私が所属している SRE チームでは、いわゆる狭義の SRE 的な業務だけでなく、Platform Engineering 的な活動もあわせて行っています。
Platform Engineering としての施策についてもその範囲は広いですが、この記事ではその中の一つの取組みとして、SREチームが主導して進めようとしている 「横断的品質改善」 の施策について書かせていただきます。
前置き:品質について
品質を改善する、とした場合、まず大前提として 「品質とはなにか」 ということを定義する必要があります。
この話は無限に話題が膨らみそうですし、この記事で網羅的な解説はできないので、ここでは前提をかなりすっ飛ばして、「品質が保たれている」とはつまり以下のような状態だ、と定義するとします。
1. 要件を満たしていること
- 機能要件
- 「この機能は A を入力すると B が出力されます」という機能について、Aを入力したら正しく B が出力されること
- 非機能要件
- 機能を実現するために支障がある状態でないこと。端的には以下のようなことが起こらないこと
- 処理に異常に時間がかかる(レイテンシ)
- 稀にエラーが発生する(リライアビリティ)
- 複数のリクエストが同時に接続した場合、メモリが不足した場合、サービス再起動時に接続した場合、等
- 入力した内容が外部に漏洩する(セキュリティ)
- etc.
- 機能を実現するために支障がある状態でないこと。端的には以下のようなことが起こらないこと
2. 技術的負債が無いこと、もしくは少ないこと
※技術的負債については後述します
1, 2 について、いずれについても、改善をしたいと思うのであれば現状を把握することが必要で、今の状況を測定した上でどのように改善をしていくか、を考える必要があります。
前置き: いかにして問題をとくか
「改善をしたい」と思った時に、ただ思うだけで、口に出すだけでは前に進まないため、適切な改善プロセスを取る必要があります。
ここでは、世界的名著である 「いかにして問題をとくか」に記載されている内容をベースに整理します。
当書では、問題をとくためのプロセスを以下のように整理しています。
- 問題を理解すること
- 計画を立てること
- 計画を実行すること
- ふりかえってみること
この書籍の内容を基に、自分なりに咀嚼した内容が以下です。
まず、問題を理解するためには、 「問題を正しく定義する(解決するべきゴールを明確にする)」 必要があります。その定義した「問題」が妥当なのかを判断する上でも、今起こっている事を 「正確に測定すること」 が必要です。
問題の定義に失敗すると、その後のアクションを行っても見当違いのアクションになりがちで、かけた時間に比して効果が出ないことが多いです。
また、計画を立てた改善策を実行してどうだったのかを振り返る際にも、 「起こっている事を正確に測定すること」 が必要になります。
ということで、開発の現場においては、問題を定義し解決していくためには、以下のプロセスが必要そうです。
1. 解決すべき「課題」の候補のリストアップ
2. 課題の「原因」の調査と特定
3. どのような状態になれば解決したか、「解決の定義」を整理
4. 「課題」の「原因」と「解決の定義」を整理した上で、どのようにすれば解決できるのか、「解決策」について検討
- 解決策には、複数の選択肢があって良い
5. 解決策を実際に「実行」する
6. 実行した結果について、指標をもとに「効果測定」をして振り返り、どのような結果をもたらされたか分析
- この上で新たな問題が発見、もしくは発生した場合は、1に戻る
例
極めてわかりやすいものについて、例として
- 課題: あるサービスが重い
- 原因: 様々あるが、データベースへの接続処理(SQLの処理)に時間がかかっている
- LCP などの指標で画面の重さを測定
- APM などを用いてアプリケーション内の Time Spent を測定
- DB の処理時間が処理時間の中で支配的
