こんにちは。virapture株式会社のもぐめっとです。

写真写る時は割と全身で今の気持ちを表現することが多いです。
本日はorelliyより出版されてる「モノリスからマイクロサービスへ - モノリスを進化させる実践移行ガイド」を読み、具体例があって非常に読みやすく、実践にも使える内容でとてもいい本だったのでこちらをぎゅっと凝縮して、もぐめっと的におすすめなポイントを掻い摘んで説明していこうと思います。
本書は下記のような章立てで構成されており、私の解説もなぞるような形で解説していきます!
- 1章「必要十分なマイクロサービス」
- 2章「移行を計画する」
- 3章「モノリスを分割する」
- 4章「データベースを分割する」
- 5章「成長の痛み」
では早速解説していきます!
1. マイクロサービスとモノリスってなんぞや
マイクロサービス

マイクロサービスとはなにか。
今日はこれだけは覚えてから帰ってほしい内容です。
結論から言うと
「ビジネスドメインに基づいてモデル化された独立したデプロイ可能なサービス」です。
これだけ覚えればもうこのページを閉じてもいいでしょう。
.
..
...
嘘です。閉じないでいてくれてありがとうございます。
ドメイン駆動設計を利用して独立したサービスを作り、ネットワークを介して通信することで、様々な形態の結合を減らすために頑張るのがマイクロサービスです。
モノリス
それに対し、モノリスとはなにかというと、システム内の全ての機能を一緒にデプロイする必要があるシステムのことを指します。
通常下記の3種類のモノリスに分割されます。
-
単一プロセスのモノリス

LAMP構成とかでもよくある同じデータベースからデータをよんで、全てのコードが単一のプロセスとしてデプロイされるシステムです。
一人で焼き肉焼いて一人で食べるみたいな感じですね。
マイクロサービス的観点で考えると誰かに焼いてもらってそれを自分が食べる方がきっとより美味しいですよね。 -
分散モノリス

複数のサービスから構成されているものの、システム全体が一緒にデプロイされなければならなくなっているシステムです。
30人31脚とかありますが、分散されていても同時に走らないといけないですよね。(どちらかというと一人で走ったほうが早いですよね。) -
サードパーティ製ブラックボックスシステム

給与システム、CRMシステム、人事システムなど、他の誰かに開発されたソフトウェアであり、自分たちではコードを変更できないシステムを指します。
触れぬ神に祟りなしということわざもありますし、無理に自分たちで手を入れずにそっとしておいてあげましょう。
モノリスの課題

同じ場所で作業する人が増えれば増えるほどお互いを邪魔し始めます。
別チームが働いていない時間に機能をプッシュしたりデプロイしたりなどを考慮しないといけなくなり、そうすると誰が何を所有して、意思決定をしているのかと、把握や調整が必要になってきて、次第に混沌な世界が広がっていきます。
最近もぐめっとの近況でも、typescriptに移行するためのリファクタリングを、みんなが使ってない土日に一気に実施してしまうみたいな経験が私にもあります。
2. 移行計画

マイクロサービスとモノリスがわかったところで、どうやって移行計画を考えていくかを紐解いていきます。
そのためにはまず下記の質問を自問自答しましょう。
-
- 達成したいことは何か?
-
- マイクロサービスの他に代替案はなかったか?
-
- どうすれば移行がうまくいってるか分かるだろうか?
達成したいことを把握しないと、どこに時間を集中するのか、どのように優先順位をつけるのかが見えずプロジェクトが路頭に迷い、そして最終的に辿り着く場所が
「みんな使ってるからXXXのアーキテクチャ、技術を使おうぜ」
みたいな結論に至ってしまいます。
決して「磯野野球しようぜ〜」みたいなノリで誘惑してくる中島くんの誘惑に負けてはいけません。
そして、達成したいことから算出するともしかするとマイクロサービスじゃなくても実施できる可能性もあります。
その可能性を考えずとりあえずマイクロサービスを採用するみたいなこともしないように気をつけましょう。
次からはマイクロサービスの特徴を紹介するので、特徴を踏まえた上で他の技術・アーキテクチャも選択候補としてあげるようにしましょう。
マイクロサービスのメリット

本書では下記のようなメリットが紹介されています。
- チームの自律性が高まる
- 市場投入までの時間を減らせる
- 負荷への費用対効果が高いスケーリングができる
- 堅牢性が改善する
- 開発者の数を増やしやすくなる
- 新しい技術を受け入れやすい
個人的には新しい技術を受け入れやすいという観点に関して、サービス事に選択できるようになるので楽しいことができていいなとか思ったりしています。(技術者目線)
しかし、担当するサービスが変わった際のスイッチコストをなくすために、できるだけ技術は揃えたほうがいいという考えもあるので、あくまでビジネス要件を満たすために選ぶように気をつけましょう(ビジネス目線)
マイクロサービスを選ばないほうがいい時

マイクロサービスが適さないパターンも紹介されています。
それは下記のような時になります。
- ドメインが不明瞭
- スタートアップ
- 顧客の環境にインストールするタイプのソフトウェア
- もっともな理由を持たない
スタートアップなどは事業がよくピポットするのでそもそもドメイン自体がころころ変わる場合があるので向いてないというのもあります。
また、一番気をつけたいのは理由を持たずに選ぶ場合です。
先程の達成したいことの話に近いですが、目標の明確なビジョンがなければ、プロジェクトが路頭に迷います。
決して、みんながやっているからという理由だけでマイクロサービスに手を出すことはしないようにしましょう。
中島くんの甘いお誘いは聞いちゃダメだぞっ!絶対だぞっ!
どこから着手して、どこまでやるか
結論として、ドメインモデルを書くことによって、どこから分解に着手すべきかを合理的に判断し、必要十分なだけな情報を集めながら分割していくといいです。
例えばこのようなドメインモデルがあった場合、一番分割するのが大変なサービスと、分割するのが簡単なサービスはどれになるでしょうか?
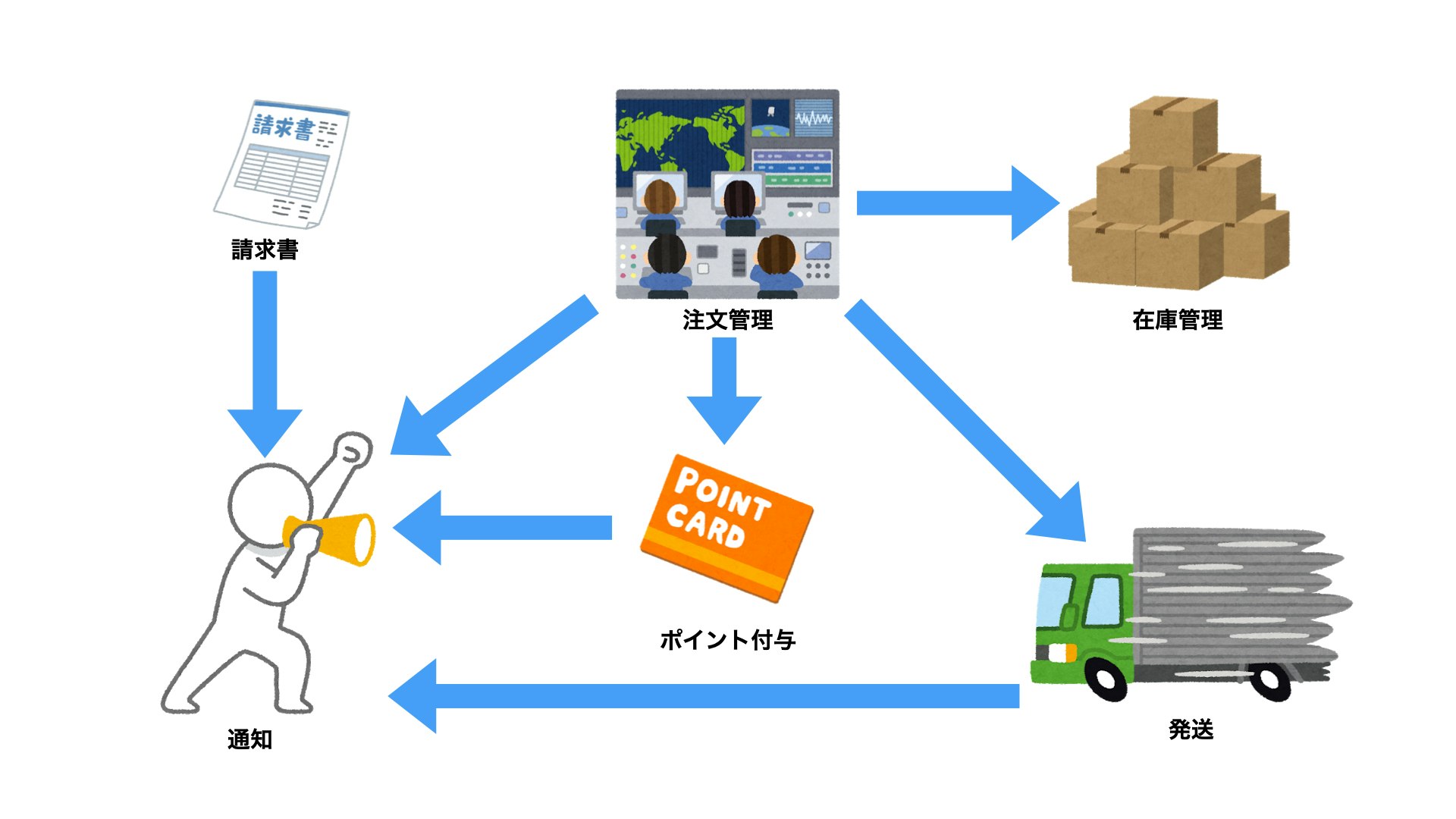
答えは、通知機能が一番大変です。
なぜなら通知機能には多くの内向きの依存関係があるので、切り出す際には依存している既存のモノリスもいじらないといけなくなるからです。
逆に分割が簡単なのは請求書機能になります。

