はじめに
どうもこんにちはもきお(@mokio_50)です。実務でスクレイピングやデータ分析に触れたので、なんかデータ取ってきて取得したものを分析してみたい欲にかられました。
そこでふと思ったのが、自分がこれまで投稿してきた記事の総閲覧数とかってパッとみる事できなくね?総閲覧数ってどのくらいなんだろう?と調べてみたくなりました。
なので今回は総閲覧数をPythonを使用し取得する実装を書き残しておきたいと思います。
実装方法
最初はスクレイピングしないと取得できないかなーと思っていましたが、調べてみるとQiitaさんが正式にAPI提供してくれているではありませんか!!ドキュメントも分かりやすく書かれています。さすがQiitaさん!
あとはこのAPIにリクエストを投げて、返ってきたjsonデータを可視化すれば良さそうです。Qiita API使用している良さそうな記事ないかなーと思っているとまさに自分がやりたい事を記事にしていただいてました。ありがてぇ。
今回はほぼほぼこの記事通りに実装させていただいてます。自分が追加で取得したいデータのみ追記しているという感じです。
アクセストークン取得
Qiita APIを使用して自分の記事のデータを取得するためには、アクセストークンが必要になるみたいです。
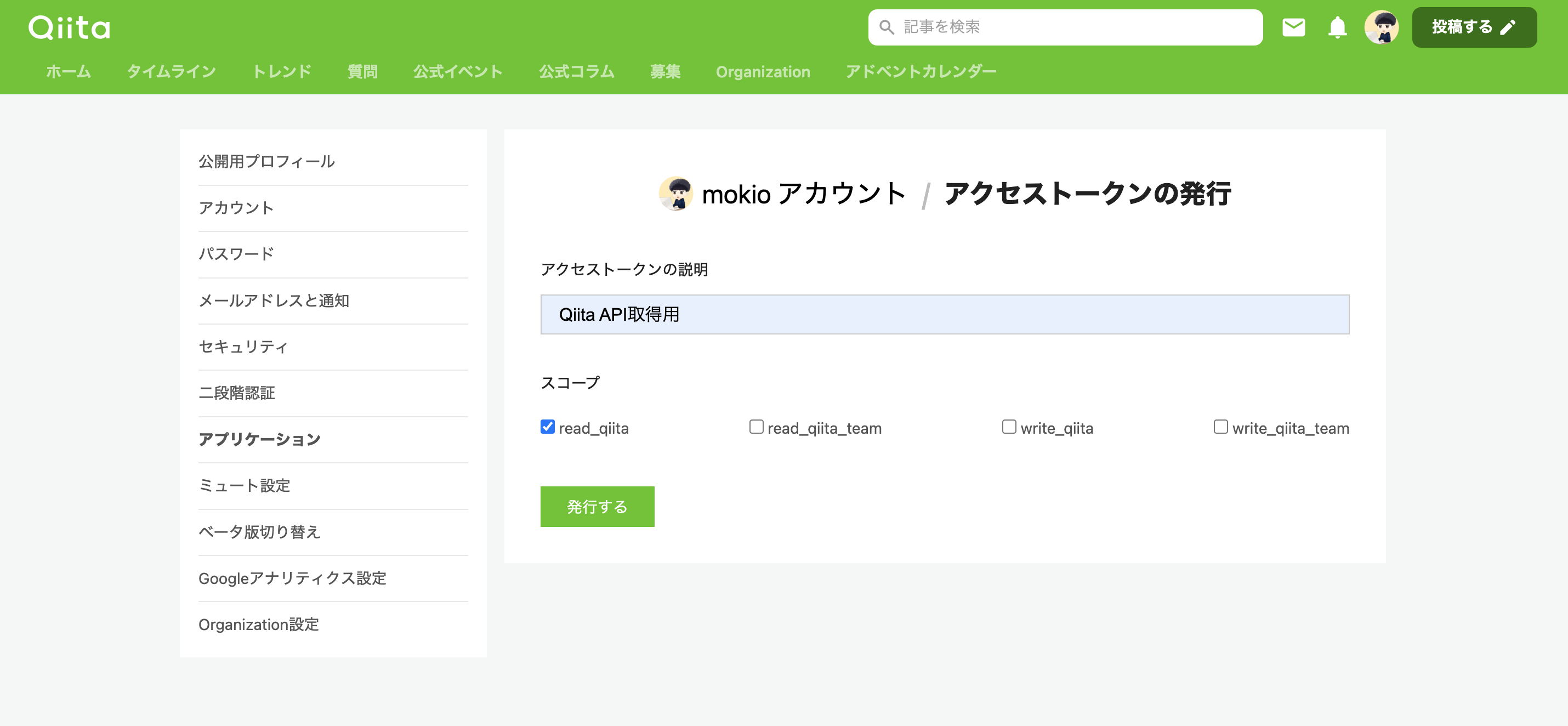
まずQiitaにアクセスし、自身のアイコンをクリック→設定→アプリケーションを選択

「新しくアクセストークンを発行する」をクリック

今回は情報を取得するだけなので、read_qiitaを選択しました。アクセストークンの説明は何でもいいので適当に書いて発行するをクリック笑
ちなみにwrite_qiitaを選択して発行したアクセストークンを使用すれば、APIリクエストによって遠隔でQiitaに記事を投稿できたりもするみたいです。上手くやれば記事投稿の自動化とかもできそうですね笑
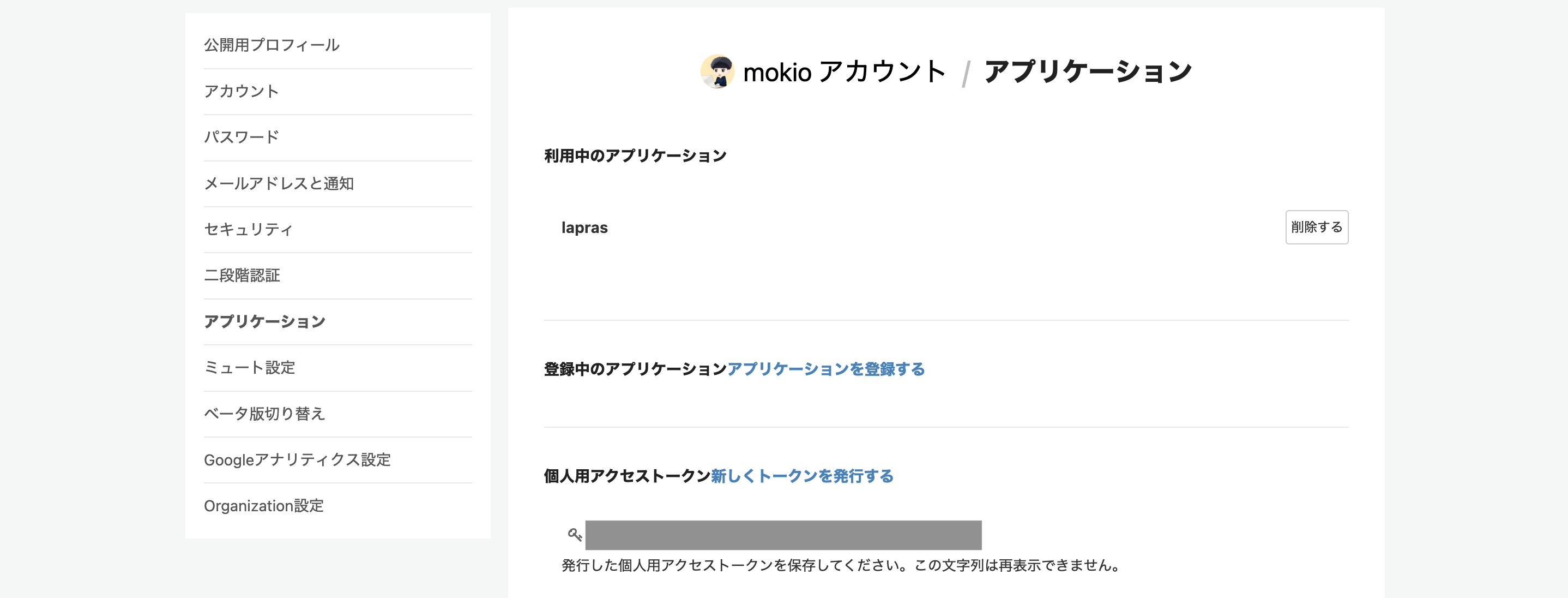
無事アクセストークンが発行されました!(画像グレー部分)
実装
準備ができたら早速実装に入ります。pythonのファイル作ってターミナルで実行しても良かったんですが見やすさを考え今回自分はJupyter Notebookを使用しました。実装コードは以下。基本引用させてもらっており、ストック数やいいねの平均いいね数などは個人的に興味があった点、ちょっと注意したほうが良い点を追記しております。
import requests
