先の記事では、Haskellエコシステムに色々ある文字列型を分類しました。この記事では、色々ある文字列型を変換する方法を説明します。
パッケージの依存関係:変換関数を探すにはどこを見れば良いか
各種文字列型や変換関数を提供するパッケージ間の依存関係は次のようになっています(依存元パッケージから依存先パッケージに矢印を伸ばしています):
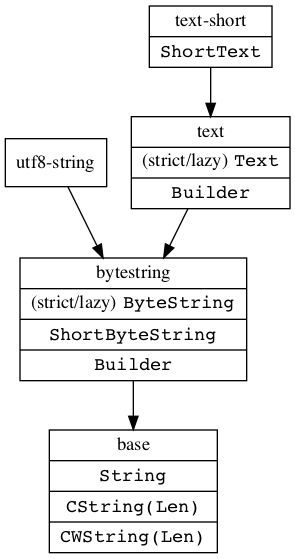
当たり前ですが、変換関数が用意されているとしたら変換元の型と変換先の型の両方を参照できるパッケージです。つまり、 Text と ByteString の変換関数を探したかったら bytestring パッケージではなく text パッケージを探すべきです。なぜなら、 bytestring パッケージの関数は Text 型には言及できないからです。
同様の理由で、 ByteString と CStringLen の変換関数を探したかったら bytestring パッケージを探すべきです。また、 Text を ByteString Builder に書き出す関数を探したかったら text パッケージを探すべきです。そして、 ShortText を他の型と変換する関数は全て text-short パッケージにあるはずです。
例外として、 String と ByteString をUTF-8で変換する関数は utf8-string パッケージにあります。
Unicode文字列同士の変換
Unicode文字列同士の変換の場合は、エンコーディングや変換失敗時の挙動はあまり考える必要はありません。厳密に言えば String から Text 系への変換時はサロゲートコードポイントの扱いを考える必要がありますが、デフォルトの挙動で問題ないことが多いでしょう1。
ここでは、以下の5つの型(Unicode文字列型、あるいは文字列ビルダー型)の変換方法を図でまとめておきます。
-
String(=[Char]) - strict
Text - lazy
Text ShortText- Text
Builder

図の中でモジュール名は以下のように略しています。Data.Text.Short 以外は text パッケージで提供されています。
-
T:Data.Text -
TL:Data.Text.Lazy -
TB:Data.Text.Lazy.Builder -
TS:Data.Text.Short(text-short パッケージ)-
ShortTextはtextとは別のパッケージで定義されている関係で、ShortTextが絡む変換は全てData.Text.Shortで定義されています。
-
lazy Text は strict Text のリスト [T.Text] に近い構造で定義されているので、strict Text から lazy Text への変換(TL.fromStrict)は低コストで行えます。文字列型を Builder に埋め込む関数も、その段階ではコピーは行われないので低コストです。他の変換関数は多くの場合データのコピーを伴うので、長さに比例した時間がかかります。
Text Builder から直接出力できる文字列型は、 lazy Text のみです。strict Text が欲しい場合は、一旦 lazy Text を出力してから toStrict する必要があります。
ShortText と lazy Text を直接変換する関数は text-short パッケージからは提供されていないようです。
