Oracle Cloud Infrastructure (OCI) には、サーバーのエンド・ポイントをアクティブに監視するヘルス・チェック (OCI Health Check) という機能があります。この機能、設定がとても簡単で、トラフィック管理機能(OCI Traffic Management)と連携してエンドポイントを別サーバーにフェイルオーバーしてくれる機能もあり、重宝します。
また、このヘルス・チェック機能、モニタリング機能(OCI Monitoring)と通知機能(OCI Notification)を経由してアラートを飛ばすことができる、と色々な資料に書かれています。これができると、Webサーバーがちゃんと稼働していることを監視する用途に最適なのですが、マニュアルにもモニタリング・メトリックの記述がなく、どう設定するといいかよくわからない状態です。
手順は慣れてしまえば大したことないのですが、設定できると便利な機能なので、人柱としてこのブログを書こうと思った次第です。
やりたいこと
OCI上の仮想マシンに設置したWebサーバーを、「大げさな監視の仕組みとかを構築することなくクラウドの機能で簡単に」 監視して、異常があれば通知を受け取りたい!!
実現方針
OCIヘルス・チェック機能を使って監視し監視し、HTTPのステータスコードに異常がある場合、メールで通知を受け取ります。
色々な監視方法があると思いますが、今回はシンプルに、HTTPステータスコードを監視して、200以外のコードを返ってきたものが一定割合を超えた場合に通知を行うように設定してみます。
事前作業
既にWebサーバーが構築が終わって、インターネットからアクセス可能な状態から始めます。
今回は、OCI上に単純に1台のWebサーバーが立ち上がっている状態ですが、ロード・バランサーを経由している状態でもOKです。
作業ステップ
1. ヘルス・チェック機能でエンドポイントの監視を設定する
