(2019.2.18更新) リポジトリ登録の際のレビューで指摘のあったパッケージ名をMolecularGraph.jlに変更し、URLも変更になりました。
創薬 Advent Calendar 2018の22日目の記事です。
今年10月から、私が以前Pythonで開発したChorusというケモインフォマティクスのツールキットのJulia移植に取り組んでいます(趣味で)。MolecularGraph.jlという名前でGitHubに公開しています。
Chorus
https://github.com/mojaie/chorus
MolecularGraph.jl
https://github.com/mojaie/MolecularGraph.jl
単純な移植の予定だったのですが、移植元のライブラリに比べてかなり機能が増えてきたので、今後はこちらをメインに開発していきたいと思っています。
本記事はMolecularGraph.jlの簡単な紹介と、PythonからJuliaにパッケージ移植した際の開発環境や、言語仕様の違いについての所感などです。
MolecularGraph.jlデモ
GitHubにいくつかnotebookのデモを置いています。
https://github.com/mojaie/MolecularGraph.jl/tree/master/notebook
まだJuliaのパッケージリポジトリには置いていません。近々リリース予定です。
今のところ、SDFileとSMILESの取り込み、SVGでの構造式描画、SMARTSクエリによる部分構造検索、官能基認識あたりまで実装しています。
構造式描画
Jupyter notebookで構造式を書くコードは以下のような感じです。
mol = sdftomol(open(MOL_FILE_PATH))) # ファイル読み込み
mol_svg = drawsvg!(mol, 400, 400) # width=400px, height=400px
display("image/svg+xml", mol_svg) # SVG表示
SVGなので割と小さいものから大きいものまで綺麗に出力できます。SMILES用の2D座標生成機能はまだ実装中です。







部分構造検索
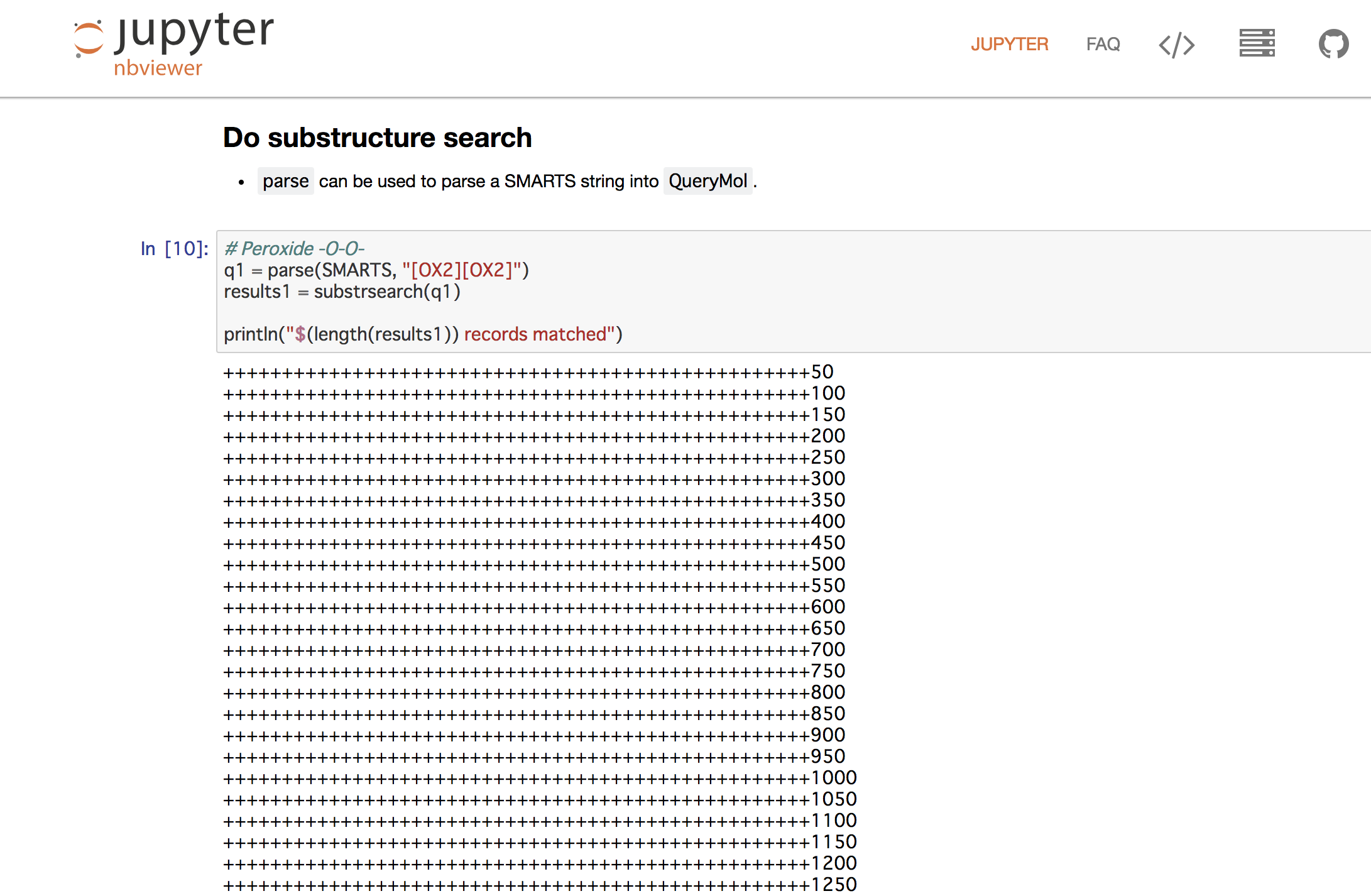
以下、コード例です。SMARTSが使えます。
query = parse(SMARTS, "[OX2][OX2]")
cnt = 0
for mol in MOLECULES # データベース(molオブジェクトの配列)
if match_molquery(mol, query)
