環境
- MacOSX 10.10.5 (NumexprとCythonはWindowsだと多分ダメです)
- Python 3.4.3
- NumPy 1.9.2
以下のコードは、2つの任意の配列を総当りで比較して、値が一致する要素のインデックスのペアのリストを取得する関数の例です。
from d_profile import profile
@profile
def example(arr1, arr2):
result = []
for i, e1 in enumerate(arr1):
for j, e2 in enumerate(arr2):
if e1 == e2:
result.append((i, j))
return result
if __name__ == "__main__":
arr1 = [i for i in range(100000) if i % 17 == 0]
arr2 = [i for i in range(100000) if i % 37 == 0]
print(example(arr1, arr2))
profileデコレータについては下記の記事参照
http://qiita.com/mojaie/items/e14c3db9f8fdec896f8a
Profile結果
<<<---
1600 function calls in 137.711 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 137.710 137.710 137.710 137.710 calc_performance.py:8(example)
1590 0.001 0.000 0.001 0.000 {method 'append' of 'list' objects}
1 0.000 0.000 0.000 0.000 pstats.py:62(__init__)
1 0.000 0.000 0.000 0.000 {built-in method print}
1 0.000 0.000 0.000 0.000 pstats.py:72(init)
1 0.000 0.000 0.000 0.000 pstats.py:91(load_stats)
(以下略)
--->>>
ナイーブな実装だと138秒かかります。
NumPy
NumPyを使うとこのようになります。
import numpy as np
@profile
def example_numpy(arr1, arr2):
c1 = np.array(arr1, dtype=int)
c2 = np.array(arr2, dtype=int)
c1 = c1[:, np.newaxis]
m = c2 == c1
result = []
for p in zip(*np.nonzero(m)):
result.append(p)
return result
Numexpr
Numexprは行列演算をコンパイルすることでNumpyをさらに高速化するものです。==, +, -などの基本的な演算子しか使用できませんが、ブロードキャスティングがかなり速くなります。
Numexprはpipでインストールできます。
pip3 install numexpr
Numexprを使うと
import numpy as np
import numexpr as ne
@profile
def example_numexpr(arr1, arr2):
c1 = np.array(arr1, dtype=int)
c2 = np.array(arr2, dtype=int)
c1 = c1[:, np.newaxis]
m = ne.evaluate("c2 == c1") # ここがNumexpr
result = []
for p in zip(*np.nonzero(m)):
result.append(p)
return result
Profile結果
<<<---
1918 function calls (1850 primitive calls) in 13.544 seconds
Ordered by: cumulative time
List reduced from 92 to 20 due to restriction <20>
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.007 0.007 13.543 13.543 calc_performance.py:30(example_numexpr)
1 0.000 0.000 11.071 11.071 fromnumeric.py:1380(nonzero)
1 11.071 11.071 11.071 11.071 {method 'nonzero' of 'numpy.ndarray' objects}
1 2.449 2.449 2.451 2.451 necompiler.py:688(evaluate)
4 0.013 0.003 0.013 0.003 {built-in method array}
1 0.002 0.002 0.002 0.002 necompiler.py:557(NumExpr)
(以下略)
--->>>
NumPy, Numexprを使うことで実行時間が13.5秒と当初のおよそ1/10になりました。
しかしながら、Profile結果をよく見てみると、行列の生成と比較にかかっている時間はせいぜい2.5秒くらいです(necompiler.py:688(evaluate))。計算時間の大半をnonzeroという関数が食っていますが、これは値が0(False)でない要素のインデックスをすべて取得するイテレーターです。
NumPyの弱いところ
NumPyの行列演算やブロードキャスティングは強力ですが、生成した行列からインデックスを取得するような操作(whereやnonzero)はそれほど速くありません。Profileしてみて明らかにこれらの関数がボトルネックになっているようであれば、Cythonで型指定をするとかなり高速化する可能性があります。