- パフォーマンスが劣化しているタイミングで DB の CPU 負荷が高まりリソース枯渇している
- 解決の定義: いくつかの指標について改善が見られたら、解決・改善とみなす
- 初期: LCP
- 現在: SlowQuery、 DB の System Usage
- 解決策: 以下
- SQL チューニング
- インデックスの付与
- SQL の改修
- テーブル構造の改修
- 仕様として重たい SQL を発行しないように修正する
- 不要な画面・機能を削除する、等
- etc
- 効果測定: 各種指標をもとに改善しているか否かを判断
これらのプロセスを踏まないで施策だけ実行して、良い結果をもたらすこともありますが、それはマークシートの回答をサイコロの出た目で埋める事に等しく、当たることもあるし外れることもあるし、どちらかというとハズレる事の方が多いと思います。もしくはハズレた事にも気づかないかもしれません。
もちろん上記プロセスを経ても間違える事はありますが、不確実性を減らすことはできると考えています。
SRE チームとしての品質への取り組み
ここからが本題になっていきます。
上記に挙げた「品質」について、SREチームでどのように捉え、改善に取り組んでいるか、もしくは取り組んでいこうとしているかを書いていきます。
機能要件について
まず、機能要件については、こちらは横断的チームの役割というより各プロダクト開発チームの責務、として捉えています。
Team Topology における「Stream-aligned team」 の役割ですね。
なので、ここではこれ以上は特に触れません。
非機能要件について
SRE チームは第一に 「課題の発見」 について責任を負うと考えています。
- エラー件数
- パフォーマンス・レイテンシ
- セキュリティ
- etc
課題を発見するためには、適切に 「計測」 を行う必要がある。
今風の言葉で言うと Observablity を向上させる必要がある。
という感じだと認識しています。
Observablity を向上させ、課題の発見を容易に行えるような状況を作ることが SRE チームの基本的な役割になり、発見された課題の解消については、各開発チームと協力しながら実施を行っていく。というのが多くの現場でもそうでしょうが基本的な流れになると思います。
この辺は以前 Datadog を軸にした施策について書いた記事があるので、そちらを引用するにとどめます。
技術的負債について
最近バズワード化している 「技術的負債」 ですが、この言葉は極めて曖昧で、 「技術的負債」と一言で言おうとするとその人の主義主張や趣味に左右されたり、あまつさえ実態と乖離した組織政治の道具とかに使われてしまうため、安易にこの言葉を使うのはためらわれます。
とはいえそれだと話が進まないので、ここでは何かしらの拠り所を基に書いていきたいと思います。
拠り所として、ここでは、Google が発表している Paper をベースにしたいと思います。
How Google Measures and Manages Tech Debt
https://www.linkedin.com/pulse/how-google-measures-manages-tech-debt-abi-noda/
https://ieeexplore.ieee.org/document/10109339
Google ではどのように技術的負債を測定し管理しているか、というようなタイトルの文章です。
この中で、Google では以下10の項目を 「技術的負債」 と判断し、管理をしているようです。
| item | in english | note |
|---|---|---|
| Migration が必要なもの | Migration is needed or in progress | |
| ドキュメントの不足 | Documentation on project and application programming interfaces (APIs) | |
