はじめに
先日、AI系で日本で一番有名と言っても過言ではない、東京大学の松尾研究室のLLM 大規模言語モデル講座の資料が、非商用利用での二次利用可能という条件で無料公開された。
詳しい利用規約は下の資料ダウンロードページよりご確認ください。
講義資料はすべて、以下のライセンスがあります。
LLM 大規模言語モデル講座 講義資料 © 2023 by 東京大学松尾研究室 is licensed under CC BY-NC-ND 4.0
この資料は、2023年秋に同研究室が開催したLLM講座と同様のもので、僕も含めて約2000人が受講した。
2024年8月14日現在、2023年版の資料公開は停止したらしいです。2024年秋に新LLM講座が開講されるらしく、そちらの受講をおすすめします。(申込は2024年8月26日までらしいです)
さすが松尾研、何から何までとても質が良く、大変勉強になったので、今回はそれの復習&備忘録がてら、資料を詳しく読みつつ、参考になるサイトや動画を貼り付けつつ、記事を書いていく。
この資料において、「LLM資料」とは、松尾研究室から公開されたLLM講座の資料を指します。
手元に資料を用意し、同時にこの記事を参照していくことを想定しています。
今回は第3回の講義資料について進める。それ以降は近々。講義資料は上のリンクから無料でダウンロードできます。
第2回についての記事はこちら
間違いがあるかもしれないので、コメントで教えていただけると大変嬉しいです。
資料に書いていないことでこの記事に書いてあることは筆者が調べたことや考えです。
松尾研の深層学習基礎講座も受講させて頂きましたが、本当に質が良く、めちゃくちゃおすすめです。深層学習をこれから勉強する、基本まではわかる、という方にとてもおすすめです
筆者がさらに詳しく勉強したり、記事を読んだ方から「この情報参考になったよ」というものがあれば、随時更新していきます
自己紹介
データサイエンティストを目指して日々勉強している、慶應大学理工学部4年生(202.01.09時点)
取得資格、コンペ優勝経験など、リアルタイムの情報は👇👇👇をみてね
X: @A7_data←普段はXで活動しています。ありがたいことに、フォロワーは6500人を超えました😌
プロフィールページ👇👇👇
X👇👇👇
Day3の概要
Day3の大きなテーマはTransformerとLLMの事前学習について
Transformerに関しては、同モデルが提案された論文「Attention Is All You Need」は深層学習界で最も有名な論文といっても過言ではないほど有名なので日本語解説記事もたっくさんある。
なので詳細な解説はそちらに譲ります。
LLM資料の「発展的な話題」にある内容も各項目にまとめて記載しています
Transformer
深層学習モデル以前の言語モデルの課題
言語モデルでやりたいことは、「今まで生成した単語列を元に、次の単語を予測する」ことで、その単語は今まで生成した単語列を条件とし、次にある単語がくる条件付き確率を求め、その確率が最大のものを選ぶということだった。(LLM資料p.8参照)
ただ、これだと単語列が長くなったときや、類義語の処理に課題が生じてしまっていた。
ニューラル言語モデル
しかし、計算したい条件付き確率をNNで推定することにより、対処できた。
Encoder-Decoder型のRNN(Recurrent Neural Network)が最も基本的なモデルにはなるが、これでは長文に対応できなかった。(勾配消失&単語間の長距離依存性の把握が困難)
RNNが勾配消失するのは、活性化関数のtanhが1未満の値を取るため、BPTT時に掛け算されるとだんだん値が小さくなってしまうことが原因で、勾配爆発はBPTT時に隠れ状態の同じ重みが掛け算され続けることが原因。(ゼロつく2より)
このRNNの弱点を補い、深層学習界に大きな衝撃をもたらしたのが、Transformerというわけだ。
Transformerの解説記事たち
さて、Transformerの解説を書きたいところだが、すでに僕より何歩も先を行く方達がたっくさん解説記事を書いてくれているので、それらを紹介し、この記事では概要や、自分が調べたことのみ書いていく。
- まずは元論文
- 1700いいね越えの良記事
- 今回の講義より詳しい解説かもしれない記事。これが一番かも
- この記事も詳しい解説が載ってる。Query, Key, Valueの計算過程が特に詳しかった
- TensorflowでのTransformerの実装
- PyTorchでのTransformerの実装
Word Embedding
テキストをベクトルに変換する場所。
テキストをモデルで学習するには数字に直さないといけない。しかしながら単語の意味情報も失いたくないため、単語をベクトルにすることで意味を表しつつ、数値化する
ベクトル化の基礎はCBOWやskip-gramが有名だろう
僕は以前Aiciaさんの動画で勉強したが、とてもわかりやすいのでおすすめ
CBOWは前後c個ずつの単語の中から中央の単語を穴埋めするタスクを二層のNNを使って解くことで、単語の分散表現(どうベクトル化すべきか)がわかる
skip-gramはその逆で、中央の単語から前後c個ずつの単語を予測する。
これらのタスクを行うことで、単語の分散表現がNNの重みの部分で表現ができる。(詳しくは動画)