また、whileループの中で頻繁にコンテナの値を出し入れするようなアルゴリズム(ex.経路探索)もNumPyの恩恵が得られにくいですが、Cythonでコンパイルするだけでかなり速くなることがあります。
Cythonで速くなるもの
- for, whileなどのループ
- list
非常に遅いと言われているPythonのループですが、Cythonを使うとかなり速くなります。forはループインデックスをcdefで型指定すると速くなります。
listの代わりにC++標準のvectorが使えます。NumpyのArrayと同様に連続したメモリ領域を確保しているらしいので要素のルックアップが高速です。listと同様に検索と末尾のpush、popがO(1)です。もちろんvectorに格納するオブジェクトもcdefで型指定します。
Cythonで速くならないと思われるもの
- dict
- set
Pythonのdictとsetは高性能なのでCythonでもそのまま使いましょう(cdefも不要)。
Cythonで書きなおす
モジュール先頭のコンパイラディレクティブにprofile=Trueを入れるとPythonのプロファイルが有効になります。boundscheckとwraparoundをFalseにすると配列の要素へのアクセスが速くなりますが、Python特有の負の添字を使ったり、IndexErrorを発生させるような処理を行うと最悪クラッシュするので注意が必要です。
C++の標準ライブラリのvectorとpairを使用するので、後述のsetup.pyの設定が必要です。
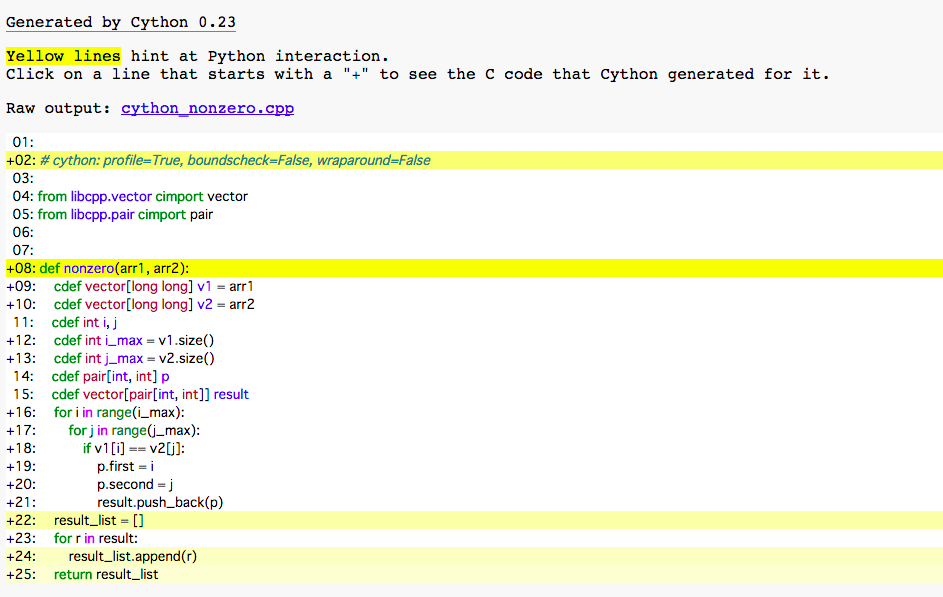
# cython: profile=True, boundscheck=False, wraparound=False
from libcpp.vector cimport vector
from libcpp.pair cimport pair
def nonzero(arr1, arr2):
# listをvectorに変換
cdef vector[long long] v1 = arr1
cdef vector[long long] v2 = arr2
cdef int i, j
cdef int i_max = v1.size()
cdef int j_max = v2.size()
cdef pair[int, int] p
cdef vector[pair[int, int]] result
for i in range(i_max):
for j in range(j_max):
if v1[i] == v2[j]:
p.first = i
p.second = j
result.push_back(p)
# vectorをlistに変換
# pairは暗黙的にtupleになる
return list(result)
Profile結果
<<<---
1604 function calls in 1.602 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 1.602 1.602 calc_performance.py:42(example_cython)
1 0.000 0.000 1.602 1.602 {cython_nonzero.nonzero}
1 1.596 1.596 1.602 1.602 cython_nonzero.pyx:8(nonzero)
2 0.004 0.002 0.004 0.002 stringsource:49(__pyx_convert_vector_from_py_PY_LONG_LONG)
1590 0.001 0.000 0.001 0.000 stringsource:180(__pyx_convert_pair_to_py_int____int)
1 0.000 0.000 0.000 0.000 pstats.py:62(__init__)
(以下略)
--->>>
1.6秒。最初のコードの1/100くらいの速さになっています。
Cythonのsetup.pyファイルの作成例
from distutils.core import setup
from distutils.extension import Extension
from Cython.Distutils import build_ext
from Cython.Compiler import Options
Options.annotate = True
ext_modules = [Extension("module1", ["module1.pyx"], language="c++"),
Extension("module2", ["module2.pyx"], language="c++")]
setup(cmdclass={'build_ext': build_ext}, ext_modules=ext_modules)
Extensionの引数にlanguage="c++"を指定すると、C++のコードを生成しコンパイルします。vectorなど便利なC++の標準ライブラリが使えるようになります。
Options.annotate = Trueにするとコンパイルする際にCythonがどの行をCに変換したかがわかるhtmlファイルが生成されます。黄色が濃い部分はPythonのコードのままです。無色の行は完全にCのコードに変換されています。無色の行が多ければ良いというわけではありません。Profileしてみてボトルネックになっている部分が無色になっていることが重要です。
Boost::pythonは?
Cythonでボトルネックになっているループを型指定するだけでも必要かつ十分に高速化するので、さらにネイティブのC++で書きなおして著しく速くなるということはないでしょう。あくまでBoost::pythonは既存の膨大なC++のライブラリを活用するためのものだと思います。