C言語やC++にはインラインアセンブリやintrinsics(組み込み関数)があり、最近のCPUで追加された命令を活用したコードを簡単に書くことができます。
一方、Haskell (GHC) にはそのような仕組みはありません1。しかしそれで諦めるのは早い。なんとかしてHaskellからインラインアセンブリっぽいことをしてみましょう。
筆者の環境はx86_64なMacで動かしているGHC 8.6.5です。他の環境では状況が異なる可能性があります。C言語の処理系はClangを使いますが、GCCでも多分同じです。
題材:64ビット整数の積の上位と下位
2つの64ビット整数の積を計算し、上位64ビットと下位64ビット(合わせて128ビット)をそれぞれ計算することを考えます。
C言語やHaskellにあるような通常の乗算 (*) :: Word64 -> Word64 -> Word64 では下位64ビットしか計算できません。一方、x86のアセンブリ言語のレベルでは、乗算の際に上位64ビットも一緒に計算されます。
こういう「機械語レベルでは容易だが、C言語やHaskellのレベルでは非自明な処理」には、インラインアセンブリ(や組み込み関数)を使いたいところです。
(実はGHCには timesWord2# :: Word# -> Word# -> (# Word#, Word# #) という組み込み関数があるので、これを使えば一発です。それでもこの題材を選んだのは、「GHCの組み込み関数と比較した場合にどの程度遅くなるか」を検証できるようにするためです。)
C言語では
GCC/Clangには __int128 型があるので、それを使えば一発です。インラインアセンブリもintrinsicsも必要なかった(ぇ)
unsigned __int128 wideningMul(uint64_t a, uint64_t b)
{
return (unsigned __int128)a * (unsigned __int128)b;
}
あえてインラインアセンブリで書くとすれば、こんな感じでしょうか:
uint64_t wideningMul_inlasm(uint64_t a, uint64_t b, uint64_t *outHigh)
{
uint64_t lo, hi;
asm("movq %2, %%rax;"
// mulq は %rax とオペランド(この場合は %3)の積を計算し、
// 上位64ビットを %rdx, 下位64ビットを %rax に入れる
"mulq %3;"
"movq %%rax, %0;"
"movq %%rdx, %1;"
: "=r"(lo), "=r"(hi)
: "r"(a), "r"(b)
: "%rax", "%rdx");
*outHigh = hi;
return lo;
}
さて、この処理では2つの uint64_t を受け取って、2つの uint64_t を返します。C言語の構文には多値返却がないので、値の返却方法として次のいずれかを選択することになります:
- 構造体の値返し:
struct uint128 { uint64_t lo, hi; }のような構造体を定義して値で返す-
unsigned __int128を値で返すのも内部的にはこれっぽい(詳しくは x86_64 のABIを確認。Unix系の場合は「System V ABI x86_64」とでもググればよろしい)
-
- ポインタを受け取って渡す:2番目以降の返却値の受け渡しする場所をポインターとして引数に取る(例:さっき書いた
wideningMul_inlasm関数)
前者の例として、C標準の div, ldiv, lldiv 関数は ホニャララdiv_t という構造体を値で返しています。
構造体を値で返すメリットは、構造体が小さければ値をレジスタに載せたまま返すことができることです。
一方、構造体の値返しのデメリットは、他の言語のFFIが対応していない場合があることです。実際、現在のGHCのC FFIは構造体を値で受け渡すことに対応していません。
一応、Cの構造体をFFIで値渡しできるようにしよう、という提案 (proposal) がありますが、動きがありません:
- GHC Wiki: Support C structures in Haskell FFI
- GHC Issues: Support C structures in Haskell FFI (#9700)
C FFIを使う(ポインタ使用)
Safe FFI
Haskellにできないことは他の言語の力を借りよう!ということで、HaskellにはFFIがあります。これを使えばC言語で書いた関数を呼び出すことができます。
早速やってみましょう:
# include <stdint.h>
extern uint64_t wideningMul_with_ptr(uint64_t a, uint64_t b, uint64_t *outHigh)
{
unsigned __int128 result = (unsigned __int128)a * (unsigned __int128)b;
*outHigh = (uint64_t)(result >> 64);
return (uint64_t)result;
}
先ほど書いたように、現状のGHCのFFIでは構造体を値渡しできないので、返り値の1つはポインタを経由することにします。
Haskell側のコードはこんな感じです:
foreign import ccall "wideningMul_with_ptr"
c_wideningMul_with_ptr :: Word64 -> Word64 -> Ptr Word64 -> IO Word64
