初めに
ここでは、CIFAR-100で、類似画像検索をやってみる。
やり方としては、あらかじめ被検索画像(参照画像)を読み込み、512次元のベクトルに変換しておく(これをembeddingと言うらしい)
類似画像検索を行う際は、検索画像を同様に512次元の特徴量ベクトルに変換し、上記のベクトルとのコサイン距離を計算して、一番近いものを類似画像として抽出。
ということをやる(下図)

事前準備
DatasetとDatamoduleを以下のように定義
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import timm
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader, random_split
from torchvision import datasets, transforms
from pytorch_metric_learning import distances, losses, miners, reducers, testers
from pytorch_metric_learning.utils.accuracy_calculator import AccuracyCalculator
import faiss
import pytorch_lightning as pl
class ImgDataset(Dataset):
def __init__( self , train_img , transform=None):
self.transform = transform
self.train_img = train_img
self.len = len(self.train_img)
def __len__(self):
return self.len
def __getitem__(self,index):
xy = self.train_img[index]
y = xy[1]
X = xy[0]
if self.transform:
X = self.transform(X)
return y, X
class LitDataModule(pl.LightningDataModule):
def __init__(self , base_transform ):
super().__init__()
self.transform_train = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32, padding=4),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.5)]
+ base_transform.transforms
+ [transforms.RandomErasing(), transforms.RandomErasing()])
self.transform_test = base_transform
self.batch_size = 96
def prepare_data(self) -> None:
print("prepare data")
data_path = "dataset"
train_img = datasets.CIFAR100(data_path, train=True, download=True)
test_img = datasets.CIFAR100(data_path, train=False, download=True)
self.ds = ImgDataset( train_img , transform=self.transform_train )
self.ds_test = ImgDataset( test_img , transform=self.transform_test )
self.train_size = int( len(self.ds) * 0.8 )
self.valid_size = len(self.ds) - self.train_size
self.ds_train , self.ds_valid = random_split( self.ds , [self.train_size,self.valid_size])
def setup(self, stage = None) -> None:
print('setup')
return super().setup(stage)
def train_dataloader(self) -> DataLoader:
return DataLoader(
self.ds_train,
batch_size= self.batch_size,
shuffle=True,
num_workers=8
)
def val_dataloader(self) -> DataLoader:
return DataLoader(
self.ds_valid,
batch_size=self.batch_size,
shuffle=False,
num_workers=8
)
学習の実行
512次元の特徴量ベクトルにする際に使うモデルは、同じクラスの画像が特徴量空間の近くに配置されるように学習を進めることがポイントになるが、ここでは、pytorch_metric_learningで実装されているArcFaceLossを使う。
具体的に、やることは、学習ステップで使うloss関数を変更するだけ。
一点気を付けるところとしては、loss関数自体も学習パラメータを持っているのでloss関数を学習させるためのoptimizerも用意しなくてはならない点。(モデル用のoptimizerと合わせて2つのoptimizerを準備する)
今回使っているpytorch-lightningでは、デフォルトでは自動的にoptimizer.step()が実行されるが、それだと都合が悪いのでautomatic_optimizationをFalseにして、手動でoptimizer.step()を呼び出している。
class LitModule( pl.LightningModule):
def __init__(self, model):
super().__init__()
# 自動最適化をOffにしておく
# (loss関数自体も最適化するので)
self.automatic_optimization = False
self.model = model
self.criterion = nn.CrossEntropyLoss()
# このloss関数を使うことで、特徴量空間の近い場所に寄せることができるようになる
self.loss_func = losses.ArcFaceLoss(num_classes=100, embedding_size=512, margin=28.6, scale=64).to('cuda')
self.accuracy_calculator = AccuracyCalculator(include=("precision_at_1",), k=1)
def forward(self,X):
return self.model(X)
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.model.parameters(), lr=1e-3)
loss_optimizer = torch.optim.Adam(self.loss_func.parameters(), lr=1e-4)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer,T_max=200)
return [optimizer,loss_optimizer],[scheduler]
def training_step(self, batch, batch_idx) :
y,X = batch
embeddings = self.model(X)
opt, loss_opt = self.optimizers()
opt.zero_grad()
loss_opt.zero_grad()
loss = self.loss_func( embeddings, y)
self.log("train_loss",loss)
self.manual_backward(loss)
opt.step()
loss_opt.step() # loss関数を最適化するためのステップを追加
return loss
def validation_step(self, batch, batch_idx):
y,X = batch
embeddings = self.model(X)
loss = self.loss_func( embeddings, y)
self.log("valid_loss",loss)
ここまでで準備ができたので、以下のコードで学習させる
modelname = "efficientnet_b3"
net = timm.create_model(modelname, pretrained=True, num_classes=512)
conf = timm.data.resolve_data_config({}, model=modelname)
conf['input_size'] = (3,96,96)
conf['crop_pct'] = 1.0
base_transform = timm.data.transforms_factory.create_transform( **conf )
dm = LitDataModule(base_transform)
litmodel = LitModule(net)
trainer = pl.Trainer( max_epochs=100, gpus=1)
trainer.fit( litmodel , dm )
prepare data
Files already downloaded and verified
Files already downloaded and verified
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params
-----------------------------------------------
0 | model | EfficientNet | 11.5 M
1 | criterion | CrossEntropyLoss | 0
2 | loss_func | ArcFaceLoss | 51.2 K
-----------------------------------------------
11.5 M Trainable params
0 Non-trainable params
11.5 M Total params
46.138 Total estimated model params size (MB)
:
特徴量の計算
類似画像検索をするために、出来上がったモデルを使って元画像を512次元の特徴ベクトルに変換してlist格納しておく(これをembeddingと呼ぶ)。
net = net.to('cuda')
net = net.eval()
data_path = "dataset"
train_dataset = datasets.CIFAR100(data_path, train=True, download=True)
conf = timm.data.resolve_data_config({}, model=modelname)
conf['input_size'] = (3,96,96)
conf['crop_pct'] = 1.0
base_transform = timm.data.transforms_factory.create_transform( **conf )
ds = ImgDataset( train_dataset, transform=base_transform)
dl = DataLoader(
ds,
batch_size=128,
shuffle=False,
num_workers=8
)
embedings = []
labels = []
for y,x in tqdm(dl):
with torch.no_grad():
emb = net( x.to('cuda') )
lbl = y.cpu()
embedings.extend(emb.tolist())
labels.extend(lbl.tolist())
出来上がったembeddingを、次元削減して可視化すると以下のようになる。
図では、一つ一つの点が元画像を表しており、同じクラスは同じ色になるようになっている。
512次元の特徴量空間で、学習が進むにつれて似た画像が近い位置に配置されるようになっていることがわかる。
tSNE_met = TSNE(n_components=2,random_state=0).fit_transform(embedings)
plt.scatter( tSNE_met[:,0], tSNE_met[:,1], c=labels, s=10)
plt.colorbar()
5エポック学習させた状態

