この記事は Oracle Cloud Infrastructure Advent Calendar 2019 の12/4の記事として書かれています
先日、 OCHaCafe Premium#1:Oracle Cloudで考える高可用性アーキテクチャ というセミナーで話させて頂く機会がありました。
その際、Oracle Cloud Infrastructure (OCI) の仮想マシンインスタンスに付与したセカンダリIP(Virtual IP)を、コマンドラインで他のインスタンスに付け替えて擬似的なVIPフェイルオーバーを行う、というデモをやったので、Oracle Cloud Infrastructure Advent Calendar 2019の記事にはそのHowToでも書こうかな、なんてと思っていたら、なんと @NSO-KC さんがすでに記事を書いている!! しかも今日!!
[Oracle Cloud] ComputeのセカンダリIPのフェールオーバを試してみる
やばいネタがなくなった。。。
ということで & せっかくなので、ちょっと予定を変更して、@NSO-KC さんのブログエントリーに便乗してを発展させて、このVIPのフェイルオーバーを自動化する方法について書いてみたいと思います。
やりたいこと
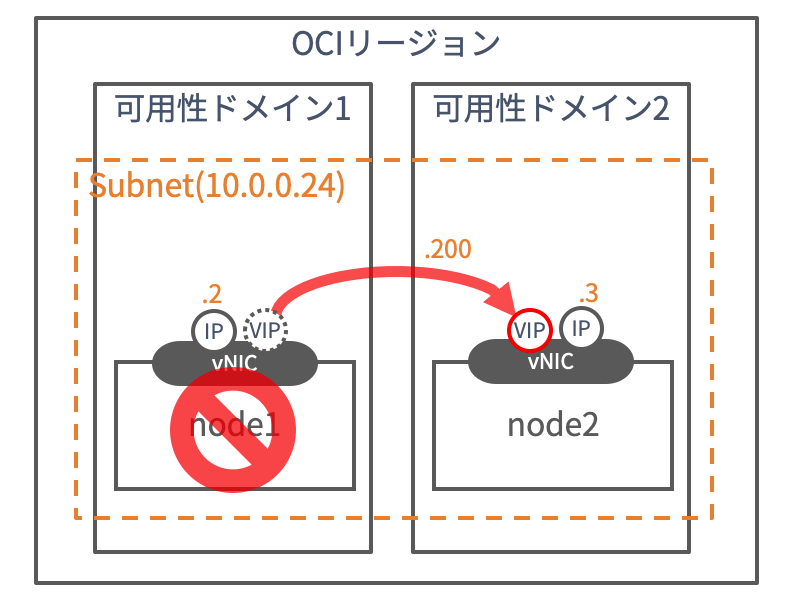
可用性ドメイン(AD)障害がおきて、インスタンスがダウンしたような場合にも、別の可用性ドメインのインスタンスに仮想IPを引き継いで、オンライン処理を継続したい。 しかも自動で!!