import json
import math
USER_ID = 'mokio(自身のユーザー名)'
PER_PAGE = 20
allViews = 0
allLikes = 0
allStocks = 0
headers = {"content-type": "application/json", 'Authorization': 'Bearer 発行したアクセストークン'}
url = 'https://qiita.com/api/v2/users/' + USER_ID
res = requests.get(url, headers=headers)
json_qiita_info = res.json()
#投稿したQiita記事の数
items_count = json_qiita_info['items_count']
# Qiita APIは一回のリクエスト上限があるのでリクエスト数を分けるために定義
page = math.ceil(items_count / PER_PAGE)
print('|記事タイトル|いいね数|ストック数|View数|')
for i in range(page):
# リクエスト送ってそれぞれの記事の情報が含まれたjsonをぶち込む
url = 'https://qiita.com/api/v2/authenticated_user/items' + \
'?page=' + str(i + 1)
res = requests.get(url, headers=headers)
json_qiita_info = res.json()
for j in range(PER_PAGE):
try:
# IDをjsonから引っ張り出す
item_id = json_qiita_info[j]['id']
# リクエスト送って指定したIDの記事のView数が含まれたjsonをぶち込む
url = 'https://qiita.com/api/v2/items/' + str(item_id)
res = requests.get(url, headers=headers)
json_view = res.json()
# View数をjsonから引っ張り出す
page_view = json_view['page_views_count']
# 加算代入して総View数とする
allViews += page_view
# 総いいね数を取得
allLikes += json_qiita_info[j]['likes_count']
