はじめに
5月病真っ盛りのGW、研究や勉強に1ミリも注力できない日々の中で、友人からあるメッセージが届きました。
「これ面白そうじゃね?」
今回は、深層学習による音声合成の簡単な紹介をしてみました。
友人と共に、実装・開発を行う予定であるので進捗があり次第、投稿していきます。
音声合成
さて、ウィキペディアによると、
音声合成(おんせいごうせい、英: speech synthesis)とは、人間の音声を人工的に作り出すことである。音声情報処理の一分野。音声合成器により合成された音声を合成音声(ごうせいおんせい)と呼ぶ。
と記載されています。要するに、**「機械を用いて音声を作り出す技術」**というイメージです。
歴史
その歴史は意外にも深く、機械の発表のみに焦点を当てても1779年まで遡ります。
当時は、コンピュータもない時代であったために、人間の口を模倣した機械によって音声を出力するという技術の研究が盛んでした。簡単に言えば、「言葉を発する楽曲」という感じですね。
その後、1950年代にようやくコンピュータを用いた技術が開発され始めます。
そして、1999年に我らが日本の東京工業大学が提案した隠れマルコフモデル音声合成を筆頭に、統計的統計的パラメトリック音声合成という手法が音声合成界を席巻していくことになります。
今回紹介するのは、この統計的パラメトリック音声合成におけるニューラルネットワーク音声合成という技術です。
以降の実装・開発においてもこの技術を使用する予定です。
ニューラルネットワーク音声合成
ニューラルネットワークとは
ニューラルネットワークとは、脳の神経回路(ニューロン)を模倣したパーセプトロンというアルゴリズムを複数組み合わせた数理モデルです。詳しい説明は、他の優秀なサイトや論文、書籍をご参考ください。
| ニューラルネットワークの簡略図 |
|---|
 |
ニューラルネットワーク音声合成の例