wideningMulWithPtr :: Word64 -> Word64 -> Word128
wideningMulWithPtr !a !b = unsafePerformIO $ do
Marshal.alloca $ \outHigh -> do
lo <- c_wideningMul_with_ptr a b outHigh
hi <- peek outHigh
return $ Word128 hi lo
ポインタを扱うということは、領域を確保したり値を読みだしたりするために IO を行うということです。しかし「64ビット整数の乗算」という処理全体としては純粋だと考えられるので、 unsafePerformIO を使って純粋な関数として書いています2。
(ちなみに、 Word128 型は wide-word パッケージの Data.WideWord.Word128 型を使いました。)
試してみると、
> wideningMulWithPtr 123 456
56088
> 123 * 456
56088
> wideningMulWithPtr (2^63) (2^62) -- CPUの命令を使う
42535295865117307932921825928971026432
> 2^125 -- 多倍長整数で計算する
42535295865117307932921825928971026432
という風に正しく計算できているようです。
C言語のコードを別のファイルに書くのが面倒であれば、
- @tanakh 氏の記事「Haskellにインラインアセンブリを書く」
のように inline-c のようなパッケージを使うのも一つの手段かもしれません。
Unsafe FFI
さて、HaskellのFFIにはsafety levelという概念があります。デフォルトではsafeで、これは「呼び出した外部のコードからHaskellの関数をコールバックしても安全」であることを意味します。
safeの逆はunsafeで、「呼び出した外部のコードからHaskellにコールバックしたら何が起きるかわからんよ」という意味です。
unsafeなFFIはリスクがある分、オーバーヘッドが小さいことが期待できます。
safety levelの指定は、 foreign import 宣言の呼び出し規約の直後に safe または unsafe を書きます:
foreign import ccall unsafe "wideningMul_with_ptr"
c_wideningMul_with_ptr :: Word64 -> Word64 -> Ptr Word64 -> IO Word64
inline-cパッケージを使う場合は、quasiquoter (exp, pure, block) として Language.C.Inline.Unsafe にあるものを使います。
C FFIを使う(2回呼び出す)
先のセクションでは、Cで書いた関数から複数の値を返すためにポインタを経由しました。
しかし、ポインタで値を受け渡しするのは、レジスタ渡しに比べて遅い気がします[要出典]。ポインタを使わずに値を受け渡しできれば、それに越したことはありません。
幸い、今回の題材は「64ビット整数の乗算」という、コストが低い演算です。これだったら、上位64ビット、下位64ビットのそれぞれに対して同じ計算をするのもアリではないでしょうか?
// 下位64ビットを計算する
extern uint64_t wideningMul_lo(uint64_t a, uint64_t b)
{
unsigned __int128 result = (unsigned __int128)a * (unsigned __int128)b;
return (uint64_t)result;
}
// 上位64ビットを計算する
extern uint64_t wideningMul_hi(uint64_t a, uint64_t b)
{
unsigned __int128 result = (unsigned __int128)a * (unsigned __int128)b;
return (uint64_t)(result >> 64);
}
foreign import ccall unsafe "wideningMul_lo"
c_wideningMul_lo :: Word64 -> Word64 -> Word64
foreign import ccall unsafe "wideningMul_hi"
c_wideningMul_hi :: Word64 -> Word64 -> Word64
wideningMul2 :: Word64 -> Word64 -> Word128
wideningMul2 !a !b = Word128 (c_wideningMul_hi a b) (c_wideningMul_lo a b)
実際のところ「2回呼び出してレジスタ渡しで完結させる」方針が「ポインタで渡す」方針に比べてどうなのかは、後で比較します。
黒魔術:foreign import prim
注意:unsafePerformIOやUnsafe FFIを見て「unsafeこわ」と思った健全な方は、今のうちに帰っパ3しておくことをお勧めします。
GHCのPrimOpsについて
さて、たかだかCPUの命令1つのためにFFIでC言語で書いた関数を呼び出す、というのはどうしてもコストがかかる[要出典]印象が拭えません。
FFIのオーバーヘッドをもっと削減し、GHCの組み込み関数に近いパフォーマンスを出すようにはできないでしょうか?