方法
VIPのフェイルオーバーそのものは、oci-cliを使えばコマンドライン一発でインスタンスの状態に関わらず、IPを別インスタンスに付与することができます。
処理を発動する前のインスタンス(IP)の状態監視と、インスタンスダウン判定時のコマンドの発動には、RHEL系のLinuxでよく使われる Pacemaker というHAクラスタのOSSを使います。
実は、Pacemakerを使ったOCIでのIPフェイルオーバーについては、かなり昔のこの Oracle Blog にエントリーがありますので、実際にはこちらをやってみるだけです。とはいえこのエントリーは情報が少し古いのと、細かいステップまでは省略されていますので、その辺りを補足しながら書きたいと思います。
ではやってみましょう。
最初の方のステップは、@NSO-KCさんのこちらのブログエントリーとほぼ同じです。
1. ネットワークを準備する
今回は可用性ドメインをまたぐフェイルオーバーをやりたいので、複数の可用性ドメインが存在するリージョン(US East/US West/UK South/EU Centralのいずれか)を選択して、VCNを一つ作ります。
そして、サブネットはテンプレートが初期状態で作成するサブネット(可用性ドメイン固有サブネット)ではなく、新しくリージョナル・サブネットを作成します。サブネットのCIDRは任意ですが、今回の例では10.0.0.0/24 で作成しています。
また、初期状態では作成したサブネットの中同士の通信は拒否される状態になっていますので、セキュリティ・リストのイングレス通信で、サブネット内の全てのを許可にしておきましょう。
VCNの設定方法がよくわからない方はこちら
2. インスタンスを2つ準備する
異なる2つの可用性ドメインに、それぞれコンピュート・インスタンスを立てます。シェイプはなんでもOK、OSはOracle Linux 7を使用します。(CentOS 7でもOKだと思います)
インスタンス名およびホスト名は任意のもので結構ですが、今回は node1、node2で作成していきます。他の名前を使用する場合は、以後のコマンドなどはなどは適宜読み替えてください。
OCIのインスタンスの作り方がよくわからない方はこちら
3. 各インスタンスのrootユーザーにoci-cliをインストールする
ここは、@NSO-KC さんの手順と違うところです。oci-cliをrootユーザーでセットアップしてください。
今回は、Pacemakerからoci-cliを起動しますので、rootユーザーからoci-cliが実行できる必要があります。
OCIのインスタンスで初期状態で作成されるopcユーザーは、sudo -sでrootになれるように設定されていますので、rootになった状態で、ociコマンドが通ることを確認してください。
oci-cliのセットアップ方法はこちら
4. 各コンピュート・インスタンスの中からのAPIコールを許可する
今回は、インスタンス・プリンシパルの機能を使用して、API鍵の登録なしでも各インスタンスからVIPの操作ができるようにします。@NSO-KCさんのエントリーの
3.動的グループの作成
4.ポリシーの作成
をそのまんま実行します。
5. 必要なパッケージをインストールし、サービスを起動する
Pacemakerの他に、クラスタの死活監視をしてくれるcorosync、コマンドラインインタフェースのpcsと、IPを監視するのに必要なエージェントのパッケージ類一切合切をインストールします。node1、node2両方で実施してください。
$ sudo yum -y install pcs pacemaker corosync resource-agents fence-agents-all
pacemaker、corosync、pcsd の各サービスの起動と、常時起動の設定もしておきます。こちらも両ノードで実施します。
$ sudo systemctl start pcsd.service
$ sudo systemctl start corosync.service
$ sudo systemctl start pacemaker.service
$ sudo systemctl enable pcsd.service
$ sudo systemctl enable pacemaker.service
$ sudo systemctl enable corosync.service
6. ハートビート通信用のポートを開ける
OCIのOracle Linux 7 (CentOS7も)のインスタンスは、初期状態でfirewalldが起動していますので、ポートを開けます。こちらも両ノードで実施してください。
$ sudo firewall-cmd --permanent --add-service=high-availability
$ sudo firewall-cmd --add-service=high-availability
$ sudo firewall-cmd --reload
7. haclusterユーザーのパスワードを設定する
pcs コマンドは、haclusterというOSユーザーを使ってクラスターノードの設定などを行うため、パスワードを各ノードに設定します。
設定はリモートノードからも行う場合もありますの、パスワードは両ノードで同じになるように設定します。
$ sudo passwd hacluster
Changing password for user hacluster.
New password:
Retype new password:
passwd: all authentication tokens updated successfully.