Transformerでは、このEmbeddingを行うNNも学習の対象であり、学習を通して単語の意味をより良く表現できるようにしていく。
Attention
Scaled Dot-Product Attention
Transformerの核はAttentionであるが、中でもScaled Dot-Product Attentionが中心となっている。
その処理の説明を言葉でここに書くのはちょっときつい。笑
LLM資料のGIF画像が一番よくわかると思う。このサイトのもの。
Q. 「1ステップで全単語と繋がる」とは?
A. 上のサイトの図から分かるように、Attentionでは他の全単語との関係を一度の処理で(1モジュールの追加で)把握できる。RNNは前のステップの隠れ状態と現在の状態を使って計算するので、一度の処理で全単語との関係は把握することができず、逐次的に計算をするしかない。
この違いも、RNNは長距離記憶が苦手であることの原因になっているんだろう。
Q. Attentionでやってることは?
A. 単語の意味を、文脈を含めた意味に変換(transform)していると言える。文脈内での意味をより取り込む、と言うこと。
LLM資料の「アテンション機構の可視化例」のスライドの左の図がわかりやすい。
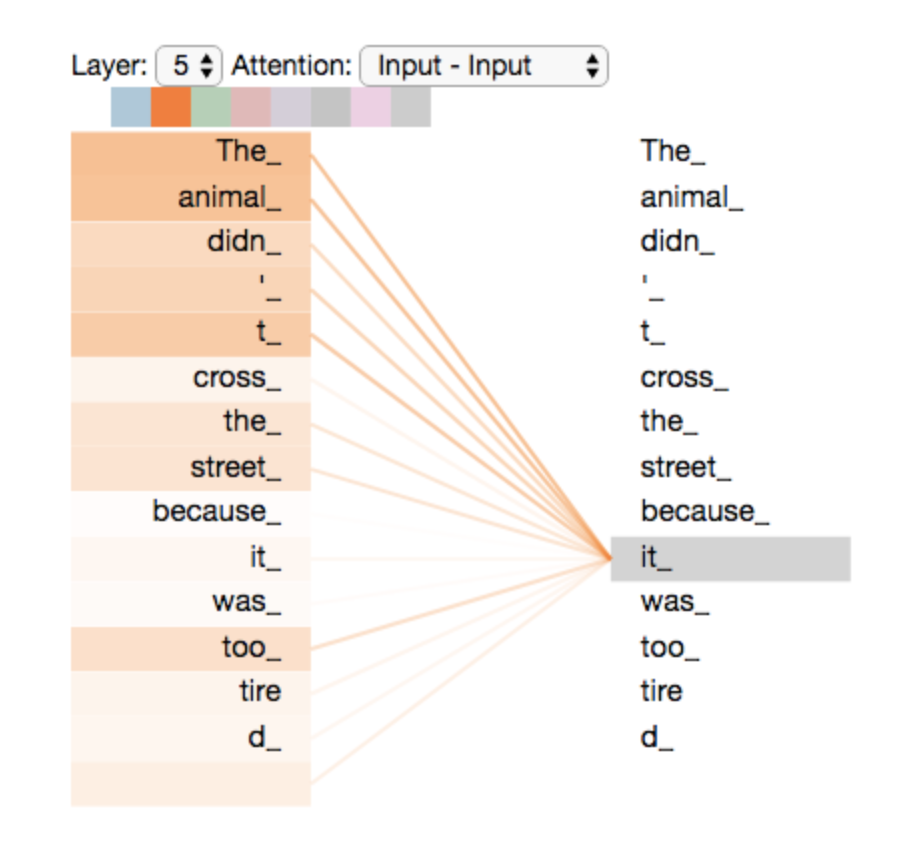
↓以下のサイトより抜粋
こんなにわかりやすいものが得られることは稀だが、この例では、文中の「it」が「The」と「Animal」に強いAttentionを示している。つまり、itの意味が単なる「それ」ではなく、この文中では「The Animal」を意味すると学習したということである。
このように、Attentionは他の単語との内積(=類似度)を計算することにより、それぞれの単語の意味ベクトルを、よりその文で適切な意味を持つように変換していると考えられる。
Multi-Head Attention
Multi-Head Attentionは上記のScaled Dot-Product Attentionを複数個並列に組み合わせることで、意味を適切に捉える処理をより多くの角度から行なっている。これにより、表現力が増しているらしい。
Feed Forward
Feed Forwardは活性化関数がReLUの巨大なNNである。ここの説明で出てきたニューラルメモリが何かわからなかったので、少し調べて見ようと思った。
思った。思ったが、ちょっと時間制約の関係上、後回し。ChatGPT先生にも聞いたがちょっと難しそうなので必要になった時にしっかり学ぶ。
Others
Layer Normalization
Layer Normalizationは正規化手法の一つで、学習を安定させ、速度も向上させることができる。
同じ正規化だとBatch Normalizationは有名だが、Batch Normalizationはシーケンス長が異なる場合は適用できないため、平均と分散を取る軸を変えたLayer Normalizationが自然言語処理では用いられる。
他にもNormalizationの種類はあるっぽい。ここは要勉強。
x = [[1, 2, 3],
[4, 5, 6]]
Layer Normalizationはこういうデータがあった場合、平均は(1+2+3)/3=2のように、横方向に計算する。分散も同様。それらを使って各要素を正規化する。らしい。ChatGPT先生曰く。
もっとわかりやすい記事や教材があれば教えてください🙇♂️
残差接続(residual connection)
residual connectionは僕が深層学習に興味を持った理由の一つ。
ResNetという画像認識モデルで導入されたもの。
深層学習は性能を向上させるために層を深くすることがトレンドだったが、深くさせすぎると、入力を1、出力も1というような単純な処理が逆に難しくなってしまった。そこで何が問題になるかというと、処理自体は例えば100層で十分であるものが、モデルが130層あると、100層時点の出力を130層でも同じように出力できれば良いのだが、それができないということになり、30層分余計なノイズを含ませ、精度を劣化させてしまう。