| テスト不足 | Testing | |
| コードの品質不足 | Code quality | |
| デッドコード | Dead and/or abandoned code | |
| デグレを起こしているコード | Code degradation | |
| 専門家不足 | Team lacks necessary expertise | |
| 依存関係の崩壊 | Dependencies | |
| 二重メンテナンスが必要なコード | Migration was poorly executed or abandoned | Migration の失敗や、作りかけのコードなどが残っている状況を指す |
| リリースプロセス | Release process |
論文から類推される実際の Google での取り組みとしては、これらの技術的負債について 117のメトリクス を定義し、もしくは定期的なサーベイにより定性的にフィードバックをもらった上で、組織が以下の4段階の Maturity Model (能力熟成度モデル) のうちどの段階にいるかを判断しているようです。
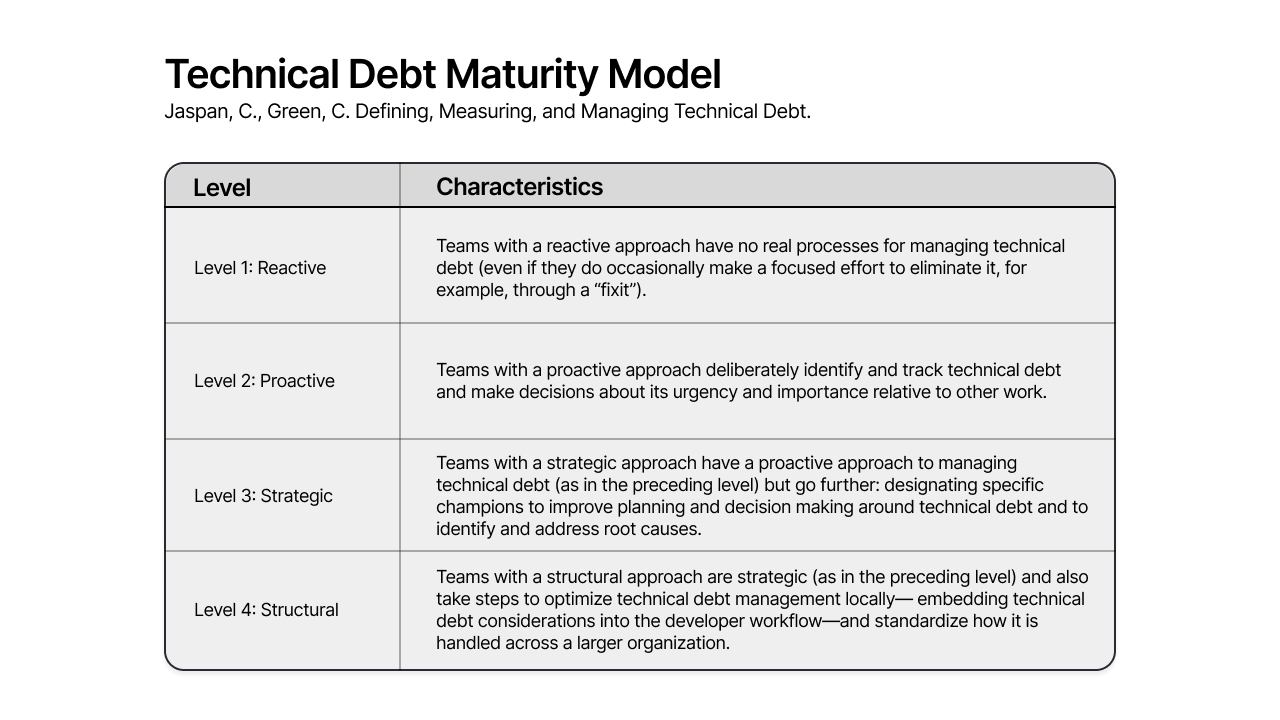
(https://www.linkedin.com/pulse/how-google-measures-manages-tech-debt-abi-noda/ より引用)
具体的にどのようなメトリクスを用いているかについては、私の調査不足もあってか情報にたどり着けませんでした。
いずれにせよ、定量的・定性的であるか関わらず、指標を定め、何かしらの形でメトリクスを収集し、それを基に「技術的負債」について判断をしている、ということが伺えます。
SRE チームとしての技術的負債への取り組み
SREチームにおける取り組みに話を戻します。
Google がやっていることをすべて踏襲することは情報不足もあるし、今いる組織の成熟度の差もあるため難しいと判断し、Maturity Model を構築するというアプローチは現在は取っていません。
そのうえで、上記内容を咀嚼した上で、以下についてフォーカスして考えました。
-
上記リストの中で、現状フォーカスして取り組むべき技術的負債は何か
- 取り組むべき対象がある場合は、どのように対応を行っていくか
- 上記の10個の中に含まれない課題で、フォーカスして取り組むべき技術的負債は何か
- それらは測定可能か。測定可能だとした場合、どのようなメトリクスを定義すべきか
端的に言うと、 「技術的負債についても Observability が大事だ」 ということが、ここまでの結論になります。
技術的負債のみならず品質全般について、測定可能な状況にし、現状がどうなっていて、どのような施策をすると何が改善されるかを明らかにすることが、こういった施策を進める上で何よりも大事な観点である、と考えています。
具体的な施策の流れ
「具体的」と書いてはいますが、社内の状況を詳らかに書くことにも問題があるため、ここからは施策のアウトラインについて記載をしていきます。
RACIチャートの定義
まず、組織として品質改善に向けてどのような Role and Responsibility で動くかについて、 RACIチャートを用いて整理しました。
| team | 機能要件 | 非機能要件 | 技術的負債 | |
|---|---|---|---|---|
| 各開発チーム | R | C | C | |
| SREチーム | - | R | R | |
| CTO室 | - | - | R (一部) | |
| QAチーム | C | - | - | 機能要件の品質担保の協力者。実際はもっと踏み込んだ動きも多い |
なお上記は記事執筆時の状況のスナップショットで、この役割分担は流動的に変化していくことになると思います。