cnt += 1
print("@")
else
print("-")
end
end
println()
println("$(cnt) records matched")
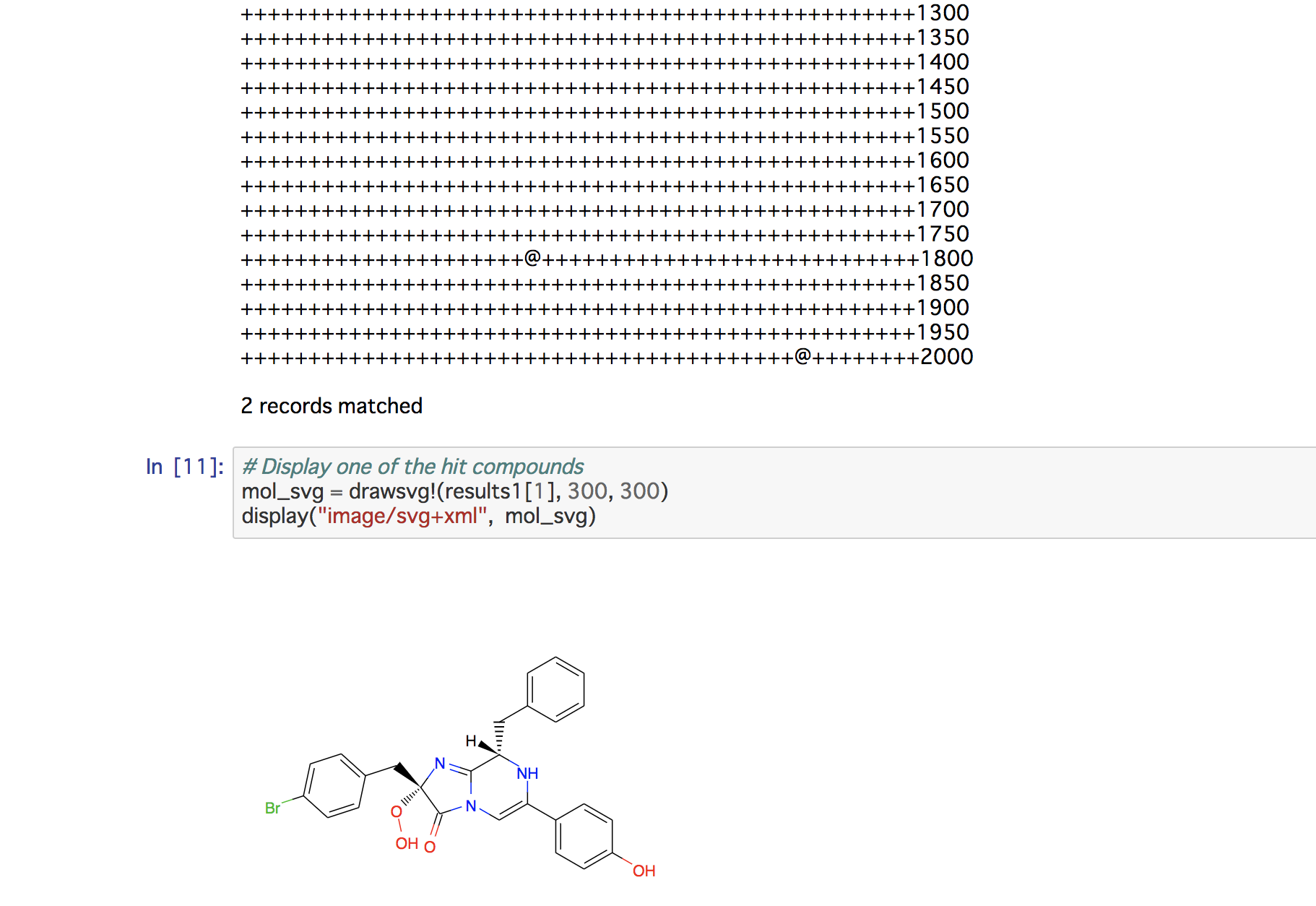
Notebookデモ(部分構造検索)
https://nbviewer.jupyter.org/github/mojaie/MolecularGraph.jl/blob/master/notebook/substructureSearch.ipynb
官能基検出
オントロジーベースの官能基検出を実装しています。官能基の定義はYAMLファイルなので自由にカスタマイズ可能です。
Notebookデモ(官能基検出)
https://nbviewer.jupyter.org/github/mojaie/MolecularGraph.jl/blob/master/notebook/functionalGroupAnalysis.ipynb

開発環境
- Julia 1.0.2
- Atom 1.33.0
- Mac OS X 10.13
Juliaには、Python同様、コマンドラインで動くインタプリタ環境(REPL)があります。Juliaに特徴的なのが、パッケージマネージャーがインタプリタ環境に一体化している点です。Juliaを起動し]を入力するとパッケージマネージャーが開きます。
Juliaカーネルを設定することで、Jupyter notebookでも利用することが可能です。パッケージマネージャーでadd IJuliaしてIJuliaをインストールします(パスを通すなど多少設定が必要です、詳しくはIJuliaのGitHub)。なお、Julia v1.0.0ではMacでLLVM関連のエラーがでてIJulia含む一部パッケージがインストールできない問題がありましたが、v1.0.1で対応されています。
Atomで開発していますが、2018年12月現在linterが使えないのがつらいです(linterのlanguage-juliaはあるが、あまり開発が活発でなく、Julia v1.0にまだ対応してない)。シンタックスハイライトは対応してますが、少々変なところがあります。
言語仕様についての情報は公式マニュアルが充実しているのでほぼこれで事足りる感じです(むしろそれ以外のインターネット上の情報が少ない)。Google検索の際はnot safe for work的な画像を避けるために検索ワードに工夫が必要です(juliaではなくjulialangで検索するなど)。
手軽さ