8. pcs でクラスターノードの認証を行う
pcsコマンドで、クラスターの設定ができるように認証を行います。以下のコマンドを片方のノードだけで実行します。haclusterユーザーのパスワードを聞かれるので、入力します。
$ sudo pcs cluster auth node1 node2
Username: hacluster
Password:
node1: Authorized
node2: Authorized
9. クラスターの起動
vip-failover-test という名前(任意)のクラスターを作成し、起動します。片ノードだけでOKです。
$ sudo pcs cluster setup --start --name vip-failover-test node1 node2
10. 仮想IPをクラスターのリソースとして登録する
vip-failover-test クラスターに、10.0.0.200を仮想IPとして Cluster_VIP という名前(任意)で登録します。IPアドレスは任意ですが、必ず作成した2つのインスタンスが所属しているサブネットの中の、他にインスタンスが存在しないIPアドレスを指定するようにしてください。監視間隔も任意で設定してください。(ここでは10秒)
$ sudo pcs resource create Cluster_VIP ocf:heartbeat:IPaddr2 ip=10.0.0.200 cidr_netmask=24 op monitor interval=10s
11. フェイルオーバー時に実行されるスクリプトにoci-cliのコマンドを仕込む
今回の設定のキモはここです。
今回の設定では、IPaddr2 というPacemakerのリソースエージェント(RA)を使用してリソースの監視を行います。このIPaddr2は、リソースの障害を検知した場合に /usr/lib/ocf/resource.d/heartbeat/IPaddr2 というスクリプトを実行するように設定されています。
初期状態では、このスクリプトはリソース「Cluster_VIP」がnode1からnode2に移動する際に、VIP(今回は10.0.0.200)をnode1のNICから削除して、node2に追加する、という作業をやるように記述されていますが、今回はそれに加えてoci-cliのコマンドを発行して、クラウドのネットワーク側からも、10.0.0.200の仮想IPをnode1からnode2に付け替える処理を追記します。
というわけで、細かいことは抜きにして以下のコマンドを、node1、node2の両ノードで発行します
sudo sed -i '64i\##### OCI vNIC variables\' /usr/lib/ocf/resource.d/heartbeat/IPaddr2
sudo sed -i '65i\server="`hostname -s`"\' /usr/lib/ocf/resource.d/heartbeat/IPaddr2
sudo sed -i '66i\node1vnic="<ノード1の仮想NICのOCID>"\' /usr/lib/ocf/resource.d/heartbeat/IPaddr2
sudo sed -i '67i\node2vnic="<ノード2の仮想NICのOCID>"\' /usr/lib/ocf/resource.d/heartbeat/IPaddr2
sudo sed -i '68i\vnicip="10.0.0.200"\' /usr/lib/ocf/resource.d/heartbeat/IPaddr2
sudo sed -i '616i\##### OCI/IPaddr Integration\' /usr/lib/ocf/resource.d/heartbeat/IPaddr2
sudo sed -i '617i\ if [ $server = "node1" ]; then\' /usr/lib/ocf/resource.d/heartbeat/IPaddr2
sudo sed -i '618i\ /usr/bin/oci network vnic assign-private-ip --unassign-if-already-assigned --vnic-id $node1vnic --ip-address $vnicip \' /usr/lib/ocf/resource.d/heartbeat/IPaddr2
sudo sed -i '619i\ else \' /usr/lib/ocf/resource.d/heartbeat/IPaddr2
sudo sed -i '620i\ /usr/bin/oci network vnic assign-private-ip --unassign-if-already-assigned --vnic-id $node2vnic --ip-address $vnicip \' /usr/lib/ocf/resource.d/heartbeat/IPaddr2
sudo sed -i '621i\ fi \' /usr/lib/ocf/resource.d/heartbeat/IPaddr2
<ノード1の仮想NICのOCID> および <ノード2の仮想NICのOCID> の箇所は、ご自身の環境に合わせて書き換えてください。
また、途中に仮想IPの値 10.0.0.200 と、一つ目のノードのホスト名 node1 もありますので、必要に応じて変更してください。
12. OCIコンソールから、VIPをセカンダリIPとして追加
OCIコンソールから、VIP (10.0.0.200)を、node1、node2のどちらかのプライマリ仮想NICにセカンダリIPとして追加します。
セカンダリIPの追加の方法はこちら
13. リブート
最後に、両方のノードをリブートします。
14. 設定の確認
pcs status コマンドで、ここまでの設定が確認できます。
[opc@node1 ~]$ sudo pcs status
Cluster name: vip-failover-test
Stack: corosync
Current DC: node1 (version 1.1.20-5.el7-3c4c782f70) - partition with quorum
Last updated: Wed Dec 4 07:02:53 2019
Last change: Fri Nov 29 14:14:51 2019 by root via cibadmin on node1
2 nodes configured
1 resource configured
