はじめに
1/10に日本oracle社主催のMySQL 8.0入門セミナー講演資料 (チューニング基礎編、SQLチューニング編)に行ってきました。
本記事では上記イベントのレポートをしていきます。
※こちらのイベントではタイトルにもある通りMySQL8.0を対象としており、上記リンクからダウンロード可能な資料や本記事で解説するコマンド等はMySQL5.7以前のものではサポートされていない場合がございます。
データベースにおけるパフォーマンスとは
実際にパフォーマンスの向上方法を解説する前にデータベースにおけるパフォーマンスとは一体何を指し示しているかを整理する必要がある。
下記が主にデータベースのパフォーマンスを測定するための指標となっている。
・スループット
単位時間あたりの処理能力
並列処理が出来る件数が増えるほどこのスループットの値が向上する
・レスポンスタイム(レイテンシー)
処理を実行してからの結果が帰ってくるまでの時間
1処理自体にどのくらい時間がかかるか
・スケーラビリティ
データベースをはじめとするサービスのパフォーマンスは必ずハードウェアのスペックに依存するため、メモリやCPUの追加、ディスクのSSD化などに柔軟に対応できる必要がある。
※単にハードウェアを良いものにすればパフォーマンスが上がりますが本記事の趣旨と異なるので以降では解説しない
キューイング
パフォーマンス測定の指標ではないが、パフォーマンスチューニングに当たって非常に重要な仕組みなので解説していく。
キューイングとは複数のリクエストが発生したときに順番通り処理が実行されるように管理される待ち行列のことである。レスポンスタイムはこの待ち時間+実行時間で計算される。
実処理が実行される前のプロセスの準備時間にもキューに含まれるが、大量ののリクエストが発生した場合など現環境のスループットでは一度に処理できない際に待ち時間として増加される。当然、レスポンスタイムも増加する。
このキューイングの仕組みを理解した上で、どの指標が低いのか、そしてネットワーク、処理、I/O、テーブルロックなどどこにボトルネックがあるかによって効果的な方法が異なるので、これらを知ることがパフォーマンスチューニングの第一歩になる。
またパフォーマンスチューニングはどのようなものであってもコストがかかるため、そのパフォーマンス向上の必要性や費用対効果などもしっかり検討したうえで実施をしていく必要がある。
パフォーマンスチューニングにおいて大事なこと
以上のことをまとめるとパフォーマンスチューニングには実対応の前に下記のことを検討実施していく必要がある。
1.パフォーマンスの測定(パフォーマンス状況の確認)
2.パフォーマンス低下のボトルネックの洗い出し(スループット?レスポンスタイム? I/O?)
3.上記に対するチューニングは必要か、コストに見合ったビジネスメリットがあるかの検討
これらを踏まえた上で実際にどのようなことを確認していく必要があるのか見ていく。
パフォーマンス測定方法
例えばwebサイトなどの場合であれば、サーバ,DBサーバとの通信速度(ネットワーク)やリクエストの混雑状況、ファイル出力、データ加工処理などアプリケーションによる処理の差など様々な要素があるため、ここではMySQLデータベースの処理単体でのパフォーマンス測定について解説する、
一番単純な方法は開発環境などで実際に利用するSQLを実行して各種指標を監視する方法である。
tcpdumpコマンドでパケットの通信を計測する方法や、MySQL Proxyで監視する方法がある。
後半のSQLチューニング章で紹介するEXPLAINコマンドやSHOW FULL PROCESSLISTコマンドを利用することでクエリ自体のステータスや対象テーブルの状況なども確認できるので併せて利用すると効率的。
その他ツールを利用する場合、下記などがある。
・mysqlslap
・SysBench
チューニングのアプローチ
では実際にパフォーマンスチューニングを行っていく。
DBのパフォーマンスチューニングでは大きく分けて2種類のアプローチがある。
・DBチューニング(全体最適化)
主にスループットを向上させる
MySQLの設定ファイルのパラメータ等を環境に適した形に操作する
・SQLチューニング(個別最適化)
