はじめに
備忘録としてアルゴリズムの解説をしていきます。
「わかりやすく短く」を意識して執筆していきます。
コードは毎回Pythonで実装していきます。
今回のテーマはC、D問題に出てくる 座標圧縮 ですます。
前提知識
誰でも理解できるという題ですが、前提知識がなければどうにもなりません![]()
下記の知識は理解している前提で執筆いたします![]()
記事リンク
- 【bit全探索】誰でも理解できるアルゴリズム解説
- 【座標圧縮】誰でも理解できるアルゴリズム解説(今回の記事)
- coming soon...
座標圧縮とは?
簡単にいうと、配列の中でその値が何番目に小さいか・大きいかを記録することです。
使用効果
MLE(メモリ上限超過)を防ぐことができます!!!
めちゃくちゃでかい配列(10億×10億とか?)を作ることになる問題に有効です。
例1 : 一次元配列の座標圧縮
# 座標圧縮前↓
[6, 70, 40, 90, 90, 6, 20]
# 座標圧縮後↓
[1, 4, 3, 5, 5, 1, 2] # 6は1番目に小さい、20は2番目に小さい ... 90は5番目に小さい
座標圧縮の前と後の配列です。
このように、その値が配列の中で何番目に小さいかを記していきます。
注)同じ値は同じ順位とします。
例2 : 二次元配列の座標圧縮
二次元配列の、値が0以外の点のみに着目して座標圧縮してみます。
圧縮後の形式は[縦の順位, 横の順位]にします。
少し複雑ですが、1つ1つ確認してみましょう。
# 座標圧縮前↓
[
[6, 0, 0, 0, 0, 8],
[0, 1, 0, 6, 0, 0],
[0, 2, 8, 0, 5, 0],
[0, 0, 0, 0, 0, 0],
[0, 0, 0, 5, 0, 0],
[2, 0, 0, 5, 0, 0],
]
# 座標圧縮後↓
[
[2, 1], # 座標[0, 0] = 6
[1, 2], # 座標[0, 5] = 8
[1, 1], # 座標[1, 1] = 1
[2, 2], # 座標[1, 3] = 6
[2, 1], # 座標[2, 1] = 2
[1, 3], # 座標[2, 2] = 8
[1, 2], # 座標[2, 4] = 5
[1, 1], # 座標[4, 3] = 5
[1, 1], # 座標[5, 0] = 2
[1, 2], # 座標[5, 3] = 5
]
6×6=36マスの座標を、2×10=20マスに圧縮できましたね。
座標圧縮は、配列の特定の値を無視することで圧縮します。例えば、1000マス×1000マスの100万マスあったとしても、そのうち100マスにしか着目しないなら、200マス(100マスに対して、縦と横で座標圧縮する)に圧縮できます。
座標圧縮のコードと解説
コード
zaatsu関数の引数はintを扱う一次元listです。
def zaatsu(before_list):
set_sort = sorted(list(set(before_list))) # 重複排除とソート
rank = {x:i+1 for i,x in enumerate(set_sort)} # 各値に順位づけ
after_list = []
for tmp in before_list:
after_list.append(rank[tmp])
return after_list
解説
・ 解説に用いる配列[7, 4, 9, 9, 2]
-
重複排除とソートした配列の作成
順位づけのための下準備です。set_sort [2, 4, 7, 9]

-
値の順位付け
各値が配列の中で何位なのかをdictにします。rank {2:1, 4:2, 7:3, 9:4}

-
2で作成した順位のdictと最初の配列を用いて結果を作成
「7は3位、4は2位、9は4位、9は4位、2は1位」after_list [3, 2, 4, 4, 1]

実践
ABC213 C問題「Reorder Cards」で実践してみましょう!
問題を要約すると以下のようになります。
前提
1. H×W枚のカードがある
2. N枚のカードのみに番号が書いてあり、その他のカードには何も書いてない
3. 上からAi、左からBi番目のカードにはi番が書いてある
処理
4. 何も書いてないカードだけの行もしくは列を全て削除する
5. 全て削除した後、数字の書いてあるカードがどこにあるか出力する。
入力例1を見るとわかりやすいですが、一番目のABが「3 2」なので、上から3番目・左から2番目のカードに1が書いてあります。
MLEの計算
今回の問題、「メモリ制限が1024MB」に対して「座標の最大値は10億×10億の100京マス」になります。1,000,000,000,000,000,000です![]()
配列の要素は、1つで40バイトほどのようです。実際に二次元配列を作るとなると40B×100京マスで、40000000000000MBです![]() 余裕でMLEしますね。
余裕でMLEしますね。
よって、座標圧縮を使用します!例2のように「何か書いてるカード」だけに着目することで、Nの最大値である10万×2(縦と横)の20万マスに圧縮することができます。
解答のコツ
- 実はこの問題、座標圧縮の結果を出力するだけでACになっちゃいます