前置きとして、統計学や最適化といった細かい数学の話は私に学がないため今回は致しません。この辺りのニッチな話は次回以降に投稿することにして、簡単な概要だけ紹介しましょう。
**【注意】**最新の手法では、テキスト解析を必要としないEnd-to-End音声合成が提案されていますが、説明の簡単化のために今回は少し古いモデルの説明を行っています。Google社における研究内容の紹介がされている動画が非常にわかりやすいのでそちらをぜひご覧ください。
| 深層学習を用いた音声合成の例 |
|---|
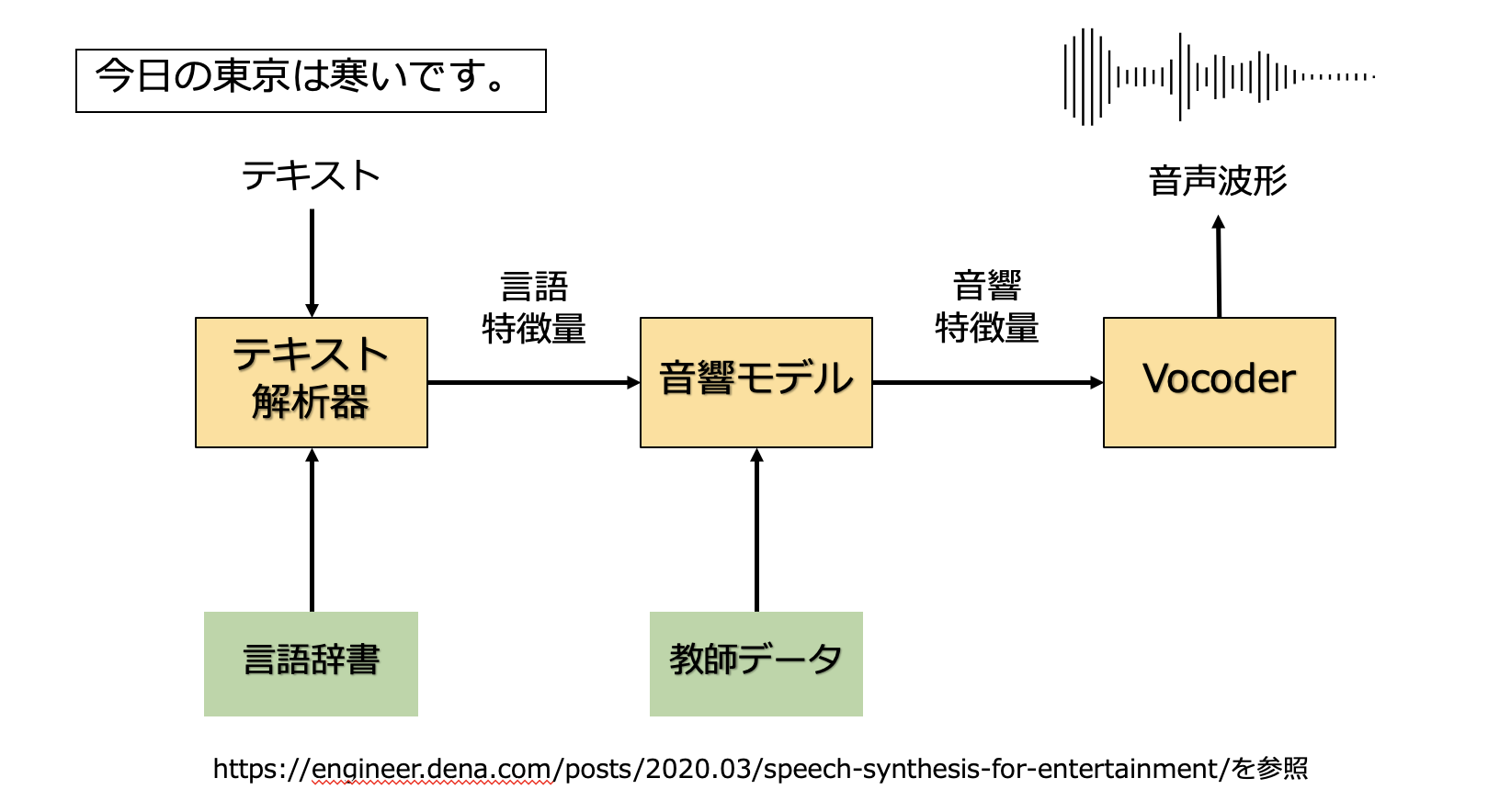 |
深層学習を用いる場合、大きく分けて、**「テキスト解析」「音響モデル」「Vocoder」**の3つのモジュールに分けられます。
テキスト解析
| テキスト解析 |
|---|
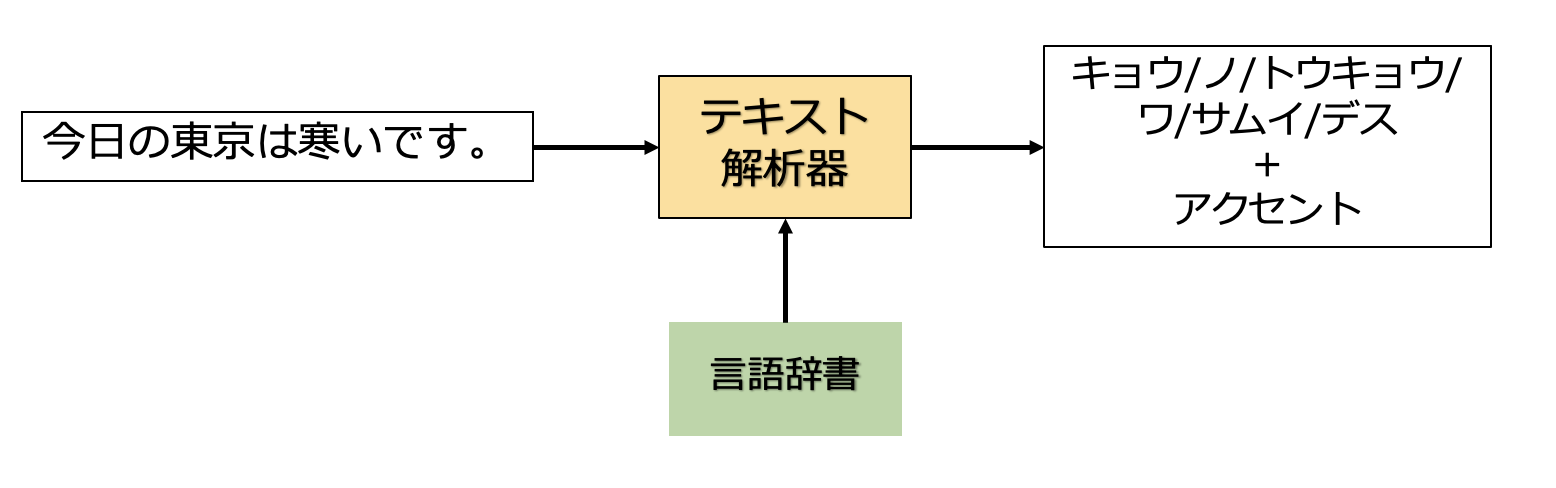 |
**「テキスト解析」**では、入力されたテキストに対して形態素解析を行い、そこに言語辞書を用いることで、文章や単語の読み方、アクセントなどの言語特徴量を抽出します。
Chasen、Mecab、JUMANなんかが日本語の形態素解析ツールとして有名ですね。
音響モデル
| 音響モデル |
|---|
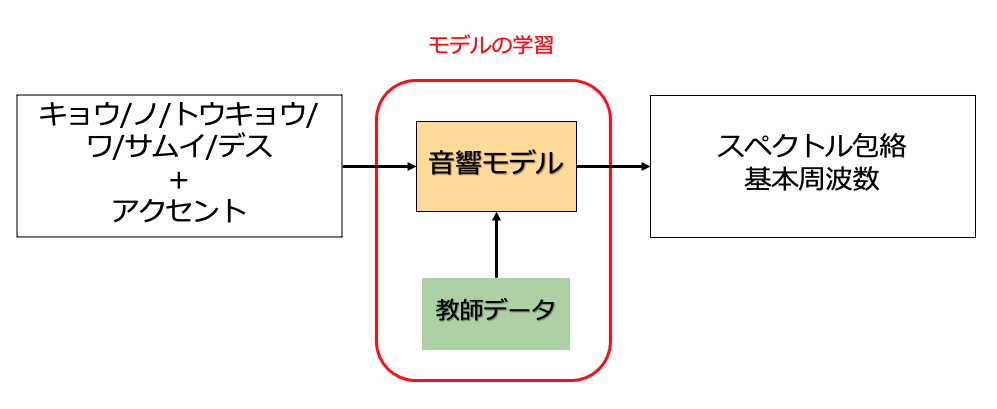 |
**「音響モデル」**では、テキスト解析にて抽出された言語特徴量をEncodeし、それを音響特徴量にDecodeします。Encoder-Decoerのアーキテクチャを持つ深層学習モデルです。各辺の重みは、事前に収録されたテキストデータ及びその読み上げデータを教師データとして学習することで決定します。
音響特徴量とは、音声の基本周波数やペクトル包絡といったものが挙げられます。詳しい説明は省きますが、音声情報を数値化したものだと思っていただいて構いません。
