どうもこんにちは。さだまさしアドベントカレンダーも皆さんのご参加のおかげでもう少し頑張れば25日間完走できそうな雰囲気が出てきたので、僕も少し欲が出てきました。ということで、こういう軽めの記事を書いて穴埋めをしようかなと思います。
Word2Vec
「Word2Vec」は昨年火がつき、すっかり技術者界隈ではバズワード化を超えて汎用的なツールとして定着した感があるので、説明は割愛します。
Word2Vec が世の中に紹介された時のユースケースとして、単語の意味ベクトル同士の計算で語の類似度が算出できるというものが一番認知されていると思いますので、この記事でも、さだまさしの歌から単語を抜き出して語間の類似度を調べてみたいと思います。
デモサイト (単語の類似度)
https://sadatech.herokuapp.com/word2vec
さだまさしの歌詞から抽出した、2500語程度の単語(名詞句)を元に意味ベクトルを作ってみました。上記デモサイトでは、入力した単語と近しい単語を類似度が高い順に 10 件返却します。
対象となる単語はサジェスト表示されるようになっています。逆にサジェストされない単語は上記サイトでは含まれてないのであしからず。
実行例 : 「君」
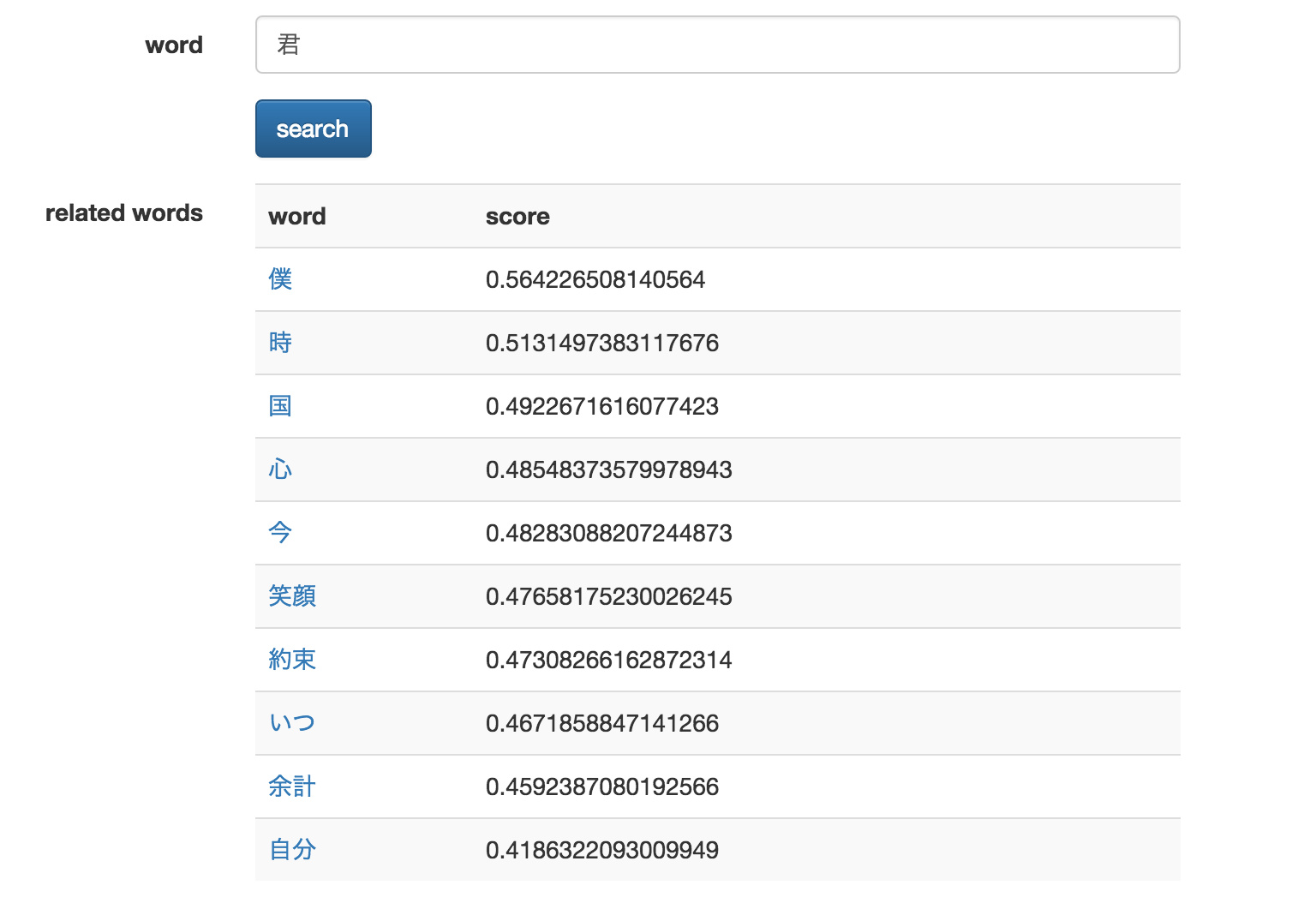
「僕」が一番スコアが高いのは、何かそれらしい感じがしますね。
また「笑顔」や「約束」という言葉は、特定の歌の歌詞を想起させます。
実行例 : 「生」
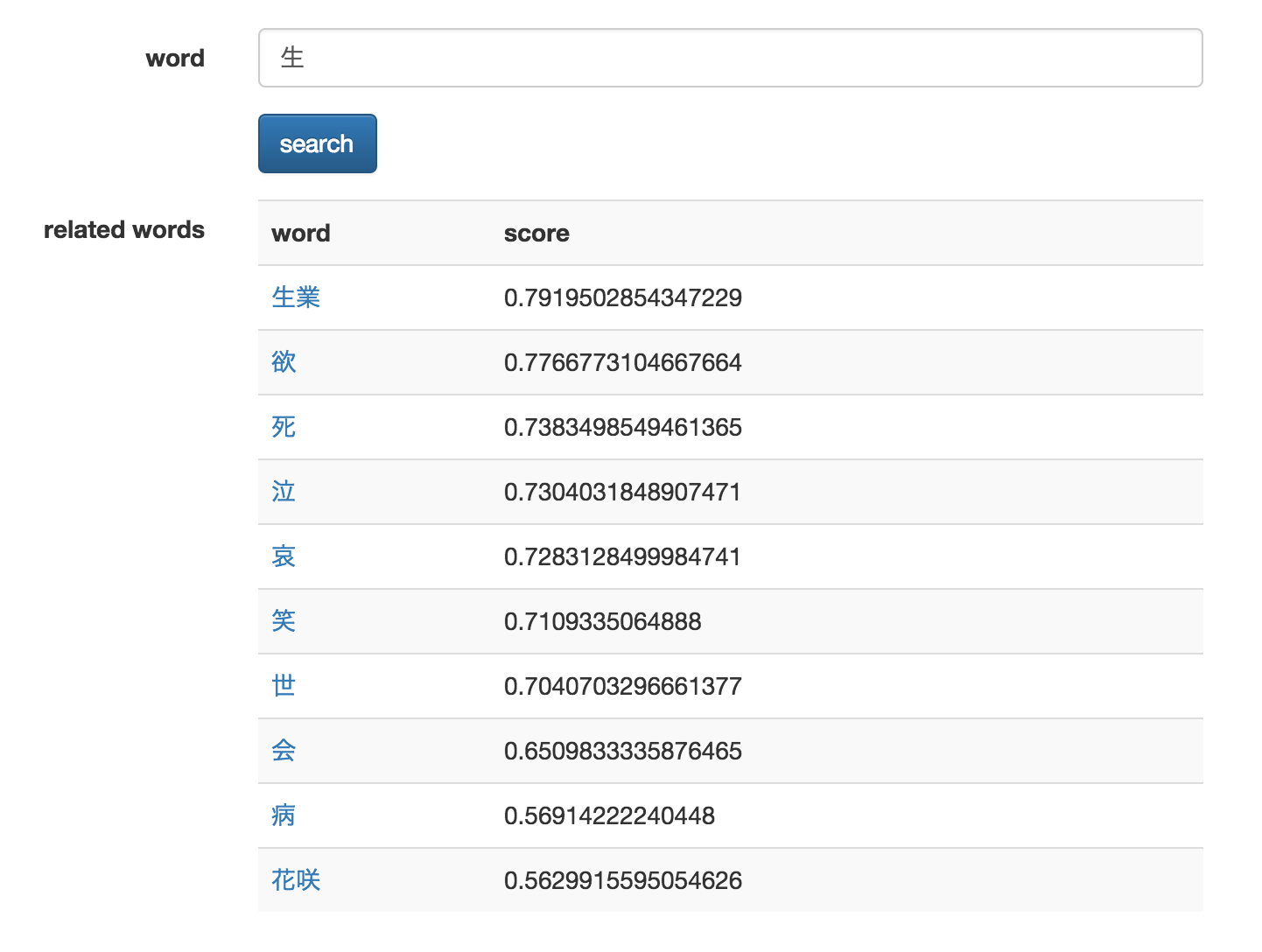
