はじめに
Amazon Kinesis Data Analytics が東京リージョンで利用可能になりました。
Apache Kafkaのマネージドサービスも発表されたこともあり、ストリーミングサービスの盛り上がりに焦ったので触ってみます。
Kinesis Data Analyticsとは?
- ストリーミングデータの分析/検索するサービス。
- リアルタイムにフィルターをかけることができるらしい。
- SQLで書けるらしい。
やってみる
定常的に流れてくるCloudwatch Logsに、Data Analyticsを使って、リアルタイムにフィルターをかけてみます。
今回はCwLogsに出力しているVPCFlowLogsを例にやってみます。
流れ
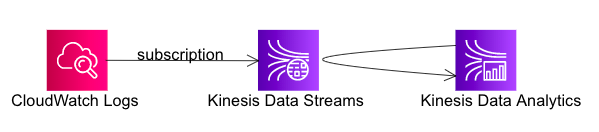
1. Kinesis Stream
-
VPCFlowLogsという名前で作成します。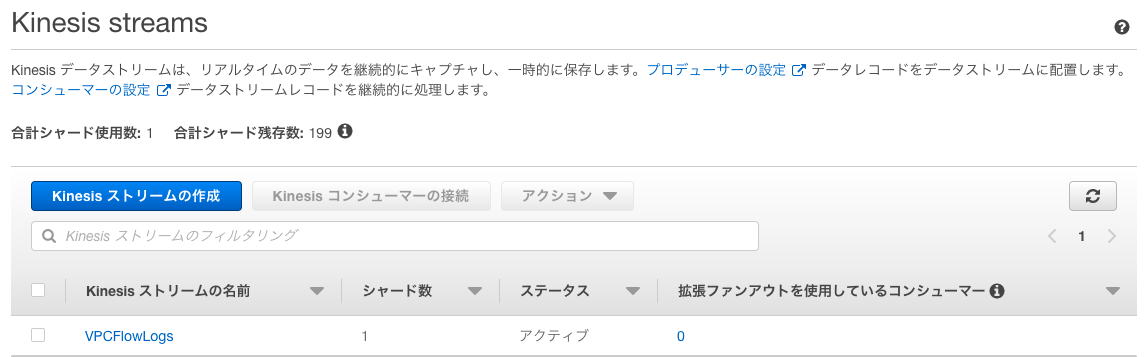
サブスクリプション
CloudWatch LogsをKinesis Streamに連携するには サブスクリプション という機能を使います。
マネージメントコンソールでは出来ないようなので、CLIを使います。
IAMRole作成
- Kinesisストリームにデータを置く権限をCWLogsに付与
% cat << EOF > TrustPolicyForCWL.json
> {
> "Statement": {
> "Effect": "Allow",
> "Principal": { "Service": "logs.ap-northeast-1.amazonaws.com" },
> "Action": "sts:AssumeRole"
> }
> }
> EOF
% aws iam create-role --role-name CWLtoKinesisRole --assume-role-policy-document file://./TrustPolicyForCWL.json
{
"Role": {
"AssumeRolePolicyDocument": {
"Statement": {
"Action": "sts:AssumeRole",
"Effect": "Allow",
"Principal": {
