうすることで01234に関係するテーブルが更新されても同じIDで叩き込めるため更新コストが低くなる。Elasticsearchのauto idは使えない。(もしauto idを使った場合は検索→id特定→更新になるのでコストが高い)
・「根元の主キー」は、まとめて受け取ること(たとえば1秒間に発生したイベント)
・受け取ったIDをまとめてSELECTすること
・まとめて処理受け取らないと処理が追い付かなくなってリアルタイム性がなくなる。
・同じイベントの固まりで「根元の主キー」が同じものは一つにする
・取得できたらElasticsearchへPUT
・取得できなかったらElasticsearchへDELETE
とにかく冪等性!
平行性の問題
ElasticsearchへPUT/DELETEするとき、速度の問題から平行で処理を行うので順番が狂ってしまう。
たとえば、「member_01234」がほとんど同じ時間に「作成→更新→削除→作成」が行われたときにイベントの種類を気にしてElasticsearchにDeleteを投ると最終的には「member_01234」が存在するはずなのにElasticsearchから消えてしまう。
解決方法として、
・イベントの種類は問わないで根元のIDを取得することに注目する
・取得できたらPUTをElasticsearchに投げる
・取得できなかったらDELETEをElasticsearchに投げる
これだけで入れ違いによるデータの不整合発生確率が低くなる
平行性のそもそも・・・
「削除→作成」の処理がトランザクション中にまとまっていることがほとんどで、その場合は「MySQL上”作成”の状態でdummy slaveへイベントが発生する」ので問題が無い(binlogの仕組み上そうなる)。別トランザクションで削除、作成、更新が行われる場合は問題なので「なんだか変なシステム」である可能性がある。CURDでの確認ができてないかもね。
DBの設計が幼いと・・
強実体、弱実体で関係する項目の持ち方を間違えるとリソースを取得するSQLが重くなってしまう。1:Nなら自然になるが、1:1の場合は意識して設計しないと後で大変になる。
ようは・・弱実体から強実体を探さなければならない場合。弱実態の主キーを強実体に保存していると、強実体に余計なインデックスを作らなきゃならん。それにインデックスは無いことがほとんどなのでとてもきつい。
最初の取り込みは?
根元のIDをまとめて取り出して、上記の処理に食わせてあげればいい。食ってる最中も変更がどんどん流れてくるので、冪等性でちゃんと最新になる。
ALTER TABLEは?
属性追加やインデックスの変更程度のALTER TABLEが流れても特に問題なかった。削除はドキュメントの生成にかかわらなければ問題ないはず。
はまったポイント
・協調動作(マルチプロセス、マルチスレッド)の方式はよく検討した方がいい。
・MySQL、Elasticsearchが異常な状態によくなるので、自動で復旧するようにすること
・Elasticsearchにどのくらい負荷がかかっているか正しく検知して、PUTのタイミングを調整すること
・24時間365日動作するのでメモリーリークに気を付けること
・MySQLが落ちた時に認識しているポジションが無くなること。
・メモリを大量に消費するので、根本ID数を適当に絞るようにしないと落ちる
2020/06/30 追記 MySqlのbinlogが書き込まれたタイミングではSELECTでデータを取得することはできない。binlogとcommiteの関係と順番について。
Elasticsearch リアルタイムインデクシングが失敗する
極々まれに古いデータを取得することがある。
結果から書くと・・
1:binlogが「Binlog Network Stream」に吐かれるがまだコミットされていない(予想)
2:Elasticsearch インデックスが行われる
3:古いデータを読む
4:commite処理
5:DBだけ新しいデータになる
で・・調べてみた記録
調査
現象はmariaDBからMySql v8.0に変更したら発生し始めた。
確認プログラムを組んだらマレに現象を確認することができた。
設定値の違いを調べてたら
mariaDBはsync_binlog=0
MySqlはsync_binlog=1になっていた。
binlogがソケットを流れるタイミングとcommitedになるタイミングが思っていたのとちがうような気がする。![]()
Oracleだとログに書き込んだらcommitedだったような・・・![]()
binlogはredoログではないと思うけど。![]() よく知らないし・・・
よく知らないし・・・
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Mysqlソースコードを確認したい!(binlog回りの)
MySqlのソースを確認する
https://downloads.mysql.com/archives/community/
からSource Codeを落としてくる
今回はmysql-8.0.17.tar.gzを対象にみてみる。
google検索でsync_binlogを調べてみると、「グループコミット」って出てくる。
fsyncコマンドをたたいてるらしい。
https://blog.longest-road.com/contents/?p=987
こちらの記事がわかりやすかったです。![]()
コードをbinlog syncでgrepしたらでてくるんじゃないかな?と
grepしたら1件しかでてこないでてこない。
binlogでgrepしたら大量すぎる。
binlog sync 、binlog fsync 、binlog commitなどなど・・
とにかく調べまくったら、binlog commitででてくるbinlog.ccがそれっぽい。
mysql-8.0.17\sql\binlog.cc(8868,18) [SJIS]: /* Clone needs binlog commit order. */