見ての通り内向きの依存関係がないため、既存のモノリスの変更が少ないからになります。
また、依存関係だけじゃなく、優先度でみて選択する方法もあります。
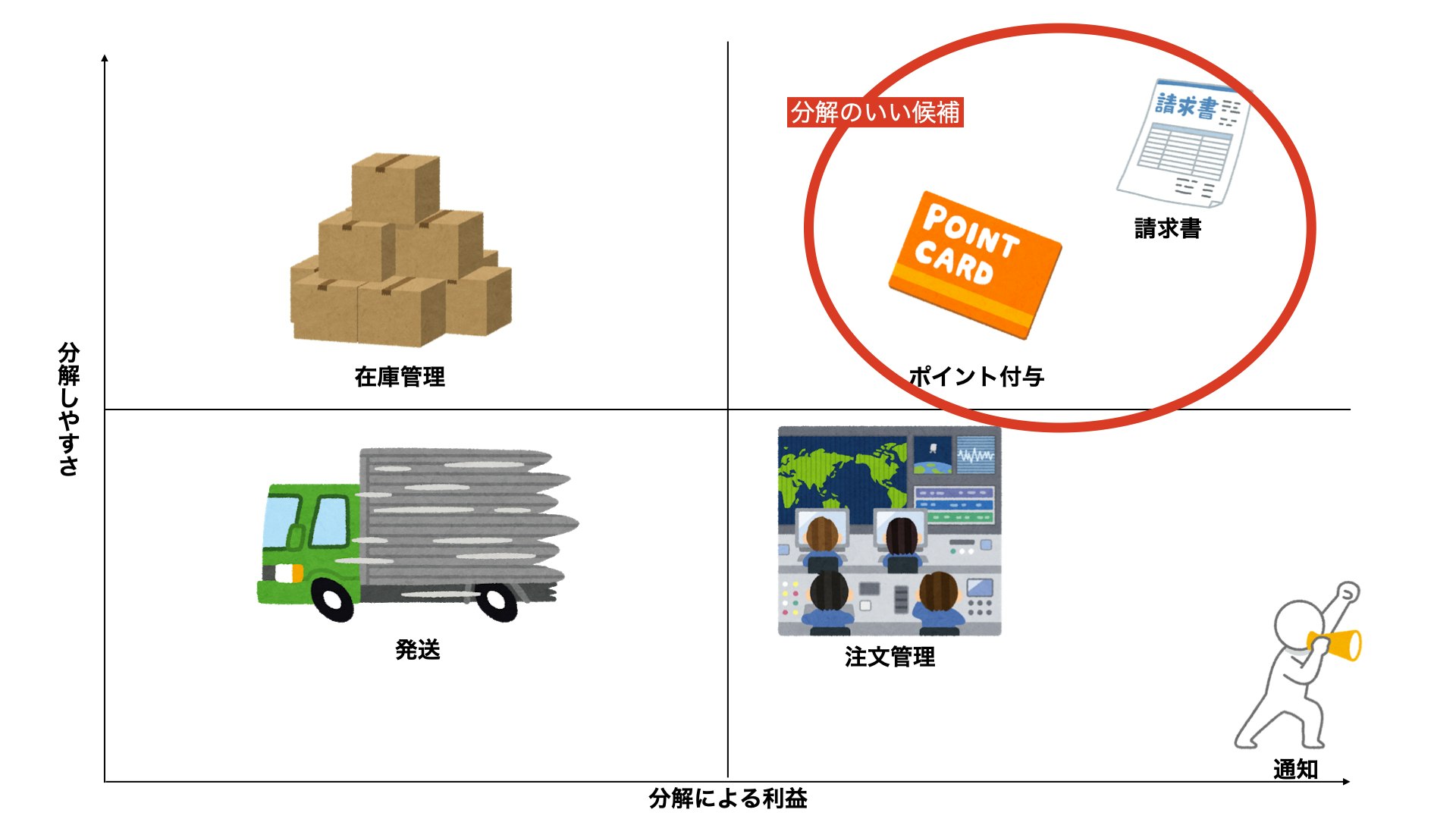
変更や調査をしていくうちに中身がわかってきて、場合によっては簡単だと思っていたことの中には、難しいこともでてくるかもしれないし、難しいと思っていたことが、簡単になることもある。
これは自然なことなので、そのたびにこの優先順位付けを見直し、計画を立て直すことが重要です。
大体のITは不確定な要素が多いので優先順位が変わることは許容して作っていかないとやりとげるのは難しいと思います。
(アジャイルでやっていくとそこらへんが許容しやすく作りやすいともぐめっと的には考えます)
うまくやっているかどうかを分かるには?
簡単です。
定期的なチェックポイントを設けて振り返るようにしましょう!
チェックポイントでは利用可能な情報を分析し、軌道修正が必要かどうかを判断するようにします。
大規模なプログラムであれば、明確な定期の活動として計画するか、さまざまな活動のリーダーを集めての月に一度のセッションで状況をふりかえる必要があるかもしれません。
本書ではチェックポイントの内容として下記を振り返るとよいとありました。
- マイクロサービスへの移行で何を達成したいと期待しているのかを再確認する。ビジネスの方向性が変わってしまって、あなたの進む方向性が意味をなさなくなってしまったのであれば、その時点でやめることだ。
- 導入している定量的な手段を確認して、進歩しているかどうかを確認する。
- **定性的なフィードバックを求める。**みんなは物事がまだうまくいっていると思っているだろうか?
- もし何かあるなら、今後変えていくことを決める。
もぐめっと的にはチーム以外にも、ステークホルダーへのチェックポイントが肝と思っており、定期的に振り返りの機会を作ることによってビジネスが変わったことへの対応や、フィードバックを早く受けることでの軌道修正などが早めに実施できるので失敗の要素を少なくすることができると考えております。
ステークホルダー的にも見えるものがあるとちゃんと進んでいるということが目に見えて分かるので安心できると言った作用もあるので、是非定期的なチェックポイントを実施するようにしましょう。
3. モノリスの分割方法

マイクロサービスにすることになったら機能を新しいサービスへと抽出する作業は、本番環境で使われないとゴールといえません。
しかし、本番に一部でも使われればその経験やプロセスから多くを学び、早く利益が得られるようになります。
この章からは実際にどうやって分割していくかを解説していきます。
モノリスを変更すべきかどうかを熟考する

最初に考慮しなければならないのは、移行において既存のモノリスの変更を計画するか(またはそれが可能か)ということです。
既存のシステムを変更できるのであれば、自由度は最も高くなりますが、既存システムがソースコードを所有していないベンダー製品だったり、組織内からは失われてしまったスキル・技術で作られているオーパーツな機能だったりする場合は使える手法も制限されます。
状況によって、コピペするか、リファクタするか、再実装するかなど、様々なパターンを考えましょう。
次から実際に変更するパターンをいくつか紹介します。
移行パターン
移行に使えるパターンとその使い所を紹介します。
| パターン名 | 使い所 |
|---|---|
| ストラングラーパターン | The王道パターン。最初にこれで考えてみて、ダメなら他のパターンを考える |
| UI合成 | 一部分のUI挙動変更ができる場合 |
| 抽象化によるブランチ | 既存のシステムを変更できて、既存のコードベースを変更するのに時間がかかりそうな場合や、同僚を混乱させたくない場合 |
| 同時実行 | 機能を変更するリスクが高い場合のみ(実装が難しいのでまれ) |
| デコレーティングコラボレータ | 受信リクエストやモノリスからのレスポンスから必要な情報を抽出できる場合 |
| 変更データキャプチャ | データを複製する必要がある場合 |
今回はその中でももぐめっと的に実用的だと感じたストラングラーパターンと抽象化によるブランチを紹介します。
ストラングラーパターン
下記にわかりやすい図があったので引用させていただきます。