バイト文字列同士の変換
バイト文字列同士の変換も、エンコーディングや失敗時の挙動は考える必要はありません。
ここでは、以下の5つの型の変換方法を図示します。
[Word8]- strict
ByteString - lazy
ByteString ShortByteString- ByteString
Builder
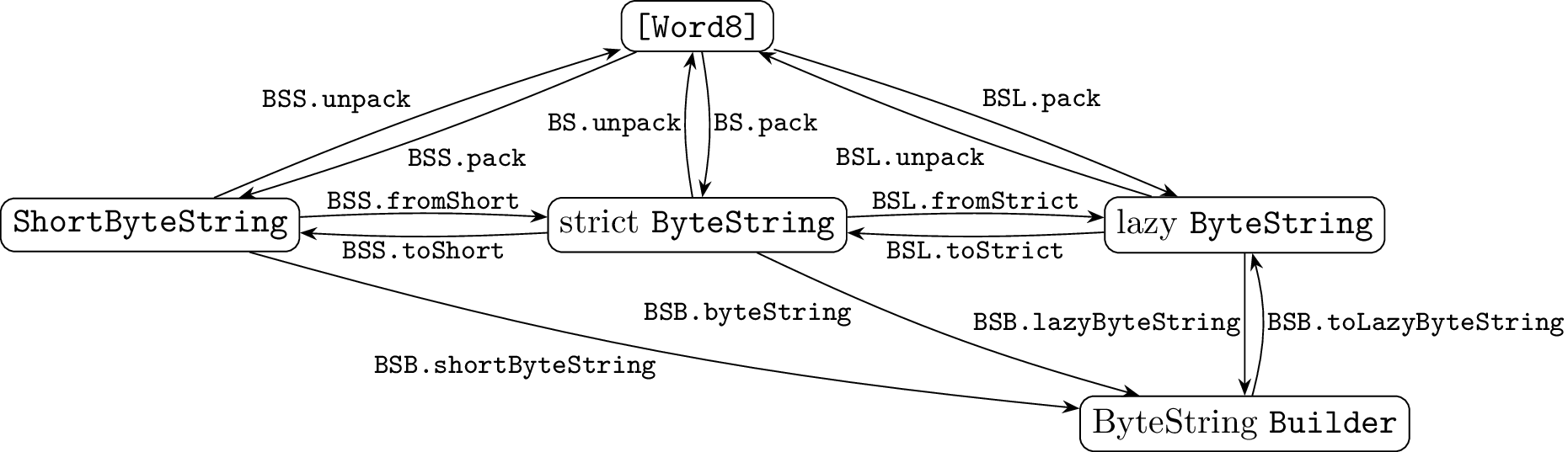
図の中でモジュール名は以下のように略しています。いずれも bytestring パッケージで提供されています。
-
BS:Data.ByteString -
BSL:Data.ByteString.Lazy -
BSB:Data.ByteString.Builder -
BSS:Data.ByteString.Short
lazy ByteString は strict ByteString のリスト [BS.ByteString] に近い構造で定義されているので、strict ByteString から lazy ByteString への変換(BSL.fromStrict)は低コストで行えます。文字列型を Builder に埋め込む関数も、その段階ではコピーは行われないので低コストです。他の変換関数はデータのコピーが伴うので、長さに比例した時間がかかります。
ByteString Builder から直接出力できる文字列型は、 lazy ByteString のみです。strict ByteString が欲しい場合は、一旦 lazy ByteString を出力してから toStrict する必要があります。ビルダーの代替物の中には直接 strict ByteString を出力できるものもあるようです(fast-builder 等)。
ShortByteString と lazy ByteString を直接変換する関数は bytestring パッケージからは提供されていないようです。
Unicode文字列とバイト文字列の変換
Unicode文字列同士の変換、バイト文字列同士の変換は、効率を度外視すればどういう経路で変換してもほぼ同じ結果になります。
これに対し、Unicode文字列とバイト文字列を変換する場合はそうはいきません。「エンコーディング」と「エラー処理」を意識する必要があります。
ASCIIまたは8ビット文字 (Latin-1)
まず、バイト文字列の文字コードをASCIIまたはLatin-1として扱う場合を考えます。この場合、バイト文字列型からUnicode文字列型への変換時にはエラーは起こりません。
一方で、Unicode文字列型からバイト文字列型に変換する際には、エラーまたは文字化けが起こる可能性があります。以下の図では、そういう「危険な」変換は破線で描きました。実際の挙動はドキュメントを参照して確かめてください。
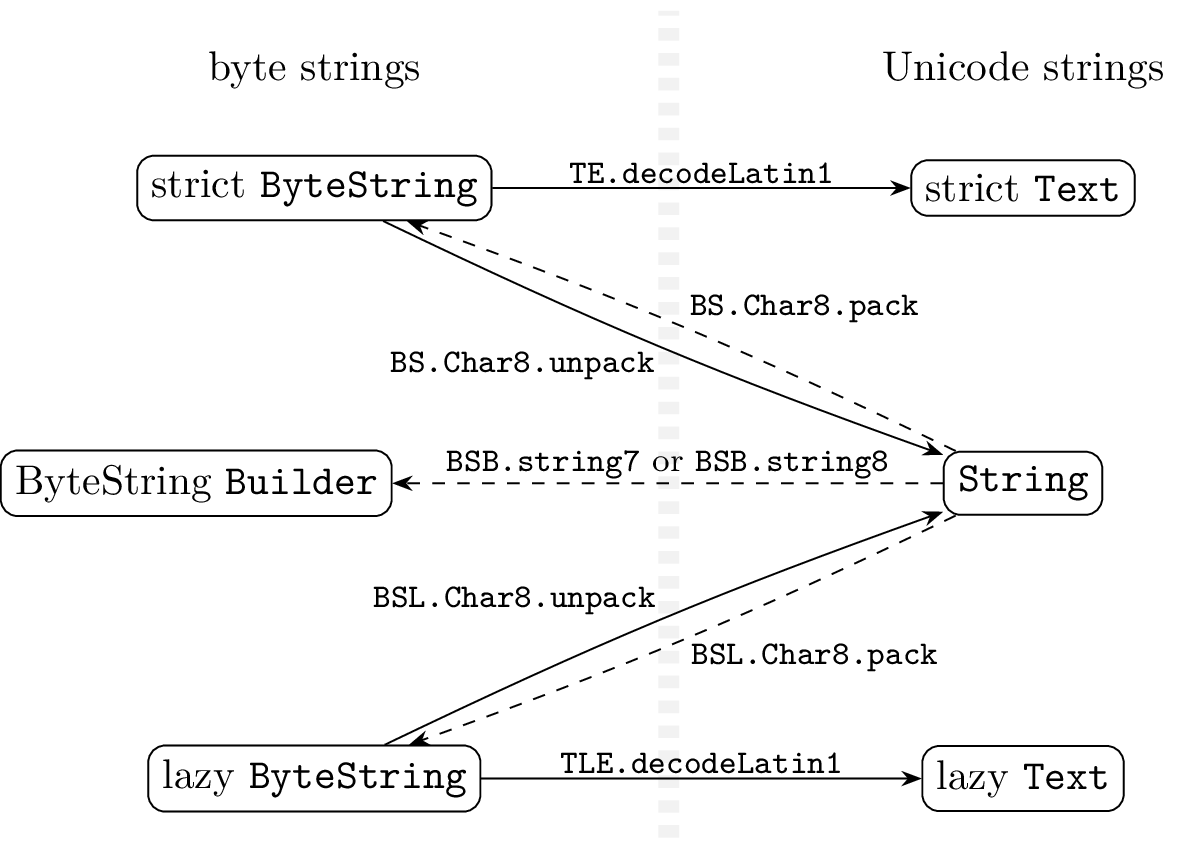
モジュール名の略称は以下の通りです。
-
BS.Char8:Data.ByteString.Char8(bytestring パッケージ) -
BSL.Char8:Data.ByteString.Lazy.Char8(bytestring パッケージ) -
BSB:Data.ByteString.Builder(bytestring パッケージ) -
TE:Data.Text.Encoding(text パッケージ) -