これを解決したのがresidual connectionであり、層の出力をその層の入力と足し合わせることで、(=その層では入力と出力の「残差」をどうすれば良いかを計算することになる)もし単純に1を入力として1を出力としたければ、層内の重みは全て0としてしまえば、入力がそのまま出力として採用できる。これにより、上記の「余計な学習」に対処でき、さらにモデルを深くできるようになった、というわけだ。
この些細な工夫で大きなインパクトを出せている感じが好きで、自分もこのような発見や工夫で何か大きなことを達成したいなあと思っている。
Transformerを使ったモデルたち
Transformerは現在のAIモデルの多くに使われており、非常に重要な位置付けとなっている。
GPT
2023年世界を賑わせたChatGPTの中核技術「GPT」だって、Generative Pretraind Transformerの訳で、TransformerのDecoder部分を改良して用いている。事前学習はNext Token Prediction。
BERTなどのモデルは事前学習した後にファインチューニングして下流タスクに合わせるのが主流であるのに対し、GPTはもはやファインチューニングなしでプロンプトによって下流タスクに対応できてしまうほどのすごさ。まあ、ChatGPTを使っていればわかりますよね
プロンプトとかファインチューニングのお話はDay2。すでに100いいね以上頂いてます。ありがとうございます。勉強したら更新していきます。(2024.02.16現在)
GPTはGPT-2やらGPT-3とだんだん進化していったけど、モデルの進化は基本的にはモデルを大きくしてデータセットも大きくして巨大化させた感じ。GPTがTransformerのDecoderを12個積み重ねていたのに対し、GPT-3では96個積み重ねている
その結果、ChatGPTで体感できるように、もはやFine-Tuningなしでも多様タスクに対応できるようになったわけだ。(もちろん、Fine-Tuningすればさらに性能が向上することがほとんど)
BERT, RoBERTa
BERTも、Bidirectional Encoder and Representations from Transformersの略で、やっぱりTransformer。論文は2018年に発表されており、当時は11の多様なタスクでSoTAを達成した
基本は事前学習→ファインチューニングの流れで個別タスクに対応できる。
モデルはTransformerのEncoderを12層重ねており、事前学習としては文章をランダムにマスクし、文章全体からマスクされている単語を予測する「Masked Language Model」と、2文目が1文目の続きかどうかを、文の先頭単語のベクトルから判定する「Next sentence prediction」を行う
これにより、前者からは単語の意味や文法構造、後者からは文の意味や文同士の整合性を学習する。
RoBERTaについては、BERTの改良版であり、基本的にはモデルサイズと事前学習データ量を増やし、さらに事前学習タスクも長文化、マスクもランダム化したものらしい。
日本語解説記事もあったから、さっと読んでみよう。
T5
T5も、Text-to-Text Transfer Transformerということで、やっぱりTransformer。
T5は、それまでのモデルが入力がテキスト、でも出力は数値だったり、テキストだったりと様々であったものを、出力もテキストに統一することによって、学習を同じ方法で、同時にできるようにしたもの。
T5では、Transformerに様々な改造を施したものを使っている。Layer Normalizationのバイアス項を無くしたり、skip-connectionの外に出したり、色々と。
事前学習
さて、Transformerの凄さがわかったところで、後半は事前学習のお話。
事前学習とは?
