普段はサービスのタスクを全く動かさず、SQS キューにメッセージが入っている時だけタスクの起動と AutoScaling を行う SQS + ECS によるキューワーカーパターンを構成しました。
また、様々な環境へ適用できるように、CloudFormation テンプレートを作成しました。
アイデアのベースは「SQS ECS」でググると先駆者様の構成例が多数出てきます。
私は主に去年の AWS ブログにあったこちらを参考にさせてもらいました。
アーキテクチャ
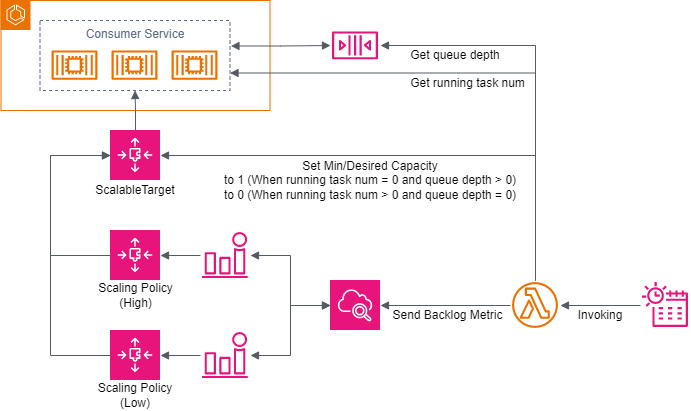
タスクバックログの算出し、その値に応じたスケーリング処理を行う点は、参考元をベースにしています。
さらにコストをケチるため、Application AutoScaling ターゲットのキャパシティ操作によるタスク起動有無の変更、スケーリング不要時にメトリクスの送信を中断する調整、ステップスケーリングポリシーによる1分周期のスケーリングを行っています。
適用する意味がありそうだと思う条件
-
普段はメッセージがないが、たまにメッセージがまとまった時間の間届く。
-
タスク数が0の時に送信されたメッセージの処理遅延を許容できる。
目安: バックログ計算用 Lambda の計算周期 + StepScaling の更新時間
データプレーンが EC2 なら + マネージドオートスケーリングのアラーム条件 と EC2 インスタンス起動時間 -
タスク数が0になるスケールイン発生時から暫く新規メッセージは発生しない。
少なくとも、メッセージ数が0になってから ECS タスク数が0になるまでの時間以上。
データプレーンが EC2 なら更に EC2 インスタンスがすべて停止するまでの時間以上。 -
2.と同様の目安でスケールアウトに少々時間を有しても問題ない。
-
SQS or SNS + Lambda で実装しようとすると実行時間が15分を超える可能性がある or 1関数の実行時間が15分未満になるような分割を自然な形で行えない。
-
SQS or SNS + Lambda などによるタスクディスパッチャ + One-shot な形で ECS タスク実行だとサービス当たりタスク数がクォーターを超える可能性がある。
-
AWS Batch で実装しようとすると1ジョブ実行当たりのオーバーヘッドを無視できない。
-
AWS Batch で実装しようとすると SUBMITTED 状態のジョブ数や submitjob API 呼び出し TPS がクォーターを超える可能性がある。
1はそもそもの SQS を挟む用途ですね。
2、3は常にコンシューマーが稼働している SQS + ECS or EC2 構成より有意になるための目安になります。
4は言い換えると、Lambda や 6. 構成による Fargete 上でのスケールアウト速度が必要か、ということです。
5~8はメッセージが存在する間だけコンピューティングに関する課金が発生してかつ、さらに AWS マネージドよりの構成を検討した際、それの適用が難しくなる条件になります。
実装解説
CloudFormation テンプレートと、AutoScaling 調整用 Lambda のコードになります。
CloudFormation テンプレート
AWSTemplateFormatVersion: 2010-09-09
Transform:
- AWS::Serverless-2016-10-31
Parameters:
SQSQueueName:
Type: String
ECSClusterName:
Type: String
ECSServiceName:
Type: String
MinCapacity:
Type: String
MaxCapacity:
Type: String
ExpectedMsgCapacityPerTask:
Type: String
Resources:
ScalableTargetECS:
Type: AWS::ApplicationAutoScaling::ScalableTarget
Properties:
ServiceNamespace: ecs
ResourceId: !Sub service/${ECSClusterName}/${ECSServiceName}
ScalableDimension: ecs:service:DesiredCount
MinCapacity: 0
MaxCapacity: 0
ScalingPolicyStepHigh:
Type: AWS::ApplicationAutoScaling::ScalingPolicy
Properties:
ScalingTargetId: !Ref ScalableTargetECS
PolicyName: step-high
PolicyType: StepScaling
StepScalingPolicyConfiguration:
AdjustmentType: ChangeInCapacity
StepAdjustments:
-
MetricIntervalLowerBound: 0
ScalingAdjustment: 1
Cooldown: 60
MetricAggregationType: Average
ScalingPolicyStepLow:
Type: AWS::ApplicationAutoScaling::ScalingPolicy
Properties:
ScalingTargetId: !Ref ScalableTargetECS
PolicyName: step-low
PolicyType: StepScaling
StepScalingPolicyConfiguration:
AdjustmentType: ChangeInCapacity
StepAdjustments:
-
MetricIntervalUpperBound: 0
ScalingAdjustment: -1
Cooldown: 60
MetricAggregationType: Average
AlarmHigh:
Type: AWS::CloudWatch::Alarm
Properties:
Namespace: CustomMetricsForAutoScaling/ECS/Task
MetricName: Backlog
Dimensions:
-
Name: ClusterName
Value: !Ref ECSClusterName
-
Name: ServiceName
Value: !Ref ECSServiceName
Statistic: Average
Period: 60
ComparisonOperator: GreaterThanThreshold
Threshold: !Ref ExpectedMsgCapacityPerTask
EvaluationPeriods: 1
DatapointsToAlarm: 1
TreatMissingData: notBreaching
AlarmActions:
- !Ref ScalingPolicyStepHigh
AlarmName: !Sub StepScaling-service/${ECSClusterName}/${ECSServiceName}-AlarmHigh
AlarmLow:
Type: AWS::CloudWatch::Alarm
Properties:
Namespace: CustomMetricsForAutoScaling/ECS/Task
MetricName: Backlog
Dimensions:
-
Name: ClusterName
Value: !Ref ECSClusterName
-
Name: ServiceName
Value: !Ref ECSServiceName
Statistic: Average
Period: 60
ComparisonOperator: LessThanOrEqualToThreshold