GHC Wikiのページ (Primitive Operations (PrimOps)) によると、GHCの組み込み関数には、inline PrimOps, out-of-line PrimOps, foreign out-of-line PrimOps (foreign import prim) の3種類があるようです。
- inline PrimOps: その場で命令列に展開される。GHCにハードコードされている。
- out-of-line PrimOps: 専用の呼び出し規約に従う。GHCにハードコードされている。
- foreign out-of-line PrimOps: 専用の呼び出し規約に従う。ライブラリー開発者が
foreign import primによって定義できる。GHC本体に付属するライブラリー向け。
この中では(というか、CPUの特定の命令を叩くためにHaskellで使えるあらゆる方法の中で)inline PrimOpsが一番低コストだと思われますが、命令一つを使いたいがためにGHC本体に手を入れるのはやりすぎ4です。というわけで、必然的に foreign out-of-line PrimOps を使うことになります。
foreign import prim を使う
foreign import prim を使うHaskellコードの例は次のようになります:
{-# LANGUAGE GHCForeignImportPrim, UnliftedFFITypes, MagicHash, UnboxedTuples #-}
foreign import prim "wideningMul_prim"
wideningMul_prim# :: Word# -> Word# -> (# Word#, Word# #)
wideningMul :: Word64 -> Word64 -> Word128
wideningMul (W64# a) (W64# b)
= case wideningMul_prim# a b of
(# lo, hi #) -> Word128 (W64# hi) (W64# lo)
一見すると foreign import の呼び出し規約が ccall から prim に変わっただけですね。安心した!(型名やタプルに # がついているのは低レベルHaskellではよくあることなので今更驚きません。ccallでも # を使いまくるFFIはできますし)
使うGHC拡張ですが、 foreign import prim を使うには GHCForeignImportPrim 拡張5が必要です。また、引数と返り値は基本的にunboxed typesしか使えないので、 UnliftedFFITypes 拡張も必要になります。MagicHash, UnboxedTuples は言わずもがなですね。
foreign out-of-line PrimOpsを実装する
Haskell側でオレオレPrimOpsを使う準備はできたので、次は実装を用意します。
GHCのout-of-line PrimOpsはCmmで書くことが想定されているようですが、
- Cmmはよくわからん!
- Cmmでインラインアセンブリや環境依存の組み込み関数を使えるかわからん!
