はじめに
本内容は以下と8割ぐらい同じです。Community Component版を使用しているのが相違点です。
Confluent PlatformはConfluent社が提供するApache Kafkaを中心としたプラットフォームです。Apache Kafkaに加えて、Schema Registry、Rest Proxyや運用ツール等が同梱されています。
商用版(Enterprise)とCommunity版があり、各ライセンスのコンポーネントの違いは以下のとおりです。
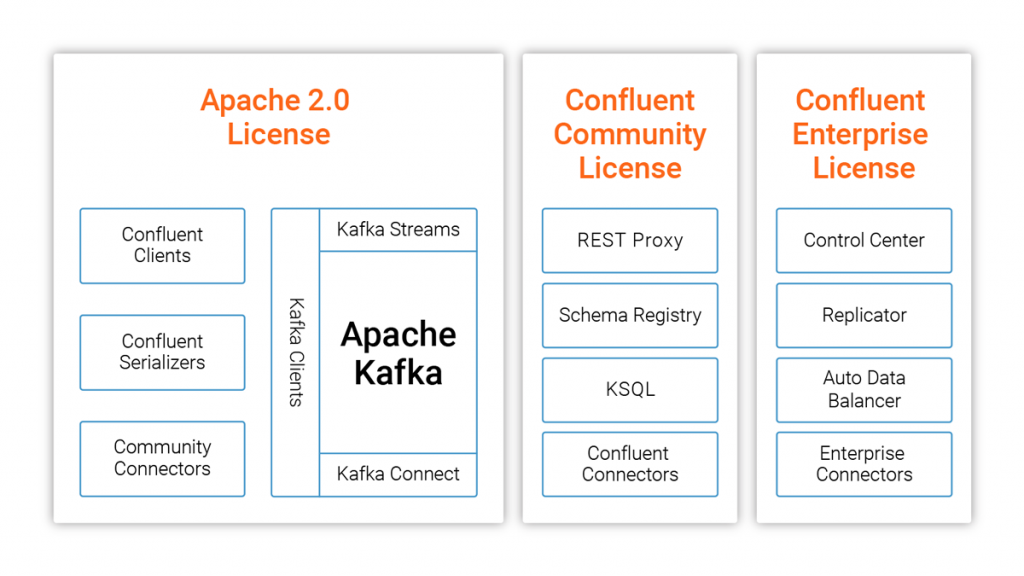
Confluent Community License FAQから引用
商用版は30日以内まで使用でき、30日を過ぎると商用機能が利用できなくなります。
ただし、Kafkaブローカーが1ノードの場合は無期限で利用できるそうです。
今回はCommunity版をインストールし、Kafka Connect(こっちが本当にやりたいこと)を利用してOracleのデータをKafkaへ配信することを試してみます。
Confluent Platformのダウンロード
まず、以下のインストール手順の「downloads page」のリンク先から、Confluent Platformのモジュールをダウンロードします。
リンクを飛んでいくと、以下のページに遷移し、「TAR archive」を選択してダウンロードします。
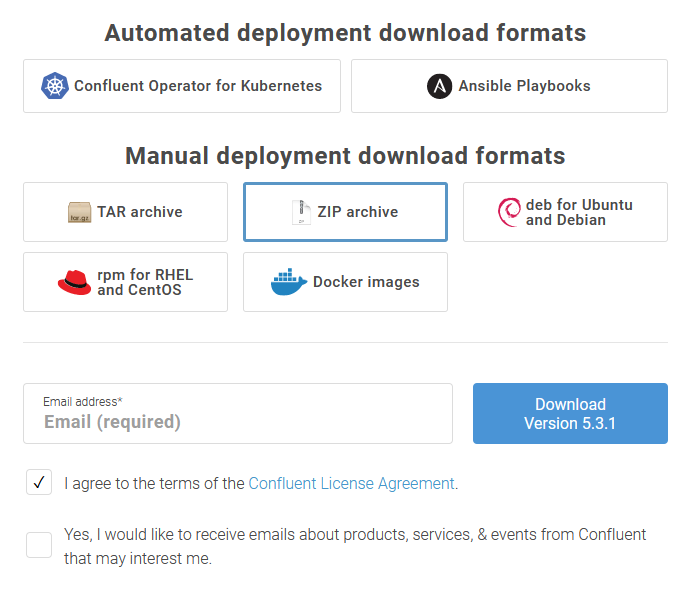
今回ダウンロードしたバージョンはv5.3.1で、ファイル名は「confluent-community-5.3.1-2.12.tar.gz」でした。
Confluent Platformのインストール
Confluent Platformのインストールは以下のページを参考に実施します。
今回はKafka Connectを試してみたいだけなので、localモード(?)という開発用のスタンドアローンで動作するモードで構築します。
インストール前に以下の手順でOpenJDK8をインストールしておきます。
# yum install java-1.8.0-openjdk-devel
# java -version
openjdk version "1.8.0_222"
OpenJDK Runtime Environment (build 1.8.0_222-b10)
OpenJDK 64-Bit Server VM (build 25.222-b10, mixed mode)
JAVA_HOMEを設定し、PATHにJavaのパスを追加しています。
# echo "export JAVA_HOME=$(readlink -e $(which java)|sed 's:/bin/java::')" > /etc/profile.d/java.sh
# echo "PATH=\$PATH:\$JAVA_HOME/bin" >> /etc/profile.d/java.sh
# source /etc/profile
次にconfluent-community-5.3.1-2.12.tar.gzを/opt以下に展開します。
# tar xvzf /tmp/confluent-community-5.3.1-2.12.tar.gz -C /opt
Confluent CLIをインストール
スタンドアローンで動作させる際に使用するconfluent localコマンドを利用するため、Confluent CLIをインストールします。
# curl -L https://cnfl.io/cli | sh -s -- -b /opt/confluent-5.3.1/bin
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 162 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 10113 100 10113 0 0 6247 0 0:00:01 0:00:01 --:--:-- 9875k
confluentinc/cli info checking S3 for latest tag
confluentinc/cli info found version: latest for latest/linux/amd64
confluentinc/cli info installed /opt/confluent-5.3.1/bin/confluent
confluentinc/cli info please ensure /opt/confluent-5.3.1/bin is in your PATH
Confluent binディレクトリをPATHに追加
Confluent binディレクトリのインストール場所をPATHに追加します。
# echo "export PATH=/opt/confluent-5.3.1/bin:$PATH" >> /etc/profile.d/confluent.sh
# source /etc/profile
Confluent Platformを起動