みるとcommit_stage: ってある。
関数名はMYSQL_BIN_LOG::ordered_commit
![]()
Mysqlのコードの関数名はわかりやすい!
この関数のコメントをみてみる!
/**
Flush and commit the transaction.
This will execute an ordered flush and commit of all outstanding
transactions and is the main function for the binary log group
commit logic. The function performs the ordered commit in two
phases.
The first phase flushes the caches to the binary log and under
LOCK_log and marks all threads that were flushed as not pending.
The second phase executes under LOCK_commit and commits all
transactions in order.
The procedure is:
1. Queue ourselves for flushing.
2. Grab the log lock, which might result is blocking if the mutex is
already held by another thread.
3. If we were not committed while waiting for the lock
1. Fetch the queue
2. For each thread in the queue:
a. Attach to it
b. Flush the caches, saving any error code
3. Flush and sync (depending on the value of sync_binlog).
4. Signal that the binary log was updated
4. Release the log lock
5. Grab the commit lock
1. For each thread in the queue:
a. If there were no error when flushing and the transaction shall be
committed:
- Commit the transaction, saving the result of executing the commit.
6. Release the commit lock
7. Call purge, if any of the committed thread requested a purge.
8. Return with the saved error code
@todo The use of @c skip_commit is a hack that we use since the @c
TC_LOG Interface does not contain functions to handle
savepoints. Once the binary log is eliminated as a handlerton and
the @c TC_LOG interface is extended with savepoint handling, this
parameter can be removed.
@param thd Session to commit transaction for
@param all This is @c true if this is a real transaction commit, and
@c false otherwise.
@param skip_commit
This is @c true if the call to @c ha_commit_low should
be skipped (it is handled by the caller somehow) and @c
false otherwise (the normal case).
*/
これじゃないか??![]()
binlogとcommitの関係が分かった
不具合の原因
1:binlogが「Binlog Network Stream」に吐かれる(予想)
2:Elasticsearch インデックスが行われる
3:古いデータを読む
4:commite処理
5:新しいデータになる
と予想するので
commit_stage:の下にsleepでも入れて再現するか?お願いしてみた。
そうすると、再現したので・・・
解決方法は・・・GTIDの出番です。
gtidとはーーーにわかなのでよくわかりませんが。
行更新イベントが発生したサーバと連番みたいなものがイベントにくっ付いてきてイベントの発生順番とか時期みたいなものが分かるIDと認識してます。
なので・・
binlogからgtidを受け取ってそのgtid以降の番号が記録されていればOKとして
SELECT COUNT(*) AS count FROM mysql.gtid_executed WHERE source_uuid = :uuid AND interval_start <= :gtid1 AND interval_end >= :gtid2
こんなSQLをデータ取得まえにとって目的のgtidまで達してなければリトライする方法にしたらうまく稼働するようになった。
mysql.gtid以外にも取得できるオブジェクトがあったけど(忘れた)メモリ上の話でstorageの話ではなかったので使えなかった。