"Service": "logs.ap-northeast-1.amazonaws.com"
}
}
},
"RoleId": "AAAAAAAAAAAAAAAAAAA",
"CreateDate": "2019-06-04T13:35:24Z",
"RoleName": "CWLtoKinesisRole",
"Path": "/",
"Arn": "arn:aws:iam::123456789:role/CWLtoKinesisRole"
}
}
- PutPolicy
% cat PermissionsForCWL.json
{
"Statement": [
{
"Effect": "Allow",
"Action": "kinesis:PutRecord",
"Resource": "arn:aws:kinesis:ap-northeast-1:123456789:stream/VPCFlowLogs"
},
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::123456789:role/CWLtoKinesisRole"
}
]
}
% aws iam put-role-policy --role-name CWLtoKinesisRole --policy-name Permissions-Policy-For-CWL --policy-document file://~/PermissionsForCWL.json
- サブスクリプションフィルタ作成
% aws logs put-subscription-filter \
--log-group-name "/aws/vpcflowlogs/" \
--filter-name "VPCFlowLogsAllFilter" \
--filter-pattern "[version, account_id, interface_id, srcaddr != "-", dstaddr != "-", srcport != "-", dstport != "-", protocol, packets, bytes, start, end, action, log_status]" \
--destination-arn "arn:aws:kinesis:ap-northeast-1:123456789:stream/VPCFlowLogs" \