主にレスポンスタイムを向上させる
テーブルの構成やクエリの最適化によってクエリ実行速度の向上を目指す
それぞれ解説していく。
DBチューニング(全体最適化)
MySQLサーバの設定はシステム変数で定義されている。
まずはどのような設定がされているのか確認が必要。
システム変数はmy.cnfやmy.iniにて参照・編集可能になっている
また下記コマンドにても参照・編集が可能。
/*全システム変数を表示*/
SHOW VARIABLES ;
/*システム変数を設定*/
SET [GLOBAL] @variable = @value ;
各種システム変数の詳細についてはこちらに記載されている。
今回はパフォーマンスに焦点を置いているため、性能統計情報分析のために用意されているパフォーマンススキーマ/sysスキーマにフォーカスする。
・パフォーマンス・スキーマ
性能統計情報の仕組み
MySQLサーバ内の「イベント」ごとの処理時間を記録
・処理時間
・処理データ量
・ソースコードでの位置
・各種メタデータ
・sysスキーマ
パフォーマンススキーマをより便利に使うためのビュー、プロシージャ、ファンクションのセット
・I/O量の多いファイルや処理、コストの高いSQL文、ロック情報
・テーブル、インデックス、スキーマの統計、レイテンシ、待ち時間
performance_schema/sys_schemaで実行できるクエリサンプル
/* performance_schemaからグローバル変数を参照する */
SELECT * FROM performance_schema.global_variables ;
/* sys_schemaからテーブル統計の要約を参照する */
SELECT * FROM sys.schema_table_statics limit 1 ;
重要確認パラメータ
上記にあげた確認方法の中でもDBサーバ設定にボトルネックがある場合、下記の値を参照・編集することで解決につながる可能性が高い。
max_connections
・サーバが許容可能なコネクションの数
・スループットが低い場合にはここを増やすことでパフォーマンス改善につながる
・増やしすぎるとサーバメモリを多く消費するためハードウェアのスペックと相談
・デフォルト(設定なし)の場合は151となっている
thread_cache_size
・スレッドをキャッシュする数
・レスポンスタイムが長い場合にもこちらを増やすことで改善につながる可能性がある
・こちらもメモリを利用するため増やしすぎ注意
・デフォルトは9
query_cache_size
・クエリ結果のキャッシュ
・直近に似た内容のクエリが叩かれた場合などはこのキャッシュから返されるためDBの処理としては非常に効率的
・近い内容のクエリを頻繁にたたく場合はこのキャッシュを利用することでパフォーマンス改善につながる
sort_buffer_size
・ソート処理用のメモリサイズ
・ここで設定されているサイズを超えるものはディスクによって行われる
・ディスクI/Oは処理に時間がかかるため、大量データのソート処理が入る場合はこの値を上げることでパフォーマンス改善につながる可能性がある
・MySQL5.6でデフォルトが2MB⇒256KBに縮小されたらしい
※Tips スキーマデザイン
テーブル定義においてもパフォーマンスを考える上で非常に大切になってくる。
【データ型】
・桁数の多くない数値型に対してはtinyint,smallint,mediumintなどを利用する
・joinで利用する列は同じデータ型にする
・charではなくvarcharを利用する
・可能なところはNOT NULLを宣言
【インデックス】
・複数列貼ることで参照速度を改善することができる
※参照速度は上がるが更新速度は下がるため貼りすぎも注意
DBチューニングまとめ
★スループットが低い、待機が多いことによるレスポンスタイムの低下はDB設定を見直す
★自身の環境のメモリサイズを鑑みて有効に使えているか確認する
⇒全然使っていない・・・スレッド/クエリキャッシュを使用してみる
⇒カツカツ・・・・・・・メモリを使い切ると処理コスト高のディスクを使用するのでキャッシュなどを減らす
★テーブルで利用する列の型は、インプットを想定して適切な型にする