TLE:Data.Text.Lazy.Encoding(text パッケージ)
UTF-8による変換
多くの方が興味のあるのは、UTF-8による変換でしょう。UTF-8によってUnicode文字列からバイト文字列へ変換する際は基本的にはエラーは発生しません2。
一方で、バイト文字列をUTF-8として解釈してUnicode文字列を得る場合、不正なバイト列をどうするかという問題があります。エラーを投げるのかU+FFFDに置換するのかはたまた Maybe で返すのか、実際の挙動はドキュメントを読んで確かめてください。以下の図ではそういう「失敗しうる」変換は破線で描きました。
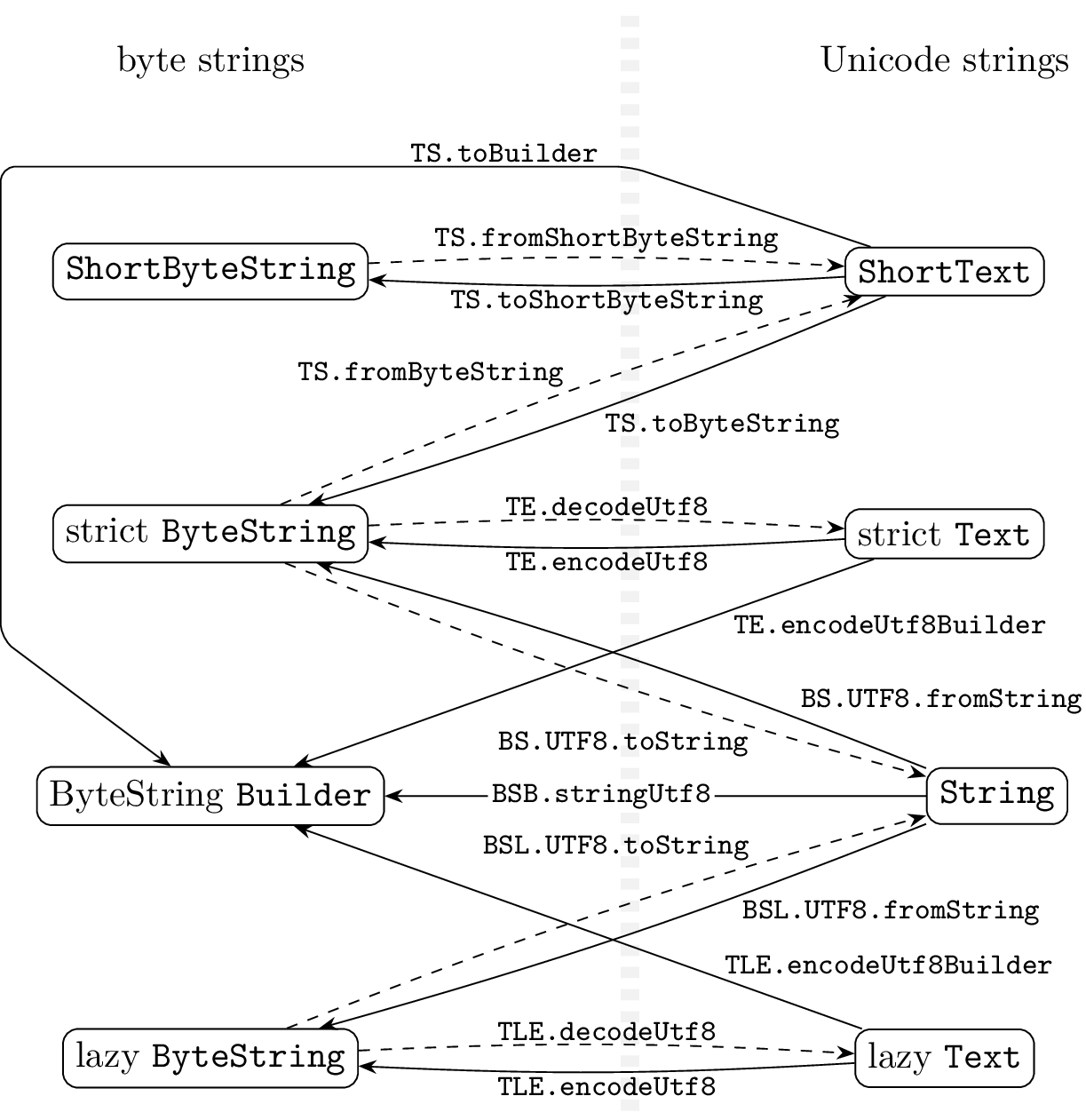
モジュール名の略称は以下の通りです。
-
BSB:Data.ByteString.Builder(bytestring パッケージ) -
BS.UTF8:Data.ByteString.UTF8(utf8-string パッケージ) -
BSL.UTF8:Data.ByteString.Lazy.UTF8(utf8-string パッケージ) -
TE:Data.Text.Encoding(text パッケージ) -
TLE:Data.Text.Lazy.Encoding(text パッケージ) -
TS:Data.Text.Short(text-short パッケージ)-
ShortTextが関係する関数は、例によってここで提供されています。
-
内部的には ShortText は ShortByteString のnewtypeであり、Unicode文字列をUTF-8で保持しているので、 ShortText から ShortByteString への変換はゼロコストで行えます。逆の変換の際にはUTF-8としての正当性を検査する必要があるので、長さに比例した時間がかかります3。
C文字列との変換
CとのFFIで使う、 CStringLen 等の変換についても触れておきます。先に、簡単なまとめを書いておきます。
-
CString(Len) ↔String- システムデフォルトのエンコーディングを使用:
Foreign.C.String.(peek|new|with)CString(Len) - ASCII/8ビット文字専用:
Foreign.C.String.(peek|new|with)CAString(Len) - 任意の
TextEncodingを指定する版:GHC.Foreign.(peek|new|with)CString(Len)
- システムデフォルトのエンコーディングを使用:
-
CStringLen↔Text- UTF-8:
Data.Text.Foreign.(peek|with)CStringLen
- UTF-8:
-
CString(Len) ↔ByteString- バイト文字列同士:
Data.ByteString.(pack|useAs)CString(Len)
- バイト文字列同士:
-
CWString(Len) ↔String- Unicode文字列同士(UTF-16 or UTF-32):
Foreign.C.String.(peek|new|with)CWString(Len)
- Unicode文字列同士(UTF-16 or UTF-32):
ロケール依存な変換方法
Foreign.C.String には String と CString(Len) を変換するための関数が用意されています。
-- String から CStringLen
