Decision Tree
この記事では、Decision Treeの最も基本的なアルゴリズムの一つである「CART: Classification And Regression Tree」を紹介します。
構成
decision_tree以下に格納しています。
- mod_base_tree.f90
- 実装中の決定木アルゴリズムに共通で使えそうな部分を切り出したもの
- mod_node.f90
- ノードのクラスを記述
- mod_splitter.f90
- ノード分割の関数を格納。
- mod_woodworking_tools.f90
- その他のいろいろな操作を格納
- mod_base_tree.f90とうまく切り分けられておらず、関数を探すのが面倒になってしまっているので、直したいと思います
- その他
- 各アルゴリズムの実装です。各アルゴリズムの肝はmod_splitter.f90のほうに入っています
Decision Treeとは
Decision Tree(以下DT)は機械学習の最も基本的な手法として様々な場所で紹介されています。DTは特定のアルゴリズムを指す言葉ではなく、大きな手法の括りを指す言葉です。アルゴリズム、つまりDT構築の具体的な手段は非常に多くの種類があります。
Awesome Decision Tree Research Papers
なぜこれほどまでにDTが利用されているかについては、以下のような理由があると思います。
- アルゴリズムが単純で分かりやすい(ものが多い)
- 比較的高速に動く
- 結果の解釈が容易
- スケールなどの前処理が必要ない
- 古いアルゴリズムのため、様々な言語で実装されている
Decision Treeの用語説明
DTで画像検索した際によく以下のような図が見つかると思います。
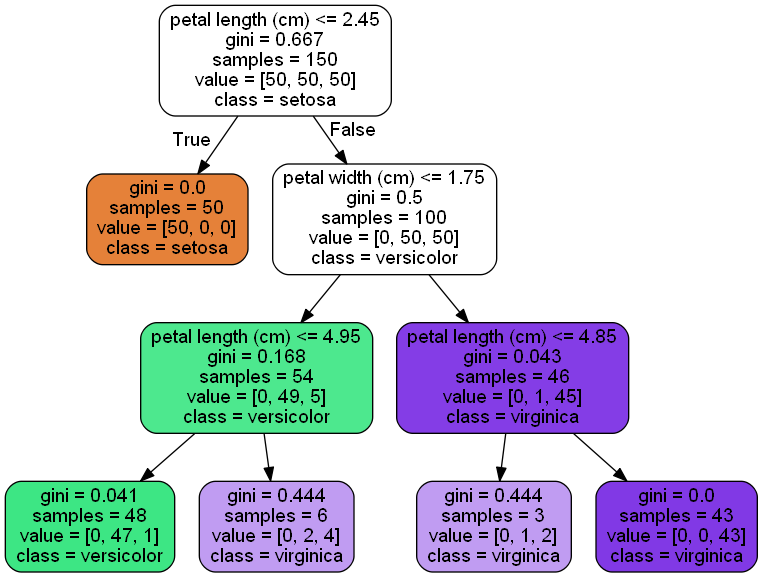
こちらを用いてこれから使う用語を説明したいと思います。
- ノード=四角
- Root Node(根ノード):最も上にあるノード
- Internal Node(内部ノード):矢印の出入りがあるノード
- Leaf Node / Terminal Node(葉ノード/終端ノード):最下部の矢印が入るのみのノード
- Parent Node(親ノード):Internal NodeとLeaf Nodeそれぞれの一つ上の階層にあるノード。Root Nodeは持たない
- Child Node / Daughter Node(子ノード/娘ノード):Root NodeとInternal Nodeのそれぞれの一つ下の階層にあるノード。Leaf Nodeは持たない
- Sibling Node(兄弟・姉妹ノード):Internal NodeとLeaf Nodeそれぞれの親ノードを同じくするノード。Root Nodeは持たない
- 分割条件 = <特徴量の名前> <= <閾値>
- ノードの1行目。どの特徴量を用いて、どの値で分割するかを記載。Trueのサンプルは左側へ、Falseのサンプルは右側へ流れる。
- Criterion=分割基準、不純度ともいう
- ノードの2行目。ノードを分割する際に用いる基準。分割は最も「良い」分割条件で行うが、その評価を行うためのもの。0に近いほど「良い」としており、Pure(分類の場合はノード中にクラスラベルが一つのみ、回帰の場合はすべてのサンプルの値が同じ)であれば0をとる。
- Information Gain
- 情報利得。ノードの分割前後での情報の差。より「良い」分割であるほど大きな値をとる。親ノードのCriterionが大きく、子ノードのCriterionが小さければより「良い」分割である(Pureでない状態から、分割でよりPureな状態にすることができた)。
- サンプル数
- 四角の3行目。ノード内に持つサンプルの数。自分の親ノード内のサンプルしか持たず、自分の兄弟のノードのサンプルは含まれない。自分+兄弟ノードのサンプル=親ノードのサンプルとなる(例外のアルゴリズムもある)。
- 出力
- 四角の5行目。
- 分類の場合は四角の4行目が、各クラスごとのサンプル数を表している。最も多いクラスがそのノードのクラスラベルとなる。同じ数のクラスが複数ある場合は実装によるが、最も小さいラベルが選ばれる(ランダムに選ばれるものがあってもよい)。
- 回帰の場合は四角の4行目が、そのノードに含まれるサンプルの平均。
- Depth=深さ