★インデックスを利用する
SQLチューニング(個別最適化)
大半の場合SQLをチューニングすることでパフォーマンス改善がなされる場合が多い。
まずは実行に時間がかかっているクエリの特定が必要。
遅いクエリの参照方法手順(slow_query_log)
slow_query_logの設定確認
OFFになっているのでONにする必要がある。
mysql > show variables like 'slow%' ;
+---------------------+----------------+
| Variable_name | Value |
+---------------------+----------------+
| slow_launch_time | 2 |
| slow_query_log | OFF |
| slow_query_log_file | mysql-slow.log |
+---------------------+----------------+
SET slow_query_log = ON ;
これでslow_query_log_fileから実行時間の遅いクエリを確認することができる。
また、「実行時間の遅い」定義はlong_query_timeという変数で設定されている。
SHOW FULL PROCESSLIST
SHOW FULL PROCESSLISTコマンドを使えば現在実行中のクエリの実行時間やデータ量、ステータスなどが参照できる。
実行計画
実行計画とはSQLを処理する際の処理の手順となっている。
主なプロセスとしては下記などがある。
・インデックススキャン
・テーブルスキャン
・JOINの順番
・サブクエリの処理
実行計画によってパフォーマンスが大きく変わる可能性もあるので、対象のクエリが適切な実行計画を持っているか確認をする。
EXPLAINコマンド
対象のクエリの実行計画を参照するクエリである。
mysql > EXPLAIN select * from sampledb.sampletable ;
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| 1 | SIMPLE | table | ALL | sample_id | NULL | NULL | NULL | 10 | NULL |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
ここで非常に重要なカラムはtypeとpossible_keys になる。
type
typeには下記の種類があり、そのクエリの意味を説明してくれる。
上にいくほど処理が軽く、下に行くほど高コストとなっている。
上記の例ではselect * で指定をしているためALLになっている。
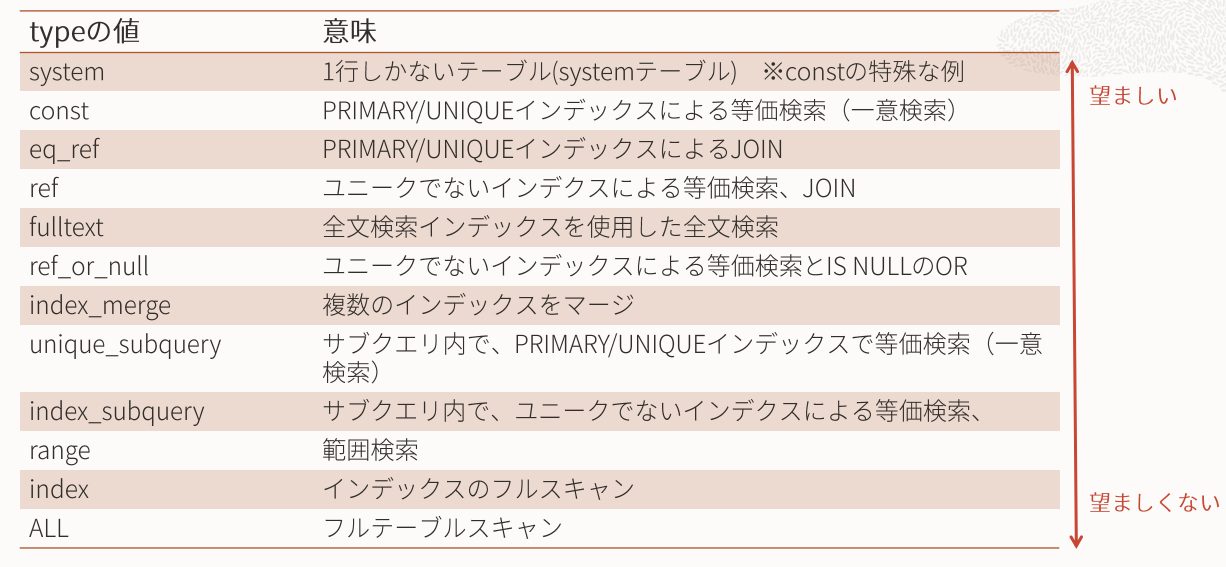
意味の欄に頻出するようにインデックスをいかに適切に使用するかがカギになる。
possible_keys
テーブルのアクセスに利用可能なインデックスの候補として挙げられるキーを表示してくれる
SHOW INDEX FROM table_nameにてインデックスが参照できるのでそこにないキーを指定された場合はインデックス検討の余地があると言える。
key
実際にインデックスとして参照されたカラムになる。
テーブルにインデックスが貼られていたとしてもこの値に含まれなければ使用できていないということになる。
SQLチューニングまとめ
1.インデックスが使えていないクエリはインデックスがないか検討
※更新処理はインデックスがある方が時間がかかる
2.JOINの工夫
・取得される行数が少ないテーブルから順番にjoinするのが基本
・3テーブル以上のjoinは結果セットが少量になるテーブルからjoin
終わりに
今回このセミナーに参加して、インデックスやjoinについては知っていたもののEXPLAINコマンドの便利さや、サーバ側のパラメータ設定などについては目からうろこだったので非常に勉強になりました。
最近遊びでテーブル作成をしたりしていたのでこの辺りの情報をしっかり自分でも触ってパフォーマンスの改善を自身で感じられるようになっていきたいです。