ので、アセンブリで直接書くことにします(後述しますが、Cmm, アセンブリベタ書きの他にLLVM IRをいじる、という第3の道もあります)。
GHCのPrimOps用の呼び出し規約は、x86_64の場合は
- 引数と返り値は全てレジスタで渡す。最初が
%rbx, 2番目が%r14, 3番目が%rsi, 4番目が%rdi, ... - 呼び出し側に戻る時は
jmp *(%rbp)する
という感じのようです。レジスタの使い方に関しては MachRegs.h を参照してください。
実際のアセンブリコードは次のようになります:
.globl _wideningMul_prim
_wideningMul_prim:
## 第一引数:%rbx
## 第二引数:%r14
movq %rbx, %rax
mulq %r14 ## %rax と %r14の積を計算して、上位を %rdx, 下位を %rax に入れる
movq %rax, %rbx ## %rbx に最初の返却値 (lo) を入れる
movq %rdx, %r14 ## %r14 に第二の返却値 (hi) を入れる
jmp *(%rbp)
先ほどリンクを貼った MachRegs.h のコメントによると %rax や %rdx はcaller-saveのようなので好きに使って大丈夫です。たぶん。
なお、どうしてもC言語で書きたかったら、「特定のプロトタイプを持つ関数として書いてClangでコンパイル、-S -emit-llvm で出力されたLLVM IRをいじって呼び出し規約を cc106 にする」という方法があるみたいです。詳しくは下記リンクを参照してください。
参考になるかもしれないリンク集:
- Parsing Market Data with Ragel, clang and GHC primops - Ten Cache Misses: clangが吐くLLVM IRに手を加えてGHCの呼び出し規約を使っている
- haskell - foreign import prim call to LLVM - Stack Overflow: 同上
-
haskell - Using
foreign import primwith a C function using STG calling convention - Stack Overflow: 同上 - Almost Inline ASM in Haskell With Foreign Import Prim - Brandon.Si(mmons): LLVMを介さずに直接x86_64のアセンブリを書いている
Cの構造体返しと foreign import prim を組み合わせる(サンク方式)
今回のように命令一発で済む場合はPrimOpsの実体をアセンブリ言語でゴリゴリ書いても苦にはなりませんが、もう少し複雑なコードになるとC言語のような高級言語で書きたくなりますよね。
そこで、
- 処理の本体はC言語の関数として書く(構造体の値返しを使う)
- C言語で書いた関数を呼び出すPrimOpsをアセンブリで書く
- アセンブリで書いたやつを
foreign import primでHaskellから呼び出す
という方式を考えます。C言語の呼び出し規約とGHCの呼び出し規約の違いを、アセンブリで書いた少量のコードで吸収するわけです。この、間に挟まるコードをサンクと呼ぶことにします(Haskellでサンクというと遅延評価がらみのアレを連想しがちですが、そのサンクとは違います)。
Cで書いた部分はこんな感じで、
// __int128 is equivalent to struct { uint64_t lo, hi }; on System V/x86_64 ABI
