概要
文章をカテゴライズするモデルを作る。必要なものは1カテゴリ100個くらいの文章。
(100個くらいでもお!って感じになる)
ここではニュースや記事を分類するモデルを構築してみる。
応用すれば・・・
- 商品説明を学習して商品カテゴライズ
- ブログやツイートのカテゴライズ
- 星に頼らない「レビュー」の評価
- 作者ごとに文章を学習して、特定の人が書いた文章を検索する
などなど・・・
教師データ無し機械学習では精度が上がらない分野にマッチするかも。
文章分類をニューラルネットワークでやるメリット・デメリット
教師データ無しとくらべて・・・
メリット
本当は必要なのかもしれないけども事前処理はほぼいらない。
(学習で勝手に重みを変更してくれるので)
これ(https://qiita.com/mokoenator/items/c9f4c4fd926b5b62db2a )とちがい簡単。
細かなゴミ削除やTF-IDFのような処理がいらない。
シノニムの変換も不要。
デメリット
教師データを作成しなければならい。
データをどーーーんと置いておけば勝手にカテゴライズは・・・しないのです。
せっせとラベル(アノテーション)をつけてあげないとダメなんです。
環境
anaconda3と・・・・pip list 抜粋
tensorflow-gpu 1.12.0
mecab-python-windows 0.996.3
matplotlib 2.2.2
numpy 1.14.3
Keras 2.2.4
ipykernel 4.8.2
mecabを動かすために「mecab-0.996-64.exe」が必要、さらにインストール先「・・・MeCab\bin」のpathを通しておく
学習プログラム・ブロック
辞書作成→データ行列変換→モデルの作成→モデルの学習
辞書作成
教師データから辞書を作成する。
辞書と言ってもどの単語が辞書の何番目にありますよ~くらい。
データ行列変換
教師データと正解ラベルを行列に変換する。
列に対応するニューラルネットワークの入力が単語の出現回数になる
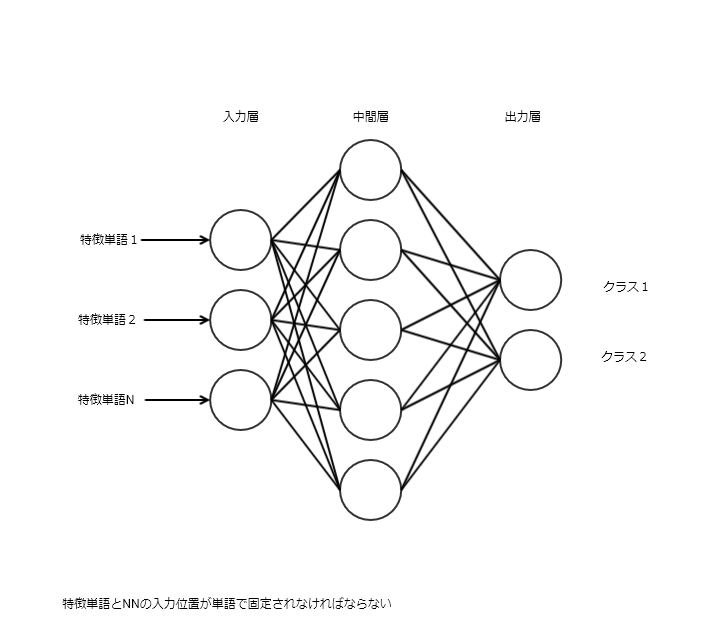
特徴単語1の入力には必ず「毎回同じ単語」の出現回数が入る。
例えば「リンゴは甘い果物」なら
リンゴ→特徴単語1(1回出現)
甘い→特徴単語2(1回出現)
果物→特徴単語3(1回出現)
このようになる。
上記辞書で単語の順番が固定化されるので、辞書順番に従って行列を作る。
モデルの作成
適当に作成する。
# モデル
model = Sequential()
model.add(Dense(128*3, input_shape=(max_words,)))
model.add(BatchNormalization())
model.add(BatchNormalization())
model.add(Dense(256))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Dense(num_classes))
model.add(Activation('softmax'))
model.summary()
これだけ。
モデルの各レイヤーは検索すると何してるかわかるので適当に変えれば精度があがるかもしれない。
このモデルは4時間くらい適当に層を追加したり、OUTの数を変えたりして一番よさそうなのを載せました。
教師データ
以下のような感じで教師データを集める。
data/
├ aaaa/
│ │ 00001.txt
│ │ 00002.txt
│ └ 0000n.txt
├ bbbb/
│ │ 00001.txt
│ │ 00002.txt
│ └ 0000n.txt
└ cccc/
│ 00001.txt
│ 00002.txt
└ 0000n.txt
この方法だと一つの記事に1つのカテゴリしかつけられない。
なのでtxtの1行目をJSONでカテゴリを複数指定できるようにする。
["economy"]
ここから記事
なので、aaaa,bbbb,ccccでフォルダ分けする理由はあまりない(大まかにカテゴライズするくらい)
学習するprogramの全体
# !/usr/bin/env python
# -*- coding: utf-8 -*-
# 文章をカテゴライズするモデルを作成
import json
import os
import random
from keras import optimizers
from keras.models import Sequential
from keras.layers import Dense,Activation,Dropout,BatchNormalization,AveragePooling1D
import MeCab
import numpy as np
from keras.callbacks import ModelCheckpoint
import pickle
import matplotlib.pyplot as plt
epochs=500
in_path = r"/data/"
t_dir=os.path.dirname(os.path.abspath(__file__))+ in_path
files_dir = os.listdir(t_dir)
classes = [f for f in files_dir if os.path.isdir(os.path.join(t_dir, f))]
m = MeCab.Tagger("-Ochasen")
keyword={}
dict=[]
key_index=0
text_datas=[]
if(False):#Falseにすると、データを固定するのでモデルを探すときにつかう
#教師データの作成
#テキストファイルを読み込みながら
#教師データとラベルを作成
for targetdiir in classes:
digtargets=os.listdir(t_dir+targetdiir)
for openfile in digtargets:
with open(t_dir+targetdiir+'/'+openfile, encoding="utf-8") as f:
#cont=f.read()
cont=''
fastread = True
for line in f:
if(fastread):
fastread=False
labels=json.loads(line)
else:
cont = cont + line
token=m.parseToNode(cont)
#教師データを集める
text_datas.append((cont, labels))
while token:
if token.feature.split(',')[0] in ['動詞','名詞']:
if token.surface not in keyword:
keyword[token.surface]=key_index
dict.append(token.surface)
key_index+=1
token = token.next
max_words=len(dict)
num_classes=len(classes)
#学習用データと検証用データを作成
x_train=np.empty((0,max_words), int)
y_train=np.empty((0,num_classes), int)
x_test=np.empty((0,max_words), int)
y_test=np.empty((0,num_classes), int)
for text_data in text_datas:
#特徴量に変換
tokutyou = np.zeros(len(dict))
label =np.zeros(num_classes)
token = m.parseToNode(text_data[0])
while token:
if token.feature.split(',')[0] in ['動詞','名詞']:
if token.surface in keyword:
tokutyou[dict.index(token.surface)]+=1
token = token.next
#labelをつける
for one_lable in text_data[1]:
label[classes.index( one_lable)]=1.0
num = random.randint(1, 10)
if(num in [1,2]):
#検証データ
x_test=np.append(x_test,[tokutyou],axis=0)
y_test=np.append(y_test, [label], axis=0)
else:
#学習データ
x_train=np.append(x_train,[tokutyou],axis=0)
y_train=np.append(y_train, [label], axis=0)
#データを固定するために保存
f = open('x_train.bin', 'wb')
pickle.dump(x_train, f)
f.close()
f = open('y_train.bin', 'wb')
pickle.dump(y_train, f)
f.close()
f = open('x_test.bin', 'wb')
pickle.dump(x_test, f)
f.close()
f = open('y_test.bin', 'wb')
pickle.dump(y_test, f)
f.close()
# 辞書を保存
f = open('toekn_word.bin', 'wb')
pickle.dump(dict, f)
f.close()
# class名を保存
f = open('classes.bin', 'wb')
pickle.dump(classes, f)
f.close()
else:
#固定したデータの利用
f = open("x_train.bin","rb")
x_train = pickle.load(f)
f.close()
f = open("y_train.bin", "rb")
y_train = pickle.load(f)
f.close()
f = open("x_test.bin", "rb")
x_test = pickle.load(f)
f.close()
f = open("y_test.bin", "rb")
y_test = pickle.load(f)
f.close()
f = open("toekn_word.bin", "rb")
dict = pickle.load(f)
f.close()
f = open("classes.bin", "rb")
classes = pickle.load(f)
f.close()
max_words=len(dict)
num_classes=len(classes)
# モデル
model = Sequential()
model.add(Dense(128*3, input_shape=(max_words,)))
model.add(BatchNormalization())
model.add(BatchNormalization())
model.add(Dense(256))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Dense(num_classes))
model.add(Activation('softmax'))
model.summary()
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
modelCheckpoint = ModelCheckpoint(filepath = 'token'+'ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5',
monitor='val_loss',
verbose=1,
save_best_only=True,
save_weights_only=False,
mode='min',