こんな感じで徐々に根を張って最終的にすげかえるように、サービスもすり替える手法がストラングラーパターンとなります。
(参考のURLだとちょっと怖い名前ついてますね)
では実際のIT世界だとどんな感じかと言うとこんなステップですげ替えていきます。

cf: 絞め殺しの木の移行パターン
Step1. 移行対象の機能を見つけたら、
Step2. その機能のマイクロサービス版を作り
Step3. リバースプロキシなどを使って既存の機能の呼び出しをマイクロサービスにリダイレクトする
といった手法になります。
ただ、このときに気をつけてほしいのが、機能を呼び出しているプロキシの方にロジックを詰め込まないようにすることです。
でないとこのプロキシ自体がマイクロサービスになってしまって、技術的な課題が発生してしまいます。
ちなみにもぐめっとが某webサイトを運用する会社で働いていたときは、スイッチ側でパスを見て振り分けるサーバを切り替えるなどのL7の制御をしていました。
今思うと中々みない運用な気はします。
(でもnginxとかよりはよりレイヤーが低い層でL7制御してるのでパフォーマンスは発揮しそう)
抽象化によるブランチ
機能を一度抽象化してプロキシみたいな機能を実装して切り替える手法になります。
実際の切り替えまでの流れを既存にある通知機能を置き換える場合のパターンとして追ってみましょう。
Step1. 既存の通知機能を実装する抽象「通知機能抽象」を作ります
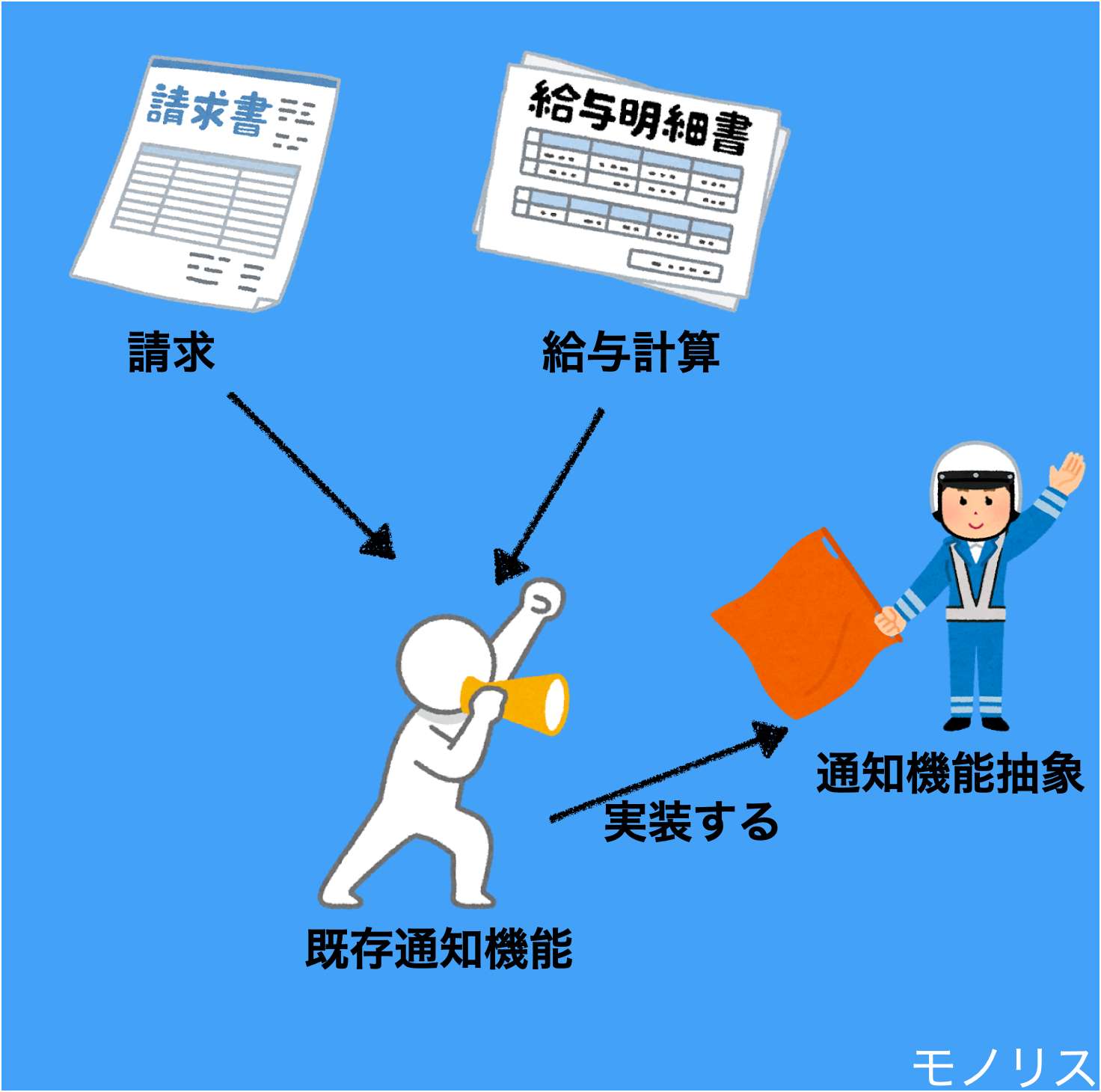
Step2. 請求、給与計算が作った抽象を使うようにします
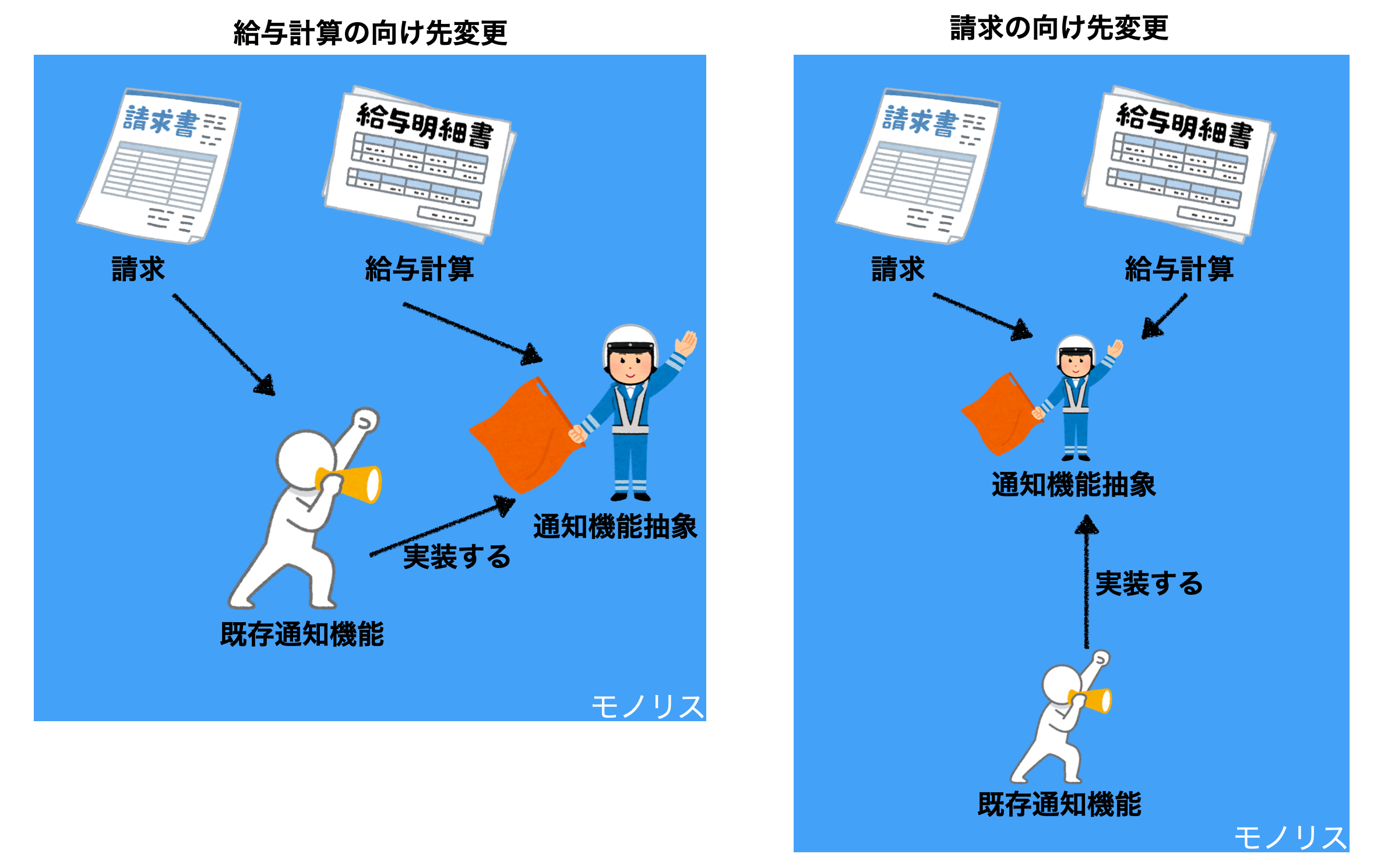
Step3. 新しい実装を作成します。この段階ではデプロイはされていますが、まだ新サービスは使われてません。
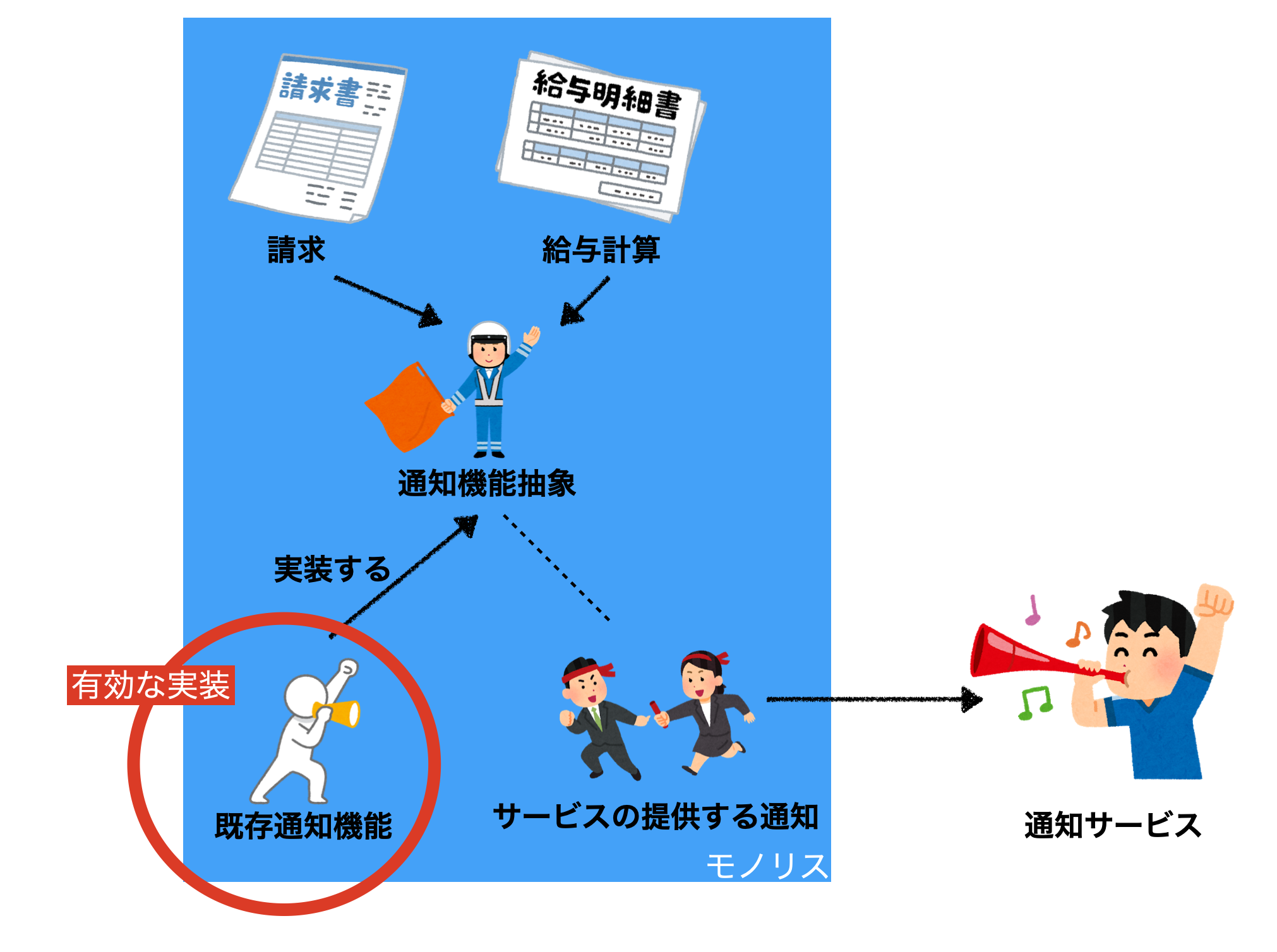
Step4. フィーチャーフラグなどを使って、新しい実際に切り替えます
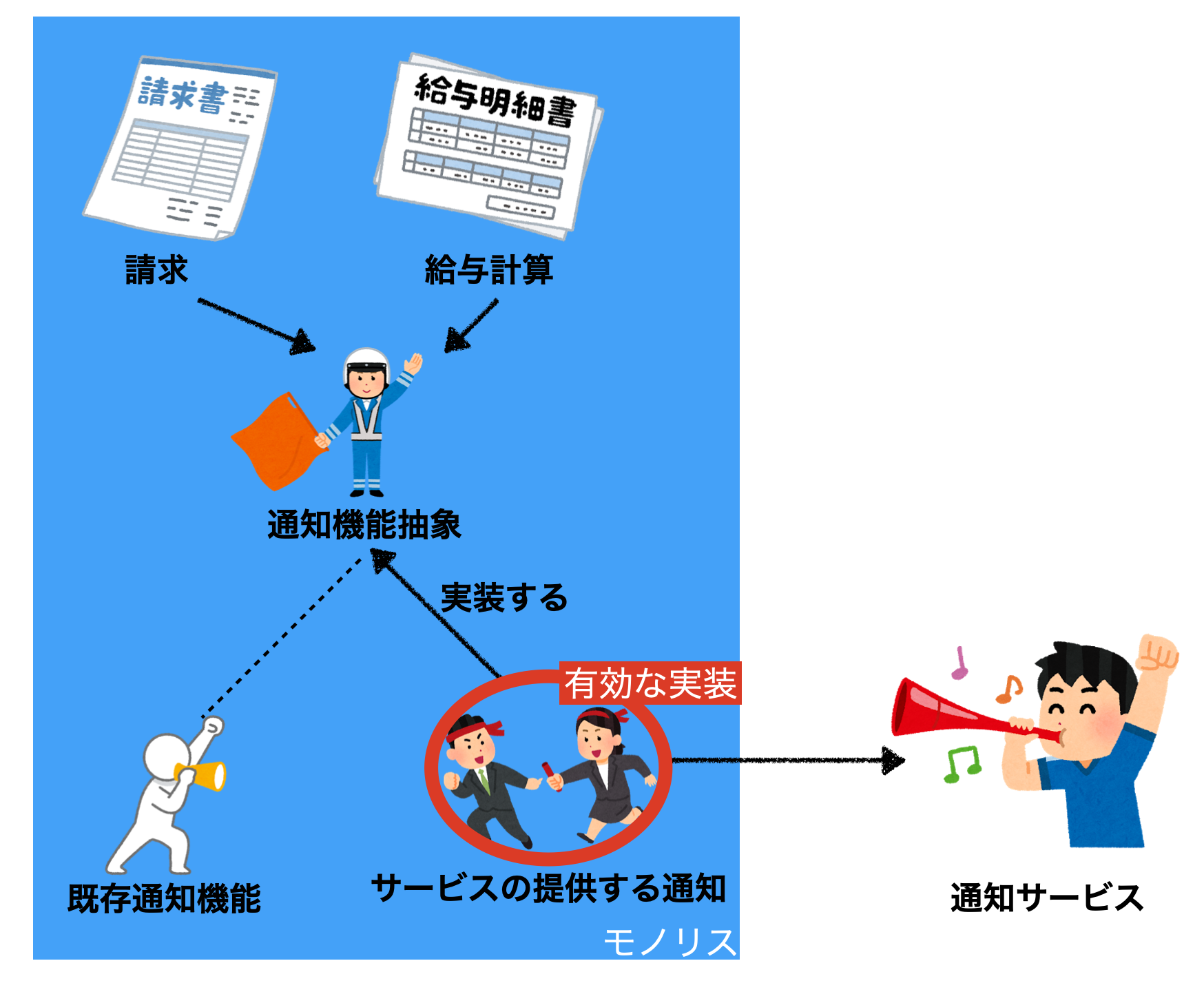
Step5. 使われなくなった古い機能は削除します。
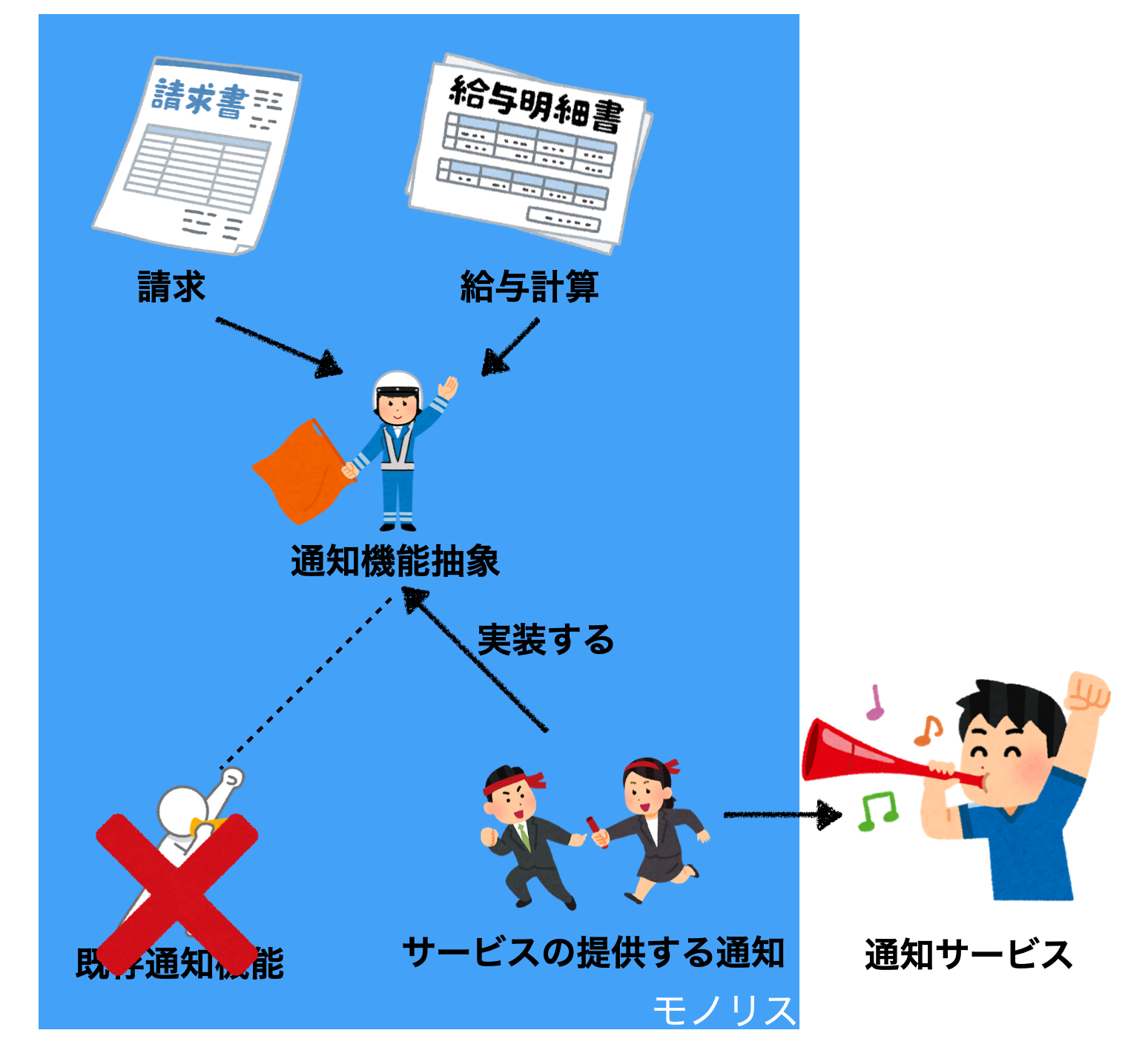
Step6. このステップはスキップしてもいい場合もありますが、抽象も削除します。(インターフェースなど単純なものなら残しても問題ない)
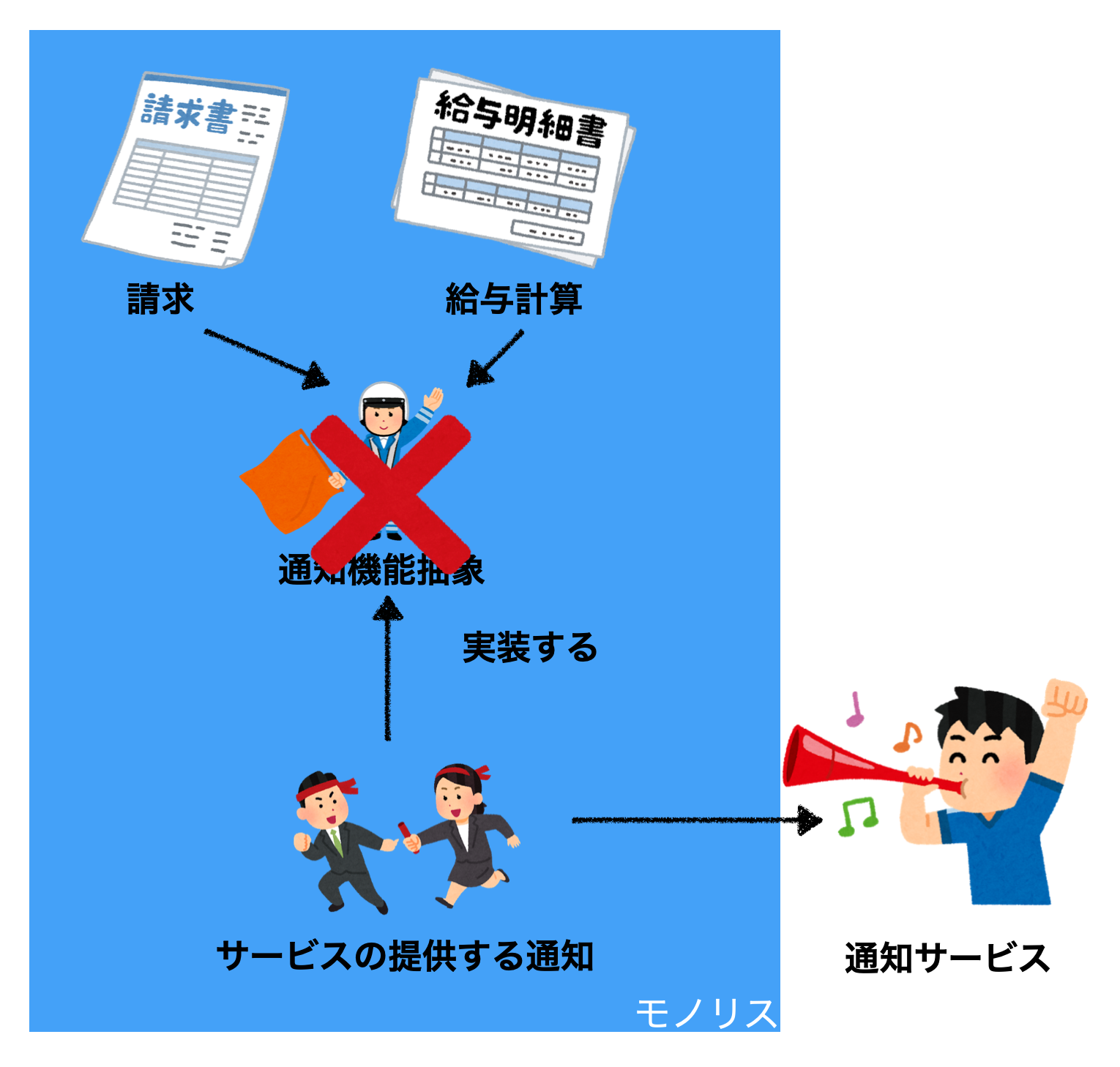
無事に切り替え完了。
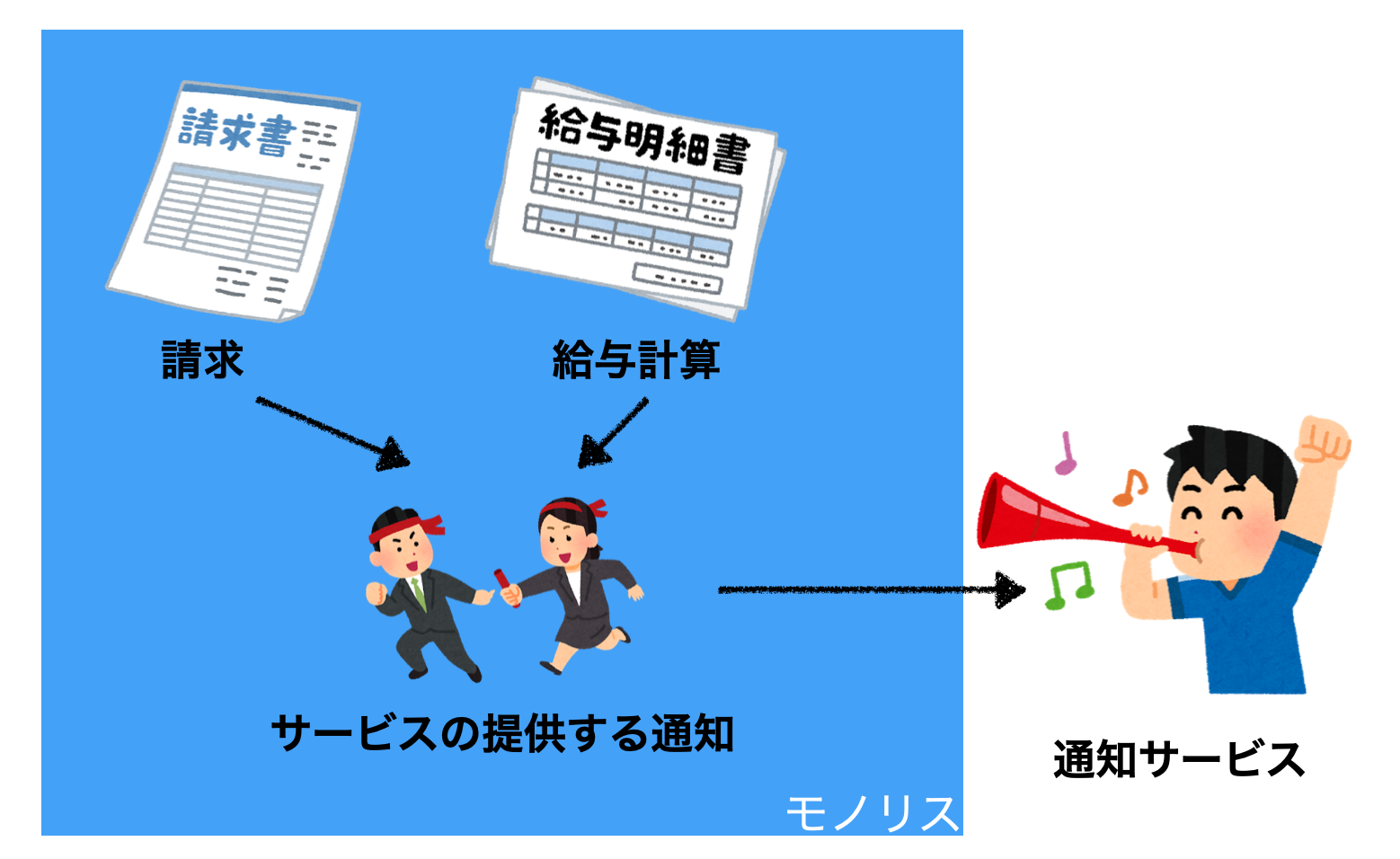
これによる良いポイントは既存のブランチの開発は並行したまま移行ができるというポイントにあります。
よくある開発の仕方でブランチをきってそのブランチに対して開発をしていくといったことが往々にあると思いますが、
ソースコードのブランチが長生きするということは、継続的インテグレーションの原則に反しており、おすすめされません。
大体、並行していくとコンフリクトがだんだんひどくなったりしてマージするのが大変になります。
この抽象化によるブランチはマイクロサービス以外でも使える技でもあって、アプリに新機能を実装するときに実はユーザには画面は見せずに裏側で機能を作られていて、完成したタイミングでユーザに見せるように変更してリリースしたといった経験もあります。