「生業」「欲」「死」「泣」「哀」と、何か荘厳なものを感じさせます......
デモ (意味ベクトルの計算)
Word2Vec が衝撃的だったことは、たとえば 「フランス」 - 「パリ」 + 「東京」 = 「日本」 といったような感じで、意味ベクトル同士の直感的でナイーブな加減算によりそれらしき概念が抽出できることです。
こちらの動作が試せるようなものについてもデモサイトに公開しようかと思ったのですが、使っているライブラリ (ND4J) の関係で heroku ではうまく動作させることが出来ないようで、ローカルでの実験結果だけを貼ります。
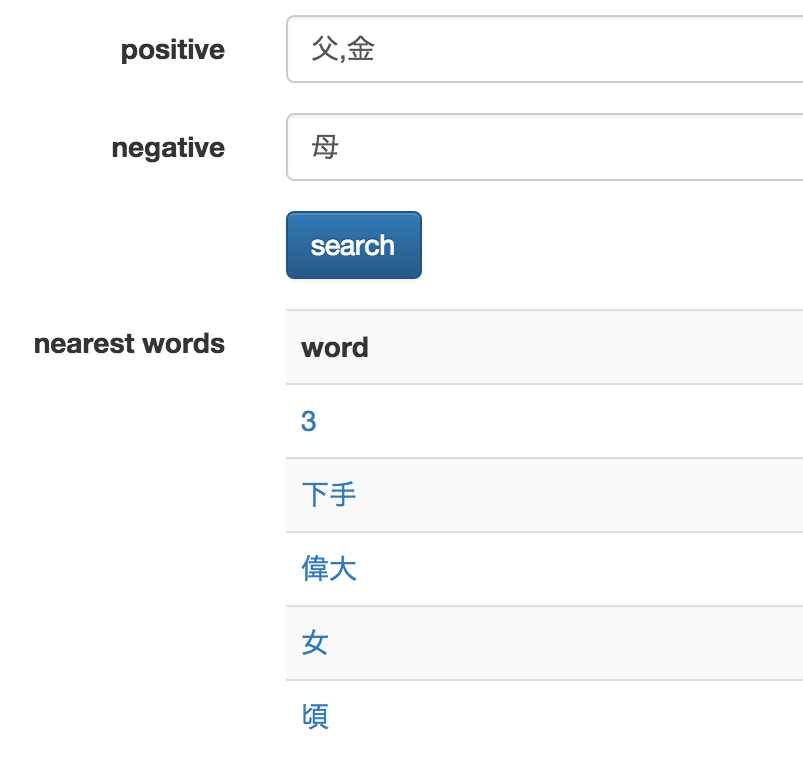
実行例: 「父」-「母」+「金」= ?
