はじめに
最近HTTPについていろいろと勉強する機会があったので、これを機にHTTP/2についてまとめてみました。
HTTP/2は標準化から3年が経過し、意識こそしていないものの普通に使われるようになってきました。なんとなくサーバーをHTTP/2使うように設定したけど、なにが良くなったのかイマイチ知らないというような人が読んで、理解できる記事を目指してみたつもりです。
HTTP/2がもたらしてくれるものとその仕組みをなるべく簡潔に噛み砕いて書いてみました。そのため、この道の専門の方からすると、不十分な表現や不適切な表現、或いは私の誤った理解などがあるかもしれません。
そのような箇所を見つけたられた際には、ぜひコメントなどから指摘いただけると幸いです。
HTTPとは
HTTPは皆さんもよくご存知であろうプロトコルの名称です。正式な名前はHyper Text Transfer Protoclと言います。つまりハイパーテキスト(HTMLのことですね)をやりとりするためだけのプロトコルとして誕生しました。
今日では、HTMLだけではなくJSON/XMLのやりとりや画像などのバイナリデータのやりとりなどの用途で用いられることが当たり前となりました。
HTTPにはいくつかのバージョンがあります。1990年代に発表された最初期のHTTPは0.9、そして現在広く用いられてHTTPが1.1です。
HTTP/1.1は1997年に策定され、現在まで広く用いられているとても歴史の長いプロトコルです。十数年利用されてきた中で、生まれた欠点を克服するために誕生したのがこの記事で取り扱うHTTP/2です。
HTTP/2は2015年5月に標準化され、現在では多くのWebサイトやWebアプリケーションがHTTP/2を利用しています。まだ「自分のWebサーバーはHTTP/1.1のままだ…!」とか、「HTTP/2を使う設定にしたけど何が変わったのかわからない!」という人の一助となる記事になっていると嬉しいです。
それでは前置きが長くなってしまいましたが、本題に入っていこうと思います。
HTTP/1.xのおさらい
HTTP/2のことを知る前に、前身であるHTTP/1.1がどのようなプロトコルであるかを簡単におさらいしておきます。
HTTPクライアントはサーバーにTCP接続をした後にテキストでリクエストを送信します。その様子はcurlコマンドなどを使うことで簡単にみることができます。以下にexample.comへ接続した例を示します。
$ curl -v example.com/
* Trying 93.184.216.34...
* Connected to example.com (93.184.216.34) port 80 (#0)
> GET / HTTP/1.1
> Host: example.com
> User-Agent: curl/7.47.0
> Accept: */*
>
< HTTP/1.1 200 OK
< Accept-Ranges: bytes
< Cache-Control: max-age=604800
< Content-Type: text/html
< Date: Fri, 18 May 2018 00:52:21 GMT
< Etag: "1541025663"
< Expires: Fri, 25 May 2018 00:52:21 GMT
< Last-Modified: Fri, 09 Aug 2013 23:54:35 GMT
< Server: ECS (oxr/83C5)
< Vary: Accept-Encoding
< X-Cache: HIT
< Content-Length: 1270
<
(以下HTMLが続く)
>から始まる行がHTTPのリクエスト、反対に<から始まる行がサーバーからのレスポンスです。
リクエストはGET / HTTP/1.1という行から始まります。今回の例でいうとHTTP/1.1を利用して、GETメソッドで/を取得するというリクエストになります。その後に続く3行(Host/User-Agent/Accept)はHTTPのリクエストヘッダで、キーと値をコロンで区切って記述するというルールになっています。
今回のリクエストヘッダにはリクエスト先のホスト名(Host)、自身の情報(User-Agent)と自身が受け取ることのできるレスポンスの形式(Accept)が含まれています。実際のブラウザからのリクエストにはこれらのヘッダに加えてCookieや、認証用のヘッダーが付与されることが多いです。
ヘッダが終わると空行が送信されてリクエストは終了となります。(今回の例にも空行が含まれているのが確認できると思います)
そして、HTTP/1.1 200 OKという行から始まるのがサーバーからのレスポンスです。リクエストの時と同様にレスポンスにもヘッダーが付与されて送信されてきます。そして、ヘッダーが終了すると空行を挟んで実際のHTMLが送信されてきます。
これが、HTTP/1.1の概要です。テキストをベースにしたシンプルなプロトコルであることがわかっていただけたでしょうか?