アプリ開発にも使えるテクニックではあるので是非ご活用ください。
4. データベースの分割
本書ではできるだけデータベースを共有せずに分割するようにしましょうとのお話があります。
データベースを分割するに当たり、データとコード、どちらを最初に分割するかという問題があります。
結論としては、モノリスの変更が可能で、パフォーマンスやデータの一貫性への潜在的な影響を懸念してるならデータから分割しましょう!
それ以外の場合はコードを分割して、データの所有権にどんな影響を与えるかを理解すると良いです。
ということでデータベースの分割パターンと使い所を紹介します。
| パターン名 | 使い所 |
|---|---|
| 共有データベース | 読み取り専用の静的参照データを考える場合、複数のサービスが同じデータベースに直接アクセスするのが適切な状況の場合(基本はこれを使わずに分ける方向にする) |
| データベースビュー | 既存のモノリシックスキーマを分解することが現実的ではない場合 |
| ダータベースをラップするサービス | 基礎となるスキーマを分解するのがあまりにも厳しい場合(ビューだけでは簡潔できないときなど) |
| サービスのインターフェイスとしてのデータベース | レポーティングのユースケース(たとえば、あるサービスが保持する大量のデータをクライアントが結合する必要がある場合) |
| 集約を公開するモノリス | アクセスしたいデータが依然としてデータベースに「所有」されている場合 |
| データ所有権の変更 | 新たに抽出したサービスがデータを変更するビジネスロジックをカプセル化している場合 |
| アプリケーションでのデータ同期 | モノリスとマイクロサービスの両方がデータにアクセスしている場合(複雑なのでおすすめしない) |
| トレーサー書き込み | 双方向同期を避け、よりシンプルな選択肢を使用できる場合。(既にイベント駆動型システムを使っていたり、変更データキャプチャのパイプラインが利用可能など) |
| 境界づけられたコンテキストごとのリポジトリ | モノリスを分割する方法をよりよく理解するためにモノリスと向き合いなおそうとしている場合(どんな状況でも効果的) |
| 境界づけられたコンテキストごとのデータベース | 新しいシステムを構築する場合 |
| データアクセス層としてのモノリス | データを管理するコードがモノリスの中に残っている場合 |
| 複数スキーマストレージ | 新しいデータの保存を必要とするマイクロサービスに新しい機能を追加する場合 |
| テーブルの分割 | テーブルが現在のモノリス内の2つ以上の境界づけられたコンテキストによって所有されている場合 |
| 外部キーのコードへの移動 | モノリスのスキーマから一部を大きく削り取ることで、外部キー関係の両側を一緒に移動させられる場合 |
| 静的参照データの複製 | 全てのサービスが全く同一のデータセットを見る必要がなく、かつ大量のデータを扱う場合(ほぼない) |
| 専用の参照データスキーマ | 大量のデータや、クロススキーマ結合のオプションが必要な場合 |
| 静的参照データ用のライブラリ | データが多くなく、異なるサービスが異なるバージョンのデータを参照することが許容可能な場合 |