30エポック学習させた状態
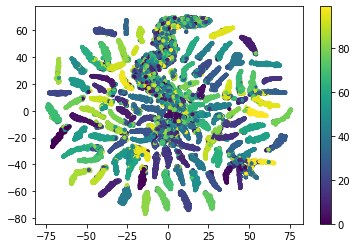
100エポック学習させた状態

類似画像の検索
まず、学習済みモデルを使って、検索する画像の特徴量(512次元)を生成する
idx = 15
x = base_transform(test_dataset[idx][0]).unsqueeze(0)
y = test_dataset[idx][1]
print(y ,test_dataset.classes[y], x.shape)
with torch.no_grad():
pred = net(x.to('cuda')).cpu().numpy()
print(pred.shape)
plt.imshow( test_dataset[idx][0] )
43 lion torch.Size([1, 3, 96, 96])
(1, 512)

この特徴量と、embeddingとの距離を計算
from scipy import spatial
dis = spatial.distance.cdist(pred, embedings, 'cosine')[0]
df_tmp = pd.DataFrame( {"lbl":labels ,"dis":dis})
df_tmp.sort_values(by="dis",ascending=True ).head(9)
lbl dis
14872 43 0.012260
47731 43 0.012261
41299 43 0.012680
48063 43 0.013935
21160 43 0.013977
27149 43 0.014099
6586 43 0.014405
30131 43 0.014430
42814 43 0.014616
label=43(lion)の画像が上位に来ていることがわかる。
実際に表示してみると以下の通り
fig,axs = plt.subplots(3,3,figsize=(8,8))
top_idx = df_tmp.sort_values(by="dis",ascending=True ).head(9).index.to_list()
for i ,idx in enumerate(top_idx):
print( train_dataset[idx] )
axs[int(i/3)][i%3].imshow( train_dataset[idx][0] )