- 木の深さ。深いほど複雑なデータに対応できるが、同時に汎化性能が下がる。Depth=1の時、Decision Stumpと呼ぶ。
- 画像の最も上がRoot、最も下がLeafなので、Heightと呼ぶこともある(こちらの方が正しいのでは?)。
Decision Treeの構築方法
非常に大雑把にいうと、いくつもの分割条件($w_i$は重み、$a_i$は特徴量、$c$は分割の閾値、$F$は特徴量の数)
\sum_{i=1}^{F} w_i a_i \leq c
をCriterionの下で評価し、最も「良い」分割条件で分割、これを再帰的に繰り返していきます。そして、停止条件にあたった際には、それ以上の分割を停止します。
一般化のために、重みを用いて記述していますが、現在利用されているDTにアルゴリズムのほとんどは特徴量一つずつしか用いていません。一度に複数の特徴量を一斉に用いて分割条件を決めるものをOblique DT(ODT)、一つの特徴量のみを用いて分割条件を決めるものをAxis-Parallel DT(APDT)と呼びます。
\sum_{i=1}^{F} \delta_{ij} a_i = a_j \leq c
前者が用いられていない理由としては、
- そもそも分割条件の決定に非常に時間がかかる
- 決定木の良さであるはずの、解釈性がほぼ消えてしまう
- 時間がかかる割にそこまで精度が向上することが少ない(それならばなるべく早く、わかりやすい結果が欲しい)
などが考えられます。実際にXgboost、LightGBM、CatBoostなどではAPDTのほうが実装されています(LightGBMはLinearTreeというものも実装されているため厳密には違います)。後ほどの記事で一部ODTについても解説します(目についた簡単そうなものなので、代表的なものではありません)。
また、FortLearnerでは比較的簡単な2分割(binary split)のみ実装していますが、多分割(multi-way split)を行うものも存在します。ID3、C4.5などがそれにあたります。さらに、Categorical Featureについても実装を行っていませんので、ご注意ください。
Decision Treeの分割基準, Criterion
DTでは分割条件をCriterionを用いて評価します。これらは非常に多くの種類があります。分類用のCriteriについては、以前調べた際に非常に古い文献を見つけたのですが、その時点でも30ほどのCriteriaが存在しました(どなたかご存知でしょうか?)。しかしどういう経緯かはわかりませんが、よく用いられているものは
の2種類と思われます。
また、回帰では、
- MSE (Mean Squared Error)
- MAE (Mean Absolute Error)
が良く用いられます。後ほど詳細に解説しますが、MAEは計算量がMSEに比べ非常に大きくなるため(O(N^2) vs O(N))、大規模なデータでは使わないほうが良いものです(MSEでは5分ほどで完了した学習が、MAEでは一晩放置しても完了していませんでした)。
実際に最もよい分割点とは
- 親ノードの不純度を$C$(サンプル数$M$)
- 選択された分割点で分割した際に生まれる子ノード二つの不純度をそれぞれ $C_L$, $C_R$(サンプル数$M_L$、$M_R$)
とした際に、Information Gain $G$が最大になるものを指します。
G = C - \frac{M_L}{M} * C_L - \frac{M_R}{M} * C_R
Decision Treeの分割ノード選択基準
上記は各ノード内での分割基準の選択についてでした。分割可能な各ノードをスキャンし最もよい分割点を見つけたとして、どのノードにおいて分割=子ノードの作成、を実施すべきでしょうか?代表的なものとしては以下があります。ほかにご存じでしたらご教授ください。
- Depth-First
- Best-First
- Level-Wise
それぞれ簡単に見ていきます。
Decision Treeの分割ノード選択基準: Depth-First
深さ優先探索。木構造をもったアルゴリズムを利用したことのある方ならよくご存知だと思います。このノード選択では、根ノードを分割後左の子ノードへ移動し、さらにそのノードを分割後左の子ノードの分割を再帰的に繰り返していきます。停止条件に触れた際は、途中の分岐点まで戻り未探索のノードに対して同じ操作を繰り返します。再帰関数を使えば簡単に実装することができます。sklearnはデフォルトの設定ではこちらです。