HTTP/1.1の課題
HTTP/1.1にはいくつかの課題がありました。以下にその一例を示します。
リクエストの多重化
通常、WebサイトはHTMLに加えてCSSや画像などの複数のリソースが集まって表示されています。
例えばQiitaのトップページが表示されるまでには80回以上のリクエストが発生していることがわかります。(左下に注目)
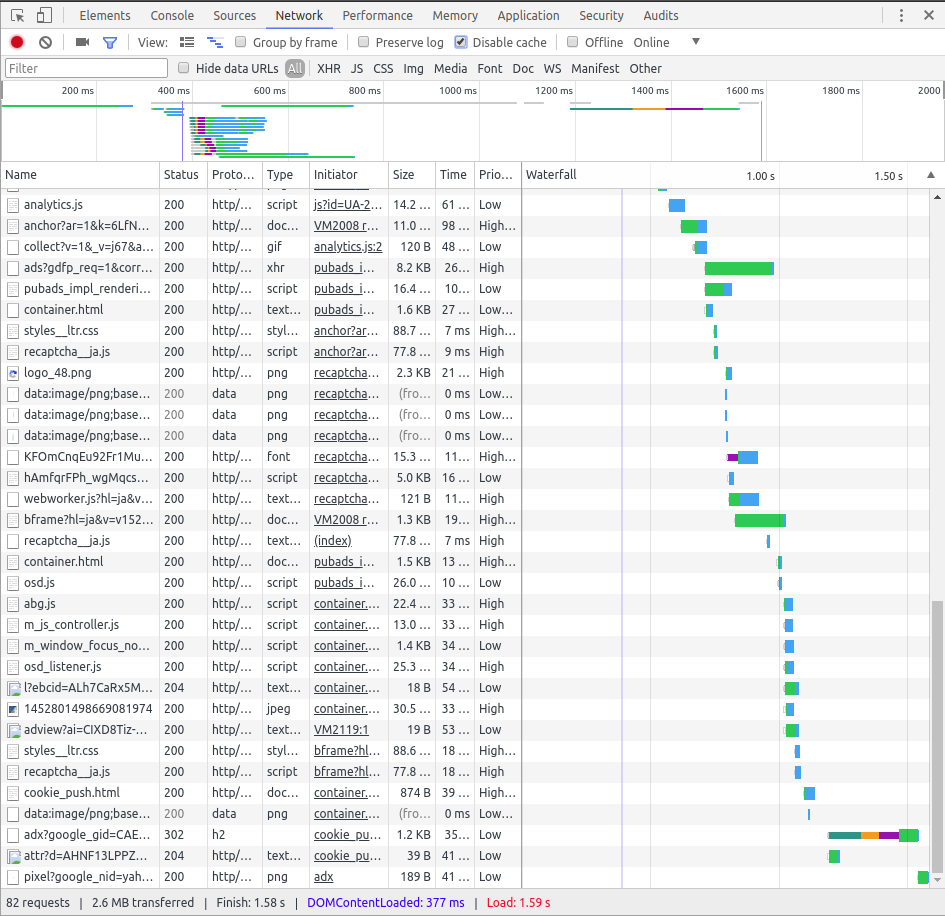
しかし、HTTP/1.xでは、1つの接続で同時にダウンロードできるのは1つのリクエストに限ります。つまり、HTMLをダウンロードしている間は、そのページの表示に必要な画像があったとしてもダウンロードを開始することができません。
この問題に対処するため、ブラウザはサーバーに対して複数のTCP接続を張ることで多重化を実現していました。
しかし、TCP接続の数が増えるということは、サーバーにとって負荷の大きい処理の一つであるということが課題となっていました。
プロトコルオーバーヘッド
よく「HTTPはステートレスなプロコトル」というような言われ方をしますが、どういうことでしょうか。
ステート(state)、つまり状態を持っておらず一回一回のリクエストはそれぞれ別のものとして扱われるということです。でも、Webサイトにはログイン機能があるし、状態を持っているじゃないか!と思われるかもしれませんが、それはCookieなどを用いて実現されており、個々のリクエストの間にプロトコルとしての関連はありません。
ログイン機構を持つようなページではCookieや、独自のトークンなどをリクエストヘッダに付与してリクエストを送信しています。場合によってはこれらのヘッダーだけでも数十KBになってしまうこともあります。そのヘッダーを毎回送信する必要があるため、小さなリソースに対するリクエストを大量に送信するような場合、オーバーヘッドが大きくなりがちという課題がありました。
余談ですが、このような課題を解決するためになるべくリクエストを送る数を減らす工夫がWeb制作の現場では行われてきました。その一例としてCSSスプライトと呼ばれる手法があります。
CSSスプライトは複数のアイコンなどの画像を一枚の大きな画像に並べて配置し、CSSで表示位置をずらすことによって使用する手法です。(これにより、アイコン素材の読み込みにかかるリクエストは1回になる)
アイコン画像などをCSSスプライトにまとめる方法 | Rriver
その他にも、画像をBase64エンコードし、HTMLに埋め込むといった手法もあります。
HTTP/2の歴史
現在RFC7540として標準化されているHTTP/2はGoogleの開発したSPDYというプロトコルから始まりました。