confluent local startコマンドを使用してConfluent Platformを起動します。
このコマンドにより、Kafkaだけではなく、Kafka Connect、KSQLなどの全てのConfluent Platformのコンポーネントが起動します。
なお、商用版ではないのでConfluent Control Centerは使用できません。
$ confluent local start
The local commands are intended for a single-node development environment
only, NOT for production usage. https://docs.confluent.io/current/cli/index.html
Using CONFLUENT_CURRENT: /tmp/confluent.2ACJxXld
Starting zookeeper
zookeeper is [UP]
Starting kafka
kafka is [UP]
Starting schema-registry
schema-registry is [UP]
Starting kafka-rest
kafka-rest is [UP]
Starting connect
connect is [UP]
Starting ksql-server
ksql-server is [UP]
Oralce JDBCドライバのインストール
Oralce JDBCドライバ(ojdbc8.jar)をOracleのサイトからダウンロードし、以下のように格納します。
- /opt/confluent-5.3.1/share/java/kafka-connect-jdbc/ojdbc8.jar
次にKafka connectを再起動します。
# confluent local stop connect
The local commands are intended for a single-node development environment
only, NOT for production usage. https://docs.confluent.io/current/cli/index.html
Using CONFLUENT_CURRENT: /tmp/confluent.2ACJxXld
Stopping connect
connect is [DOWN]
# confluent local start connect
The local commands are intended for a single-node development environment
only, NOT for production usage. https://docs.confluent.io/current/cli/index.html
Using CONFLUENT_CURRENT: /tmp/confluent.2ACJxXld
zookeeper is already running. Try restarting if needed
kafka is already running. Try restarting if needed
schema-registry is already running. Try restarting if needed
Starting connect
connect is [UP]
ロード元のテーブル作成
データロード元のOracleのテーブルを作成します。
以下のようにemtestテーブルを作成しています。
noカラムは連番のデータを格納し、Kafka Connectでincrementalにデータをロードするためのキーになります。
CREATE TABLE emtest
(
no NUMBER(3,0),
name VARCHAR2(50),
update_at TIMESTAMP(0)
);
Kafka Connectorを作成
JdbcSourceConnectorを使用して、OracleからKafkaへデータをロードするように設定します。
JdbcSourceConnectorはJDBCでデータベースからデータをロードするためのConnectorで、(たぶん)Oracle以外にもPostgreSQL等で使用できます。
まず、JdbcSourceConnector用の設定ファイルを作成します。
ファイルはどこで作成しても良いのですが、それっぽいところ(/opt/confluent-5.3.1/etc/kafka-connect-jdbc)に作成しました。
# cd /opt/confluent-5.3.1/etc/kafka-connect-jdbc
# vi source-oracle.properties
設定ファイルの内容は以下のとおりです。
{
