はじめに
Excelは非常に世の中に浸透しているが故にその使い方は千差万別だ。そんな中最近「データの再利用性」という観点でExcelワークブックの作り方を考える機会があった。直接的なプログラミング要素は無いが、Excelブックの設計という観点でメモを残してみる。なお本記事にはVBA要素は出てこない。
最初に結論
データ再利用性の高いExcelブックとは、
- データシートと表現シートが分離されており
- データシートは表現シートに依存せず
- データの形式は整然データの形をとっていて
- そのデータはExcelテーブルで保持されており
- 表現シートはデータテーブルへの構造化参照を使用して結果の出力を行う
といった特徴を備えるものである。
そもそもデータとはなにか?
そもそもデータとはなにか?改めて考えてみると、意外と難しい。規格を確認してみると、ISOおよびJISに以下のように定義されている。
「情報の表現であって、伝達、解釈または処理に適するように形式化され、再度情報として解釈できるもの」
(出典:データ - Wikipedia)
「再度情報として解釈できる」 とあるように、データはその定義に再利用可能性を含んでいる一方で、人間の視認性に対する要件はない。あくまで「伝達できる」「再処理できる」「解釈できる」情報の形式がデータだということのようだ。
Excelに付き纏うデータと表現の混同
データの概念に視認性が出てこない一方、Excelを開いて一番最初に考えるのは大抵「見た目=表現」だったりする。これは紙文化の名残でもあるし、Excel資料は最終的には人が何か判断するために作るのだから、ある意味当然とも言える。
表現はあくまで「人間が見て理解し、何かを判断する」という目的のもとに構築されるものだ。よってそもそもの成り立ちからして本質的にデータとは異なる。この違いを意識しないと、「データ」として再利用価値があるにも関わらず、「表現」に特化した形式で情報を取り扱うといった状況が発生してしまう。そしてその状況を知ってか知らずか(いや当然知らずに)、放置した結果の極地が、いわゆるネ申エクセル問題だったりするのだろう。
データと表現を分離する
ではどうするのがいいのか?データと表現で目的や成り立ちが違うのだから、適切な形式も当然異なることが予想される。だったらいっそ分離して別々に扱いましょう、というのが自然な流れだろう。責務の分離というやつだ。
最も単純なパターンは、再利用を目的とした「データシート」と、人間が見ることを目的とした「表現シート」に分けるものだ。具体的には以下のようなものになる。
- データシートはデータに適した形式で情報を保持し、データの投入と蓄積のみを行う。
- 表現シートはそのデータを参照して人間に見やすい形で出力を行う。
- データシートから表現シートへの参照は原則行わない。
こうしておけば表現シートではPivotテーブルを作ろうが、セル結合を使おうが、Excel方眼紙を使おうが、全く問題ない。大いに使って人間にとっての見やすさを追求すれば良い1。再利用に必要なデータはデータシートに保護されており、表現シートの影響を全く受けないからだ。この、「データが表現の影響を全く受けない」という点が、再利用性を考えたときに決定的に重要なポイントになる。こうすることでデータはデータにとって最適な形式をとることができ、伝達され、処理され、再解釈され、別の表現形式に出力することが容易になるからだ。
なおExcelシートに責務の分離の考え方を持ち込むアイデアは全く新しいものではなく、例えば以下の記事ではさらに「演算」も1つの独立した責務と考え、Data,Operation,Viewの3シートで管理するDOVパターンが提案されている。非常にスッキリとまとまっていてとても勉強になった。
参考:プログラマが考える劇的に効率が上がるExcelシートの作り方 | 三度の飯とエレクトロン
データはどんな形式が好ましいのか?