OCIコンソールからヘルス・チェック機能にアクセスします。ヘルス・チェックはメニューの [ソリューションおよびプラットフォーム] セクションの [モニタリング] → [ヘルス・チェック] から開けます。ヘルス・チェックはグローバルなリソースなのですが、最初の監視を設定する際にはWebサイトが存在するリージョンで設定する必要があるので、リージョン・セレクターで適切なリージョンが設定されていることを確認します。今回はJapan East (Tokyo)で作成します。
[ヘルス・チェックの作成] ボタンを押して、立ち上がったダイアログで以下の情報を入力し、ヘルスチェックを作成します。
- ヘルス・チェック名 : 任意
- コンパートメント : ヘルス・チェックを作成したいコンパートメントを選択
- ターゲット : 作成済みのWebサーバーを選択します。「コンピュート・インスタンス」という欄にある適切なグローバルIPアドレスのものを選択してください
- バンテージ・ポイント : 外部から監視するポイントを設定します。OCI以外のクラウド(AWS、Azure、GCP)の複数のリージョンを選べます。今回は東京に近そうな AWS Asia Pacific NE 2 と Azure East Asia の2箇所を選択します。
- リクエスト・タイプ : HTTP または Ping から選択、今回はWebサーバーの監視なのでHTTPを選択します
- プロトコル : HTTP または HTTPS から選択、今回はHTTPを選択します。SSL対応のサイトであればHTTPSを選択してください。リクエスト・タイプにPingを設定した場合はICMP/TCPから選択できます。
- ポート : チェックに利用するポートを設定します。今回は80番にします。
- パス : チェックに利用するパスを設定します。今回はトップページを利用するので /index.html にします。
- ヘッダー名とヘッダー値 : リクエスト・ヘッダーを追加する場合は入力します。今回は空欄。
- メソッド : チェックに利用するHTTPメソッドを HEAD / GETから選択します。今回ステータスコードしか見ませんので、負荷の軽いHEADメソッドにします。