Pythonでは速く動くコードを書くには意識して内包表記、ビルトイン関数、Numpy、Cythonなどを必要に応じて使う必要があります。Juliaは適当に書いても速いです。
一方で、Juliaは動作は速いのですがコンパイルに時間がかかります。新しいライブラリを読み込むたび、あるいはライブラリに更新があった場合に自動的に再コンパイルを実施し、そのたび数秒のタイムラグがあるので、ライブラリ開発者にとってはPythonほど気軽にユニットテストできないのがつらいです。
PythonというよりはCythonを書いている感覚に近いと思います。最適化しようと思うと、Pythonが無意識のうちにやってくれている型変換やメモリ確保の一部を自分で意識しながら書くことになります。Cython同様、配列のbounds checkを省く高速化などが必要に応じて使えます。
もちろん、エンドユーザはこのようなことは気にせず、高速化の恩恵だけを得ることができるでしょう。
言語仕様
以下、言語仕様についてざっくりと
型
JuliaもPython同様ダックタイピングの言語ですが、Juliaは型が指定可能です。後述のメソッドやユーザ定義型(struct)を作成する際には型を指定します。
Pythonよりは型にシビアです。例えば、配列やDictなどは、オブジェクトを生成した際に中身に応じて自動的に型が決まります。
julia> a = [1,2,3]
3-element Array{Int64,1}:
1
2
3
julia> push!(a, 4.1)
ERROR: InexactError: Int64(Int64, 4.1)
上記コードの例では、配列aは生成時に中身がIntなのでArray{Int64,1}という型になっています。Intの配列にFloatを入れようとするとエラーになります。
JavaやC#などにあるジェネリック型が利用可能です。Juliaではパラメトリック型と呼びます。後述の多重ディスパッチという仕組みを利用する上で、結構多用します。
関数とメソッド
関数はfunctionで定義されます。Javascriptのようなアロー形式が許容されているので使い勝手が良いです。
julia> f = x -> x^2
# 3 (generic function with 1 method)
julia> f(4)
16
関数の引数に型を指定するとメソッドになります。
julia> function m(v::Int)
return v^2
end
m (generic function with 1 method)
julia> m(4)
16
julia> m(4.0)
ERROR: MethodError: no method matching m(::Float64)