--role-arn "arn:aws:iam::123456789:role/CWLtoKinesisRole"
CwLogsの画面で確認すると、サブスクリプションが表示され、連携されているのがわかりますね。

kinesis streamに連携されているか、確認してみましょう。
% aws kinesis get-records --limit 10 --shard-iterator $(aws kinesis get-shard-iterator --stream-name VPCFlowLogs --shard-id shardId-000000000000 --shard-iterator-type TRIM_HORIZON | jq -r ."ShardIterator") | jq -r '.Records[].Data' | base64 -D | zcat
2. Kinesis Data Analytics
CwLogsとKinesis Streamの連携はできたので、続いてData Analyticsを作成します。
アプリケーション作成
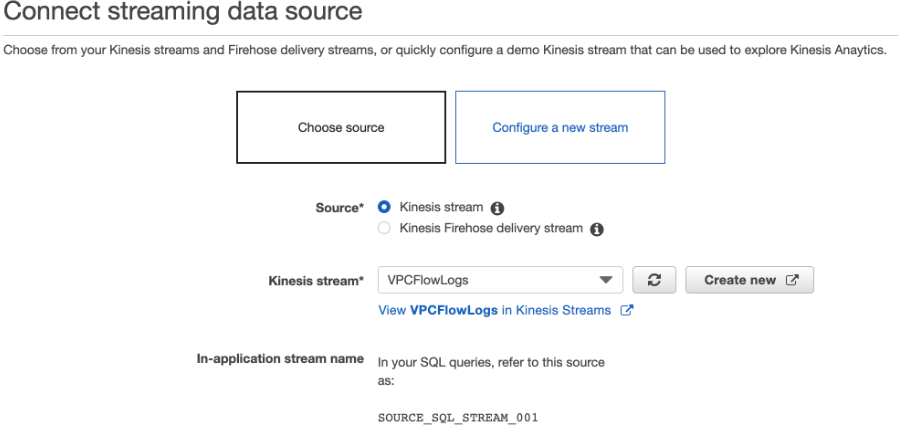
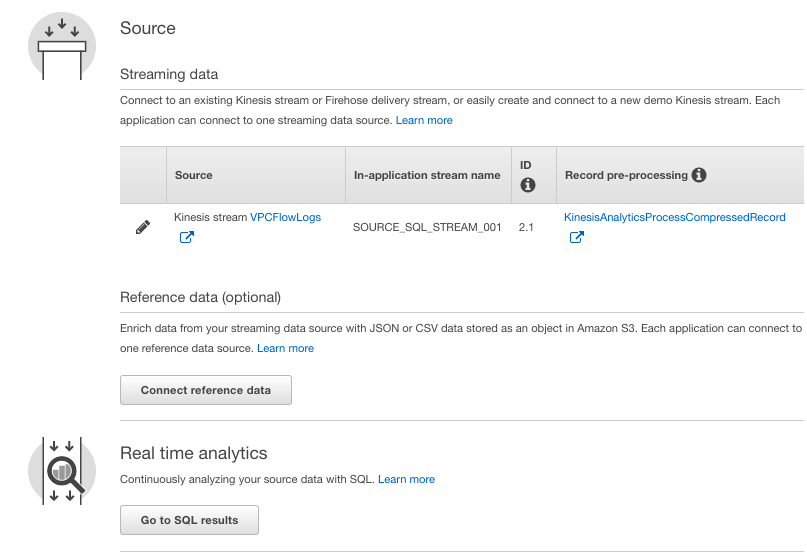
sourceで作成したkinesis streamを選択します。
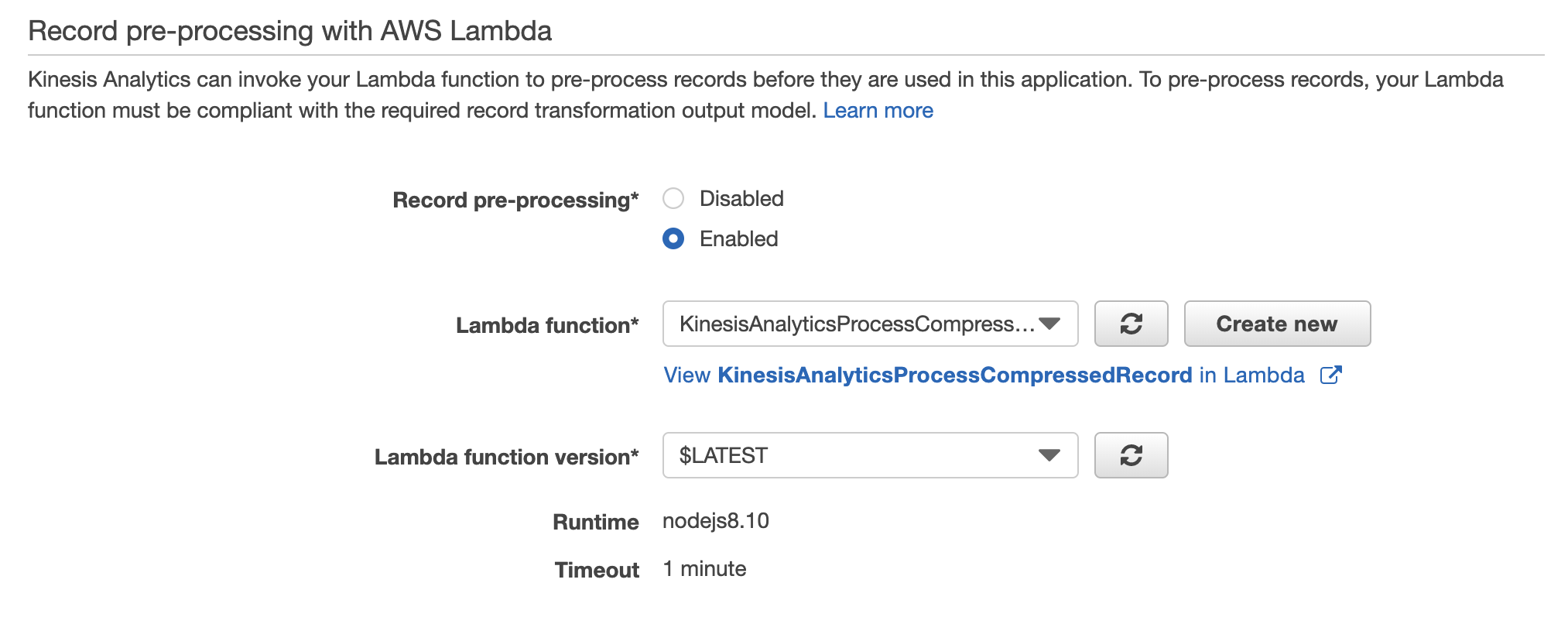
pre-processing Lambda function作成
Cwlogsのinputレコードは圧縮されてるので、解凍する必要があります。
pre-processing設定でAWS Lambdaを作成し、解凍してみましょう。
- Lambda functionの
create newを選択し、新規作成します。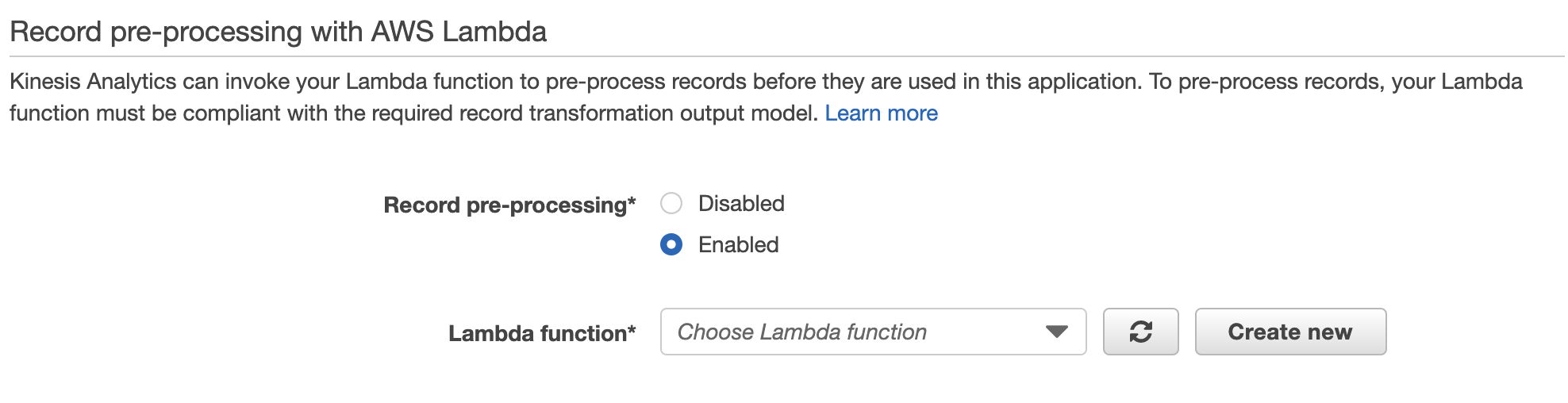
以前はblueprintがあったようなのですが、無くなっているのでこちらの記事を参考に作成します。
'use strict';
console.log('Loading function');
const zlib = require('zlib');
exports.handler = (event, context, callback) => {