- タイムアウト : チェックが失敗と判定されるまでのタイムアウト時間を設定します。10秒、20秒、30秒と選べるのでお好きなものを。今回は10秒でいきます。
- 間隔 : チェックの間隔を設定します。10秒〜15分までのお好きな値を選択してください。今回は10秒にします。
ヘルスチェックが作成されると、すぐに監視が始まります。今回は2箇所のバンテージ・ポイントから10秒ごとにチェックを行う設定をしましたので、10秒ごとに画面がリフレッシュされ、2レコードずつヘルス・チェック履歴が追加されます。
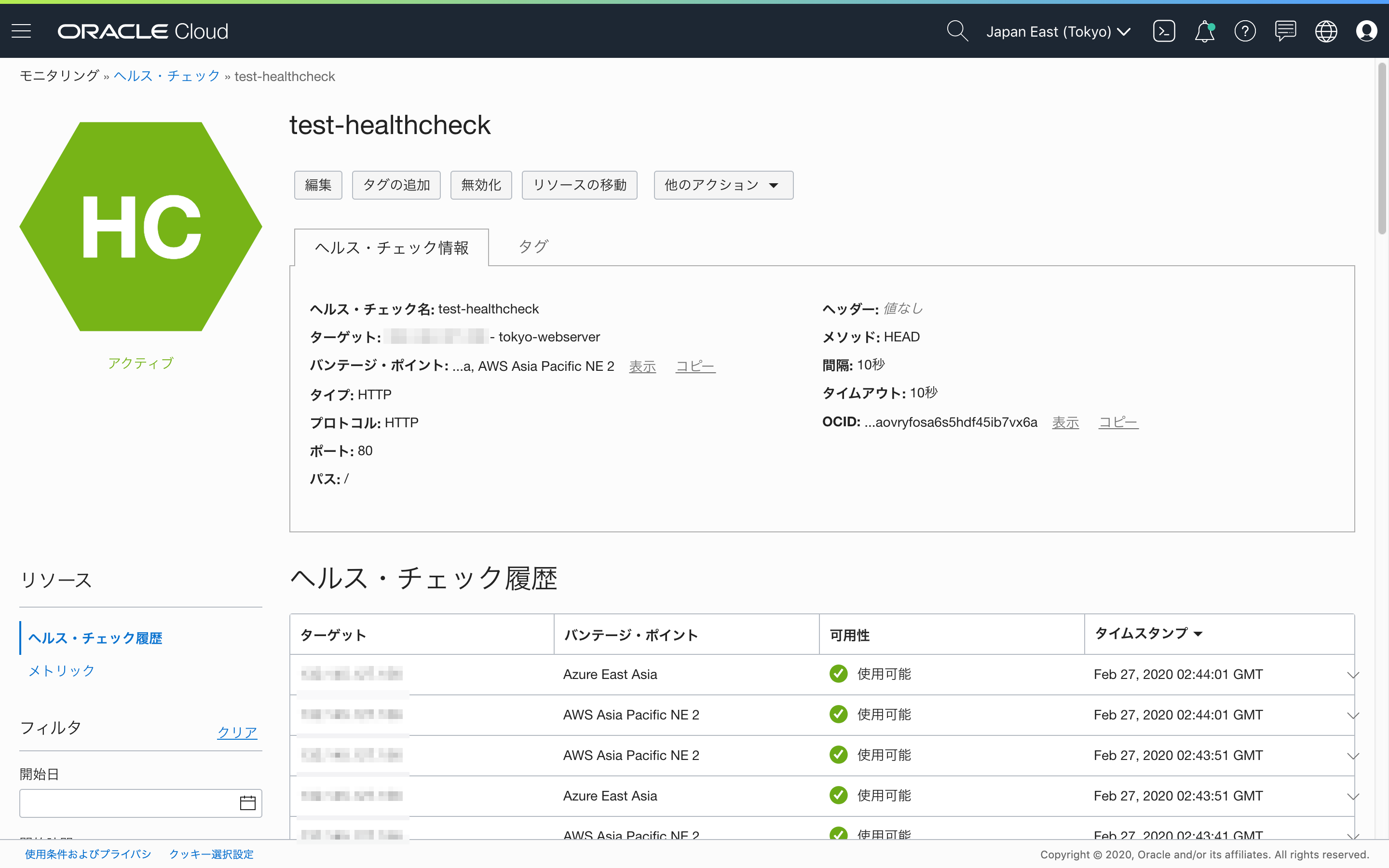
可用性の欄が使用可能になっていることを確認してください。そうでない場合は、Webサーバーが正しく動作していない、またはインターネットからWebサーバーに到達できていないことを示していますので、その問題をまず解消してください。
2. ヘルス・チェックのメトリックに対する適切な問い合わせ(MQL)を作成する
次に、ヘルス・チェックが定期的に出力するモニタリング・メトリックから、HTTPのステータスコードの値を取得するクエリ文(MQL : Monitoring Query Language)を作成します。
OCIコンソール上で、先ほど作成したヘルス・チェック画面の左下にあるリソースから、 メトリック を選択します。そうすると右側にこのヘルス・チェックが出力しているモニタリング・メトリックが一覧で表示されます。
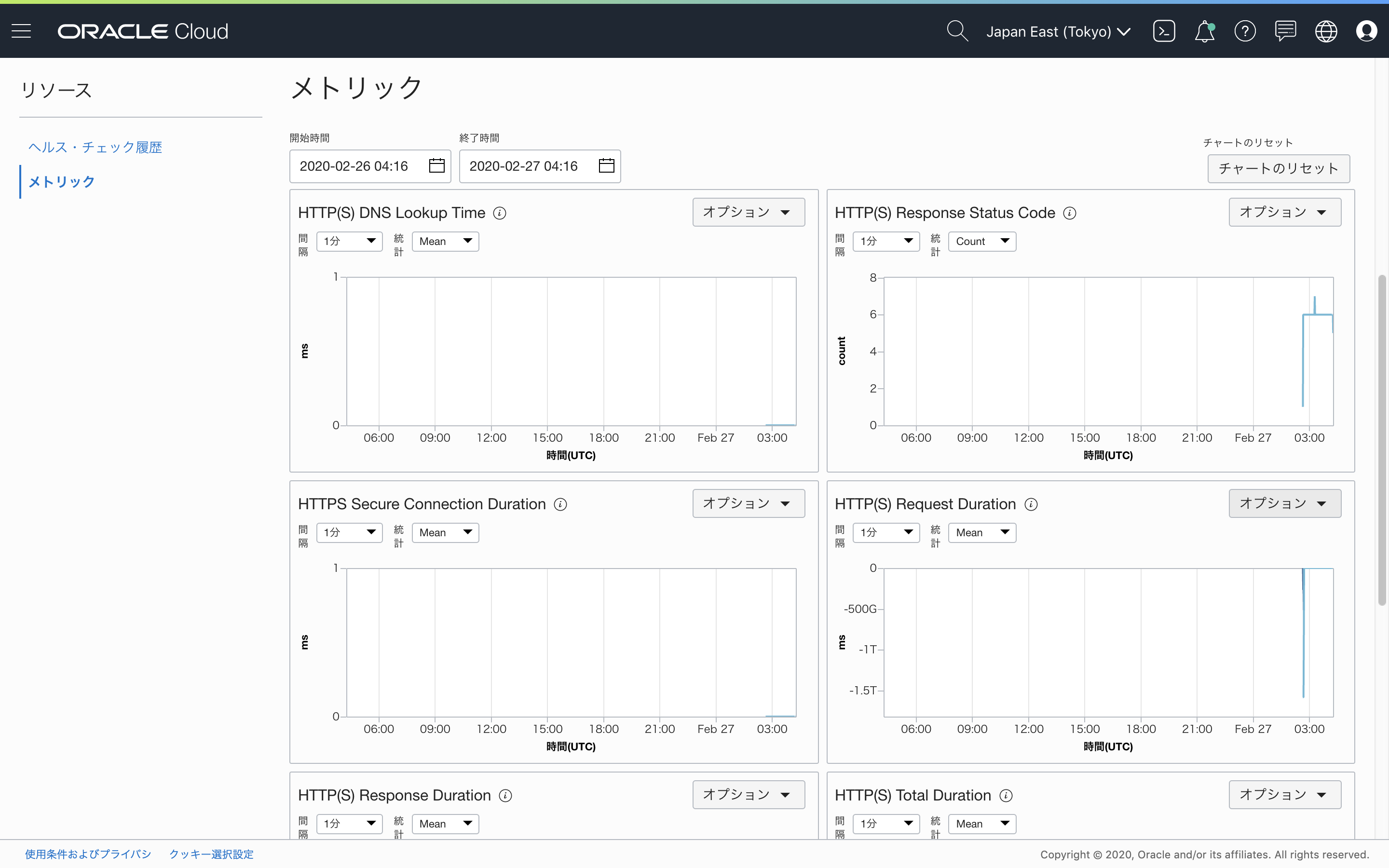
様々なメトリックがあり、それぞれ監視に使うことができますが、今回はHTTPのステータスコードの値を監視したいので、右上にある HTTP(S) Response Status Code を使います。
HTTP(S) Response Status Code の枠の右上にある オプション▼ ボタンを押し、メトリック・エクスプローラで問い合わせを表示 を選択します。

メトリックへの問い合わせの詳細を編集できる画面に遷移します。