period=1)
history = model.fit(x_train, y_train,
batch_size=64,
epochs=epochs,
verbose=1,
validation_split=0.1,
validation_data=(x_test, y_test),
callbacks=[modelCheckpoint])
# グラフ化
plt.plot(range(1, epochs+1), history.history['val_loss'], label="val_loss")
plt.plot(range(1, epochs+1), history.history['loss'], label="loss")
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
↓めんどくさいのは教師データを学習のために入力できるようにする部分のこれ。
x_train=np.empty((0,max_words), int)
y_train=np.empty((0,num_classes), int)
x_test=np.empty((0,max_words), int)
y_test=np.empty((0,num_classes), int)
これを作成するまでが大変。
ちなみに、一回の推論で二つの以上を推論する方法がこれで正しいのかわからない。
複数のOUTPUT層をもつのはできるが、カテゴリが階層的な場合に有効な感じなので使えない気がする。
推論側のプログラム
# !/usr/bin/env python
# -*- coding: utf-8 -*-
from keras.models import load_model
import pickle
import MeCab
import numpy as np
model = load_model('ss_tokenep371-loss0.141-val_loss0.290.h5')
model.summary()
def categorize(sentence, threshold =0.5):
f = open("toekn_word.bin","rb")
dict = pickle.load(f)
f.close()
f = open("classes.bin","rb")
classes = pickle.load(f)
f.close()
keyword={}
for w in dict:
keyword[w]='x'
max_words=len(dict)
m = MeCab.Tagger("-Ochasen")
token = m.parseToNode(sentence)
tokutyou = np.zeros(max_words)
x_train=np.empty((0,max_words), int)
while token:
if token.feature.split(',')[0] in ['動詞', '名詞']:
if token.surface in keyword:
tokutyou[dict.index(token.surface)] += 1
token = token.next
x_train=np.append(x_train,[tokutyou],axis=0)
pred = model.predict(x_train)[0]
# 予測確率が高いトップ5を出力
top = 5
top_indices = pred.argsort()[-top:][::-1]
result = [(classes[i], pred[i]) for i in top_indices]
return result
print(categorize("""
ここにカテゴライズしてほしい記事を書く
"""))
プログラムを見ればわかる通り、知らない単語は入力されないのでエラーにはならない。
文章量がある程度多ければ知らない単語が重要だとしてもなんとなくカテゴライズしてくれるはず。
改良点
項目を分けて精度を上げたい
項目で重みが変わりそうな内容なら入力を同じ数だけふやしてあげればいい。
たとえば・・・
- メールならタイトル、本文、from
- 商品ならカテゴリ、説明文、メーカー名
モデルの入力である
model.add(Dense(128*3, input_shape=(max_words,)))
ここのmax_wordsを項目数分ふやして、データの入力を広げてあげる
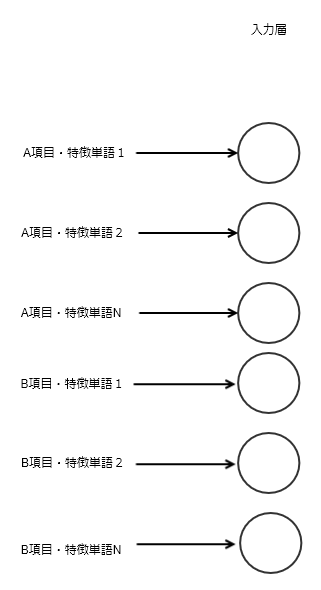
もしくは、functional APIで多くのINPUTを持つモデルを作ってあげればいい。
https://keras.io/ja/getting-started/functional-api-guide/
をみるか
「入力層を複数持つモデルの作り方」を検索する。
「Sequential」モデルを理解していることが前提です。
辞書作成をかえたら?
MeCabベースで特徴量を出しているが、これをngramに変更する又は、MeCab+ngram単語を混在させたらどうなるんだろう?
MeCabにない新しい単語にも追従できる?
今回のプログラムでは名詞と動詞だけで特徴量を作っているので精度的にどうなんだ?
と思う。
単語位置も考慮できないの?
ニューラルネットワークではちょっと厳しいのではないか?単語の出現回数が決まっていればなんとかなりそうだけど。LSTMかな?・・・
ngramベースに変更すると、なんとなく単語の位置も考慮した特徴量になるので・・もしかしたらいけるかもしれない。
感想
プログラムを見直して、「keyword」変数の使い方が勿体ない。ちゃんと組めばよかった。
このプログラムだと文章の長さも影響してきそうなので0.0~1.0の正規化をすればよかった。
「この単語があるときは、こっち単語の重みがこうでぇ~」って複雑なif文が想像できる。
なにかの文章やデータにたいして、「XXについて述べているdocumentを探して、数をまとめて、集計して」なんてめんどくさい作業から解放される。