let success = 0; // Number of valid entries found
let failure = 0; // Number of invalid entries found
/* Process the list of records */
const output = event.records.map((record) => {
/* Data is base64-encoded, so decode here */
const compressedData = Buffer.from(record.data, 'base64');
try {
const decompressedData = zlib.unzipSync(compressedData);
/* Encode decompressed JSON or CSV */
const result = (Buffer.from(decompressedData, 'utf8')).toString('base64');
success++;
return {
recordId: record.recordId,
result: 'Ok',
data: result,
};
} catch (err) {
failure++;
return {
recordId: record.recordId,
result: 'ProcessingFailed',
data: record.data,
};
}
});
console.log('Processing completed. Successful records ${success}, Failed records ${failure}.');
callback(null, {
records: output,
});
};
Discover schema実行すると、正しくパースされたデータが表示されましたね。
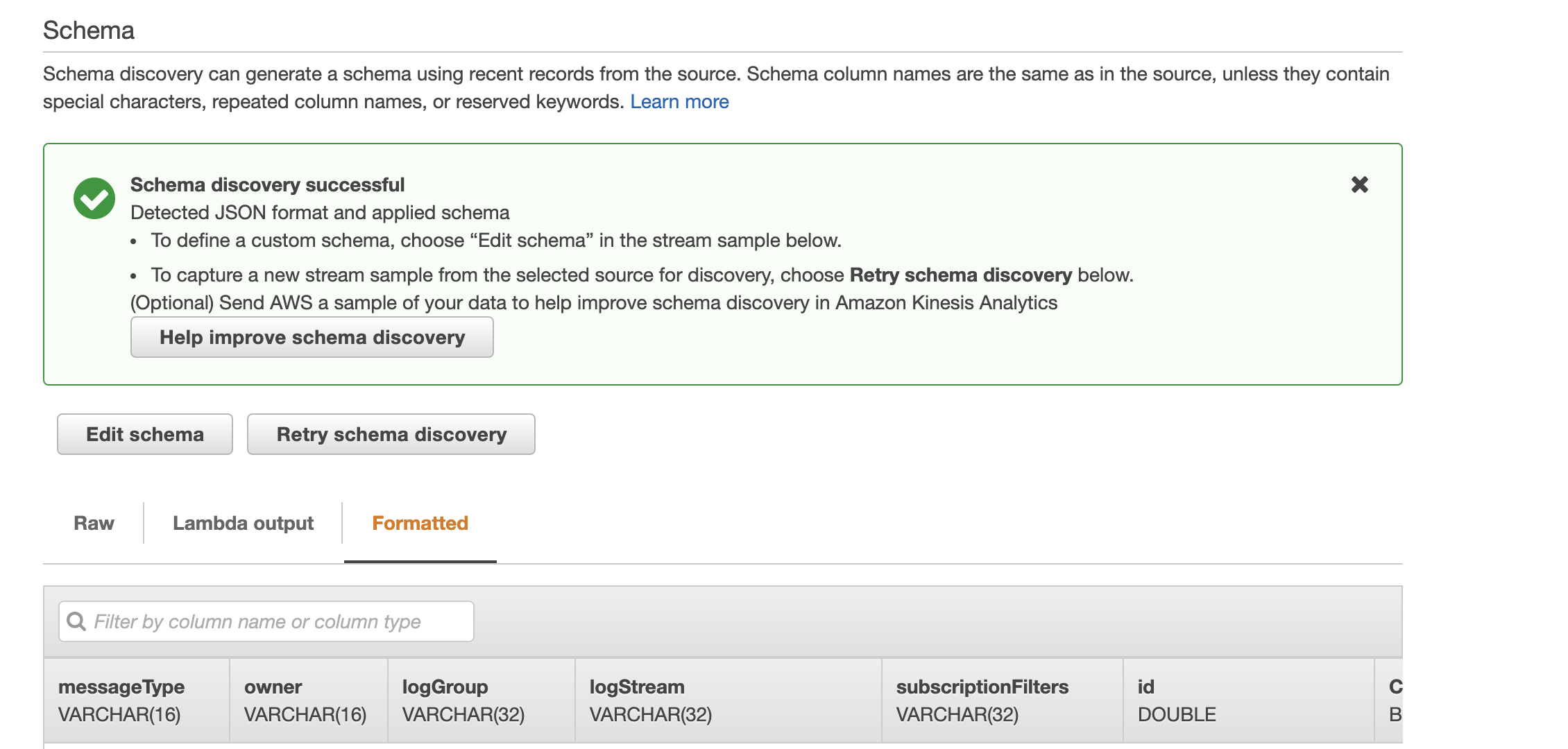
SQL作成
Source設定はできたので、実際にフィルターをかけるSQLを作成します。
Real time analytics を選択します。
byte数でフィルターしてみます。
-- ** Continuous Filter **
-- Performs a continuous filter based on a WHERE condition.