初期状態では、HTTPのステータスコードを問い合わせた件数を5分間ごとに集計した値が表示されています。
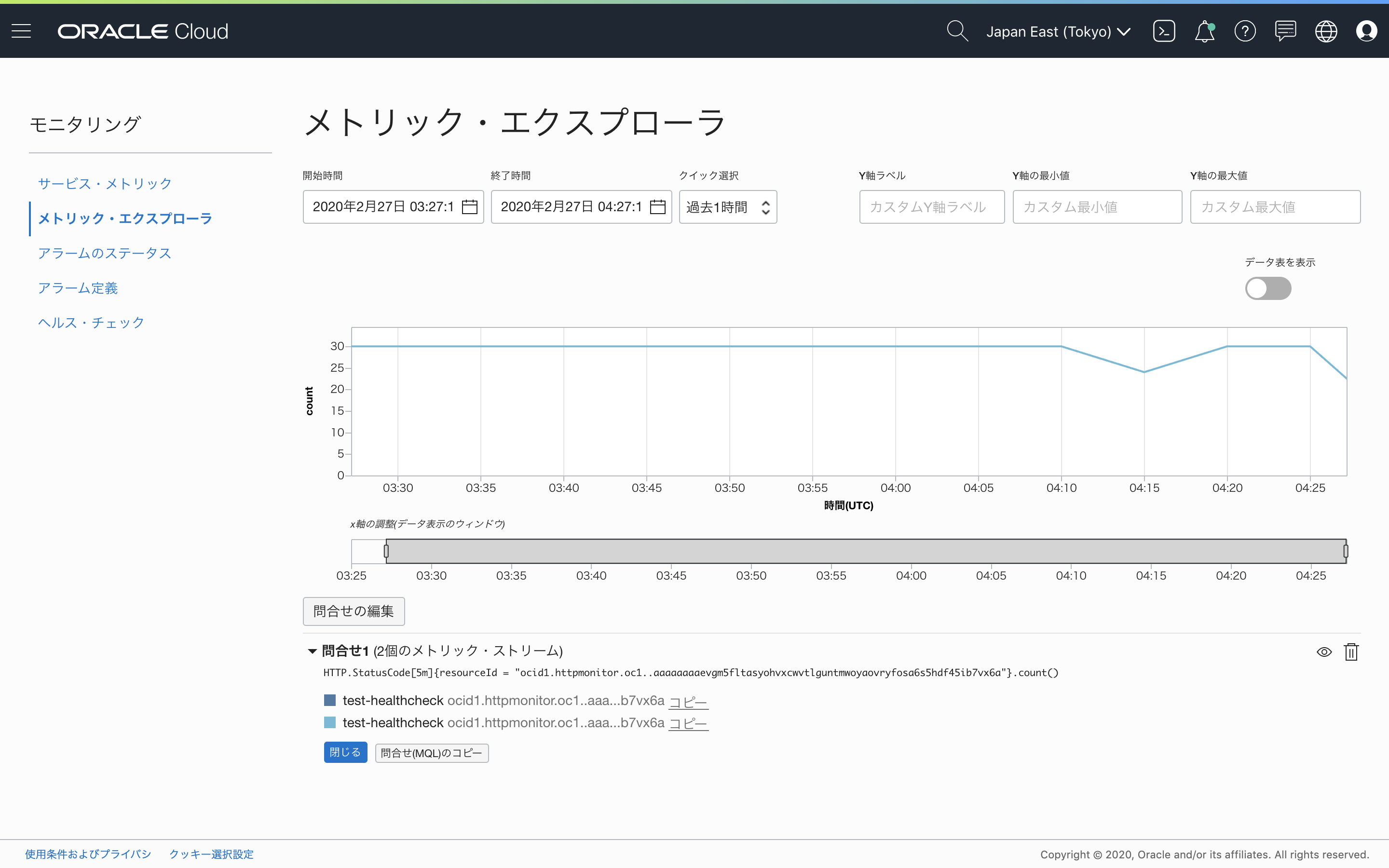
問い合わせの編集 ボタンを押して問い合わせエディタを開きます。
今回は、10秒毎に監視しているHTTPステータスについて、200以外のコードを返ってきたものが5分間あたり5% (つまり30回中2回以上)を超えた場合に通知を行うように設定してみます。
問い合わせが、5分間の間のHTTPのステータスコードの95パーセンタイル値になるよう、以下のように設定します。
- メトリック・ネームスペース : oci_healthchecks
- メトリック名 : HTTP.StatusCode
- 間隔 : 5m
- 統計 : P95
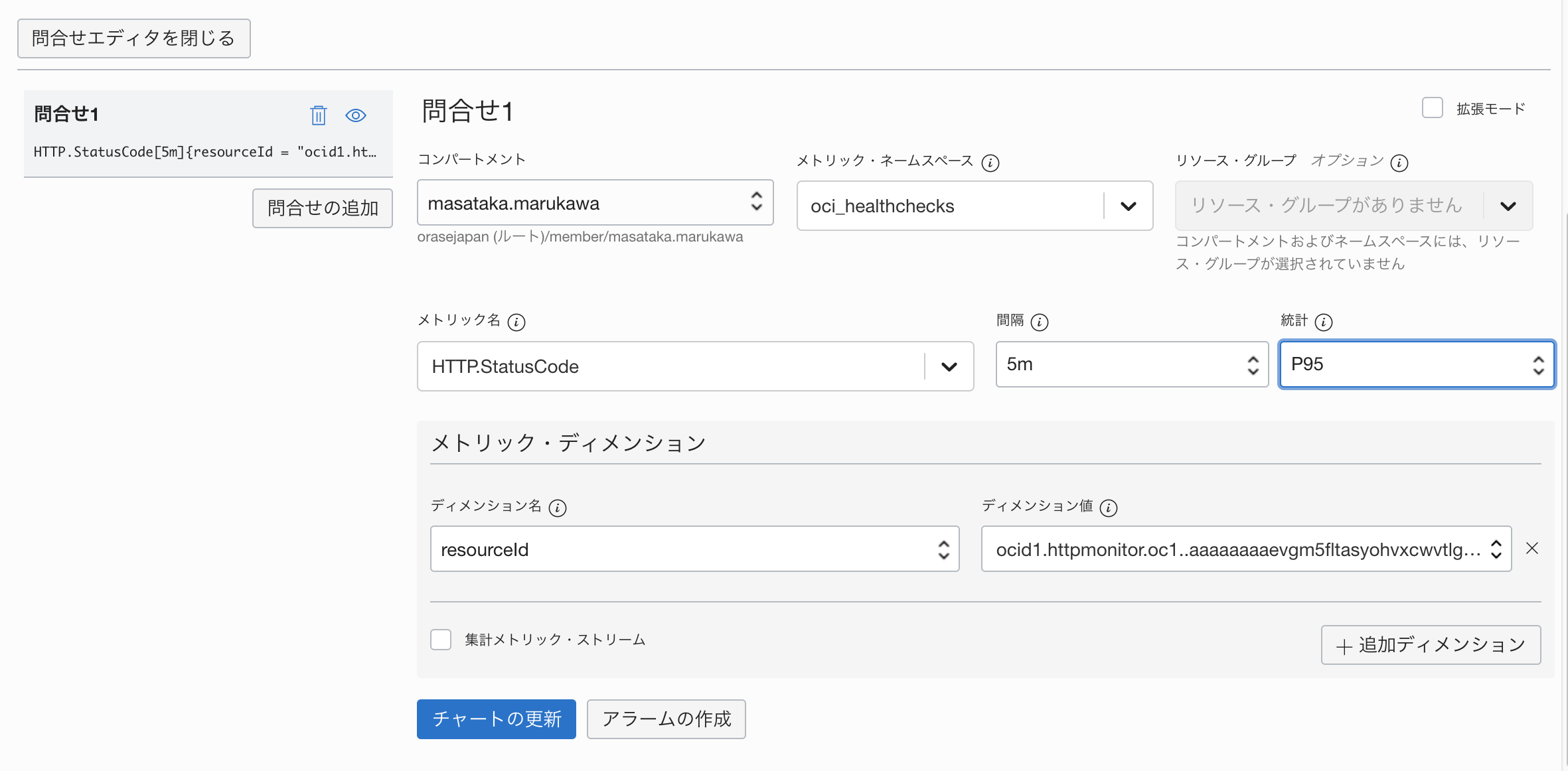
または、 時々メトリック・ネームスペースの値リストに oci_healthchecks が正しく現れない 場合があります。(ひょっとしたら何かのバグかもしれませんが未解明) そのような場合は、右上の □拡張モード というチェックボックスをチェックしたうえで、問い合わせエディタを直接返信して、以下のような文字列(MQL)になるように設定してください。
HTTP.StatusCode[5m]{resourceId = "ocid1.httpmonitor.oc1..xxxxxxxx"}.percentile(.95)
ocid1.httpmonitor.oci1..xxxxxxx の箇所は、作成したヘルスチェックのOCIDです。環境によって違います。通常は編集不要です。
チャートの更新 ボタンを押すと、新しい問い合わせでチャートが更新されます。
200の値が継続的に帰ってきているようであれば、OKです。

3. 通知アラームを作成する
作成した問い合わせをベースにして、異常を拾って管理者にメール通知するアラームを作成します。
** アラームの作成** ボタンを押します。立ち上がった画面で、以下の情報を入力します。
- アラーム名 : 任意