extern unsigned __int128 wideningMul_uint128(uint64_t a, uint64_t b)
{
return (unsigned __int128)a * (unsigned __int128)b;
}
アセンブリで書くサンクはこんな感じです:
.globl _wideningMul_thunk
_wideningMul_thunk:
## GHC:
## 第一引数:%rbx
## 第二引数:%r14
## C:
## 第一引数:%rdi
## 第二引数:%rsi
movq %rbx, %rdi
movq %r14, %rsi
subq $8, %rsp ## ???
callq _wideningMul_uint128
addq $8, %rsp ## ???
## C:
## 第一返却値:%rax
## 第二返却値:%rdx
## GHC:
## 第一返却値:%rbx
## 第二返却値:%r14
movq %rax, %rbx
movq %rdx, %r14
jmp *(%rbp)
# C:
# callee-save: %rbp, %rbx, %r12..%r15
# GHC:
# callee-save: %rbp, %rbx, %r12..%r15
# Stack frame:
# (%rsp+8) is always a multiple of 16
x86_64でのSystem V ABIとGHCのABIは、レジスタのcaller-save/callee-saveはだいたい同じなのでレジスタに関しては適当に movq してやれば良いですが、System V ABIの方はスタックポインタ %rsp のアラインメントに要件があるので適当に調整してやる必要があります。GHCの吐いたコードを読んだ感じでは %rsp に定数8を足し引きしていたので、ここでもそれに従いました。真面目にやるならGHCのABIもちゃんと調べる必要がありそうです。
妄想ですが、Template Haskellでこういう風なサンクを自動生成して、構造体を値渡しするCの関数を直接呼び出せるHaskellライブラリーがあったら楽しそうです。誰か作ってくれ〜〜
ベンチマーク
「64ビット整数2つの乗算を128ビット整数として得る」ための実装方法を色々考えました。というわけで比較です。比較対象は以下です:
- Haskellの多倍長演算(
Integer型)を使う - オペランドを
wide-wordパッケージのWord128型に変換してから乗算する-
wide-wordパッケージは内部的にはtimesWord2#を使っている
-
-
GHC.PrimのtimesWord2#を使う- GHCの内部的には
WordMul2と呼ばれる inline PrimOps の一種
- GHCの内部的には
- C FFIを使う
- Safe FFI / Unsafe FFI
- ポインタ(unsafePerformIO / unsafeDupablePerformIO / ****PerformIO) / 2回呼び出し
-
foreign import primを使う- アセンブリで実装
- サンク方式
64ビット演算2つの乗算で128ビットを得る演算としてはすでにGHC組み込みの timesWord2# があるので、「inline PrimOpsと(foreign) out-of-line PrimOpsでどのくらい差があるのか」の比較も行えます。
どれが一番早いか予想しておくと、inline PrimOpsである timesWord2# が一番早く、foreign out-of-line PrimOps (foreign import prim) が続くと考えられます。Integer の多倍長演算は一番遅い気がします。
