はじめに
ここにもちょっと書いたのですが、NPI(Neural Programmer-Interpreters) という仕組みがあります。NPIはDeepLearningで「プログラムの実行」を学習させようという試みです。「プログラムの実行」方法を人間がプログラム言語で組み立てるのではなく、「プログラムの実行」をNPIが事例をみて学習するというのが醍醐味かなと思います。
論文中では、「足し算の筆算」「数値のソート」「車の画像を正面に向ける操作」を一つのNPIで実装したということなので、今回はまず「足し算の筆算」を概ね論文の通りに実装することを目指します。
NPIの仕組みの簡単な説明
各モジュール
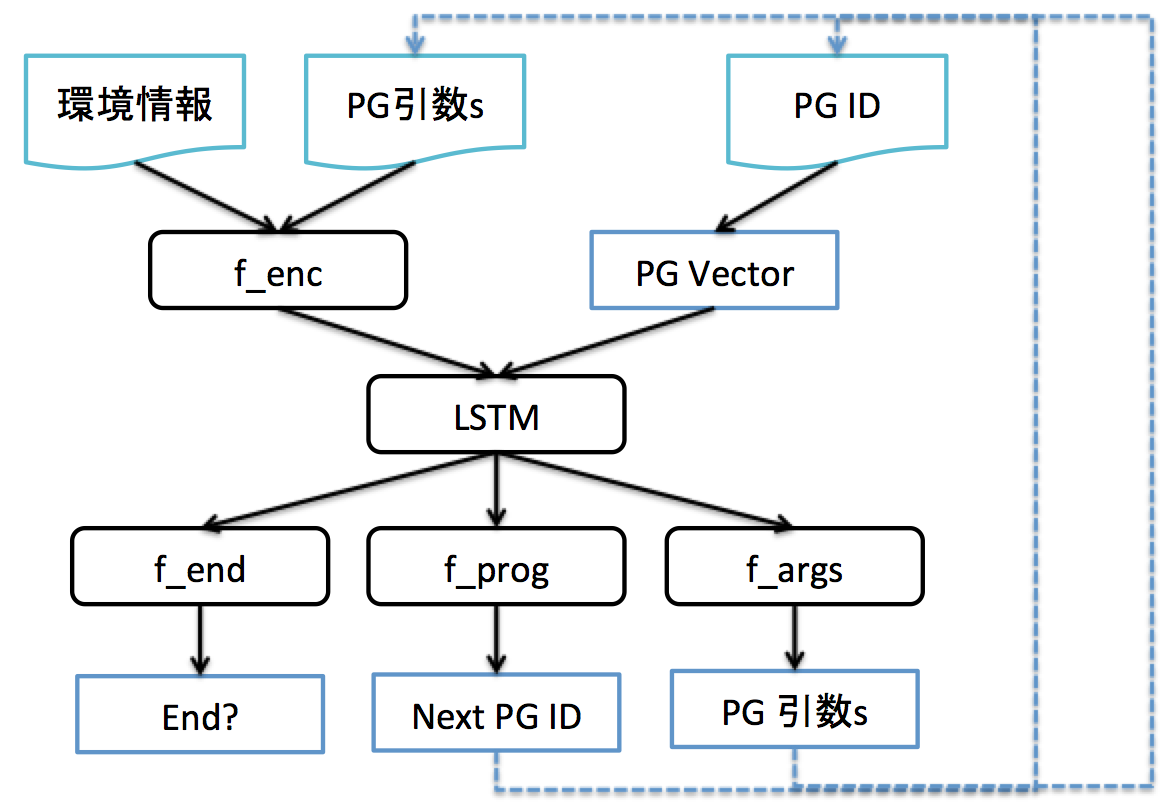
NPIの内部構造を上記の図を使って簡単に説明します。
- 環境情報: 問題のドメインに特化した環境情報を表す部分。「足し算」の問題なら「ポインタが指し示す位置の文字たち」なるし、「車の画像を・・・」の問題なら「車の画像」などになる。
- PG引数s: NPIのプログラムは引数を取るという仕様になっているのでその引数を表す。今回は「引数の数は3つで固定」「引数は整数」となっている。
- f_enc: 「環境情報」「PG引数」を入力にして、何かを出力する関数。今回はNeuralNetwork(以降 NN)で表現。NPIはこの部分を各問題用に用意することで様々なプログラムの実行を可能にしたいようだ。足し算ならば「足し算的に便利な情報を出力する何か」、「車の画像を・・・」ならば「画像→CNNで特徴抽出した何か」などになる。
- PG ID: ProgramのID。 NPIはProgramがProgramを呼び出すことができる仕様になっている。このPG IDが現在実行中のPGを表す。
- PG Vector: PG ID から Vector(固定長) に変換されたもの。おそらく、PG数が増えてもCoreな構造に影響を与えないようにするためかと思う。Embeddingのような感じ。
- LSTM: f_enc出力 や PG Vector を入力にし、PGの実行のCoreな部分?と位置付けられている部分かと思う。今回は LSTM(256)(relu) * 2 という構成。
- f_end -> End?: 実行中のProgramが returnして親プログラムに戻るか、を決定する部分。
- f_prog -> Next PG ID: 他のProgramを呼び出す場合のPG IDを決定する部分。
- f_args -> PG引数s: 他のProgramを呼び出す場合の引数を決定する部分。
足し算の実行イメージ

例えば足し算だと、 環境として「画面に文字が描かれている」「ポインタが各行に1つあり、そこのみを読み書きできる」となります。PGの種類は「ADD」「ADD1」「WRITE」「CARRY」「PTR-MOVE」「LSHIFT」「RSHIFT」があります。
今回のPGは「実際に環境に作用するもの(WRITE, PTR-MOVE)」と「他のPGを呼び出すもの(その他のADD,ADD1,CARRT,LR SHIFT)(これらは環境に作用しない)」で完全に分かれています(実装上の都合?)。例えば、足し算の実行だと上記のStepを踏むことになります。
Consoleでの実行の様子はこんな感じになります。この時は結構普通に間違えていますね。もう少し安定してくると概ね正解するようになります。ただ、現状ではなかなか学習が不安定です。
実装
実装にはKerasを使いました。Kerasは TheanoやTensorFlowをBackendにして、その詳細を隠してモジュール化を容易にしてくれるライブラリです。デフォルトではTheanoをBackendとして使います(単一CPUなどではTheanoの方が速いらしいですし)。今回もTheano Backendで使いました。
ネットワーク構造
試行錯誤の結果下記のようになりました。
こんな感じでちょっと込み入ったネットワークも割りと簡単にかけます。
コードではこんな感じです

構造の試行錯誤
「整数」をどう表現するか
「PG引数」は論文では Integer と書かれていました。例えば WRITE命令で何を実際に書き込むかをこの引数で表します。最初は、1NodeのFloatで表そうと思ってやっていましたが、なんだか無理っぽい。。
なので、今回は「0〜9の整数」として10個のone-hotなVectorで表すことにしました(今回はこれでOKだが、もっと広い範囲の整数を扱うなら辛いだろう)。こういうのはどういうのがベストプラクティスなのだろうか。。