- アラームの重大度 : 任意 (クリティカル/エラー/警告/情報 から選択)
- アラームの本体 : アラームのメッセージ本文、好きな文言をどうぞ。

メトリックの説明 および メトリック・ディメンション のフィールドは、デフォルトのままでOKです。
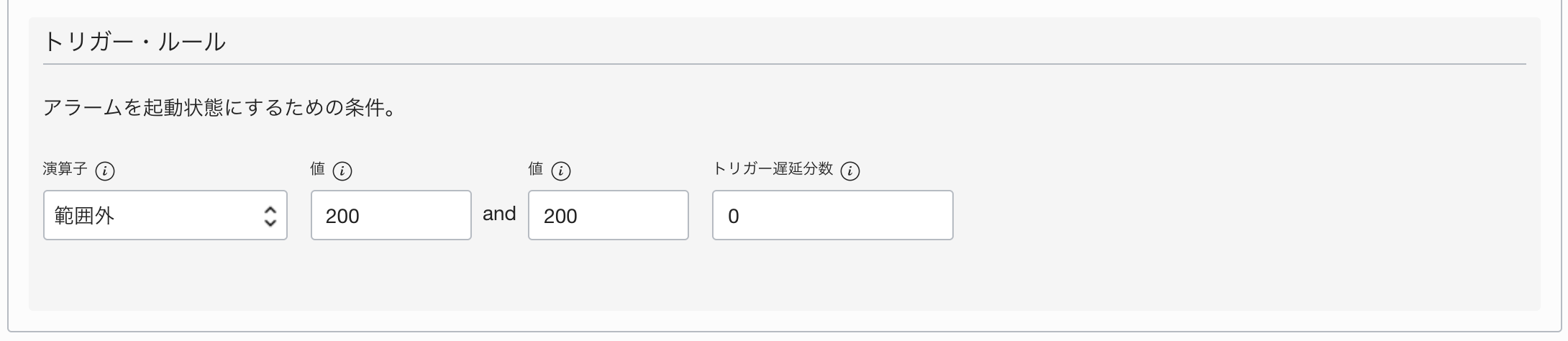
その下の トリガー・ルール に以下の情報を入力します。今回は、ステータスコード(の95パーセンタイル値) が200以外の場合をルールに設定します。
- 演算子 : 範囲外
- 値 : 200 and 200
- トリガー遅延分数 : 1
Notifications フィールドで、通知先の設定を作成します。
トピックの作成 リンクをクリックし、開いた Create a new topic and subscription* フィールドに以下を入力します。
- トピック名 / トピックの説明 : 任意
- SUBSCRIPTION PROTOCOL : 任意(今回は電子メールを選択)
- サブスクリプション電子メール : 自分のメールアドレスを入力
※既に作成済みの通知トピックを利用してもOKです。初回作成時には、登録したメールアドレス宛にサブスクリプションの確認メール(英語)が送付されますので、OKしておきます。
最後に、REPEAT NOTIFICATION? (アラームが起動し続ける場合) にチェックをつけ、通知頻度 を 1 minutes に設定します。これで、アラームの対象の間は1分毎にメールが届き続けます。
全ての入力が完了したら、アラームの保存 ボタンを押します。
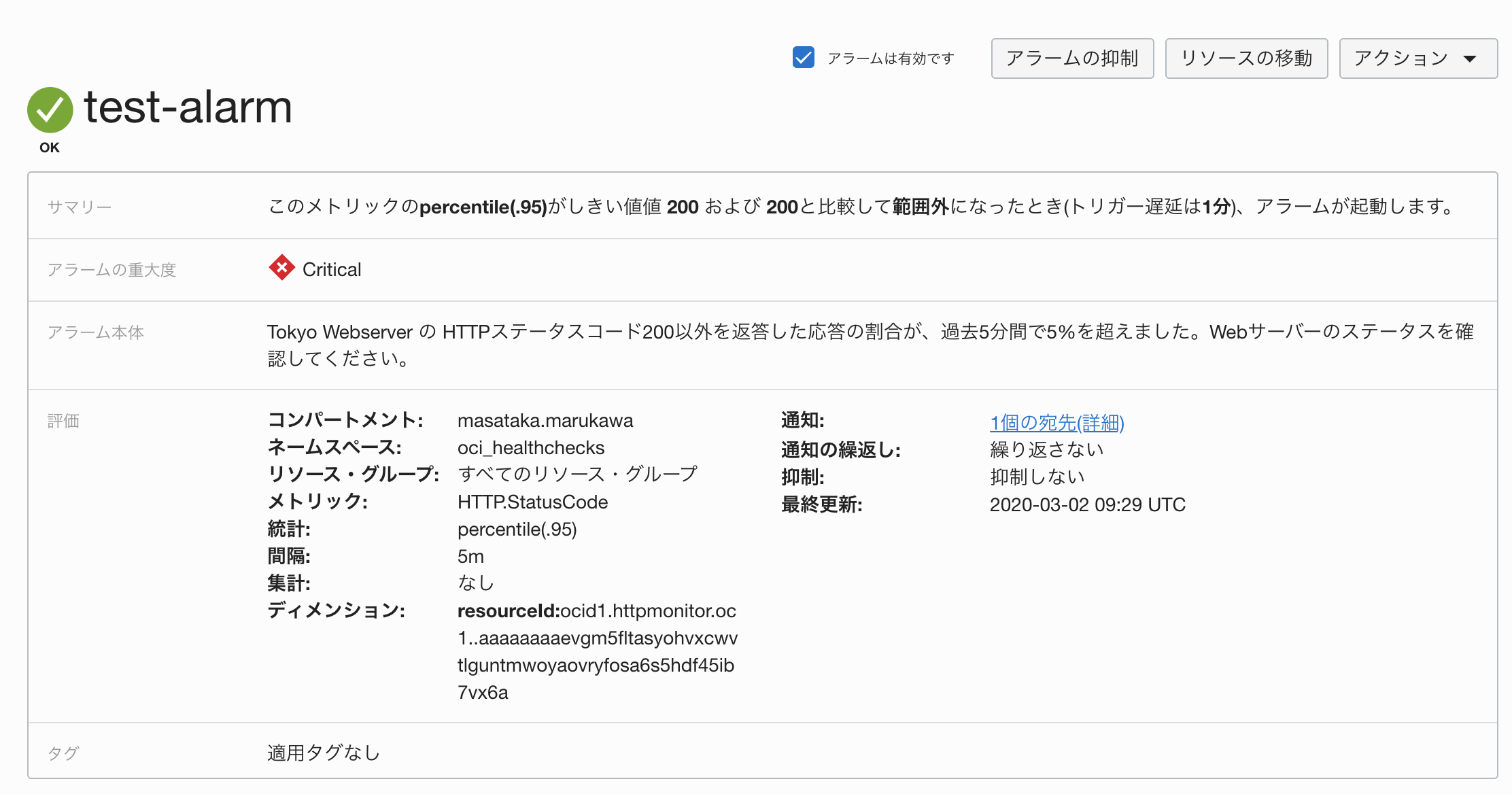
作成が完了したアラームのイメージです。ステータスが緑のOKとなっていることを確認します。
4. テスト
さて、いよいよWebサーバーの異常を起こして、ちゃんと検知するかを確かめてみましょう。
どんなやり方でもOKですが、手っ取り早くWebサーバー上で index.html をリネームしてしまって、404 Not Foundを返してみようと思います。