たとえば、開発プロセスの成熟度が高まった暁には、非機能要件・技術的負債についても各開発チームがかなりの部分の Responsibility を担当するのが望ましいのでは、とも考えられます。
基本原則の定義
その上で、直近の行動原則についても整理しました。
- 品質を定義するメトリクスとして、 定量的な指標 を定義する
- その指標を定期的に確認できるよう、 観測可能 な形にする
- その指標が低下して来た場合、改善を開発チームに依頼する、もしくは SRE チームで対応する。
- 必要であれば指標を改善するための施策についても SRE チームが立案し、開発チームと共同して実施する
品質改善タスクの注力タスクを選定
そして、上述の「技術的負債」のリストに、組織固有の課題を加えたいくつかの課題候補の中から、 「まず組織で取り組むべき課題」 について整理をしました。
ここでは具体的にピックアップした内容は割愛しますが、数個の課題について解消すべき点が多いと判断し、ピックアップしました。
メトリクスの定義
それぞれの技術的負債について、現在の状況を把握するためのメトリクスを定義します。
以下は、一例として抜粋したものになります。
例: テスト不足
| metrics | purpose | note |
|---|---|---|
| code coverage | テストの網羅率の計測 | CodeClimate などの SaaS と連携して取得・可視化 |
| テスト数 | 単純なテストファイルの数の計測 | GitHub Actions で statistics なメトリクスとして定期的に取得 |
| テスト実行時間 | 品質とは直結しないが Developer Experience に関わる事項なので取得 | GitHub Actions で取得 |
例: コードの品質不足
| metrics | purpose | note |
|---|---|---|
| code smells | コードの複雑さなど様々な指標で、バグを生み出しやすいコードを特定する | CodeClimate などの SaaS と連携して取得・可視化 |
| dead code数 | 使われていないと思われる記述の特定 | Phan の dead-code-detection などを使用 |
メトリクスの測定
定義したメトリクスを取得します。
取得した結果は、 CodeClimate などの SaaS 上で管理できているものについてはそちらに移譲します。
独自で取得するものについては Datadog などとの連携を考えています。
(現状、 CodeClimate でかなり充足できてしまっているので、このような書き方になっています)
課題の改善
測定したメトリクスを基に、改善施策を検討し、現場に適応していきます。
たとえばテストの Coverage が低い、ということが明らかになったとしたら、テストカバレッジを向上させるための施策を検討し、実施していく、といったことになります。
現状では、上記のような流れを整理し、一部施策について実行をしている、というところまででとどまっており、具体的ないくつかの施策実施の結果どれだけ品質が改善したか、もしくはしなかったか、についてはまとめられるところまでたどり着いていません。
その辺の具体的成果については、また改めて何かしらの形で共有する場を作ることができれば良いな、と考えています。
まとめにかえて
今回はさだまさしについて書く余力がありませんでしたが、2023年のさだまさしはデビュー50周年を迎え、周年を祝うコンサートも開催されるなど、ファンとしてもとても大事な節目の年になりました。
「ものづくり」の世界はおしなべて終わりのない孤独な旅路になりますが、それでも継続すること、ただ続けるだけでなく高いレベルでモチベーションを保ちながら継続することが大事だ、ということを、さだまさしから教わる1年となりました。
皆さんにとっても、この2023年がとても有意義な1年であったことを祈念し、この記事を締めたいと思います。