こんにちは。
もぐめっとです。

最近はfirestoreを使ってゴリゴリとサービスを作っています。
webでもアプリでもURLをシェアすればすぐにチャットできるoffchaとか、
部屋を作って共通の話題で話してハッピーになるfrieppyとか作ったり、
もっとフォトコンを気軽にできるCameconの設計したり、
寂しい時に話し相手になってくれるメンヘラ先輩の設計手伝ったり
なんか色々作ったりしてます。
そんなfirestoreにもみくちゃにされている中、福田雄貴氏による実践Firestore(以下聖書)を読んだので、その中でも個人的に知らなかったり、抑えたほうがいいなと感じたところがたくさんある良書だったので、そのいくつかを紹介させて頂きます。
データアクセス
データへのアクセス方法は色々やり方があるのですが、その中でも印象に残ったものをピックします。
実はOR(IN句を使って)検索できます
最近追加されたもののせいか、「firestore or」とかで検索しても一番上にドキュメントが出てこないのでメモ的なところもこめて。
こんな感じでOR検索できます。
データのクエリとフィルタ in と array-contains-any
citiesRef.where('country', 'in', ['USA', 'Japan']);
あと、array-contains-anyも割と強力で配列の中で含まれてるかどうかのor検索ができます。
citiesRef.where('regions', 'array-contains-any', ['west_coast', 'east_coast']);
ただし、10個までしか使えないのでご注意。
次のページを取得する
この方法はきっとfirestore使いまくってる方なら常識かもしれませんが、私が単に抜けていただけなのでメモがてら紹介。
limitをかけないとデータの取得は料金やデータ転送量がすごいことになるので、limitをかけてデータを取得とかやっているかとおもいますが、そのときによく見かけるのが、次のページとか追加データを読み込む処理ですね。
cameconでもこんな感じでもっと読み込むとか、
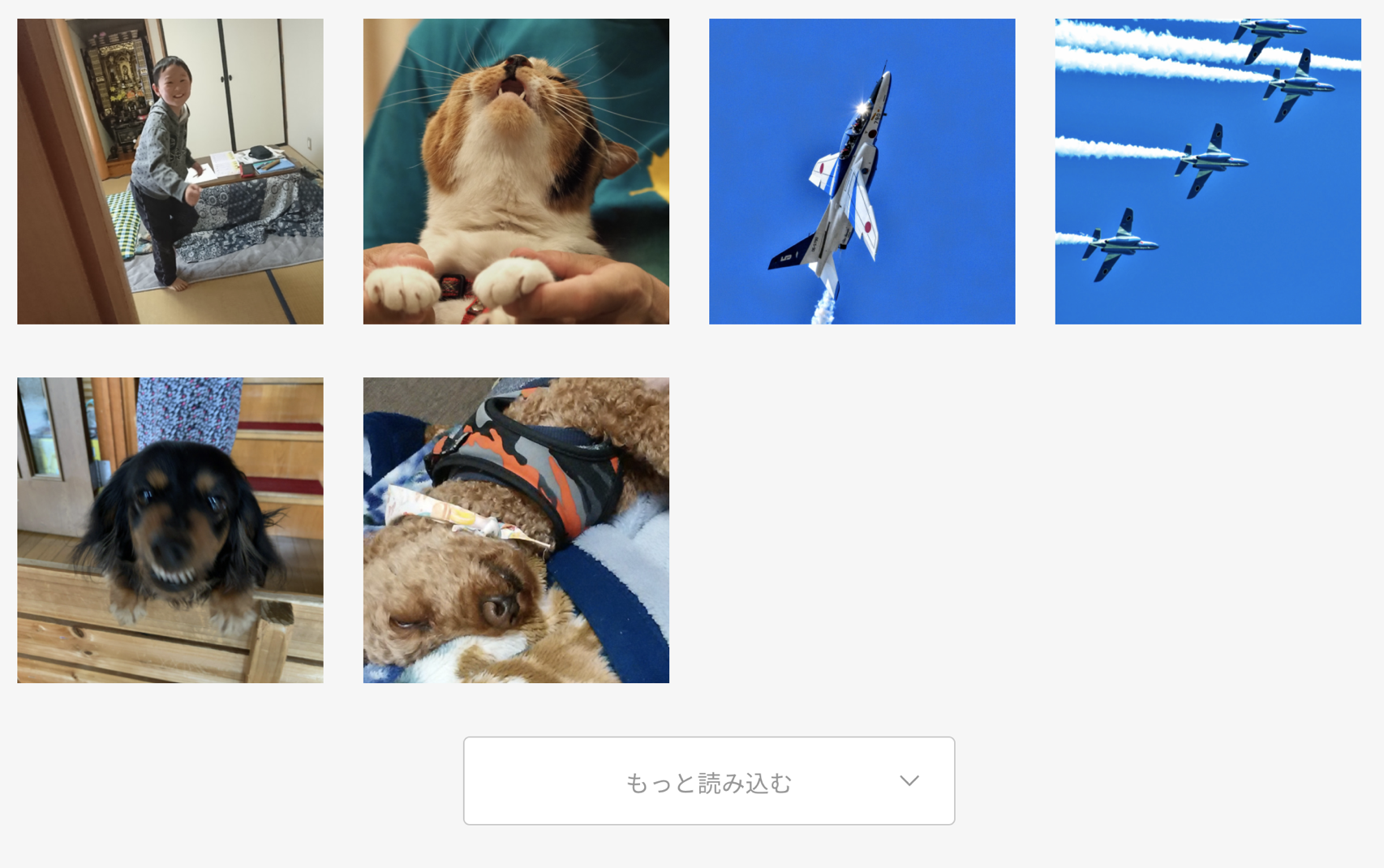
offchaでも追加読み込みするのに使ったりしてます。
今まではcreatedAtとかで時間に対してorderかけて、次の読み込みは日付を指定してたりしてたんですけど、聖書によると、DocumentSnapshotで取得もできるんですが、知らなかった・・・ってなりました。
(しかし、あとでドキュメント見返したら普通に書いてありました。よく読めって話ですね。)
cf: クエリカーソルを使用したデータのページ設定
var first = db.collection("cities")
.orderBy("population")
.limit(25);
return first.get().then(function (documentSnapshots) {
// Get the last visible document
var lastVisible = documentSnapshots.docs[documentSnapshots.docs.length-1];
console.log("last", lastVisible);
// Construct a new query starting at this document,
// get the next 25 cities.
var next = db.collection("cities")
.orderBy("population")
.startAfter(lastVisible)
.limit(25);
});
synchronizeTabs = trueにする
trueにすることで、複数のタブでキャッシュを共有して、クエリや、更新なども共有するようになります。