sudo mv /var/www/html/index.html /var/www/html/index.temp
(手元のWebサーバーの設定に合わせて作業します)
すると、ヘルス・チェックが10秒以内に異常を検知して、エンドポイントが使用不可ステータスになります。
詳細を開くと、HTTPステータスコードが404になっていることがわかります。

トリガー遅延分数を1分に設定しているので、1分ほど待つと、アラームが起動した通知メールが届きます。メールのタイトルは、アラームの名称で、メールの本文は以下のような感じのJSONデータです。(現在のところ、このメールの文面を変えることはできないようです)
{
"dedupeKey": "2889354d-b868-4a0e-a315-d2e9094252ae",
"title": "test-alarm",
"body": "Tokyo Webserver の HTTPステータスコード200以外を返答した応答の割合が、過去5分間で5%を超えました。Webサーバーのステータスを確認してください。",
"type": "OK_TO_FIRING",
"severity": "WARNING",
"timestampEpochMillis": 1583909940000,
"alarmMetaData": [
{
"id": "ocid1.alarm.oc1.ap-tokyo-1.aaaaaaaawwfk3cy7imokjef25svzyfs7vbqsfus3fotuch2uyf4n2qile66q",
"status": "FIRING",
"severity": "WARNING",
"query": "HTTP.StatusCode[5m]{resourceId = \"ocid1.httpmonitor.oc1..aaaaaaaa..........ypq\"}.percentile(.95) not in (200, 200)",
"totalMetricsFiring": 2,