Googleは、自身が開発したプロトコルを自身のサービスで使用できるようにし、Google Chromeをクライアントとすることにより標準化前から利用実績を作りました。
後に、SPDYはIETFのHTTPbisというワーキンググループによって標準化作業が進められました。
SPDYプロトコルについてはこちらの記事が大変詳しく書かれていたので引用させていただきます。
Web表示の高速化を実現するSPDYとHTTP/2.0の標準化 | IIJの技術 | インターネットイニシアティブ(IIJ)
HTTP/2の特徴
ここからはHTTP/2の主な特徴について触れていきます。
1つのTCP接続
HTTP/2ではそれ以前とは異なり、1つのTCP接続を用いて複数のリクエスト/レスポンスのやり取りをできるようになりました。
以下はHTTP/2を使用したサーバーに対して画像が100枚を参照しているHTMLをリクエストした際の様子です。
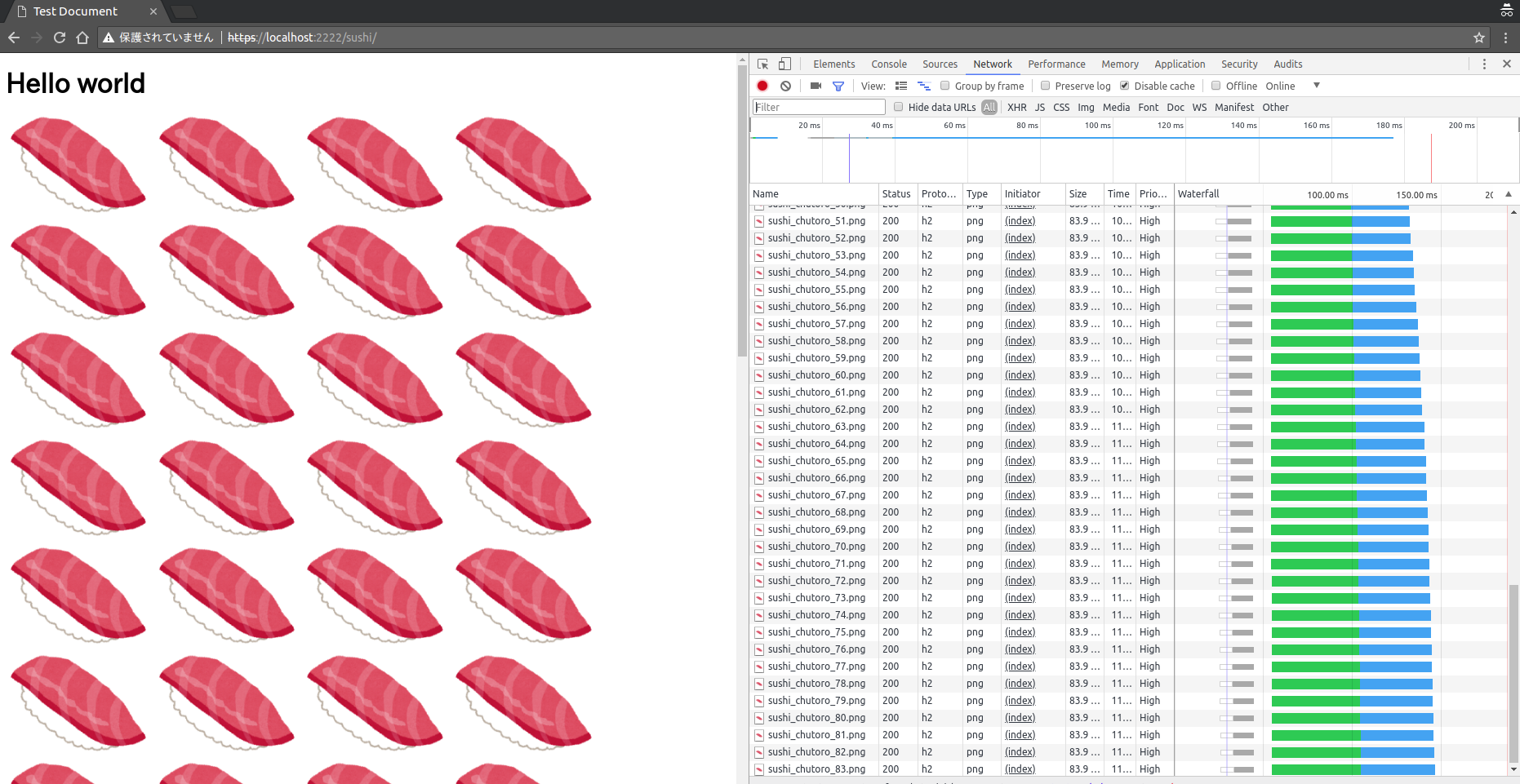
画面右にあるウォーターフォールを見るとわかるように複数のリクエストが同時並行で進行しているのがわかると思います。
これと全く同じページをHTTP/1.1を使用したサーバーを用いて表示してみると以下のようになります。
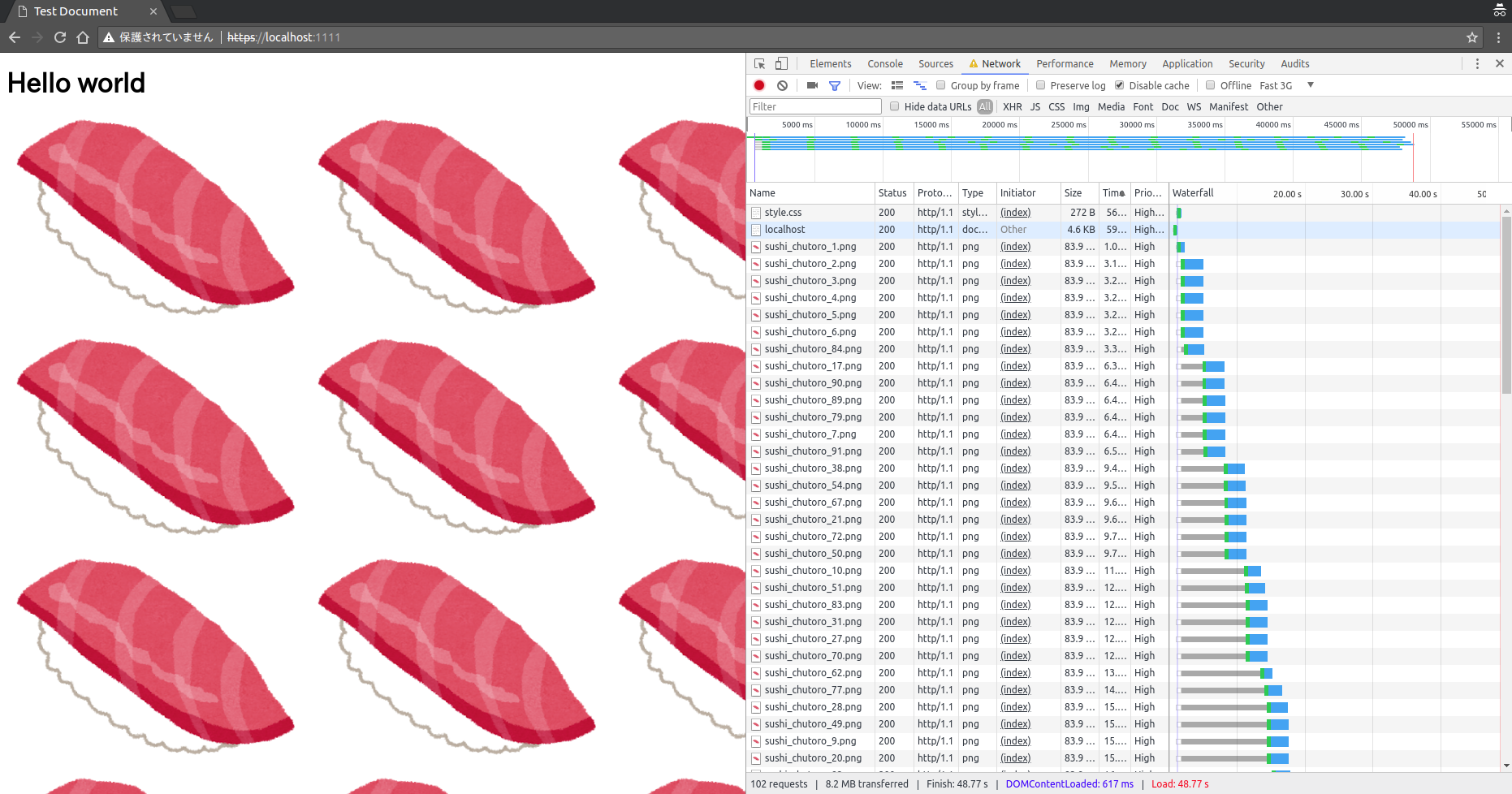
(様子がわかりやすいようにネットワークの速度を落としています)
最大でも同時に6つのリクエストしか処理できていないようのがわかります。(Chromeでは一つのオリジンに対して最大で6のTCP接続を行う)
HTTP/2は1つのTCP接続上にストリームと呼ばれる仮想的な接続を(複数個)作成します。データはフレームと呼ばれる単位でストリーム上でやり取りされます。フレームにはいくつかの種類があり、従来のHTTPヘッダの役割をするHEADERSフレームや実際のデータ(ボディ)が送信される際に用いられるDATAフレームなどがあります。
これは多くのメリットを生み出します。
まず、TCP接続が1つになったことにより、サーバーの負荷低減につながります。
それだけではなく、TCP接続の際に必要となる3ウェイハンドシェイク1やTLSハンドシェイク2なども一度で済むというメリットもあります。
バイナリベース
HTTP/2以前のHTTPはテキストベースのプロトコルでした。1行目にパスとメソッドが来てそこから次の空行が来るまで1行づつkey: valueの形でヘッダーが来て……といった調子です。極めてシンプルでわかりやすいですが、必ず上から順番に読んでいかないと解釈できないためムダも多いという弱点がありました。
しかし、HTTP/2ではバイナリベースのやり取りへと変更されました。