| 静的参照データ用のサービス | データ自体のライフサイクルをコードで管理している場合 |
いや、多すぎやろ!!
この章だけでめちゃめちゃボリューミーな量があります。
もぐめっと的にはデータベースビューや境界づけられたコンテキストごとのリポジトリが使いやすいんじゃないかと思いますが、実際の細かい説明は本書に譲り、次からはトランザクションの分割についてお話していこうと思います。
トランザクションをどう分割するか
結論からいうと
2フェーズコミット(分散トランザクション)はやめよう!
もっというなら、ACID形式のトランザクション対応はとても大変なのでトランザクション分割が関わるデータ分割はやめよう!!
細かい理由などは本書に解説を譲りますが、トランザクション分割をする前にもっと分割できるところはあるよねというお話です。
でも、それでも漢にはやらないといけないときがあるんじゃ・・・!
そんな苦難をも乗り越えようとする勇気ある漢達に本書では導きが書かれています。
それがサーガを使うという方法です。
サーガとその実装方法について
サーガは複数の状態変更を調整でき、リソースを長時間ロックする必要がないようデザインされたアルゴリズムで、関係するステップを独立して実行できる離散的な作業としてモデル化すること実現されます。
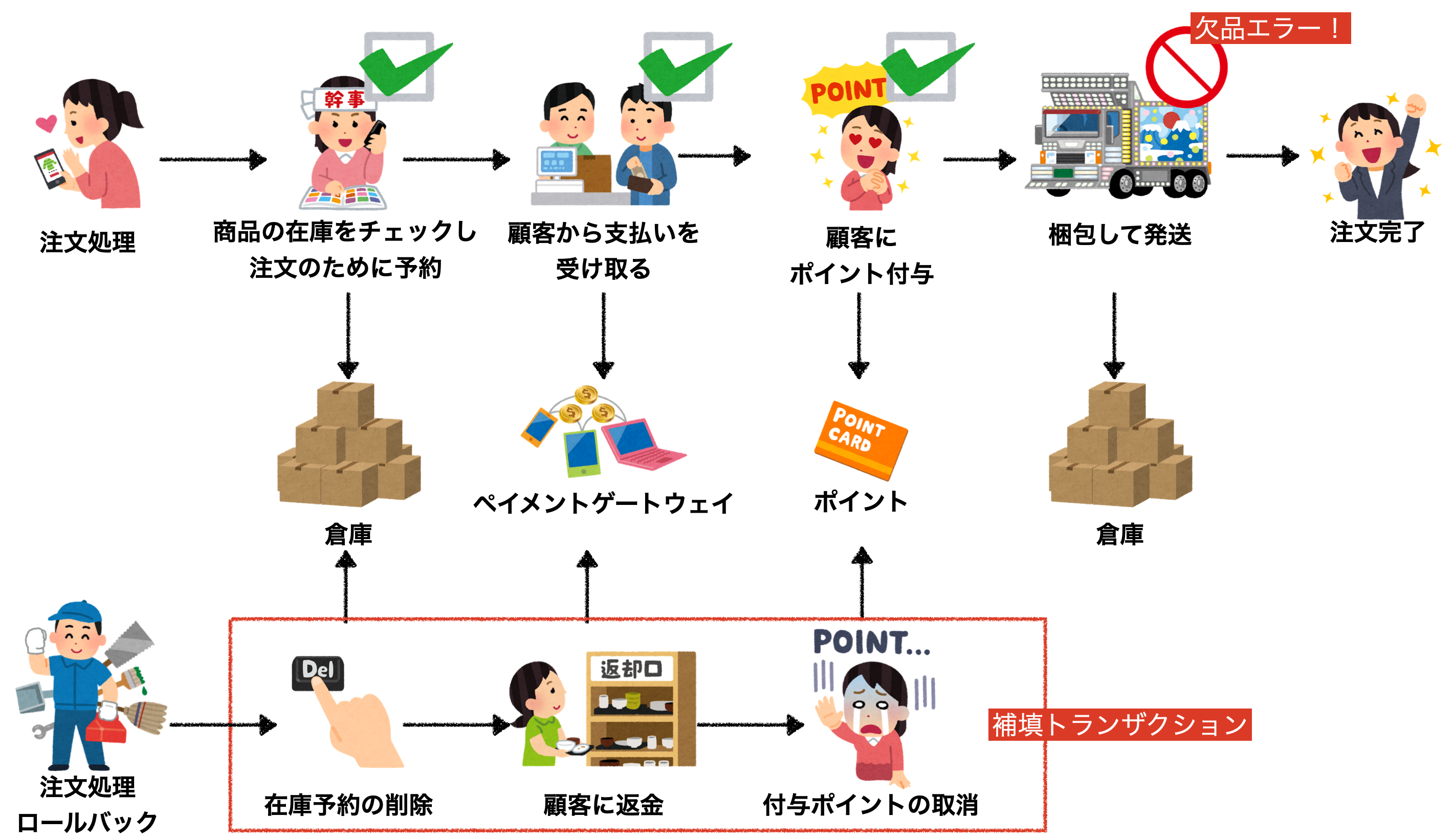
例えば注文処理を上げた場合、下記のような流れをそれぞれサービスに分割して処理を実行します。
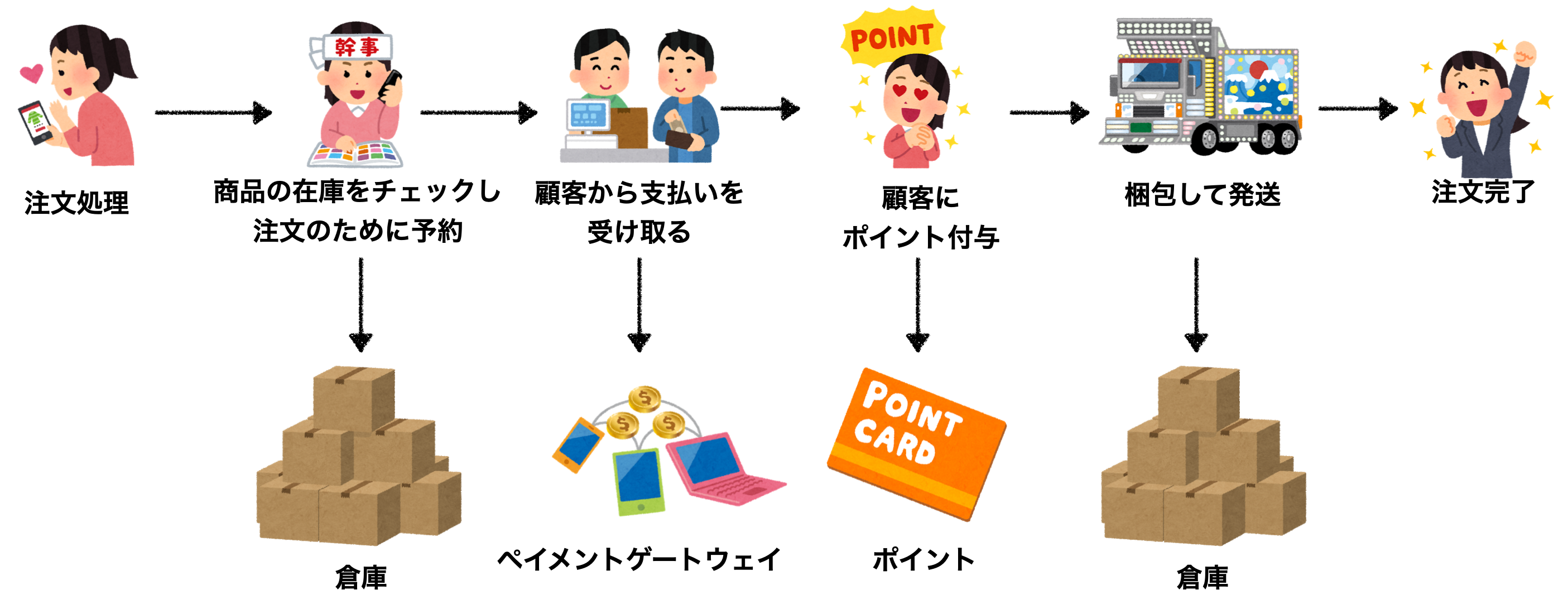
しかし、ご覧の通りそれぞれのサービスで分割されてしまっているのでACIDでいう原子性(完全に実行されるか全く実行されないか)は与えないことがわかります。
じゃぁ注文処理中に障害が起こったらどうするのか?
その答えは簡単でロールバック用の補填トランザクションというものを発行してもとに戻します。
例えば梱包エラーになった場合は下記のような補填トランザクションを実施します
そんなマイクロサービス版トランザクションとも言えるようなサーガですが、実装方法としては、オーケストレーションベースとコレオグラフィベースの2種類があります。細かい実装は本書に譲りますが、ざっくりいうと,,,
- オーケストレーションベース: オーケストラーといわれるマネージャがすべての処理を管理する
- コレオグラフィベース: イベント駆動型で各サービスがイベントを元に処理を行う。
といった形になります。
どちらもメリデリがありますが、一つのチームで全てのサービスがみれるならオーケストレーションベース、複数部署に各サービスの管理が分割されてしまっているならコレオグラフィベースを使うといいです。
5. 障害対策
障害の話としては下記が紹介されています。
- 所有権のスケール
- 破壊的変更
- レポーティング
- 監視とトラブルシューティング
- 開発者体験(ビルド・動作遅いとか)
- あまりにも多くのものを実行している
- E2Eテスト運用問題
- 全体最適と局所最適(サービスによって違うDBをそれぞれ使ったりとか)
- 堅牢性と回復性
- 孤児サービス(どうやって、なんのために動いてるか分からないサービス)
今回はその中でももぐめっと的に抑えたほうがいいと感じた破壊的変更、レポーティング、監視とトラブルシューティング、堅牢性と回復性の4点を紹介します。
破壊的変更