"dimensions": [
{
"resourceDisplayName": "test-healthcheck",
"vantagePoint": "azr-hkg",
"protocol": "HTTP",
"resourceId": "ocid1.httpmonitor.oc1..aaaaaaaa..........ypq",
"target": "xxx.xxx.xxx.xxx"
},
{
"resourceDisplayName": "test-healthcheck",
"vantagePoint": "aws-icn",
"protocol": "HTTP",
"resourceId": "ocid1.httpmonitor.oc1..aaaaaaaa..........ypq",
"target": "xxx.xxx.xxx.xxx"
}
]
}
],
"version": 1
}
待っていると1分毎にアラームのメールが届き続けます。この状態になっていれば成功です。
次に、サービス(httpd)をダウンさせてみます。
先ほど変更した index.html を元に戻した上で、sudo systemctl stop httpd でWebサーバーをダウンさせます。この時も10秒以内にヘルスチェックで検知が行われ、ヘルス・チェック履歴に表示されます。
詳細を見ると、connection refused というエラーメッセージと共に、HTTPステータスコードが 0 になっていることがわかります。これは、ヘルスチェックの仕様として、応答が返ってこない場合にはステータスコードは0が入るようになっているようです。

ステータス0は正規のコードではありませんが、今回は数値として200を外れた場合にアラームが飛ぶように設定しているため、やはり1分ほどすると先ほど同じようにメールに通知がきます。
実環境での運用に関する考慮
以上で簡単な設定とテストは完了しました。今回はHTTPのステータスコードを見るというシンプルなパターンで実装しましたが、実際にはもう少し実運用に即したアラームを張るべきです。