Decision Treeの分割ノード選択基準: Best-First
最良優先探索。こちらは分割可能なノードをすべて分割した後、最も大きなInformation Gainを持つ内部ノードの子ノードを作成します。ほかの条件での実装もできます。FortLearnerではほかにもサンプル数が最も多いノード、分散が最も大きいノードなども試してみましたが、意味がありませんでした。一応残してあります。sklearnではmax_leaf_nodeをデフォルトのNoneから変更すれば、こちらを用います。LightGBMもこちらです。
Decision Treeの分割ノード選択基準: Level-Wise
上記二つと異なり、こちらは各Levelごと(Depthごと)に一斉に分割を行います。XgboostやCatBoostなどがそれにあたります。Xgboostは(もともとの)アルゴリズムの性質上、Levelwiseに実行しなければ処理時間が非常に遅くなるため、こちらを採用していると思われます。(こちらURLの計算量の部分をご覧ください。私も実際にもともとの実装(ノードごとに分割)からこちらの記事を参考に実装を修正するとDepthにもよりますが、数倍速くなりました。
ここまでが、決定木の基本的な内容の説明です。
CART: Classification And Regression Tree
それでは具体的なアルゴリズムの説明に入りたいと思います。CARTはRandomForestの開発者でもあるReo Breimanの提唱したアルゴリズムです。scikit-learnにおいてもこちらの実装が入っています。もともとの実装はFORTRANで 公開されています。
CARTのアルゴリズム
まず、CARTのアルゴリズムを簡単に説明した後、Python(ぽい)コードでの解説を行います。ここで説明するのは私が実装した際のものであり、一般的な実装ではありません。
表記を定義します。
- $D$ : 特徴量の次元数
- $N$ : 全サンプル数
- $M$ : ノード中のサンプル数。$M \le N$
- $I$ : ノードに含まれるサンプルのインデックスのリスト。$|I| \le N$
- $X$ : 独立変数。特徴量。$N$サンプルx$D$次元。全サンプルを保持
- $Y$ : 従属変数。1次元のみを考える
各ノードでは$X$のポインターを保持し、どのサンプルを持っているかはすべてサンプルのインデックス$I$で判定することとします。下記がアルゴリズムの概要です。
- 親ノードから$I$を受け取る(根ノードで受け取る$I$は全サンプルのインデックス)。
- 特徴量分のループを回す(インデックス$d$)
- インデックス$I$に従い、$X$と$Y$からd次元目のデータを抽出し、それぞれ$X'_d$と$Y'$とする
- $Y'$を$X'_d$に従いソートする
- サンプル数$|I|-1$分のループを回す
- 隣り合う$X'_d$の要素が異なる場合、その点を分割点の候補として評価
- 現在最もよい分割点の候補と比較、よりよい方を選択
- 最もよい分割点を得る
インデックスのみを保持する理由としては、
- インデックスを持たない場合
- 分割条件に従い、現在のノード$T$ のデータ $X_T$を二つの子ノード用に分割
- 各特徴量ごとに抽出しソート、最良の分割点を取得。特徴量分繰り返す
- インデックスを持つ場合
- 分割条件に従い、インデックスを二つの子ノード用に分割
- 各特徴量ごとにインデックスに従いデータを抽出しソート、最良の分割点を取得。特徴量分繰り返す
持たない場合は1で、持つ場合は2で配列への不連続なアクセスが発生するため、処理時間という観点ではどちらも場合も大差ないかと思います。
ただ、前者はメモリ効率の観点でよくないと思い採用していません。すべてのデータをTreeで保持するため、順次必要のないデータは削除していけばよいですが、
最大で入力データと同じだけの領域を追加で消費してしまいます。初めにこちらを実装した際に、そのままの状態でRandom Forestを実装し、OpenMPでTreeを並列に
学習したらPCがフリーズしてしまいました。後者もインデックスは訓練完了した段階で必要がなくなるので、削除しています。
CARTの計算量
CARTの各ノード中での計算量はどのように概算されるでしょうか?特徴量分のループを上記アルゴリズムでは、
- ソート: $N \log N$
- 全分割点の評価: $N^2$ ?