データと表現はシートで分離した。では肝心のデータはどのような形式にするのが良いのだろう?データにとって最適な形式があるのだろうか?これについてはデータ分析でよく使われている言語の1つであるR言語の世界で「神」とも言われるHadley Wickham氏が1つの解となる概念を提唱している。整然データ(tidy data)だ。
整然データ
整然データとは、再利用しやすくデータ分析に使いやすい表データ形式であり、
- 個々の変数が1つの列をなす、2) 個々の観測が1つの行をなす、3) 個々の観測の構成単位の類型が1つの表をなす、4) 個々の値が1つのセルをなす、という4つの条件を満たした表型のデータのことであり、構造と意味が合致するという特徴を持つ
(出典:整然データとは何か|Colorless Green Ideas)
ものだ。整然データの概念については上記の記事が非常に分かりやすい。また、原論文和訳とHadley氏の著作である R for Data Science の Tidy data の章も必読だ。
Tidy dataの詳しい説明は上記の良質な記事に譲り、ここでは整然データとそうでないデータを一例ずつあげるに留める。なお、整然データでないデータ(=雑然データ)の代表例は、悲しいかなExcelの講座でよく登場するクロス集計表だ。クロス集計表は人間の視認性が良いため表現シートでは優等生かもしれないが、意味と構造の単位が一致しておらず、データ保持には不向きな形式なのだ。
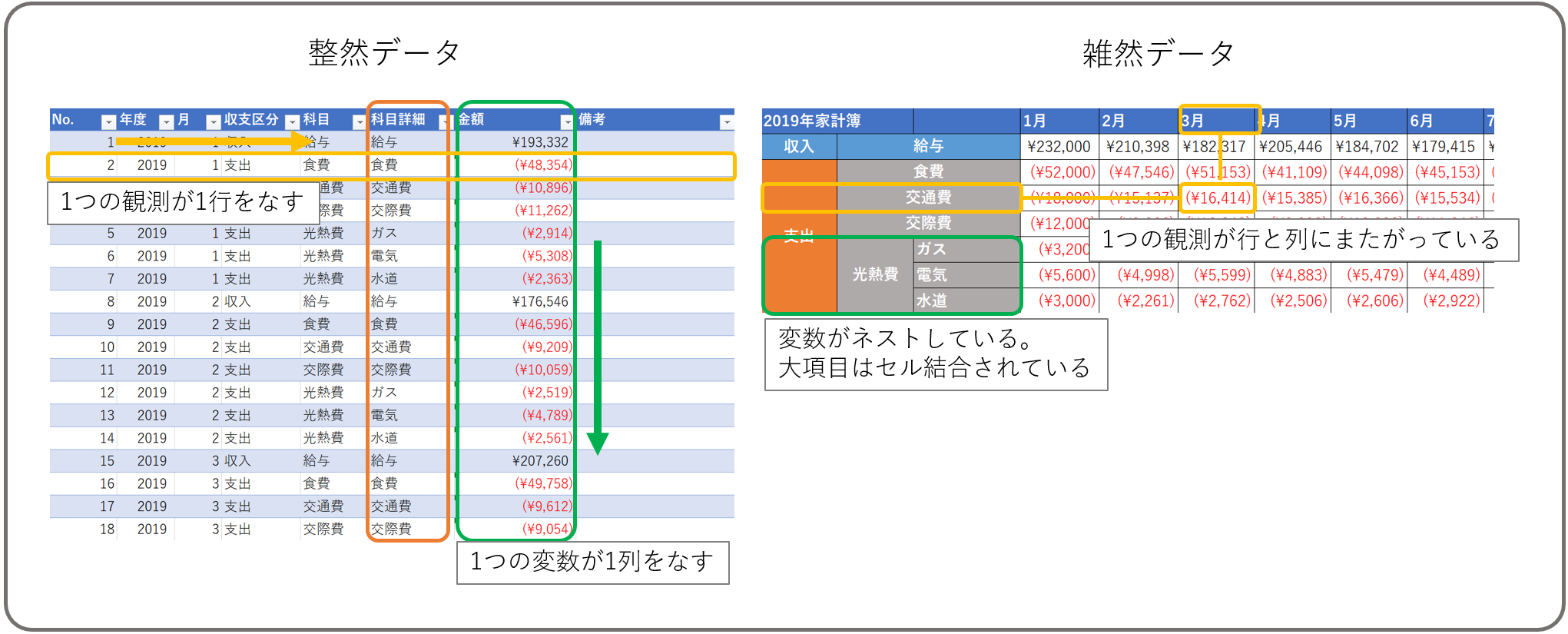
ともかくここで言いたいことは、「整然データ」というデータにとっての適切な形式2があり、その形式でデータを保持することでデータの再利用性がグッと上がるということだ。そしてExcelには整然データを保持するのにうってつけの機能がある。テーブルだ。
テーブルを使って整然データを管理する
やっと具体的なExcelの機能が出てきた。Excelのテーブル機能は整然データ保持のための機能と言い切って良いくらい整然データと相性が良い。一行目が項目名であり、1列が一つの変数を表す。そして1つの行に1つの観測が収まる。セル結合は禁止され、項目のネスト(大項目と小項目のような)もできない。いずれの制約も整然データの形式に当てはまる。
そして更に重要な点として、構造化参照が挙げられる。これはRやPythonなどを使ったデータ処理に近い取り扱いを可能にする機能だ。例えば以下のような家計簿テーブルがあったとする。
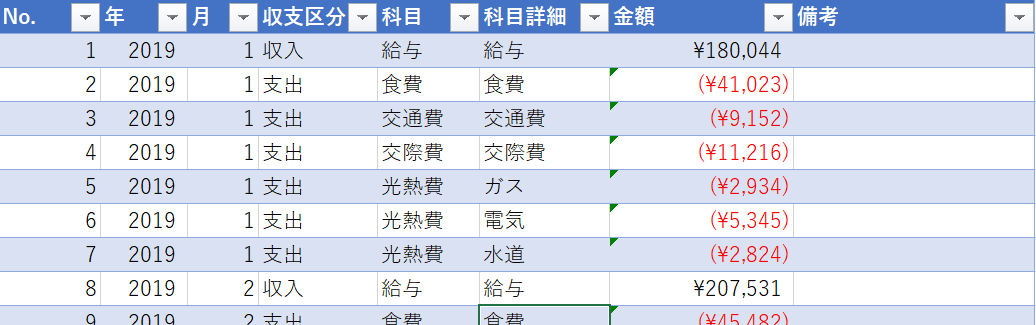
このテーブルの名称が「家計簿」の時、
家計簿[金額]