-- .----------. .----------. .----------.
-- | SOURCE | | INSERT | | DESTIN. |
-- Source-->| STREAM |-->| & SELECT |-->| STREAM |-->Destination
-- | | | (PUMP) | | |
-- '----------' '----------' '----------'
-- STREAM (in-application): a continuously updated entity that you can SELECT from and INSERT into like a TABLE
-- PUMP: an entity used to continuously 'SELECT ... FROM' a source STREAM, and INSERT SQL results into an output STREAM
-- Create output stream, which can be used to send to a destination
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (
"srcaddr" varchar(16),
"dstaddr" varchar(16),
"bytes" DOUBLE
);
-- Create pump to insert into output
CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM"
SELECT STREAM "srcaddr", "dstaddr", "bytes"
FROM "SOURCE_SQL_STREAM_001"
WHERE "bytes" > 50;
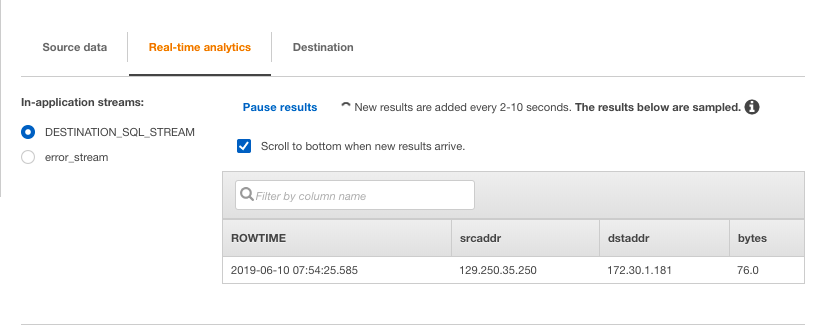
お、リアルタイムに流れてきました!(50byteなのであまり確認になってないかもしれませんが、、)
その後の連携
-
Destinationとして、Kinesis stream/Firehose/Lambdaを選択できます。
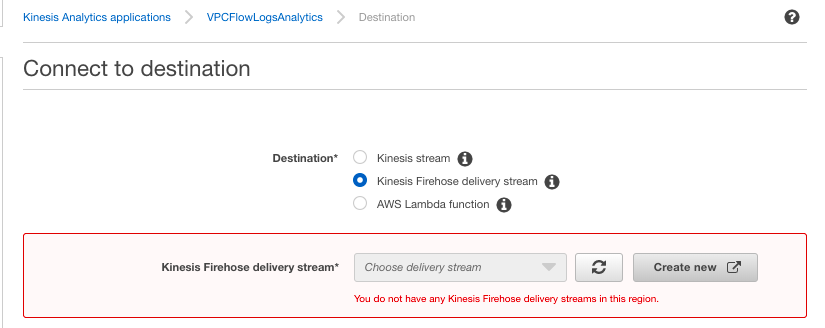
Firehoseを使って、フィルター後のデータをelasticsearchでリアルタイムに可視化しする、ってこともできそうですね。

まとめ
Kinesis analyticsの挙動を確認してみました。
SQLを使って良い感じにフィルターがかけられそうです!もう少し触ってみようと思います。
(今回の例ではCloudWatch Logs Insightsでも事足りそうですが、、)