汎用的な実装を求めるのであればおそらくIntroSortなどを用いた実装をするはずですので、理論的な性能はよく知られている$N \log N$で決められます。では全分割点の評価はどうでしょうか?
分割点の評価について
初めて実装した時にはここで躓いてしまい、3~4か月ほど仕事が終わった後に自宅で「decision tree algorithm」で検索をして、何か明示的に書いていない高速化のアルゴリズムが隠されているのではないかともやもやしていました。ここは、(分割基準にもよりますが)$N$で評価することができます。gini 係数を参考に見てみましょう。
gini係数は以下で計算されます。$p_i$は$i$番目のクラスの割合です。上記のInformation Gainの$C$の部分を下記$g$で置き換えれば計算ができます。
g(p) = 1 - \sum_i p_i^2, \\\\\\ \sum_i p_i = 1.
まず、親ノードの計算です。根ノード以外ではこれはさらに自分の親ノードから与えられるものです。そのため計算の必要がありません。
次に子ノード二つの計算です。割合 $p$ の計算には、各クラスのサンプル数(とその和)が必要です。各分割点でこの割合を計算していては、計算量が最悪の場合$N^2$になってしまいます(クラスごとのカウントを全サンプルNに対して実行するとO(N)、それをN-1回実行する。実際はデータのユニークな値の数はサンプル数に比べて少ないのが一般的ですので、計算量はO(N x ユニークな値の数)となります)。どのように改善すればよいでしょうか?
$S$は親ノード、$S_L$は左側の子ノード、$S_R$は右側の子ノード、それぞれの各クラスのサンプルの合計を集計した配列としたとき以下のような手順で解くことができます(動的計画法の1種?)。
- $S$は親ノードから取得(根ノードの場合は前処理などで計算)、$S_L$はすべての要素を0で初期化
- サンプル数$M-1$分のループを回す
- 隣り合う要素が異なる分割点まで、$S_L$にインクリメントにクラスごとにカウントする
- $S_R = S - S_L$で計算。
- 分割点を評価する
このようにすることで前回の分割点の情報を利用して計算量$N$で各特徴量のすべての分割点を評価することができます。また、MSEの場合はこちらのリンク(https://qiita.com/shu_ohm1/items/8772328bab41e0133cd9 )をご覧ください。MAEではこのような変換ができず、遅くなってしまうことがわかるはずです。
初めて実装した際には、
- ユニーク値を取得
- ユニーク値の以上以下で配列を分割し、分割したそれぞれでクラス数を算出
としてしまっていました。これでは最悪計算量がN^2になります。
# C=クラス数
# M=現在のノードのサンプル数
# class_counter_p=親ノードのクラスごとのカウント
best_gain = -sys.maxsize # 最もよいInformationGain。システム的に最も小さい値で初期化
y = np.zeros(M)
for i, index in enumerate(I):
y[i] = Y[index]
for feature_id in range(len(D)):
class_counter_l = np.zeros(C)
x_d = np.zeros(M)
for i, index in enumerate(I):
x_d[i] = X[index, feature_id]
index_x_d_sort = np.argsort(x_d)
x_d_sorted = x_d[index_x_d_sort]
y_sorted = y[index_x_d_sort]
for j in range(len(I)-1):
label = y_sorted[j]
class_counter_l[label] += y_sorted[j]
if x_d_sorted[j] != x_d_sorted[j+1]:
class_counter_r = class_counter_p - class_counter_l
M_L = np.sum(class_counter_l)
M_R = np.sum(class_counter_r)
gain = gini(class_counter_p) - gini(class_counter_l) * M_L/M - gini(class_counter_r) * M_R/M
if best_gain < gain:
best_gain = gain
best_threshold = (x_d_sorted[j] + x_d_sorted[j+1]) / 2
以上です。
次の記事ではExtraTreeについての解説を行います。