デフォはオフになっていて、毎回複数タブ開くと警告でるので、とりあえずtrueにしとくのがよさそう。
cf: Properties - PersistenceSettings | JavaScript SDK | Firebase
トランザクションは遅いので濫用しない
他のRDBMSと比べるとトランザクション処理は遅いので、なるべく用途を絞りましょうとありました。
トランザクションを選定する基準としては下記で考えるといいと聖書にはありました。
- あるユーザーが書き込みを行った結果をサーバーにコミットせずに処理を続行することが業務上必要不可欠かどうか
- 他のユーザーに不利益を与える可能性があるかどうか
UXや整合性のバランスを見て決定するといいようです。
セキュリティールール
1つのユースケースに1ルール
ユースケースごとに細かくルールを分けて疎結合にすることによって保守性が高まります。
とくにwriteとかでくくってしまうと、create/updateと同じルールを考えないといけなくなり、影響範囲や依存調査が複雑になってカオス化するので、使うのはダメ絶対です。
request.auth.tokenをうまく使う
email情報や、email認証したかどうかなどはFirebase Authenticationによって管理できるので、そういったセンシティブな情報はfirestoreに格納するのではなく、Firebase Authenticationを使いましょう。
具体的な内容だとこんな感じのものがとれます。
cf: セキュリティ ルールと Firebase Authentication - Google
メール認証したユーザだけ作成できるようにするとかだとこんなかんじでしょうか
service cloud.firestore {
match /databases/{database}/documents {
match /users/{userId} {
allow create: if request.auth.email_verified == true;
}
}
}
Custom Claimを使う
これ使うと、ユーザの属性を付与することができて、adminのユーザだったら〜みたいなこともセキュリティールールでできるようになります。
めっちゃ便利。
カスタム クレームとセキュリティ ルールによるアクセスの制御
allow read, wirte: if request.auth.token.admin == true;
ただ、設定するにはAdmin SDKを使って設定する必要があります。
聖書ではFirebaseAuthenticationでユーザが作られたタイミングでCloudFunctionsを起動して付与するといった方法が紹介されてましたが、他にもrolesみたいなコレクションを作って、そこにドキュメントを追加したらCloudFunctionsを起動させて、対象ユーザにclaimを付与するといった形でやるのもいいと思います。
サイズ上限を設定する
stringとか配列について無制限にしてしまうと攻撃社に巨大なデータが作られて大変なことになるので、N文字までや配列はN個までみたいな制限をかけるようにしましょうとありました。
一個一個チェックするのは割と面倒ですが、ちゃんとやらないとですね。
アトミックオペレーションはgetAfterをうまく使う
transactionやbatchでまとめた処理のチェックをする方法として、getAfterを使って、チェックすることが可能です。
Cloud FirestoreのセキュリティルールでgetAfter関数が使えるようになったので使ってみた
service cloud.firestore {
match /databases/{database}/documents {
// If you update a city doc, you must also
// update the related country's last_updated field.