義務教育みたいなものだと認識している。おおまかに見て、AIの研究をしたい人も、弁護士になりたい人も、医者になりたい人も、義務教育はみんな同じ教育を受け、高校、大学に進むにつれ、(=下流タスク(=それぞれの職業)に近づくにつれ、)各々にあった、専門的な教育を受けていく。
この義務教育部分が事前学習であり、しっかりと基礎を構築する。その後、それぞれの目指す先にあった専門的な教育はFine-Tuningやら転移学習であるわけだ。
ざっくりね。イメージの話ね。
事前学習データ
とはいえ、事前学習は莫大な量のデータを用いるのが主流であるから、(GPT-4は書籍1億冊分?)到底個人で用意するのは大変である。
調べてみたら、公開されているものも多いらしい。
発展的話題にあった、DolmaもHugging face上で見つけた
それにしてもDolmaは3兆トークンで5334GBあるって、どうやって使うんだ...
事前学習の前処理
この記事にデータセットに加えて前処理の話もちょっとあった。
けど、基本的にLLM資料のDolmaについての部分読めば流れは分かりそう?
この記事は実際にいくつか前処理を試してた。コード付き。
この二つが一番詳しいかも。LLMチューニングするときに見てみよ。
テキストのトークン化
LLM資料にある通り、代表的な手法はByte Pair Encoding(BPE)
このサイトに簡単なプログラムと説明があった。
僕もChatGPT先生に例を作ってもらった
見たい方はこちら
簡単な例 以下に、"aaabdaaabac" という文字列にBPEを適用するプロセスの例を示します。頻度カウント: 文字列内の全ての隣接する文字ペアの頻度をカウントします。
初期の文字ペア頻度は次のようになります: {'aa': 3, 'ab': 2, 'bd': 1, 'da': 1, 'ac': 1}
最も頻繁なペアのマージ: 最も頻度が高いペアを選択し、それを新しいシンボル(またはトークン)に置き換えます。この場合、'aa'が最も頻度が高いので、'aa'を'A'という新しいシンボルに置き換えます。
置き換え後の文字列: "AabdAabac"
更新された文字ペア頻度: {'Ab': 2, 'bd': 1, 'da': 1, 'ab': 1, 'ac': 1}('Aa'はもはや存在しないため、頻度リストから削除されます)
反復: このプロセスを繰り返します。次に頻度が高いペアは'Ab'ですので、これを'B'に置き換えます。
置き換え後の文字列: "ABdABac"
更新されると、さらに異なるペアがマージされる可能性があります。
このプロセスを繰り返すことで、元の文字列はより少ない数のユニークなシンボルで表されるようになります。BPEは特に有効な理由は、頻繁に出現するパターン(この例では'aa'や'ab'など)を単一のシンボルに置き換えることで、元のデータをよりコンパクトに表現できるからです。
NLPでは、この技術により、単語をより細かいサブワード単位に分割して、未知の単語に対応したり、語彙のサイズを管理したりすることができます。これにより、モデルの汎用性が向上し、特に多言語や語彙が豊富な言語において有効です。
単語ごとに扱うのではなく、単語よりも細かくすることで未知の単語への対策をしているらしい。上手いなあ。
事前学習の訓練
Next Token Predictionは一般的に1 epochしか学習させないらしい。
複数epochやると過学習となってdegredation(性能劣化)するか、差がないためらしい。
まあ、確かに同じ文章のNext Token Predictionたくさんやっても仕方ないもんな。。
事前学習の学習
Attention
Sparce Attention
Transformerが巨大すぎるので計算量を減らすために、Attentionをスパース(疎)にしたもの。GPT-3などで使われている。
全単語と1ステップで繋がるのではなく、ある程度前の単語までに絞ることで計算量を削減するが、2ステップ通すと全単語を参照できるStrided Attentionと、Strided Attentionの絶対位置版(このサイトの図を見た方がわかりやすい)と今までのAttentionを組み合わせたAttentionにすることで、計算量を削減。