Threshold: !Sub -${ExpectedMsgCapacityPerTask}
EvaluationPeriods: 1
DatapointsToAlarm: 1
TreatMissingData: notBreaching
AlarmActions:
- !Ref ScalingPolicyStepLow
AlarmName: !Sub StepScaling-service/${ECSClusterName}/${ECSServiceName}-AlarmLow
RoleFunctionCalcBacklog:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
-
Effect: Allow
Principal:
Service:
- lambda.amazonaws.com
Action:
- sts:AssumeRole
-
Effect: Allow
Principal:
Service:
- scheduler.amazonaws.com
Action:
- sts:AssumeRole
Condition:
StringEquals:
aws:SourceAccount: !Ref AWS::AccountId
Policies:
-
PolicyName: inline
PolicyDocument:
Version: 2012-10-17
Statement:
# lambda basic execution policy
-
Effect: Allow
Action:
- logs:CreateLogGroup
Resource:
- !Sub arn:${AWS::Partition}:logs:${AWS::Region}:${AWS::AccountId}:*
-
Effect: Allow
Action:
- logs:CreateLogStream
- logs:PutLogEvents
Resource:
- !Sub arn:${AWS::Partition}:logs:${AWS::Region}:${AWS::AccountId}:log-group:/aws/lambda/*:*
# function specific
-
Effect: Allow
Action:
- sqs:GetQueueAttributes
Resource:
- !Sub arn:${AWS::Partition}:sqs:${AWS::Region}:${AWS::AccountId}:${SQSQueueName}
-
Effect: Allow
Action:
- ecs:DescribeServices
Resource:
- !Sub arn:${AWS::Partition}:ecs:${AWS::Region}:${AWS::AccountId}:service/${ECSClusterName}/${ECSServiceName}
-
Effect: Allow
Action:
- application-autoscaling:RegisterScalableTarget
Resource:
- !Sub arn:${AWS::Partition}:application-autoscaling:${AWS::Region}:${AWS::AccountId}:scalable-target/*
Condition:
StringEquals:
application-autoscaling:scalable-dimension: !Select [ 1, !Split [ "|", !Ref ScalableTargetECS ] ]
application-autoscaling:service-namespace: !Select [ 2, !Split [ "|", !Ref ScalableTargetECS ] ]
-
Effect: Allow
Action:
- cloudwatch:PutMetricData
Resource:
- "*"
Condition:
StringEquals:
cloudwatch:namespace: CustomMetricsForAutoScaling/ECS/Task
# eventbridge scheduler
-
Effect: Allow
Action:
- lambda:InvokeFunction
Resource:
- !Sub arn:${AWS::Partition}:lambda:${AWS::Region}:${AWS::AccountId}:function:*
- !Sub arn:${AWS::Partition}:lambda:${AWS::Region}:${AWS::AccountId}:function:*:*
FunctionCalcBacklog:
Type: AWS::Serverless::Function
Properties:
CodeUri: ./calc_backlog_sqs_ecs.py
Runtime: python3.11
Handler: calc_backlog_sqs_ecs.lambda_handler
Architectures:
- arm64
MemorySize: 256
Timeout: 30
Role: !GetAtt RoleFunctionCalcBacklog.Arn
Environment:
Variables:
SQS_QUEUE_URL: !Sub https://sqs.${AWS::Region}.amazonaws.com/${AWS::AccountId}/${SQSQueueName}
ECS_CLUSTER_NAME: !Ref ECSClusterName
ECS_SERVICE_NAME: !Ref ECSServiceName
MAX_CAPACITY: !Ref MinCapacity
MIN_CAPACITY: !Ref MaxCapacity
EXPECTED_MSG_CAPACITY_PER_TASK: !Ref ExpectedMsgCapacityPerTask
AutoPublishAlias: prod
AutoPublishAliasAllProperties: false
DeploymentPreference:
Enabled: true
Type: AllAtOnce
ReservedConcurrentExecutions: 1
EventInvokeConfig:
MaximumRetryAttempts: 0
Events:
EventSchedule:
Type: ScheduleV2
Properties:
State: ENABLED
OmitName: true
GroupName: default
ScheduleExpression: cron(* * * * ? *)
FlexibleTimeWindow:
Mode: "OFF"
ScheduleExpressionTimezone: UTC
RetryPolicy:
MaximumEventAgeInSeconds: 60
MaximumRetryAttempts: 0
RoleArn: !GetAtt RoleFunctionCalcBacklog.Arn
Tags:
Name: !Sub calc-backlog-sqs-ecs-${ECSClusterName}-${ECSServiceName}
Python による Lambda 実装
from json import dumps
from os import environ
import boto3
_sqs_client = boto3.client("sqs")
_ecs_client = boto3.client("ecs")
_application_autoscaling_client = boto3.client("application-autoscaling")
_cw_client = boto3.client("cloudwatch")