前述の通り、ヘッダーやボディはそれぞれ別のフレームとして送信されてくるため、処理系もフレームのタイプに合わせた処理を行えば良くなるというメリットがあります。
ヘッダの圧縮
ヘッダには多くの情報が含まれる場合があり、それがオーバーヘッドに繋がる場合があるというのは前述の通りです。
そこで、HTTP/2にはヘッダの圧縮機能が付きました。ヘッダはHPACKと呼ばれる方式を用いて圧縮されます。
HPACKはHTTP/2の為に作られた圧縮方式で、通常の圧縮アルゴリズムとは異なり、事前に共有された辞書を持っているという特徴を持っています。
なぜなら、HTTPヘッダは特定の単語が頻出する傾向にあるので、事前に辞書を共有しておくことで、より効率よく圧縮を行うことができるからです。
HPACKの仕様が定義されているRFC7541には以下のように事前に共有される辞書が定義されています。
+-------+-----------------------------+---------------+
| Index | Header Name | Header Value |
+-------+-----------------------------+---------------+
| 1 | :authority | |
| 2 | :method | GET |
| 3 | :method | POST |
| 4 | :path | / |
| 5 | :path | /index.html |
| 6 | :scheme | http |
| 7 | :scheme | https |
| 8 | :status | 200 |
| 9 | :status | 204 |
| 10 | :status | 206 |
| 11 | :status | 304 |
| 12 | :status | 400 |
| 13 | :status | 404 |
| 14 | :status | 500 |
| 15 | accept-charset | |
| 16 | accept-encoding | gzip, deflate |
| 17 | accept-language | |
| 18 | accept-ranges | |
| 19 | accept | |
| 20 | access-control-allow-origin | |
| 21 | age | |
| 22 | allow | |
| 23 | authorization | |
| 24 | cache-control | |
| 25 | content-disposition | |
| 26 | content-encoding | |
| 27 | content-language | |
| 28 | content-length | |