match /cities/{city} {
allow write: if request.auth.uid != null &&
getAfter(
/databases/$(database)/documents/countries/$(request.resource.data.country)
).data.last_updated == request.time;
}
match /countries/{country} {
allow write: if request.auth.uid != null;
}
}
}
この例では、cityのドキュメントの書き込みを行うときは、
/databases/$(database)/documents/countries/$(request.resource.data.country) で参照できる countryのドキュメントの last_update も同時に更新されている(city書き込み時のrequest.timeと一致)のを条件にしています。
公式のサンプルがなかったので上記記事を参照させていただきました。感謝🙏
ただ、getAfter自体は10回までの制限があったり、お金もかかったり、ルールも複雑になったりもあるので、場合によってはアトミックオペレーションを避けて、CloudFunctionでやってしまうというのも考慮する点はあると思います。
これもUXやデータの整合性といったところで使うかどうかを判断するのがいいと思います。
ルールを書くときに意識する事
聖書より抜粋させていただきます。
- 公開ドキュメントは認証状態にかかわらず読み書き可能か
- 認証されたユーザーだけに読み書きが限定されているか
- アカウントの有無だけでなく、IDトークンに設定された値を用いた権限の妥当性確認が行われているか
- 特定のユーザーと関連を持つドキュメントは、ユーザーIDとドキュメントIDが関連付けられ、読み書きが限定されているか
不正なデータが書き込まれたり、読まれてはいけないものが読まれないようにとデータの種類を意識して組むといいですね。
データモデリング
1回描画するのに必要なデータは1つのドキュメントになるだけ詰める
firestoreはreadの回数に応じてコストもかかるのでなるべくリード数を減らすのがお財布にも、UXにもよいです。
例えば商品のページで、商品へのレビューを3件表示するという要件があった場合に、firestoreの設計はこんな感じとします。
- products(サブコレクション)
- reviews(サブコレクション)