_SQS_QUEUE_URL = environ.get("SQS_QUEUE_URL")
_ECS_CLUSTER_NAME = environ.get("ECS_CLUSTER_NAME")
_ECS_SERVICE_NAME = environ.get("ECS_SERVICE_NAME")
_MAX_CAPACITY = int(environ.get("MAX_CAPACITY", 1))
_MIN_CAPACITY = int(environ.get("MIN_CAPACITY", 1))
_EXPECTED_MSG_CAPACITY_PER_TASK = int(environ.get("EXPECTED_MSG_CAPACITY_PER_TASK", 1))
def _put_metric(
ecs_cluster_name: str, ecs_service_name: str,
approximate_number_of_messages: int, running_count: int, expected_msg_capacity_per_task: int):
_cw_client.put_metric_data(
Namespace="CustomMetricsForAutoScaling/ECS/Task",
MetricData=(
{
"MetricName": "Backlog",
"Dimensions": [
{
"Name": "ClusterName",
"Value": ecs_cluster_name,
},
{
"Name": "ServiceName",
"Value": ecs_service_name,
},
],
"Value": approximate_number_of_messages - running_count * expected_msg_capacity_per_task
},
),
)
def handler_main(
sqs_queue_url: str, ecs_cluster_name: str, ecs_service_name: str,
min_capacity: int, max_capacity: int, expected_msg_capacity_per_task: int):
sqs_queue_attributes = _sqs_client.get_queue_attributes(
QueueUrl=sqs_queue_url,
AttributeNames=(
"ApproximateNumberOfMessages",
"ApproximateNumberOfMessagesDelayed",
"ApproximateNumberOfMessagesNotVisible",
),
)["Attributes"]
approximate_number_of_messages = int(sqs_queue_attributes["ApproximateNumberOfMessages"])
approximate_number_of_messages_delayed = int(sqs_queue_attributes["ApproximateNumberOfMessagesDelayed"])
approximate_number_of_messages_not_visible = int(sqs_queue_attributes["ApproximateNumberOfMessagesNotVisible"])
running_count = _ecs_client.describe_services(
cluster=ecs_cluster_name,
services=(ecs_service_name, ),
)["services"][0]["runningCount"] # pyright: ignore[reportTypedDictNotRequiredAccess]