答えは「偉大」「女」などです...💰👄 リアル(?)すぎて、いろいろと考えさせられます。。
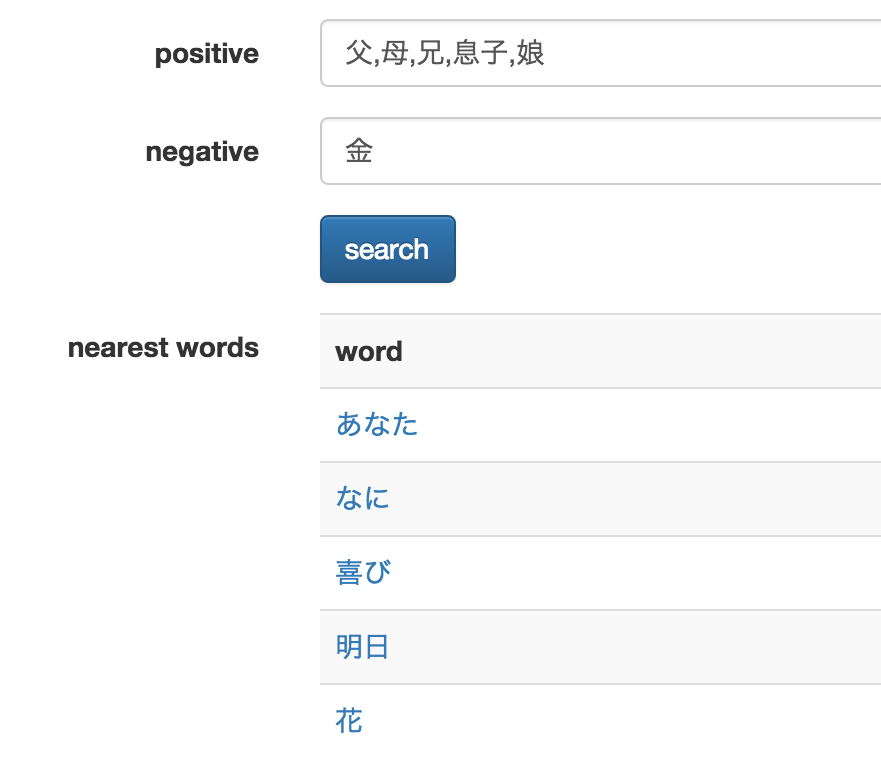
実行例: 「父」-「金」+「母」+「兄」+「息子」+「娘」= ?
答えは「あなた」「喜び」「明日」など。荒みかけた心に暖かな安らぎが訪れました。
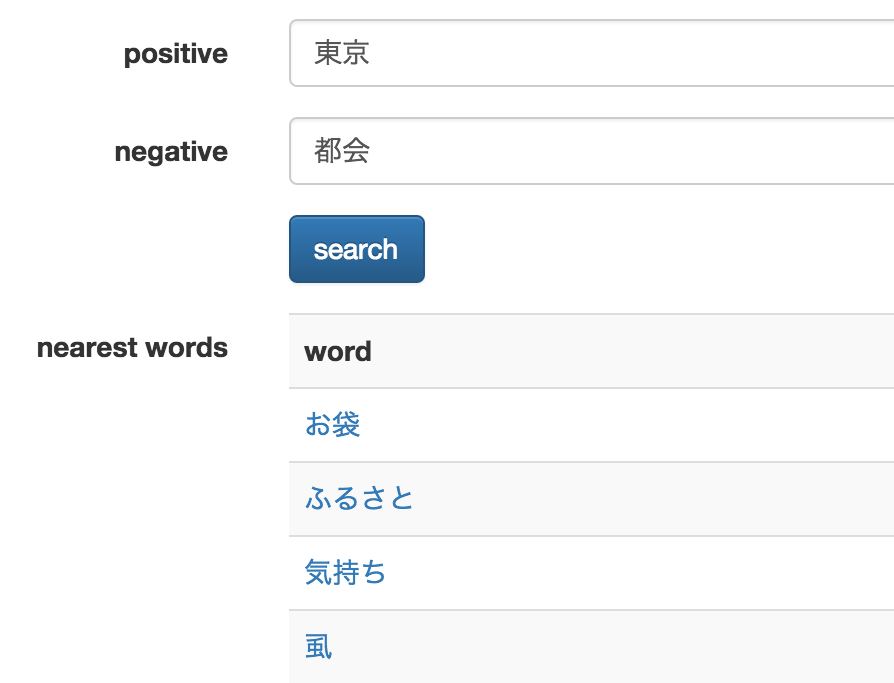
実行例: 「東京」-「都会」= ?