"name": "TestOracle",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:oracle:thin:@192.168.10.232:1521:testdb",
"connection.user": "hr",
"connection.password": "hr",
"table.whitelist": "EMTEST",
"mode": "incrementing",
"incrementing.column.name": "NO",
"validate.non.null": "false",
"topic.prefix": "test."
}
}
modeは増分をロードするようにするため、incrementingを設定しています。
incrementing.column.nameでは、増分を判断するキーを指定します。
topic.prefixで、トピック名のプレフィックスを指定します。ここでは"test."を指定しており、トピック名はテーブル名を付与した、"test.EMTEST"が自動で作成されます。
kafkaにロードされたメッセージはデフォルトでAvroフォーマットになります。
Stringにするなら、Converterに「org.apache.kafka.connect.storage.StringConverter」を指定します。
作成した設定ファイルをKafka Connectに以下のコマンドで登録します。
# curl -X POST -H "Content-Type: application/json" --data @source-oracle.json http://localhost:8083/connectors
{"name":"TestOracle","config":{"connector.class":"io.confluent.connect.jdbc.JdbcSourceConnector","connection.url":"jdbc:oracle:thin:@192.168.10.232:1521:testdb","connection.user":"hr","connection.password":"hr","table.whitelist":"EMTEST","mode":"incrementing","incrementing.column.name":"NO","validate.non.null":"false","topic.prefix":"test.","name":"TestOracle"},"tasks":[],"type":"source"}
ここでkafkaにパブリッシュされたメッセージを確認するために、kafka-avro-console-consumerコマンドを使用します。
Avroフォーマットでない場合は、kafka-console-consumerコマンドを使用します。
$ confluent local consume test.EMTEST -- --value-format avro --from-beginning
ここでEMTESTテーブルにインサートすると、以下のようにkafkaに格納されたメッセージを取得しコンソールに表示されます。
$ confluent local consume test.EMTEST -- --value-format avro --from-beginning
{"NO":{"bytes":"\u0015"},"NAME":{"string":"CCCC"},"UPDATE_AT":{"long":1569248672000}}
ログを確認(参考)
Connectのログは以下のコマンドで確認できるようです。
confluent local log connect
Confluentを終了する
Confluentを終了するためには、confluent local stopコマンドを使用します。
$ confluent local stop
The local commands are intended for a single-node development environment
only, NOT for production usage. https://docs.confluent.io/current/cli/index.html
Using CONFLUENT_CURRENT: /tmp/confluent.2ACJxXld
Stopping ksql-server
ksql-server is [DOWN]
Stopping connect
connect is [DOWN]
Stopping kafka-rest
kafka-rest is [DOWN]
Stopping schema-registry
schema-registry is [DOWN]
Stopping kafka
kafka is [DOWN]
Stopping zookeeper
zookeeper is [DOWN]
「confluent local destroy」を使用すると環境全てを破棄するようです(使用していないのでよく分かりません)