実際のベンチマーク結果は以下です:
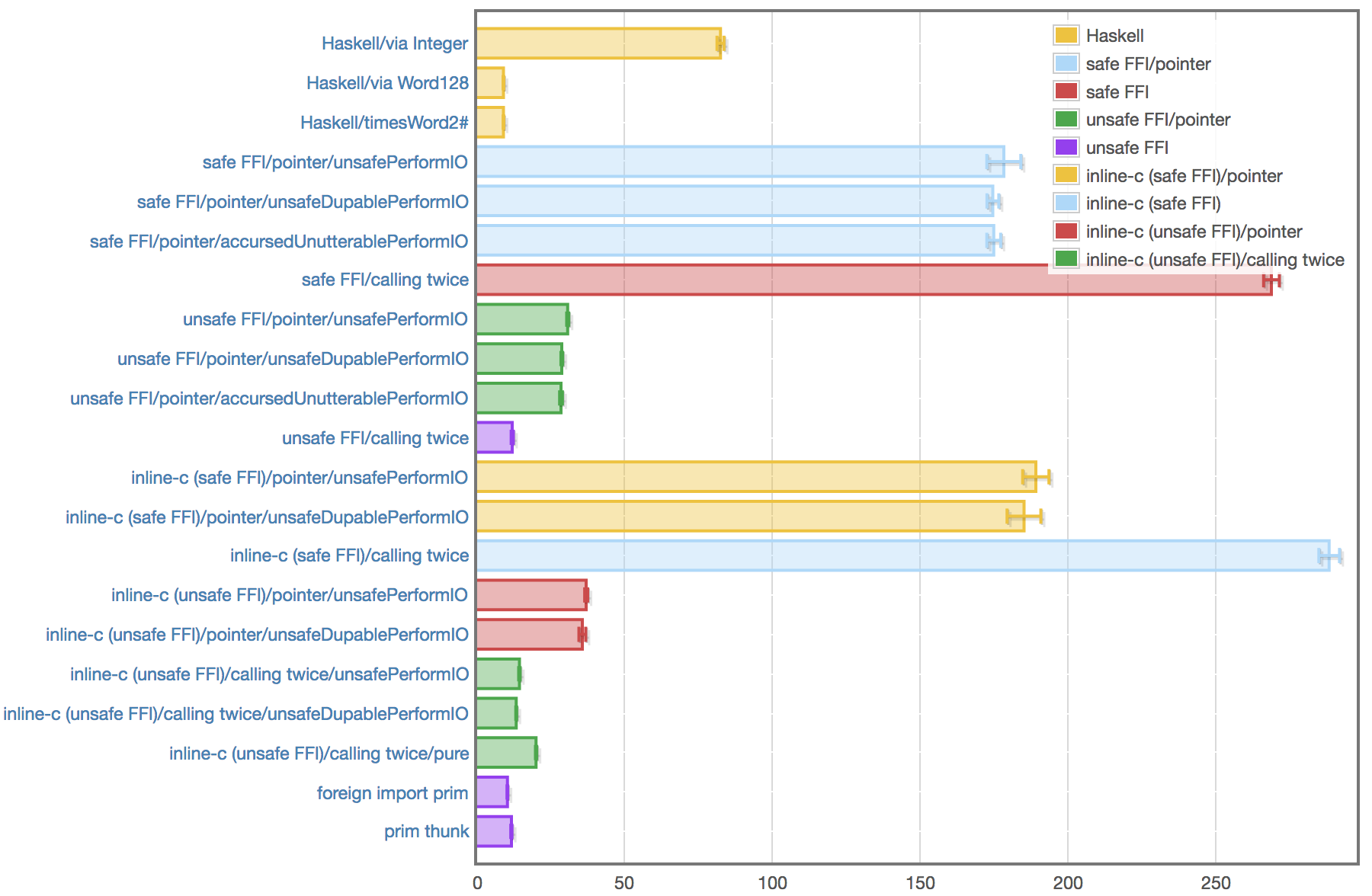
テキストで読みたい方はここを見てください。
まとめると
- 最速はGHC組み込みの
timesWord2#関数で、8.9ns程度。内部的にtimesWord2#を使うWord128も同等のパフォーマンスが出ている。 - 次点は
foreign import prim(アセンブリのみ)で、10.2ns程度。サンク方式や「unsafe FFI + ポインタを使わず2回呼び出す」もほぼ同等のパフォーマンス。 - その次は「unsafe FFI + ポインタ渡し」で、30ns程度。unsafePerformIOの代わりにunsafeDupablePerformIOや名状し難い冒涜的なやつを使ってもほぼ同じ。
- その次が
Integerの多倍長計算を使うやつで、82ns程度。 - 最下位は「safe FFI」で、180ns程度。unsafePerformIOの代わりにunsafeDupablePerformIOや名状し難い冒涜的なやつを使ってもほぼ同じ。「ポインタ渡し」よりも「2回呼び出し」の方が若干遅いのは、safe FFIのコストがポインタ渡しのコストを上回ったからでしょう。
となります。
使ったソースコードは GitHub に置いてあります。ベンチマークは筆者のMacBook Pro (Late 2013)で実行しました。
雑感・まとめ
GHC組み込みでインラインの命令列に置き換えられるものが最速なのは当然として、 foreign import prim でそれに肉薄するパフォーマンスが出ることがわかりました。
意外なのは「unsafe FFI + ポインタを使わず2回呼び出し」が foreign import prim とほぼ互角だったことです。CのFFIでもやり方次第では foreign import prim に匹敵するということです。パフォーマンスの差がわずかであれば、 foreign import prim の黒魔術よりもCのFFIを選択するという判断はアリでしょう。
逆に、CのFFIを使っていても、不必要にsafeレベルを使っていると、「CPUの便利な命令を使わずに愚直にHaskellで書いた」バージョンよりも遅くなってしまいました。
- 高速化のためにCのFFIを使う場合はsafety levelが不必要にsafeになっていないか確認しろ
というのは結構大事な教訓ではないでしょうか。
-
一応、SIMD命令はある程度使えるようですが。 ↩
-
Unsafe Haskellに精通した方なら「この場合なら
unsafeDupablePerformIOが使えるし、なんなら〈検閲削除〉PerformIOの方が…」と思われるかもしれません。安心してください、これらの実験結果も最後に載せておきます。 ↩ -
「帰ってパイソンしとこ……」の略[嘘] ↩
-
GHC本体に取り込んでもらえるなら苦労の甲斐もあるかもしれませんが、ニッチな命令に対応する組み込み関数をGHC本体に取り込んでもらえる見込みは低いでしょう。GHCにAES命令を入れようというIssueが過去にあったようですが、won't fixでcloseされています。 ↩
-
いかにも「GHC専用!外部のライブラリーは使うな!」感がある名前ですね。実際、GHC User's Guideにこの拡張の名前は載っていません(
foreign import prim自体は載っています)。 ↩ -
cc10というのはGHCの呼び出し規約のLLVM内での名称です(→LLVMの呼び出し規約のドキュメント)。GHCのLLVMバックエンドが使っていると思われます。 ↩