| 29 | content-location | |
| 30 | content-range | |
| 31 | content-type | |
| 32 | cookie | |
| 33 | date | |
| 34 | etag | |
| 35 | expect | |
| 36 | expires | |
| 37 | from | |
| 38 | host | |
| 39 | if-match | |
| 40 | if-modified-since | |
| 41 | if-none-match | |
| 42 | if-range | |
| 43 | if-unmodified-since | |
| 44 | last-modified | |
| 45 | link | |
| 46 | location | |
| 47 | max-forwards | |
| 48 | proxy-authenticate | |
| 49 | proxy-authorization | |
| 50 | range | |
| 51 | referer | |
| 52 | refresh | |
| 53 | retry-after | |
| 54 | server | |
| 55 | set-cookie | |
| 56 | strict-transport-security | |
| 57 | transfer-encoding | |
| 58 | user-agent | |
| 59 | vary | |
| 60 | via | |
| 61 | www-authenticate | |
+-------+-----------------------------+---------------+
この表に現れるヘッダに関してはIndexのみで表すことができます。それに加えて、この表にないヘッダはコネクションが続く間、クライアントが持っているテーブルに保持しておいて、再度登場した時にはそのインデックスを用いることができるようになっています。
また、複数のリクエストにおいてヘッダに差分がない場合は送信を行わない為、ヘッダーによるプロトコルオーバーヘッドはHTTP/2によって解消されたと言えるでしょう。
リクエストの優先度制御
前述したとおり、HTTP/2以前は複数のTCP接続を用いて多重化を行っています。限られた帯域やリソース(サーバーの処理能力)の中でどのリクエストを優先するか、という処理はブラウザなどのクライアントが行っていました。
しかし、HTTP/2ではクライアントからサーバーに対してリソースの優先度を指定することができるようになりました。適切な優先度を指定することで、WebサイトやアプリケーションのUXの向上などを見込めます。