print(dumps(
{
"ApproximateNumberOfMessages": approximate_number_of_messages,
"ApproximateNumberOfMessagesDelayed": approximate_number_of_messages_delayed,
"ApproximateNumberOfMessagesNotVisible": approximate_number_of_messages_not_visible,
"runningCount": running_count,
},
separators=(",", ":"),
))
if not running_count:
if approximate_number_of_messages:
print("start task")
_application_autoscaling_client.register_scalable_target(
ServiceNamespace="ecs",
ResourceId=f"service/{ecs_cluster_name}/{ecs_service_name}",
ScalableDimension="ecs:service:DesiredCount",
MinCapacity=min_capacity,
MaxCapacity=max_capacity,
)
_put_metric(
ecs_cluster_name, ecs_service_name,
approximate_number_of_messages, min_capacity, expected_msg_capacity_per_task
)
else:
# no message
pass
return
assert running_count
if all((
not approximate_number_of_messages,
not approximate_number_of_messages_delayed,
not approximate_number_of_messages_not_visible,)):
print("shutdown all tasks")
_application_autoscaling_client.register_scalable_target(
ServiceNamespace="ecs",
ResourceId=f"service/{ecs_cluster_name}/{ecs_service_name}",
ScalableDimension="ecs:service:DesiredCount",
MinCapacity=0,
MaxCapacity=0,
)
return
_put_metric(
ecs_cluster_name, ecs_service_name,
approximate_number_of_messages, running_count, expected_msg_capacity_per_task
)
def lambda_handler(event, context):
handler_main(
_SQS_QUEUE_URL, _ECS_CLUSTER_NAME, _ECS_SERVICE_NAME, # pyright: ignore[reportGeneralTypeIssues]
_MAX_CAPACITY, _MIN_CAPACITY, _EXPECTED_MSG_CAPACITY_PER_TASK # pyright: ignore[reportGeneralTypeIssues]
)
def main():
handler_main(
_SQS_QUEUE_URL, _ECS_CLUSTER_NAME, _ECS_SERVICE_NAME, # pyright: ignore[reportGeneralTypeIssues]