は家計簿テーブルの金額列への参照を表す。つまりブックのどこからでも(当然表現シートからでも)、
=SUM(家計簿[金額])
と書けば金額列の合計値を算出できるのだ。これはセル範囲を直接参照するのとは全く違う。セル範囲参照には指定された範囲、という以上の意味は無いが、構造化参照は「家計簿テーブルの金額列」というテーブル構造の一単位への参照だ。テーブルの行が増減しても問題ないし、数式を別人が(もしくは数ヶ月後の自分が)見たときの理解の速さも段違いだ。
また、上記の計算が、テーブルが整然データであるが故にシンプルになっている事も重要だ。例えば金額列がクロス集計のように1月金額列、2月金額列、、、と続いていた場合、月をまたいだ期間に渡る合計金額は(可能ではあるが)ここまで簡単には計算出来ない。「意味(=金額)と構造(金額列)の一致」という整然データの特長がここで活きている。
テーブルの特長
他にもテーブルの構造化参照の利点はある。既存の行のデータを基に新たな列を追加する操作はよくある処理の一つだが、この操作も非常に簡単に行うことが出来る。例えば上述の家計簿に「月初日」列を追加するにはテーブル右側に列を追加し、1行目に
=DATE([@年], [@月],1)
と入力する。@マークが「その行」を示すため、[@年]は同じ行の年列の値への参照だ。そして数式投入時にはオートコンプリートが働く。入力中に候補の列名がリスト表示されるため、選択してTabを押すだけで数式をサクサク書いていくことが出来る。
参考:[Excel] テーブルのすすめ 構造化参照 ~ Road to Cloud Office
まとめ(結論再掲)
まとめるとデータ再利用性の高いExcelブックは、
- データシートと表現シートが分離されており
- データシートは表現シートに依存せず
- データの形式は整然データの形をとっていて
- そのデータはExcelテーブルで保持されており
- 表現シートはデータテーブルへの構造化参照を使用して結果の出力を行う
といった特徴を備えるものである。と言えるのではないだろうか。当たり前のことしか言ってない感もあるが、とにかく整然データを分離して保護しよう、というところに尽きる。
補足
最後にいくつかの関連した話題について補足しておく。
分離が正義とは限らない
常にデータの再利用が発生するとは限らない。一回きりの使用が分かっているならば設計なんて考えずパッと作ってしまうほうが圧倒的に早かったりするので、ここで考えた方針は常に適用できるものではない。あくまでデータ再利用が想定される場面に適用を検討するものだろう。
整然データの列選択について
- 身体測定データで、「身長」と「体重」は単位も違うし別の列に入れるのが自然だが、では「身長」と「座高」は別の列とすべきだろうか?