後方互換のない変更や他サービスに影響を与える変更のことを指します。
通常、他のマイクロサービスに公開する機能はサービスに期待される動作を定義する契約と定義されます。
サービスに変更を加える際には、この契約を破らないようにする必要がありますが、それを破って実装すると、最悪の場合サービスの停止といった事態を招いてしまいます。
複数サービス同時デプロイするような事が多々あると、契約を破った実装をしようとしている兆候があるので頻発するなら要注意です。
破壊的変更の対策
基本的には下記内容を考えましょう。
- 偶発的な破壊的変更を排除する。
- 破壊的変更を加える前によく考える。
- 破壊的変更を行う必要がある場合は移行期間をコンシューマーに与える。
簡単に言えば破壊的変更はするな!というお話ですね。
これはREST APIの設計にも通じる話ですが、破壊的変更は色々調整大変なのでやらないに越したことがないです。
もしやるしかないのであればv1, v2みたいな形で切り分けをして移行期間が設けられるように移行していきましょう。
蛇足ですが、firestoreとかですと、そういったバージョニングの設計を見越してversionごとに設計をするやり方もありますね。
レポーティング

ステークホルダーの方々はレポートを見てビジネスをどう動かすかを判断したりします。
しかし開発の段階ではここが考慮されてないことが多々あり、いざ移行したらレポートが見れない!!とステークホルダーや事業開発してる方々などに怒られたりしかねません。
レポーティングの対策
対策としては簡単でレポーティング用のデータベースを用意し、各種サービスがそのデータベースにデータを溜め込めるように必要なデータを送る仕組みを作ることで解決します。
既にデータウェアハウスみたいなデータベースがある場合はこのような問題は発生しづらいとは思いますが、もし存在しないのでしたらレポーティングを早めに盛り込んでおきましょう。
監視とトラブルシューティング