_MAX_CAPACITY, _MIN_CAPACITY, _EXPECTED_MSG_CAPACITY_PER_TASK # pyright: ignore[reportGeneralTypeIssues]
)
if __name__ == "__main__":
main()
検証用スクリプト含む全ソースコードは GitHub の方で公開しております。
タスク起動の有無設定
タスクの起動有無は Application AutoScaling ターゲットのタスクの要求/最小キャパシティを、メッセージが存在してタスクが1つもない場合に 0 -> MinCapacity、メッセージが存在せずタスクが存在する場合に MinCapacity -> 0 となるよう設定することで実現しています。
大量のメッセージが送信された後は暫くメッセージ送信が発生しない前提のもと、SQS キューが空になった際、立ち上がっているタスクをすべて停止するようにしてケチっています。
スケールインもまずはポリシー通りに行いたい場合は、runningCount <= MinCapacity を if 条件文に含めることで可能です。
(そこまでするなら常に最小キャパシティを 0 にして Alarm の閾値を上手くすれば出来そうな気もします)
タスク終了判定は、取得可能メッセージ、遅延メッセージ、処理中メッセージすべてが0であれば行います。
特に処理中メッセージは考慮しないとメッセージを残したまま全タスクが停止してしまいます。
コンシューマー側の実装で、処理の途中ではなく最後にメッセージの削除処理を行うようにすることは忘れないようにしましょう。
バックログのメトリクス
参考元は (取得可能メッセージ数 / タスク数) より、現状1タスクが受け持つメッセージ数をバックログとしていましたが、個人的に直感的にしたく、本実装では (取得可能メッセージ数 - 1タスクが受け持つことができる最大メッセージ数 (以下, 許容遅延メッセージ数) * タスク数) より求めた遅延メッセージ数としています。
PutMetricData API 呼び出しもケチるため、メッセージが存在する状況のときのみメトリクスを送信するようにしています。
スケーリングポリシーとアラーム条件
これに限らずですが、ターゲット追跡スケーリングポリシーだと、自動生成される CloudWatch Alarm のしきい値より、スケールアウト開始は最短3分、スケールインは15分を要します。
なるべく早くスケーリングさせたいので、直近1分のデータポイントのみ用いたステップスケーリングポリシーで行います。
アラーム条件ですが、バックログが許容遅延メッセージ数を超えれば1タスクスケールアウト、逆に 1タスク分余裕ができれば1タスクスケールインするようにしています。
遅延を許さない場合はスケールアウト条件を バックログ > 0 にすることで、急激なスケールアウトはスケールアウト条件の追加で可能です。
記事を書いてて思ったのですが、コストが変わらないなら処理が早いことに越したことはありませんし、キューが空の時は Lambda から要求/最小キャパシティを0にして強制スケールインするので、スケーリングポリシーでのスケールインは不要かもしれません。
動作確認
動作確認のため、25秒に1回メッセージを送信するプロデューサーを模擬するスクリプトと、1つメッセージを取得後、DynamoDB へそれを書き出して60秒スリーブするコンシューマーを模擬するコンテナを作成しました。
これを用いていい感じに動くかみてみます。AutoScaling では、最小キャパシティ1、最大キャパシティ4、許容遅延メッセージ数10で実行しています。
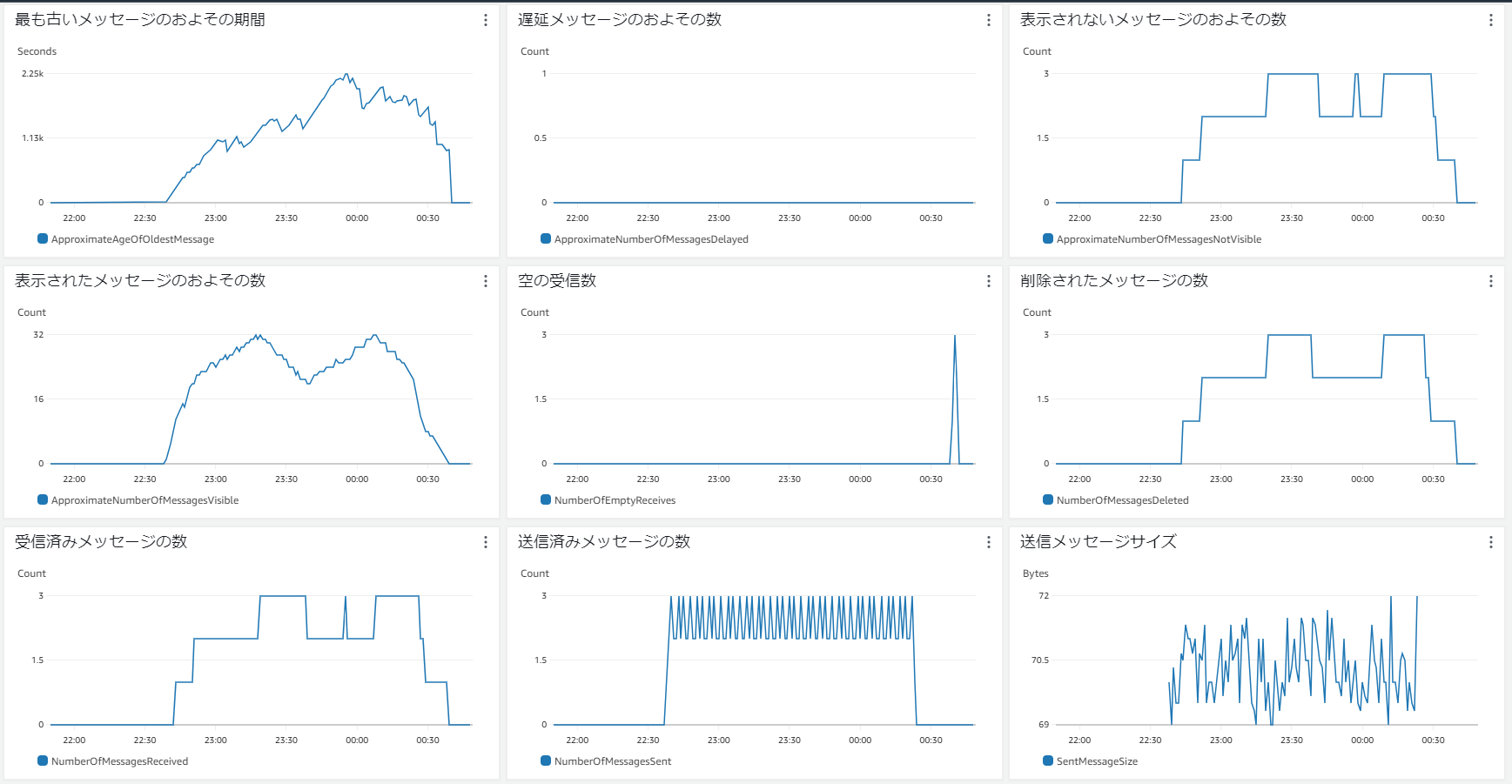
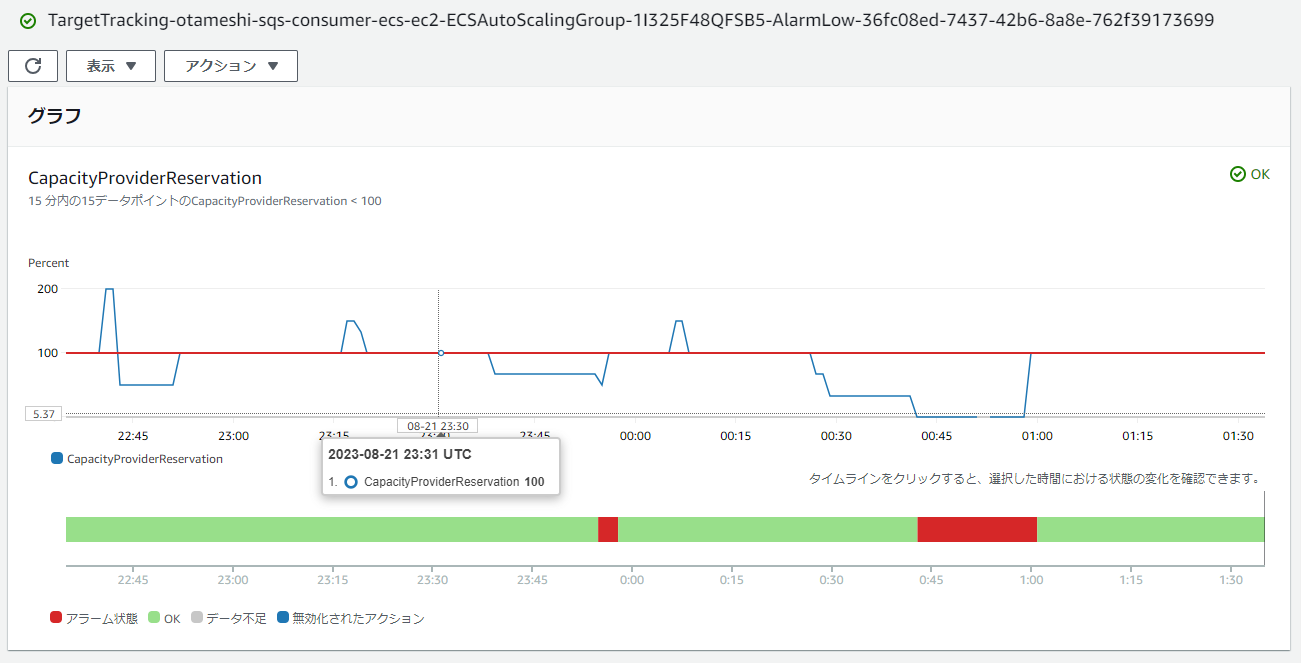
SQS キューのメトリクス
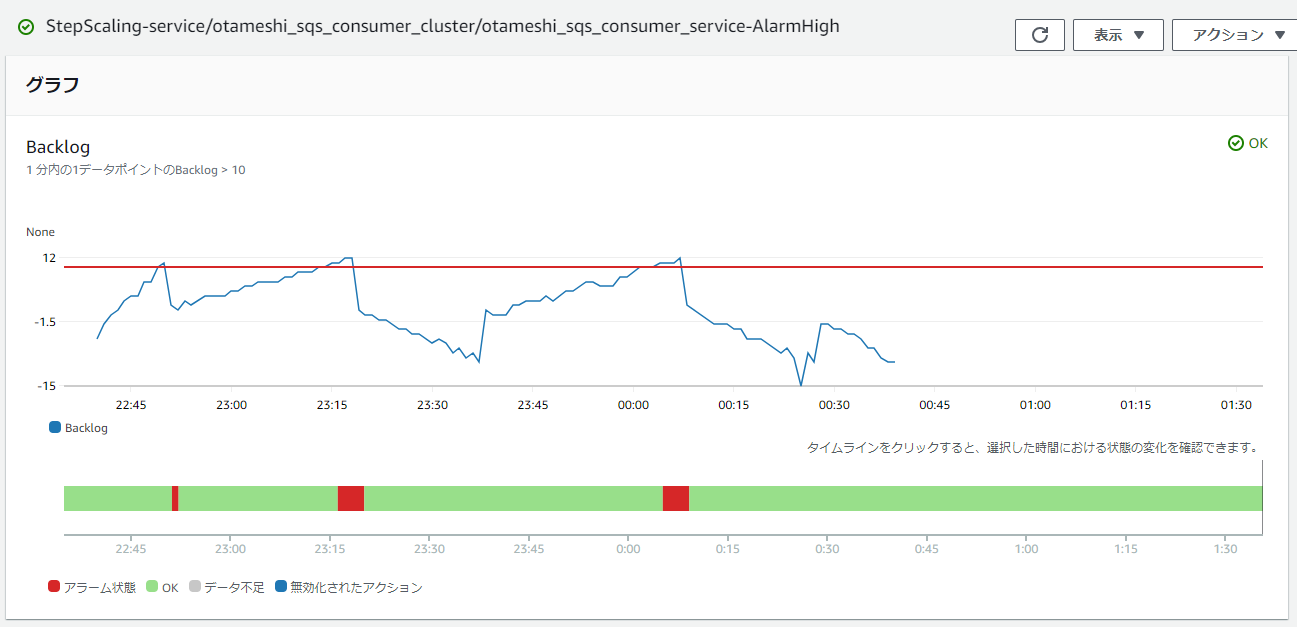
CloudWatch Alarm でのバックログ値によるアラーム
スケールアウトアラーム
スケールインアラーム