上記の記事では、十分な精度を持つモデルの学習には最低でも60分以上の教師データを必要とするみたいです。
Vocoder
| Vocoder |
|---|
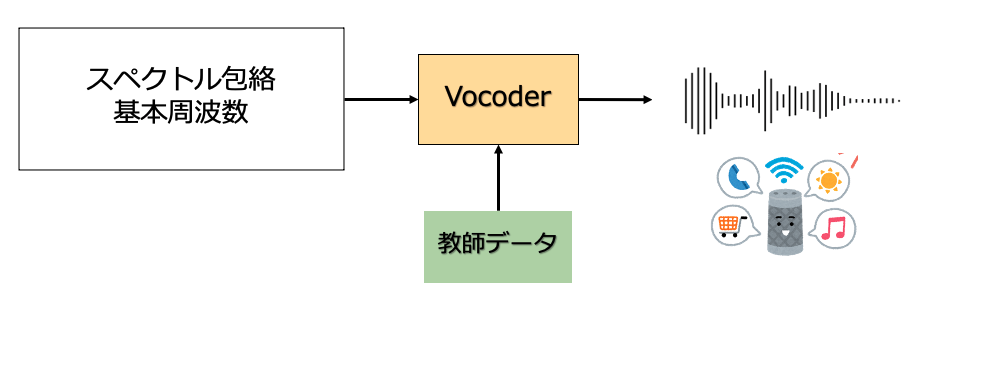 |
学習済みの音響モデルに対して、読み上げを行いたいテキストを入力します。これを音響特徴量に変換し、この特徴量をもって**「Vocoder」**により合成音声を出力することが可能になります。音声合成に限らず、電子楽器や携帯電話などで幅広広く利用されており、音声波形ではなくパラメータを用いて音声の合成を行う技術です。
まとめ
そんなこんなで好きな文章を好きな声で読み上げるツールが完成するわけです。上記の記事では、月ノ美兎さんの音声を教師データとする上で、**「ノイズ除去の精度」「教師データ量の不足」「文字起こしの労力問題と自動化における精度」**が課題点として挙げられています。
@K2_MLさんはYouTube上の動画のみを用いて教師データの作成を行なっていたので、にじさんじ公式ボイスを購入して教師データに導入するのも1つの改善方法かも知れませんね。
さいごに
今回はニューラルネットワーク音声合成について簡単に紹介させていただきました。
私も勉強しながらこの記事を綴っているため、拙いところがあると思われます。ご指摘等あれば、ぜひコメント等いただければ嬉しいです。
参考文献
- "音声合成".フリー百科事典『ウィキペディア(Wikipedia)』
.https://ja.wikipedia.org/wiki/%E9%9F%B3%E5%A3%B0%E5%90%88%E6%88%90. - "エンタメ活用へ向けたAIによる音声生成(Part1)".:DeNA.https://engineer.dena.com/posts/2020.03/speech-synthesis-for-entertainment/.