「虱」はよく分かりませんが、、「お袋」「ふるさと」などが抽出され、さだまさしの歌の心情が慮れる結果と言えるかもしれません。
実装
deeplearning4j
今回も Java で実装してみよう、ということで、Java 製の OSS として公開されている deeplearning4j を今回は用いてみたいと思います。
こちらのライブラリは、 Word2Vec だけでなく、文書に応用をした ParagraphVector などの実装も含まれています。また名前の通り、それ意外の deeplearning 系のアルゴリズムも多種多少なものが揃っているようです。
そして、今のビッグデータの時代を見越して、単純なライブラリとしての動作というよりは大規模分散基盤上での動作を念頭に置かれており、Spark などと連携して大規模なデータの並列計算なども行えるようになっている、とても重厚なライブラリです。
以下は、今年の Hadoop Summit で発表されたプレゼン資料です。(超余談ですが私は現地で聴いてました)
Applied Deep Learning with Spark and Deeplearning4j
install
基本的に jar が maven repository に公開されているので、そちらを定義するだけで使えるようになります。
今回、ローカルで単一環境で動作させるだけであれば、以下のような定義でOKです。なお、 nd4j は多次元配列を扱うための Java 実装のひとつのようです。
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-core</artifactId>
<version>0.4-rc3.7</version>
</dependency>
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-nlp</artifactId>
<version>0.4-rc3.7</version>
</dependency>
<dependency>
<groupId>org.nd4j</groupId>
<artifactId>nd4j-jblas</artifactId>
<version>0.4-rc3.6</version>
</dependency>
sample
Word2Vec の意味ベクトルを作り、それらを比較して結果として似ている語 ( nearest words ) を取得するためには、以下の手順で行います。
- 文書の用意
- 文書データを SentenceIterator で読み込み
- TokenizerFactory の準備
- 2,3,を踏まえて、 Word2Vec のインスタンス初期化
- fitting (model の train)
- 結果取得
// 2.
CollectionSentenceIterator it = new CollectionSentenceIterator(docs);
// 3.
TokenizerFactory tokenizer = new UimaTokenizerFactory();
// 4.
Word2Vec vec = new Word2Vec.Builder().minWordFrequency(2).iterations(5).layerSize(100).stopWords(stopwords).iterate(it).tokenizerFactory(tokenizer).build();
// 5.
vec.fit();
// 6.
System.out.println(vec.wordsNearest("父",10));
個人的に触り始めのライブラリということもあり、Tokenizer の挙動に確信がなかったので、今回はあらかじめ kuromoji で形態素解析(分かち書き)済みのデータを文書として渡して解析を行ってみました。
まとめ
各種言語版の実装が存在しますが、Java においても deeplearning4j を用いると簡単に Word2Vec 風な意味ベクトルを作成することが出来ました。
正直パラメータチューニングや文書データの前処理はあまりまじめに行っていないのですが、そこそこそれなりな動作をしているように思えます。
こういうツールを使って歌詞を解析していくのも面白いかもしれませんね。