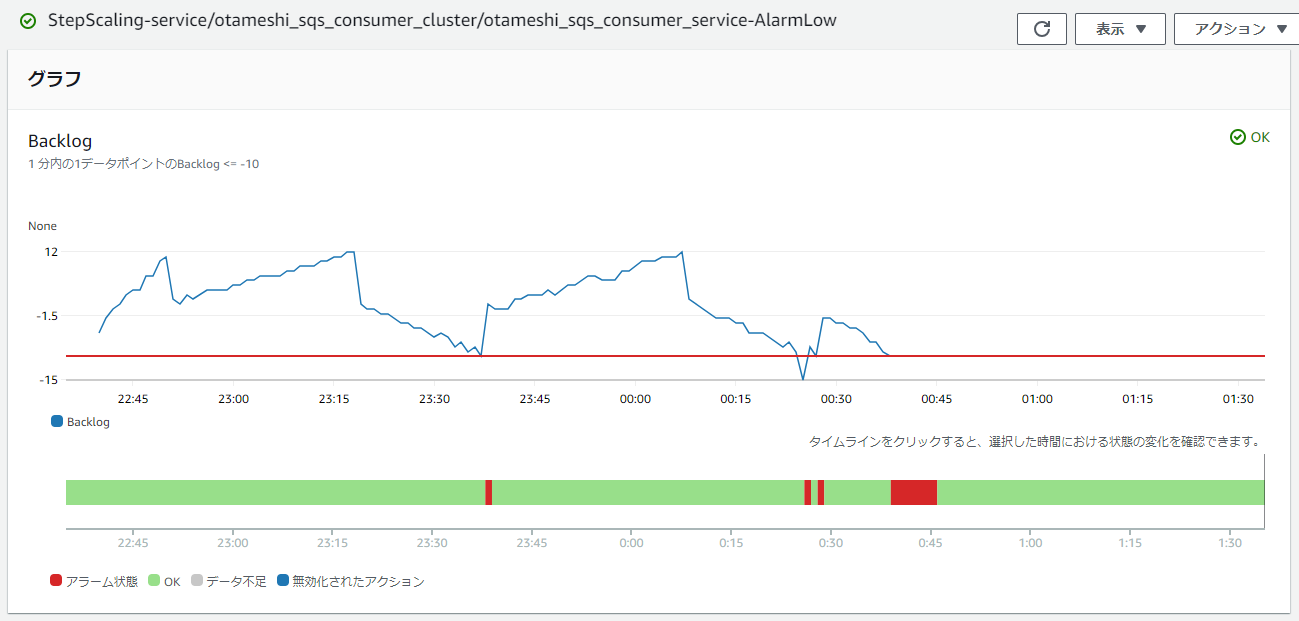
バックログはタスク数が2の時は増加、タスク数が3の時は減少しており、プロデューサーを停止させて数分経った0:30手前では2回スケールインが発生して、大体10分後に全タスクが終了してます。
キューの空の受信数についても、メッセージをすべて消費してから次のスケーリングが発生する1分の間に、ロングポーリングの際に発生した3回だけで済んでいます。いずれのメトリクスも期待通りに動いています。
データプレーンを EC2 にして ECS マネージドスケーリングを有効化した場合ですが、自動で構成されるスケールアウト用アラームしきい値が1分内の1ポイントに対して、スケールイン用のそれは15分以内の15ポイントなので、ECS タスク終了後もしばらくはインスタンスが残り続けます。
こちらは起動に時間を有する分、タスク数の増減に合わせて頻繫にスケールインするわけにもいかないので、自動生成されたアラームの意図通り、しばらく様子をみてから停止処理でいいと思います。
コストオーバーヘッド
最低1つタスクが動いているアーキテクチャより稼働コストが高いと、そちらの方が簡単なうえに安いという本末転倒になるので、きちんと計算します。
Lambda の実行周期は1分、割り当てメモリ256MB、平均実行時間300ミリ秒としています。
# EventBridge Scheduler
$1.251/M calling
1min/calling = 43800 calling/month = $0.0547938/month
# CloudWatch Metrics
1 custom metrics = $0.30/month
$0.01/1000 PutMetricData requests
1min/requests = 43800 requests/month = $0.438/month (worst case)
# CloudWatch Alarm
$0.10/alarm/month
2 alarms = $0.20/month
# Lambda ARM
$0.20/M requests
1min/requests = 43800 requests/month = $0.00876/month
$0.0000133334/GB-Sec
= $0.00000333335/.25GB-Sec
= $0.000001000005/.25GB-300msec
$0.000001000005 * 43800 requests/month = $0.043800219/month
total
0.0547938 + 0.30 + 0.438 + 0.20 + 0.00876 + 0.043800219 = $1.045354019/month + Logs のコスト
となり、 1.05USD/月くらいかかります。データプレーンが EC2 だと EC2 AutoScaling 用の CloudWatch Alarm が2つ作成されるので、+0.20で1.25USD/月になります。
仮に Fargete Spot の最小構成で動くような実装だったとしても、3.373695USD/月かかるので悪くはない感じです。
やった理由とか感想とか
私が開発しているもの中に、普段は1分や10分ごとにセンサーデータ含むファイルが送信されるが、1週間ぐらい通信不通になることも普通にあり得て、復旧時に通信不通時のデータが間髪入れずまとめて送信され、それらを処理するというのもあります。リソース予測が非常に難しいため、コンピューティング環境はほとんど Lambda に頼り切っている状態です。
これを Lambda を使えない状況だったらどのように実装しようかとふと思い盆休み中に組んでみました。業務で中々 ECS/EC2 を使う機会がなく、試してみたかったというのもあったので中々面白かったです。それと同時に、Lambda や AWS Batch がマネージドで行ってくれるスケーリング処理の便利さを実感することになりました、感謝。