具体的には、ストリームに対して優先度を0から2^31-1の31ビットの値で指定することができます。0が最優先で2^31-1が最も優先度の低いストリームです。
優先度の提案は、PRIORITYフレームによって送信されます。提案と書いたように、クライアントからサーバーへ送られた優先度はあくまでも提案で無視しても良いことになっています。また、どのようなアルゴリズムを用いてスケジューリングを行うかは実装依存となっています。
サーバープッシュ
ここまで取り上げてきたHTTP/2の新機能はすべて既存の機能の改善ですが、サーバープッシュはHTTP/2以前には存在しなかった全く新しい機能です。
例えば、Webサイトを表示するために、以下のような/index.htmlをサーバに対してリクエストしたとします。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<title>Example</title>
</head>
<body>
<h1>大都会 八王子市の紹介</h1>
<p>八王子は大都会です。みんな来てね!</p>
<img alt="八王子の写真" src="img/hachioji.jpg">
</body>
</html>
ブラウザなどのクライアントはこれを受け取ると上から順番にパースを始めます。そしてimgタグに到達したところで、画像を追加でサーバーに対してリクエストします。
追加で送ったリクエストが完了するまで画像は表示されません。
これが通常のフローです。画像に限らずJSやCSSでも同じような問題が起こります。
そこでサーバープッシュです。サーバープッシュは今回の例で言うとindex.htmlと同時にimg/hachioji.jpgも(クライアントからのレスポンスなく)返すことができるというものです。サーバーからリソースをプッシュするのでサーバープッシュです。
サーバープッシュが行われるると、クライアントはプッシュされてきたリソースをキャッシュします。そして、HTMLをパースし画像を発見し、リクエストを送信するタイミングでキャッシュを見に行くと既に画像が存在することがわかり、新規のリクエストを発行することなくページを表示することができるというからくりです。
また、サーバープッシュは必ずしも、参照されているリソースをプッシュしなければならないというわけではなく、投機的に参照されるかもしれないリソースについてもプッシュすることができます。
各種ブラウザの対応状況
2018年5月現在、主要なモダンブラウザは一通り対応していると思って問題ないでしょう。
以下はCan I useの結果です。

Can I use... Support tables for HTML5, CSS3, etc