つい最近、OCIのマニュアルも更新されてヘルス・チェックのメトリックが公開されたようですので、これを活用するといいと思います。(3/11時点ではまだ英語版のみ)
なお、HTTPのステータスコードのディメンション (絞り込み条件)で、 statusCode2xx のような、ステータスコードがx00番代の時の数、みたいなものをメトリックで取得できそうな記述がありますが、私の環境ではどうやっても設定できませんでした。もし今後できるようになれば、もう少しスマートにステータスコード異常が検知できると思いますので、情報入ったらアップデートしようと思います。
その他、アラームを張るのに使えそうなメトリックをマニュアルから読み解くと、
- HTTP.DNSLookupTime : DNSの異常を検知する
- HTTP.ResponseTime : 応答時間が極端に遅い場合に通知する
あたりはWebサーバーで普段使いできそうな感じです。
また、Webサーバー以外の場合も、以下のようなメトリックにアラームを設定しておくと有効そうです。
- PING.isHealthy : PINGのステータスコードでポートを単純に監視する
- PING.Latency : PINGの応答時間を監視する
また、つい最近(2020/2/25)に、NotificationサービスからEmailだけでなく、直接Functionsをコールできるような機能が実装されたので、これを利用して単純に通知する以外に対処まで行ってしまうことも考慮するといいと思います。例えば、単純なWebサーバーであれば、外部から再起動してしまうとか、ロードバランサーの設定を変えて異常を起こしているバックエンド・サーバーを意図的に切り離す、といったこともできると思います。
まとめ
エージェントを組み込むような大規模な監視の仕組みを実装するほどではない、ちょっとしたWebシステム(やサーバー)の監視に、ヘルス・チェックの機能はとても簡単で有効ですので、OCIを使う上で活用するといいテクニックかと思います。このドキュメントがその役に立てば幸いです。