モノリシックなシステムでの監視は非常にわかりやすく、例えばCPUの使用率100%の状態が長時間続くと大きな問題であることがわかります。
しかしマイクロサービスでは本当に別れてしまっている分、障害の切り分けが難しかったりします。
例えば倉庫のサービスが落ちていても営業時間外だったら、発注が来ることがないので開発者を叩きおこす必要がなかったりなどが考えられるので、問題としていいのかという切り分けもしづらくなります。
監視とトラブルシューティングの対策
対策はElasticsearch、Logstash, Kibana, fuluentdなどを用いてログ集約システムを早期に作ることです。
ログ集約システムの実装は簡単なのですが、組織としてその準備ができてないのであれば、マイクロサービスの採用は早い可能性があります。
また、ログを実装した後、障害が起こった際には一つのログだけを見ても障害を特定しづらく、マイクロサービス間での一連のフローを俯瞰して見る必要があります。
その際に使えるのが相関IDという仕組みで、各種ログにイベントの発生元から作られるユニークIDを付与することでフローをおいやすくできます。
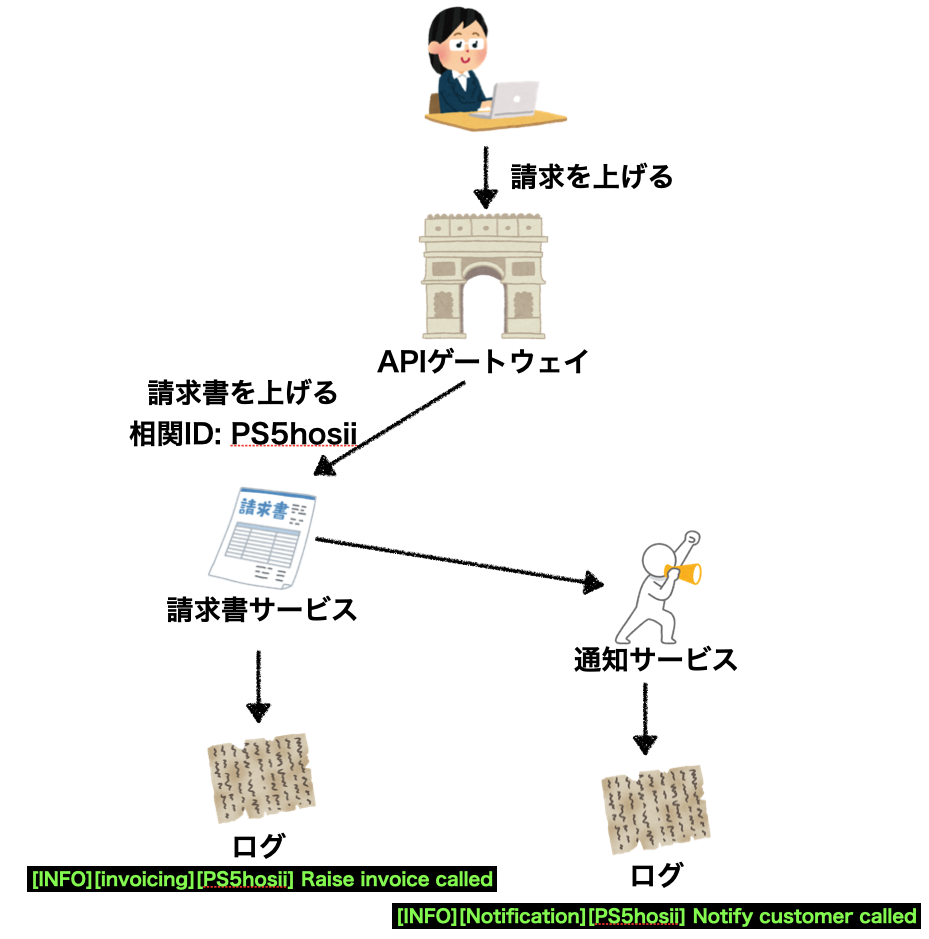
この仕組はSagaのコレオグラフィベースにて、補填トランザクションを行う際にも使えたりもするので、マイクロサービスでのログを実装する際にはフローを意識して実装するといいでしょう。
堅牢性と回復性