出力例を見るとわかりますが、その値の「縦の順位 横の順位」になっているんです。よって、実装は「入力→座標圧縮→出力」だけで終わりです。 - 縦と横それぞれで座標圧縮するため、入力時に縦と横をそれぞれ別の配列とする。こんな感じ↓
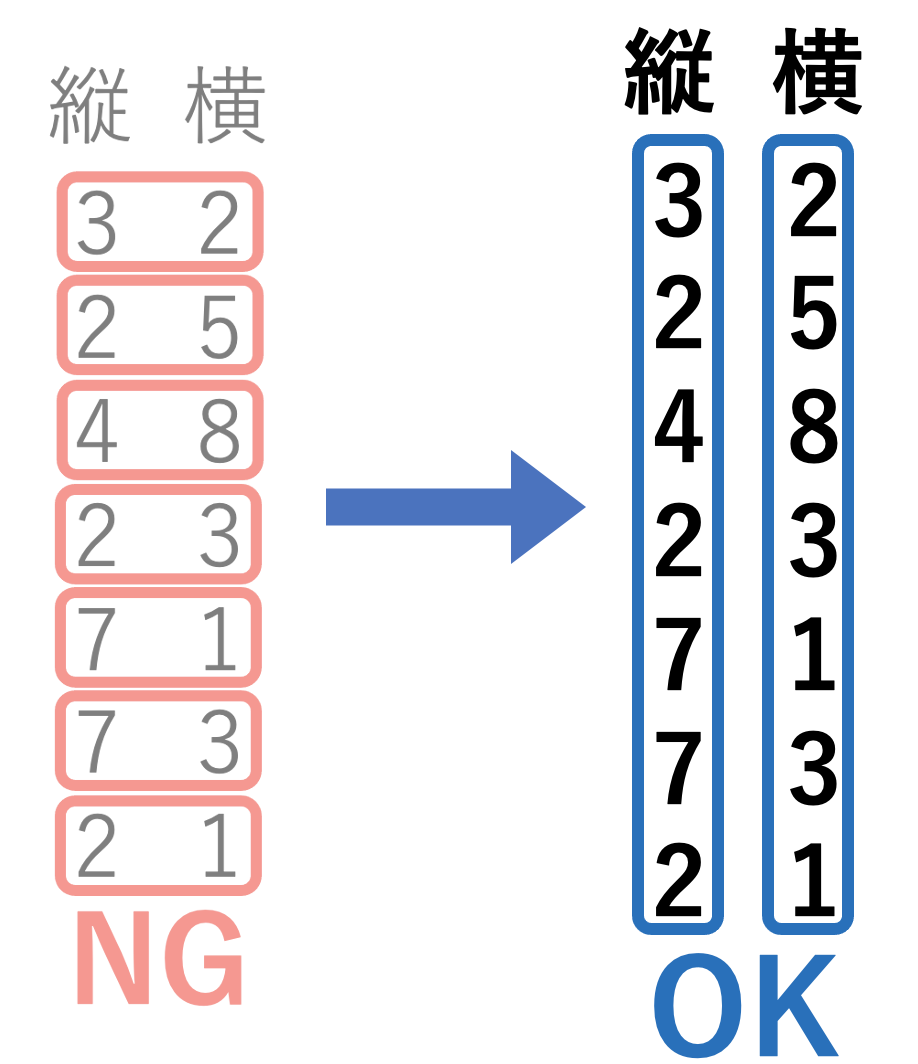
それでは実際のコードを見てみましょう。
実際のコード
# 座標圧縮の関数
def zaatsu(before_list):
set_sort = sorted(list(set(before_list))) # 重複排除とソート
rank = {x:i+1 for i,x in enumerate(set_sort)} # 各値に順位づけ
after_list = []
for tmp in before_list:
after_list.append(rank[tmp])
return after_list
# 入力
h, w, n = map(int,input().split())
h_list, w_list = [], []
for i in range(n):
a, b = map(int,input().split())
h_list.append(a)
w_list.append(b)
# 座標圧縮の実施
h_list = zaatsu(h_list) # 縦の座標圧縮
w_list = zaatsu(w_list) # 横の座標圧縮
# 出力
for i in range(n):
# その座標が縦で何位、横で何位かを出力する。
print(h_list[i], w_list[i])
入力した値を、座標圧縮し、そのまま出力するだけです。
こんな簡単なのに茶色問題なんです![]()
AtCoderの問題例
おわりに
今回は座標圧縮を解説していきました。
こうしたらもっとわかりやすくなるなど、ご教示いただけると嬉しいです。
今回はとってもいい記事になったね。明日はもっといい記事になるよね。ハム◯◯🐹
Let's AtCoder!!!
参考
- 最速で緑になる-基礎・典型50問詳細解説-佐野
https://amzn.asia/d/hCwPX57 - 【競プロ】だれでもかんたん座標圧縮
https://qiita.com/_ken_/items/7d5a955eaf362ccf1dc6