愚直にやると、productsとreviewsの2つを読まないとレビューも含めた表示はできませんが、レビューの内容のコピーをドキュメント自体に持たせてしまうといったことで、reviewsのサブコレクションをリードすることなく表示に必要なデータを取得することができます。
いわゆる非正規化というやつですね。
ネスト要素はサブコレクションに持ってく
ネストを紹介したものの、早速その逆のお話もあります。
先程の非正規化はビューのためにadmin側で追加といった形で制御するので問題ないと思いますが、クライアント側でドキュメントに何でも突っ込めるからと言ってユーザコンテンツを一つのドキュメントにいれすぎてしまうのも今度はセキュリティールールの観点でチェックが難しくなってしまいます。
そのため、サブコレクションに分けたほうがいいものに関してはサブコレクションにもっていきましょう。
スピードを取るか、複雑さをとるかというのもメリットを考えた上で判断していきましょう。
Updateは避ける
Updateの処理は更新ケースのセキュリティールールが、複雑になりがちで、CloudFunctionsでも余計な分岐処理が走りがちになってしまいます。
ではどうすればいいか?という解決策としてCreateに持っていってしまうという手があります。
たとえば、住所、電話番号、etc...などのユーザ情報を更新するといったときに、Updateを使うのではなく、更新履歴としてサブコレクションにCreateしていくといった手法が紹介されていました。
createされたタイミングでCloudFunctionsでユーザ情報を更新することによって、チェックロジックをCloudFunctionsで持つことができるためセキュリティールールも簡素化できるという素晴らしい特典付きです。
いわゆる履歴テーブルの設計パターンになるのですが、そこらへんは参考記事を貼っておきます。
履歴を持ったテーブルの設計
そういえば昔、論理削除について話し合うというマニアックな勉強会に参加したときにも削除履歴テーブルについてのお話もありました。
#ronsakucasual DBの論理削除についてひたすら共有する 論理削除 Casual Talks #1 にいってきたまとめ
ドキュメント同士の関連はReference型を使う
firestoreにはデータの参照先を表すReference型というものがありますが、(いわゆるC言語でいうポインタみたいなもの)こちらを使っていこうというお話です。
DocumentIdを示したhogehogeIdだけでも情報としては足りるのでは?というお話もありますが、それだけですとパス情報がなくなっているため正確にデータ先を参照することができません。
Frieppyでは、普通の部屋とDMの部屋とでコレクションを分けていて、構造も大体一緒の形になっていたのですが、当初はroomのIDしか保存していなかったため、正確なパスを参照することができず、謎の部屋ができてしまうというバグもあったりしました。