Online: [ node1 node2 ]
Full list of resources:
Cluster_VIP (ocf::heartbeat:IPaddr2): Started node1
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
Onlineにnode1,node2の両方があり、登録したVIPリソースCluster_VIPのステータスがStartedになっていて、片方のノードだけ登録されていればバッチリです。
また、ipコマンドで、各ノードに振られたIPアドレスも確認しておくといいと思います。
[opc@node1 ~]$ ip addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9000 qdisc pfifo_fast state UP group default qlen 1000
link/ether 02:00:17:06:12:b5 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.2/24 brd 10.0.0.255 scope global dynamic ens3
valid_lft 84316sec preferred_lft 84316sec
inet 10.0.0.200/24 brd 10.0.0.255 scope global secondary ens3:0
valid_lft forever preferred_lft forever
[opc@node2 ~]$ sudo ip addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9000 qdisc pfifo_fast state UP group default qlen 1000
link/ether 02:00:17:07:09:c7 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.3/24 brd 10.0.0.255 scope global dynamic ens3
valid_lft 84190sec preferred_lft 84190sec
このケースだと、node2だけに10.0.0.200がセカンダリのIPとして振られていることがわかります。
テスト
テストのやり方は簡単、別のインスタンスから10.0.0.200にクエリを投げつつ、VIPが振られているノードをシャットダウンやリブートするだけです。どーんとやっちゃいましょう。ハートビートを10秒にしているので、最大でも10秒+程度で無事にフェイルオーバーするはず。
手元でpingを打ちながらのテストだと、数秒程度のハングが見られますが、その後はIPがフェイルオーバーして応答が継続します。
node1をシャットダウンし、VIPがnode2にフェイルオーバーした状態で、pcs statusコマンドを打つと、こんな感じの応答が帰ってきます。node1がダウンし、node1にあったCluster_VIPリソースがnode2に移動していることがわかります。
[opc@node2 ~]$ sudo pcs status
Cluster name: vip-failover-test
Stack: corosync
Current DC: node2 (version 1.1.20-5.el7-3c4c782f70) - partition with quorum
Last updated: Wed Dec 4 07:17:58 2019
Last change: Fri Nov 29 14:14:51 2019 by root via cibadmin on node1
2 nodes configured
1 resource configured
Online: [ node2 ]
OFFLINE: [ node1 ]
Full list of resources:
Cluster_VIP (ocf::heartbeat:IPaddr2): Started node2
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
また、ipコマンドを確認すると、node2に10.0.0.2のVIPがフェイルオーバーしていることも確認できます。
[opc@node2 ~]$ ip addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9000 qdisc pfifo_fast state UP group default qlen 1000
link/ether 02:00:17:07:09:c7 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.3/24 brd 10.0.0.255 scope global dynamic ens3
valid_lft 84085sec preferred_lft 84085sec
inet 10.0.0.200/24 brd 10.0.0.255 scope global secondary ens3
valid_lft forever preferred_lft forever
まとめ
というわけで、スクリプトに少し手を加えることで、クラウド環境(OCI)でもHAクラスタによるVIPのフェイルオーバーが比較的簡単に実装できます。特にOracle Cloudは、可用性ドメイン(データセンター)をまたいでサブネットが構成できるため、データセンター障害の場合の対応としてもこの方法を利用することができます。(残念ながら東京リージョンでは可用性ドメインが1つしかないのですが。。。)
特にオンプレから持ってきたHAアプリケーションなどで利用することができますので、ぜひ試してみてください。
また、今回はpacemakerの設定周りなどはほとんど触っていません。デフォルトの状態ではnode1が再度立ち上がってくると、そちらに再度フェイルバックしますので、本番で利用する際にはそのあたりも変更が必要な場合があるでしょう。
また、今回は各ノードのIPアドレスだけを監視していますが、例えばHTTPサーバーのポートを監視してフェイルオーバーの条件にするといったこともできますので、必要に応じてPacemakerをカスタマイズして利用してみてください。
参考
HIGH AVAILABILITY ADD-ON リファレンス
この記事は Oracle Cloud Infrastructure Advent Calendar 2019 の12/4の記事として書かれています