# 総ストック数を取得
allStocks += json_qiita_info[j]['stocks_count']
# タイトル、いいね数、ストック数、View数の順に表示
print('| ' + json_qiita_info[j]['title'] + ' | ' +
str(json_qiita_info[j]['likes_count']) + ' |' +
str(json_qiita_info[j]['stocks_count']) + ' |' +
str(page_view) + ' |')
except IndexError:
#1記事あたりの平均いいね数を取得
averageLikes = round(allLikes / items_count, 1)
#1記事あたりの平均ストック数を取得
averageStocks = round(allStocks / items_count, 1)
#平均いいね率を取得(いいね数/総閲覧数 *100)
engagementRate= round(allLikes / allViews * 100, 2)
print('View総計:' + str(allViews))
print('平均いいね数:' + str(averageLikes))
print('平均ストック数:' + str(averageStocks))
print('平均いいね率:' + str(engagementRate) + '%')
print('出力完了')
break
# 何も出力されない場合のみ以下を実行
#1記事あたりの平均いいね数を取得
averageLikes = round(allLikes / items_count, 1)
#1記事あたりの平均ストック数を取得
averageStocks = round(allStocks / items_count, 1)
#平均いいね率を取得(いいね数/総閲覧数 *100)
engagementRate= round(allLikes / allViews * 100, 2)
print('View総計:' + str(allViews))
print('平均いいね数:' + str(averageLikes))
print('平均ストック数:' + str(averageStocks))
print('平均いいね率:' + str(engagementRate) + '%')
print('正常出力完了')