使い方(Nginxでの例)
サーバー側も主要なWebサーバーの最新版ではHTTP/2の対応ができていると思って問題ないでしょう。
ここでは例として、Nginxでの設定方法を簡単に示します。と言っても本当に簡単で、serverディレクティブのlistenの値にhttp2と付け加えるだけです。
server {
listen 443 ssl http2 default_server;
server_name _;
ssl on;
ssl_prefer_server_ciphers on;
ssl_certificate /etc/nginx/server.crt;
ssl_certificate_key /etc/nginx/server.key;
location / {
root /usr/share/nginx/html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
}
最も簡単な構成だとこのようになるでしょうか。
動作確認方法としては、[HTTP/2 and SPDY indicator](HTTP/2 and SPDY indicator)というChrome拡張機能を用いるか、以下の画像のようにDev Toolを開き、ネットワークタブからも確認することができます。
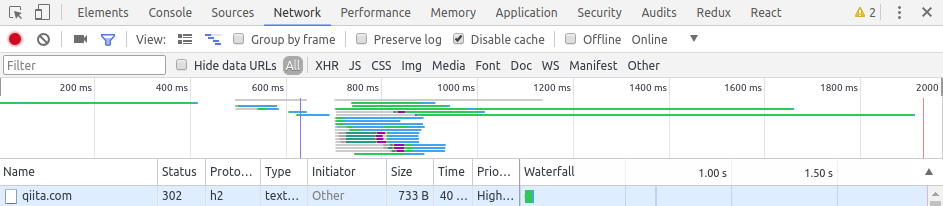
(切れてしまっていますが、Proto...となっているところが使用しているプロトコルです。h2となっていればHTTP/2を用いています。Protocolの列が表示されていない時はいずれかの列の先頭あたりで右クリックすると表示項目を増やすことができます。)
一つ注意点として、HTTP/2は実質的にはTLSでしか用いることができません。プロトコル仕様上は暗号化なしの通信でもHTTP/2は用いることができますが、Chrome含め主要なブラウザは基本的にTLSを用いた通信でしかHTTP/2を使用できないようにしています。
理由としては、暗号化通信の普及促進などが挙げられます。
参考文献
- HTTP/2 の概要 | Web | Google Developers
- Ilya Grigorik著『ハイパフォーマンス ブラウザネットワーキング』(オライリー・ジャパン刊)
- 渋川よしき著『Real World HTTP』(オライリー・ジャパン発行)
-
TCPで接続を行う際に必要となる3回のパケットのやり取りのこと。(3ウェイ・ハンドシェイク - Wikipedia) ↩
-
鍵交換などを行うためのパケットのやり取りのこと。(SSL/TLS(SSL3.0~TLS1.2)のハンドシェイクを復習する - Qiita) ↩