マイクロサービスではサービス間をネットワークを介して接続します。
そのため、ネットワークを起因とした問題としてネットワークパケットが失われたり、ネットワーク呼び出しがタイムアウトしたり、マシンが死んだり応答しなくなったりすることがあります。
しかし、その問題は運用してみないと発生がわからなかったりと厄介なものもあるので事前の対策が難しい問題でもあります。
堅牢性と回復性の対策
本書では以下の質問に答えよとのお達しがあります。
- 呼び出しがどのように失敗し得るかを分かっているだろうか?
- 呼び出しが失敗した場合、何をすべきかを分かっているだろうか?
これらの質問に答えられれば、多くの解決策を考え始められることができます。例えば一時的結合を避けるために非同期通信を導入したり、タイムアウトを賢く行って、遅い下流サービスがリソース競合を起こしてしまうのを避けたり、サーキットブレーカーのようなパターンと組み合わせて、早期に失敗させることでサービス全体に障害を波及させないようにすることもできます。
また、そもそもの回復性とは組織の進化であると一言で表せます。
回復性において、大事なのは予測できない問題が発生した場合には、必要に応じて仕事の仕方を進化させることもできる組織を構築すること、つまり、働き方全体に関わるものだと本書では主張しています。
この考えを実践する具体的な方法としては、本番環境上の問題が発生したときにはそれを文書化し、学んだことを記録しておく方法が挙げられます。
よくある事例として題を解決するか迂回するかした後に、そこから学ぶことなくさっさと次へと進んでいき、数カ月たって同じ問題に再び出くわしているという事例が多々あります。
問題が起こった場合はきちんと原因と問題を振り返って同じ過ちを繰り返さないような仕組みを作って徐々に組織を進化させていきましょう。
まとめ
長々と書いてきましたが、簡単にまとめます!
- なぜマイクロサービス化するか、目的を明確にして、定期的に振り返りながら取り組もう
- 様々なパターンを知って、現状にあった方法で分割しよう(トランザクションは大変なので後回し)
- 障害に対応できる進化する組織を作ろう
また、マイクロサービスに限った話ではないですが、選択する際には必ず必要性・有効性・将来性など様々な角度から考えて必要な方法を選ぶようにしましょう!
安易に選ばずに考えようぜの布教のためのつぶやき。
ここまで長く読んでいただきありがとうございました!
最後に、ワンナイト人狼オンラインというゲームを作ってます!よかったら遊んでね!
他にもCameconやOffchaといったサービスも作ってるのでよかったら使ってね!
また、チームビルディングや技術顧問なお話も受け付けてますので御用の方は弊社までお問い合わせください。