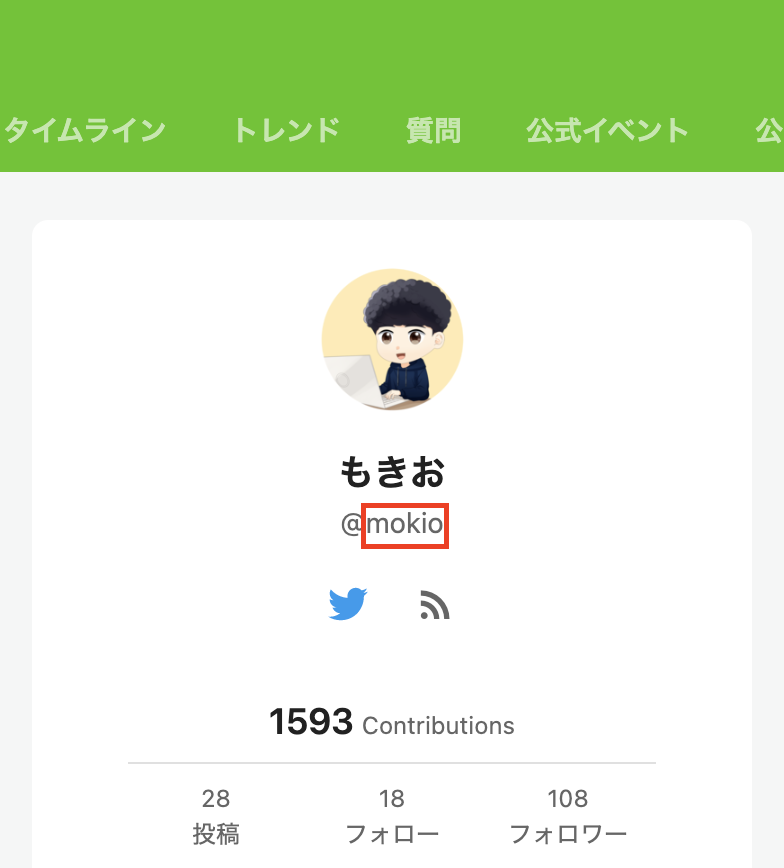
「自身のユーザー名」はマイページのプロフィールのこの赤枠で囲われている部分です。
注意点
今回の実装コードだと取得してきた記事を20ごとにループさせているため、取得した記事数が20,40,60とキリのいい記事数でない限りIndexError: list index out of rangeというエラーが発生します。よって例外処理を挟んでいるみたいです。
例えば取得してきた記事が38記事の場合、2回目のループ処理で18記事に対して20回ループ処理を行うため、19,20回目のループでは記事が取得できてないので範囲外のindexを指定してますよということでエラーを発生させているみたいですね。
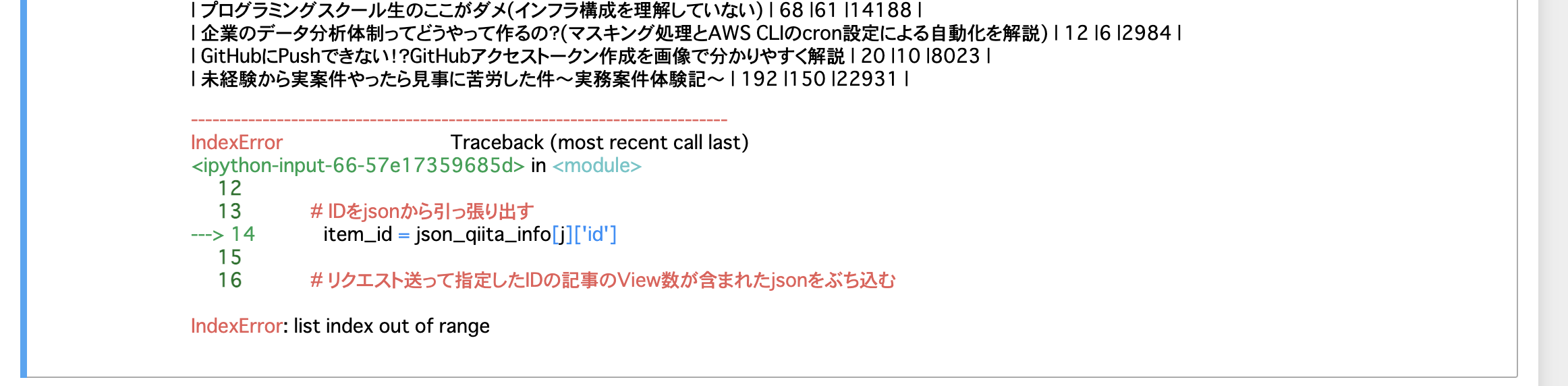
よって大体の場合はエラーが発生し、例外処理(except部分)が発動するので最後何も出力されない場合のみ、その後の記述を実行していただければなと思います。
実行結果
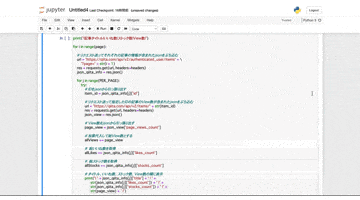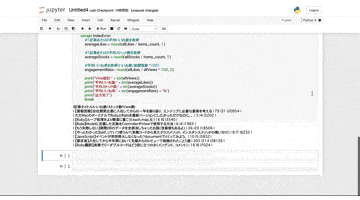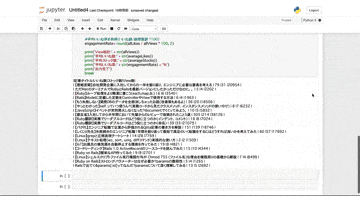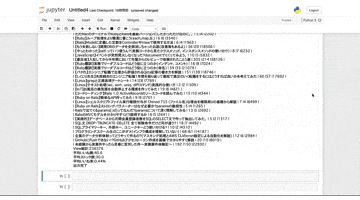

結果は2024年1月現在で以下のようになりました。
- 総閲覧数:377,190views
- 平均いいね数:44.9/記事
- 平均ストック数:34.2/記事
- 平均いいね率:0.39%
QiitaのSEOが凄すぎるというか、こんな自分の記事でもこれだけ見られているというのは驚愕の数値でした。平均いいね数と比較してストック数が下がってしまってますね。より記事の質も意識して書いていきたいと思います。
平均いいね率は0.39%と大体200回閲覧されてやっと一回いいねしていただいてる感じでした。やはり余程良いなと思った記事でないといいねするまでに至らないということですね〜。
あとがき
いかがだったでしょうか?今回はQiita APIを使用して自分が書いた記事の総閲覧数をはじめ色々なデータを取得してみました。興味本位でやってみましたが、記事のおかげですんなりできたかなと思います。
自分のQiita記事を分析してみたいという方は是非試してみてはいかがでしょうか?
ご覧いただきありがとうございました!日常をTwitterでつぶやいております。
Twitter: mokio_50