| 普通の部屋 | DMしてる時の部屋(残ハッピーポイントがつく) |
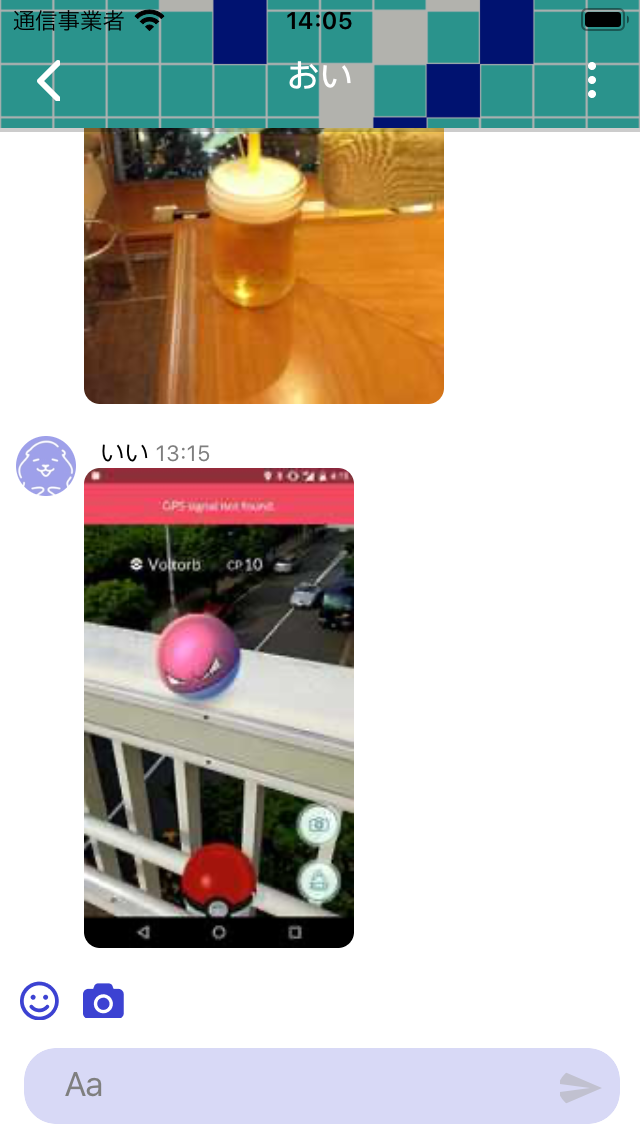
|
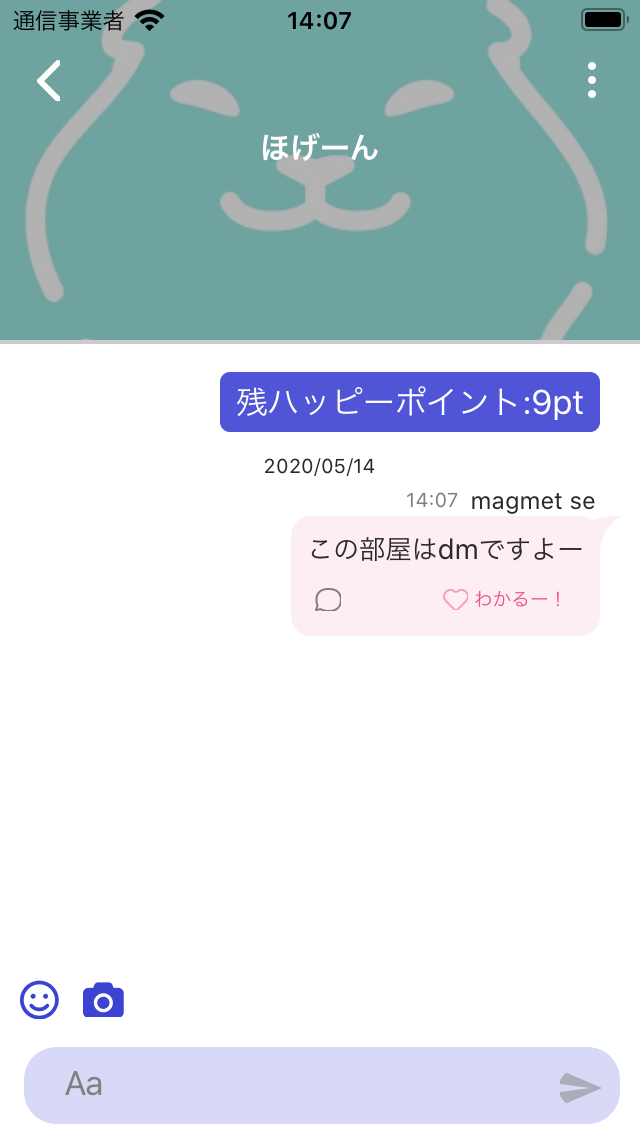
|
なので、idだけでは足りないので、Referenceを保存しておくことを強くおすすめします!!
非正規化してもReference型を残しておく
先程、リード速度向上のために、非正規化してドキュメントにデータを詰め込もうというお話をしたと思いますが、その際に、元データへのReferenceを入れておくと色々と便利になります。
例えば、あるユーザがレビューした内容にはユーザ名などのユーザ情報が非正規化して入ってたとすると、そのレビューしたユーザが名前を更新すると当然非正規化したほうのデータにも名前を更新する必要が出てきます。
そこで、聖書では、その非正規化したreferenceをキーとしてCloudFunctionsで一斉更新をかけるという例を紹介されてました。
しかし、レビューの量が増えてくるとユーザ情報の更新のたびに更新するコストがかかってしまうので、ユーザ情報更新に回数制限をいれたり、一定時間たったレビューはユーザ名を非表示にするとよいとの紹介がありました。
私が他に考えつく方法としては下記手法があります。
1. 対象ユーザがレビューを開いたときだけクライアント側でキックして更新させる。
更新大変なのでユーザ名がアンマッチしてたら更新させるという作戦です。
ただし、他のユーザからすると一部表示に不整合が見られることにはなります。
2. そもそもユーザ名をいれない
ユーザ名は出さずに、ユーザの画像だけにしてしまうとか、そもそもユーザ名は出さないデザインにしてしまうといったことで更新コストを減らします。
デザイナーさんとUXなどについて要相談にはなります。
おまけ. 画像については同じパスで更新する
ユーザの画像に関しては同じパスでアップデートしてしまえば、クライアントのキャッシュが切れた時点で自動的に更新されるので、各非正規化データに更新を掛けなくても更新することができます。
ただし、こちらも他のユーザからすると画像に不整合が見られます。
まとめ
- サービスのユースケースごとに設計や実装を細かく考えよう!
- UXや、コスト、拡張性など様々な観点から考えて設計しよう!
- セキュリティはできるだけもれないように頑張る!
みなさんのfirestoreライフに少しでもお役に立てたら幸いです。
Have a nice firestore!
本の書簡については自分のブログにひっそりかいておきました。