newCStringLen :: String -> IO CStringLen
withCStringLen :: String -> (CStringLen -> IO a) -> IO a
-- CStringLen から String
peekCStringLen :: CStringLen -> IO String
-- CString に対する(C文字列がNUL終端だと仮定する)変換関数もある。ドキュメント参照
これらの関数では、 GHC.IO.Encoding の getForeignEncoding/setForeignEncoding で指定されるエンコーディングが使われます。この初期値もシステム依存です。
エンコーディングを明示的に指定して変換したい場合は、 GHC.Foreign にある関数を使えば良いでしょう。これらの関数は TextEncoding 型でエンコーディングを指定できます。
-- String から CStringLen
newCStringLen :: TextEncoding -> String -> IO CStringLen
withCStringLen :: TextEncoding -> String -> (CStringLen -> IO a) -> IO a
-- CStringLen から String
peekCStringLen :: TextEncoding -> CStringLen -> IO String
-- CString に対する(C文字列がNUL終端だと仮定する)変換関数もある。ドキュメント参照
これらの関数に渡すべき TextEncoding 型の値は GHC.IO.Encoding にいくつか用意されています(utf8 など)。他のエンコーディングを使いたい場合は、 mkTextEncoding を使うことで、Windowsならコードページを、Unix系ならiconvを使用した変換が可能です。
ASCIIまたは8ビット文字列
ByteString と String を変換する際にコードポイントの下位8ビットを切り出す変換方法(Data.ByteString.Char8)があったのと同じように、 String のコードポイントの下位8ビットを切り出して CString(Len) と変換する関数もあります。
-- String から CStringLen
newCAStringLen :: String -> IO CStringLen
withCAStringLen :: String -> (CStringLen -> IO a) -> IO a
-- CStringLen から String
peekCAStringLen :: CStringLen -> IO String
-- CString に対する(C文字列がNUL終端だと仮定する)変換関数もある。ドキュメント参照
UTF-8
既に述べたように、 String と CStringLen をUTF-8で変換する場合には、 GHC.Foreign の関数に utf8 を渡せば良いでしょう。
Text の場合は、 Data.Text.Foreign に Text と CStringLen を変換する関数が用意されています。
peekCStringLen :: CStringLen -> IO Text
withCStringLen :: Text -> (CStringLen -> IO a) -> IO a