関数の引数はなんでも良いですが、メソッドは指定された型の引数を要求します。
クラスは???
Pythonで言うところのclassはJuliaにはありません。代わりに構造体(struct)を使ってユーザ定義型を作成します。structはclassと異なりメソッドを持ちません。
julia> struct IntPair
a::Int
b::Int
end
julia> IntPair(1,2)
IntPair(1, 2)
メソッドはstructの外に作成します。
julia> function sum(p::IntPair)
return p.a + p.b
end
sum (generic function with 1 method)
julia> sum(IntPair(2,4))
6
多重ディスパッチ
Juliaでは同じ名前で型の違うメソッドを複数作ることが可能です。
julia> struct FloatPair
a::Float64
b::Float64
end
julia> function sum(p::FloatPair)
return p.a + p.b
end
sum (generic function with 2 methods)
julia> sum(FloatPair(2.0,4.0))
6.0
上記のコード例では、2つ目のsumを定義した時点で、sum (generic function with 2 methods)になっています。これで関数sumはInt型とFloat型それぞれの値に対して個別の処理を行うメソッドを持つことになります。このように同じ関数が引数の型によって異なる動作をする仕組みを多重ディスパッチと呼びます。
structは抽象型(abstract struct)を継承することができます。これにより、似たようなオブジェクトに共通の抽象型を継承させて、その抽象型を引数とするメソッドを作成することで、オブジェクト指向言語におけるポリモーフィズムのようなことを実現しています。
このような仕様の優れた点として、値(オブジェクト)と、値に対して操作を行う関数(メソッド)がはっきりと分離されているため、意識して副作用を扱うことができることが挙げられます。関数は自然と状態を持たない設計になり、値はそれ自身やその値を扱うべきでない関数から変更されないように保護されます。
また、Juliaには破壊的な操作を行う関数の名前の末尾に!をつけるというプラクティスがあります。例えばビルトイン関数で配列の中身を直接変更するようなものはpush!やpop!のような名前になっています。これも副作用を扱う上で良いプラクティスだと思います。