Multi-Query Attention
TransformerのMulti-head Attentionで、それぞれのScaled Dot-Product Attentionで使うQとKとVを別々に用意していたが、KeyとValueをいくつかのグループで統合または一つにすることで計算量を下げるもの
ただ、一つにまとめてしまうと性能劣化が起こりやすいのでいくつかのグループの方が良いらしい。
他にも手法はあるらしいが、ちょっと筆者が直近でそれを触る予定がないので割愛。
事前学習の評価
定性評価
事前学習したLLMで、テキストを出力してみることで評価する。
Greedy Decoding
一番単純。生起確率が最大のものを逐一選択する。僕も大好きGreedy法。
絶対ね、あれこれ考えて時間かけるよりね、その時最善の手法に飛びついた方が楽だしいいんだから。(よくないです)
Beam Search
Greedy Searchは次の単語の生起確率最大のものを選択していたが、その先の単語の系列までを考慮して決める方法。
もちろん、先まで考えすぎると計算量が爆発するため、決められた範囲内で計算する
ちょっと賢いGreedy Decodingみたいな感じか。
Random Sampling
次のトークンの生起確率が最大のものを選ぶのではなく、可能性が高いところから選ぶ方法。
ChatGPTのパラメータでtemparetureという、出力の安定度を決めるものがあるが、それはrandom samplingの度合いを決められるもの。
確かに、temparetureを大きくした方が、より多彩な出力が得られることになり、面白い。水平思考ってやつ。
定量評価
色々書いてあった。
今回は軽くしか調べてないけど、なんか調べてるうちに僕だったらどれくらい点数取れるのか、やってみたくなってきた。笑
FLASK
Day6で詳しく扱うらしいので、今は割愛。
MMLU
大規模マルチタスク言語理解(Massive Multi-task Language Understanding)の略で、数学・物理学・歴史・法律・医学・倫理など、57科目の組み合わせで知識や問題解決能力を測るテストらしい。高校や大学レベルの問題を含む4択形式。Gemini Ultraは90%越えで、人間の専門家を超えたらしい。でも使ってみるとGPT-4の方が良さげなんだよな。。
GLUE
GLUE(General Language Understanding Evaluation) の略。英語でモデルの性能を評価するための標準ベンチマークらしい。英語文法の正しさ判定や映画レビューの感情分析などの9つのタスク(CoLA/SST-2/MRPC/STS-B/QQP/MNLI/QNLI/RTE/WNLI、詳細後述)に対応するデータセットのコレクション。
英語でしか評価できないらしく、日本語版は別で作られたらしい。
MATH
12,500 の挑戦的な数学の問題の新しいデータセット。モデルサイズを大きくするだけではスコアは上がりにくいらしい。やっぱりLLMは論理的思考がまだ苦手っぽい。
あのGemini UltraでもGPT-4でも50%ほどしか行かないのだから、難しい論理的思考は課題が多そう。
でもナレッジグラフとか、GNNを組み合わせて複雑な思考をできるようにするみたいな研究もあるそうで、面白そう。
僕も修論はGNNとか、ナレッジグラフとか興味あるから、もっと詳しく調べたらここに追加する。
最後に
今回はLLM講座のDay3について扱った。まだまだ勉強の途中で、個別の単元は深められていない。また調べたらこの記事に追加していきます。
次はDay4についてまとめる。割とすぐ投稿する予定なので、待っていてください。
また、X(Twitter)では日々データサイエンスやAIに関する勉強記録・情報発信をしています。フォロワーはもうすぐ7000人に到達します。
少しでも刺激になるようなことを発信できたらいいなと思っているので、気になった方は見てみてください🔥
では👋