- 予算と決算のデータにおける「予算金額」と「実績金額」は別の列とすべきだろうか?それとも「予実」列で区分けしてどちらも「金額」列に入れるべきだろうか?
- 個人データにおける「自宅電話番号」と「会社電話番号」はどうだろうか?
最後の電話番号の例は原論文で言及されているものだ。整然データでは「意味と構造の一致」が分析の容易性につながっているので、こういうときは「意味」に注目して列選択することになる。上記で言えば「身長」と「座高」はほとんどの文脈で明らかに別の意味(身体の別の属性値)なので、別の列にするのが自然だろう。一方で自宅電話と会社電話は「世の中の電話番号全体」を対象に分析を行う際には同じ意味(世に存在する電話番号の一つ)となる。
入力・演算・設定・アドホック分析
ここまで触れていなかったが、「データ」と「表現」以外にもExcelブックを構成する要素で考慮すべきものは色々ある。
入力
本記事ではデータシートに直接入力するという前提で話を進めたが、現実の場面では不特定多数の人が帳票などに入力し、それをデータとして集計するというシナリオも多いし、データの列が多くデータに入力しづらいこともある。そもそもマスターデータに直接入力していて違う行を消すなどミスをしたら困る。これについては別途検討が必要だろう。
演算
本文でも言及したDOVパターンでも使用されているように、演算を一つの責務と捉え別シートとするのは、計算が複雑になるほど有用になると考えられる。
設定
表現シートへの出力に、データ以外の変更要素が全く含まれないケースのほうが少ないのではないだろうか。例えば月次レポートを出力するシートを作ったとしたら、集計対象の「月」をどこかで指定しなくてはならない。そういう場面では「設定」に特化したシートなりテーブルを作り、それを表現シートから参照することも検討する必要があるだろう。
アドホック分析
表現シートは見た目にこだわる、というところからも推測されるように、定形レポート形式の出力が想定されている。一方でデータを分析する文脈ではデータを利用しながら、散発的にその場での分析をする場合もある。例えば家計簿であれば年間予算を去年の実績を基に検討する、といった場合だ。表現シートに予算入力欄を作ってそこで検討しても良いように思うが、例えばこの入力した予算自体も、蓄積されていくとデータとして再利用したくなるかもしれない。かといって、予算入力をデータシートで行い、都度表現シートと行き来しながら分析するのは不便極まりない。これについても別途検討が必要だろう。
雑然データの整然データ化
新しく作るデータは整然データにするとしても、手に入る既存のデータは雑然データであることが非常に多い。これらをデータとして再利用しやすくするためにはデータクレンジングを行って整然データ化する必要がある。
従来この辺はExcelではマクロを使わないで実現するのは中々難しかったが、現在ではPowerQuery(取得と変換)を使うことでかなりの事が出来るようになっているようだ。特に「列のピボット解除」は注目に値する。これは多数の同種列を属性列と値列の2列に変換することでクロス集計表を整然データ化することができる機能だ(R言語を使う人には、dplyrでいうところのgatherだと言えば伝わるだろうか)。具体的な使い方は以下の記事などが非常に参考になる。
- [Excel 取得と変換] クロス集計表やピボットレポートをシンプルな表(テーブル)に変換する ~ Road to Cloud Office
- [Excel]データが欲しいのに表をもらったのでノンプログラミングでデータに変える - Qiita
Excel方眼紙は悪か?問題
Wikipediaに掲載されていたり、ネ申エクセル問題で話題になったり、何かとお騒がせ的な存在だが、公開討論会まで開かれるほどコミュニティによって評価が極端に別れている。「そもそもExcelをDTPとして使うことの是非」といった観点もあるが、データ再利用性という観点で本記事の立場を考えると大体以下のようなものになるだろう。即ち「データから切り離された表現シートについては、Excel方眼紙を用いることは全く悪ではない」むしろ「Excel方眼紙を使わない」が教義と化してしまい、無理やり他の方法で表現を作り込むほうが生産性を落としてしまう可能性が高い。という立場だ。