見た感じでは newCStringLen や、 CString 用の関数は用意されてなさそうです。必要なら自作しましょう。
ByteString と CString(Len)
ByteString も CString(Len) もバイト列なので、エンコーディングや失敗時の挙動を考えなくても変換できます。
Data.ByteString に packCString(Len) と useAsCString(Len) という関数があります。
packStringLen :: CStringLen -> IO ByteString
useAsCStringLen :: ByteString -> (CStringLen -> IO a) -> a
ByteString のデータはピン留されていますが、 Data.ByteString の関数は一旦データのコピーを作るようになっています。これは、本来イミュータブルであるはずの ByteString の内容がポインターを経由して書き換えられてしまうのを防ぐためです。コピーを作成せずに ByteString の内容をCに渡したい場合は、 Data.ByteString.Unsafe にある関数を使うと良いでしょう。
ワイド文字列
ワイド文字列(CWString, CWStringLen)は Foreign.C.String に String との変換関数が用意されています。GHCが想定するワイド文字列はUnicode系なので、エンコーディングの指定はありません。ただ、不正なUTF-16や不正なUTF-32はあまりきちんとチェックされていないようです。
まとめ
異なる文字列型同士を変換する際には
- 失敗しうる変換なのか
- どの程度のコストがかかる変換なのか(大抵の変換は長さに比例した時間がかかりますが、
fromStrictのような一部の関数は定数時間でできる場合があります) - バイト文字列とUnicode文字列との間の変換の場合、使用されるエンコーディングはどれなのか
の3点を意識しましょう。
Unicode文字列とバイト文字列を相互変換するための、万人が納得する標準的な方法はありません。 なので、「Unicode文字列とバイト文字列をひっくるめていい感じに変換してくれる関数・型クラス」みたいなやつには要注意です。実際、 IsString クラスはバイト文字列とUnicode文字列をひっくるめて扱おうとしたために失敗しています。
Unicode文字列とバイト文字列の際は、多少面倒でも、(UTF-8で変換されて欲しいのなら)UTF-8で変換してくれる関数を使う、という風にプログラマーが明示するようにしましょう。
-
と言いたかったのですが、この記事を書いている最中に
TB.fromStringの挙動を確認したところ、サロゲートコードポイントの扱いが不適切でTextの不変条件(正当なUTF-16である)を崩せてしまうことがわかりました。要バグ報告です。 ↩ -
変換元が
Stringの場合はサロゲートコードポイントをどうするかという問題があります。BSB.stringUtf8や utf8-string のソースを読んだ感じでは、サロゲートコードポイントの検査は行わずに、UTF-8としては不正なバイト列を出力するようになっているようです。 ↩ -
変換元が正当なUTF-8であるとわかっているのであれば検査を飛ばして
ShortByteStringからShortTextへゼロコストで変換することができます。詳しくはData.Text.Short.Unsafeを参照してください。 ↩