LSTMを return_sequences=TrueにするかFalseにするか
LSTMは入力のTensorが (batch_size, input_length, in_data_length) というShapeになります。
出力は
-
return_sequences=Trueならば(batch_size, input_length, out_data_length) -
return_sequences=Falseならば(batch_size, out_data_length)
というShapeになります。
今回は常にbatch_size=1, input_length=1 で使います。
なので、LSTMを2段重ねるときは、
- LSTM1(return_sequence=True) : (1, 1, IN_SIZE)->(1, 1, 256)
- LSTM2(return_sequence=False): (1, 1, 256)->(1, 256)
とすると自然な感じなのですが、LSTM1をreturn_sequence=True にすると、その上の f_enc などがすぐに nan になってしまい、学習できませんでした(何故だろう)。
そこで
- LSTM1(return_sequence=False) : (1, 1, IN_SIZE)->(1, 256)
- RepeatVector(1): (1, 256) -> (1, 1, 256)
- LSTM2(return_sequence=False): (1, 1, 256)->(1, 256)
という形にしたらその問題が解消されました。
学習
学習もだいぶ苦労しました。
最終的には4〜5桁の足し算を99%以上正解するようにするのにMacのCPUで30分〜1時間弱くらいでできるようになりました。今回の学習のポイントをちょっと書いておきます。
学習データの準備
今回は問題は足し算なので生成は簡単ですが、それを「解くための手順」も教師データとして生成しないといけません。今回の命令セットで与えられた足し算を解く「先生プログラム」をまず作って、学習データを準備しました。
学習する問題は簡単なものから難しいものにしていく
問題の種類を、「1桁の繰り上げなしの足し算」「1桁の繰り上げあり」「1桁の足し算全て」「2桁」「3桁」「色々なパターン」というように徐々に難しくしていくと速く学習できます。実際最初から難しい問題をやらせてもなかなか進行しません。
今回は、最後の全パターン以外では、80%程度正解するようになったら、次のステップに進むようにしています。これも50%とかで進んでしまうと、その後の学習が躓いたりしてしまうのです(!)。面白いですね。逆に100%になるまで待つのは悪いことではないのですが、余計時間がかかりますし、その後の学習も特に速いということはない感じです。
f_encの学習と固定
今回何が間違えやすいかというと、どこかの桁の1桁の足し算です。 3+4=8 とかしばしばやってしまいます。
そこで f_enc はこのネットワークに入れる前に「事前学習」させておきます。具体的には「本番と同じ入力」から「数字の出力層」を付けて足し算の問題をやらせました。そうするとなかなか収束が速くなって良かったです。
ただ、後半に行くとどうしても全く学習が進まなくなりました。
そこで、「事前学習」させたあと、重みを固定(f_enc.trainable = Falseにする)してから学習させると一気に学習が安定していきました。今回はこれが決定的でした。
実際、環境別に学習済みのモデルを用いる(画像などの時は特に)ことは想定されることなので、これはありかなと思います。
結果
概ね99%近く正解するようになりましたが、未だに100%にはなってないです。既知の問題に対しては100%にできるのですが、適当に未知の問題をやらせるとまだまだ間違う時があります。
初期の頃、学習能力が不足気味で(と感じて)不要にネットワークレイヤーが増えている感があるので過学習気味なのかもしれません。もう少しスリムにしてあげたら治るかな?
ソースコード
参考まで https://github.com/mokemokechicken/keras_npi
さいごに
今回のNPI実装はまだまだ改善の余地がありますし、NPI自体もまだまだ工夫する余地があるのではないかと思いました。でも、こんな感じで他人の作業の様子をみて学習していくAIとかできたら胸熱だなぁ。
掛け算とか方程式とか解けるようになるのかな、とかその辺もできればやってみたいです。
あと今回初めてKerasを使いましたがとても便利でした。今後も愛用していこうと思います。