概要
Railsでは has_many, belongs_to の関連をよく書くのでしっかり脳で覚えているのですが、
has_many through を使った多対多の関連はたまにしか書かないためくよく忘れてしまいます。
なので個人の備忘録としても、理解をしてより覚えるためにも図でまとめました。
例
- Railsチュートリアルでもよく使われている、Twitterのようなサービスを例にした「ユーザの相互フォロー」を記載していきます
- ユーザAさんは複数のユーザをフォローできます
- ユーザAさんは複数のユーザにフォローされます
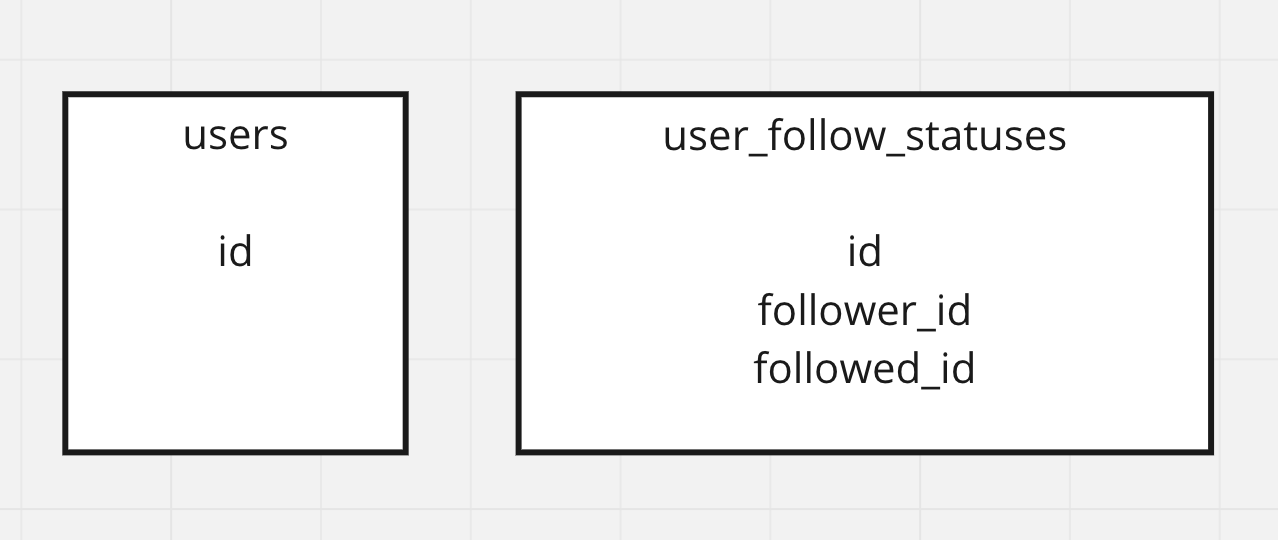
テーブル構造
- ユーザ情報(users)
- ユーザのフォロー関連(user_follow_statuses)
コード
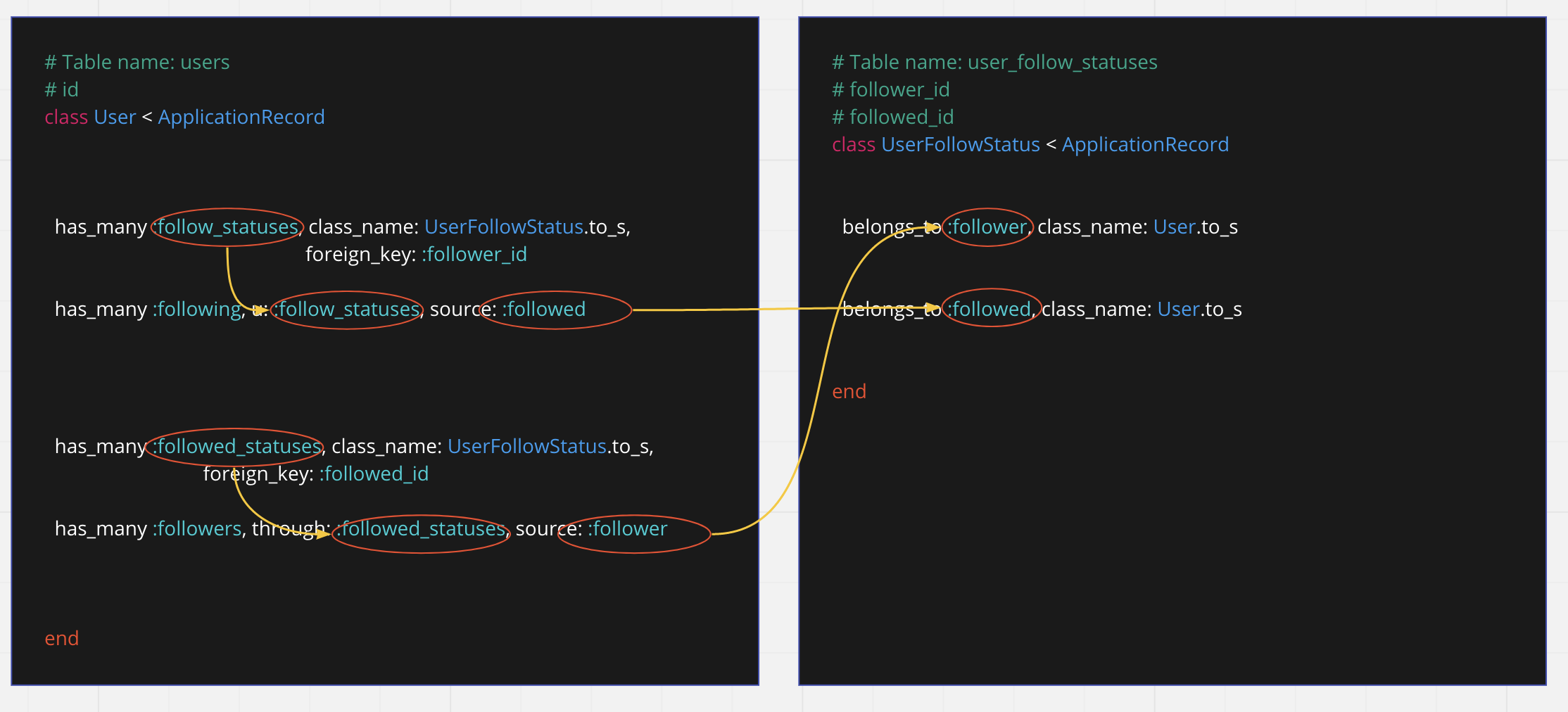
class User < ApplicationRecord
has_many :follow_statuses, class_name: UserFollowStatus.to_s,
foreign_key: :follower_id,
# 自分がフォローしているユーザたち
has_many :following, through: :follow_statuses, source: :followed
has_many :followed_statuses, class_name: UserFollowStatus.to_s,
foreign_key: :followed_id,
# 自分がフォローされているユーザたち
has_many :followers, through: :followed_statuses, source: :follower
end
class UserFollowStatus < ApplicationRecord
belongs_to :follower, class_name: User.to_s
belongs_to :followed, class_name: User.to_s
end
図
AさんがBさんをフォローしている
- 以下のような関係になる
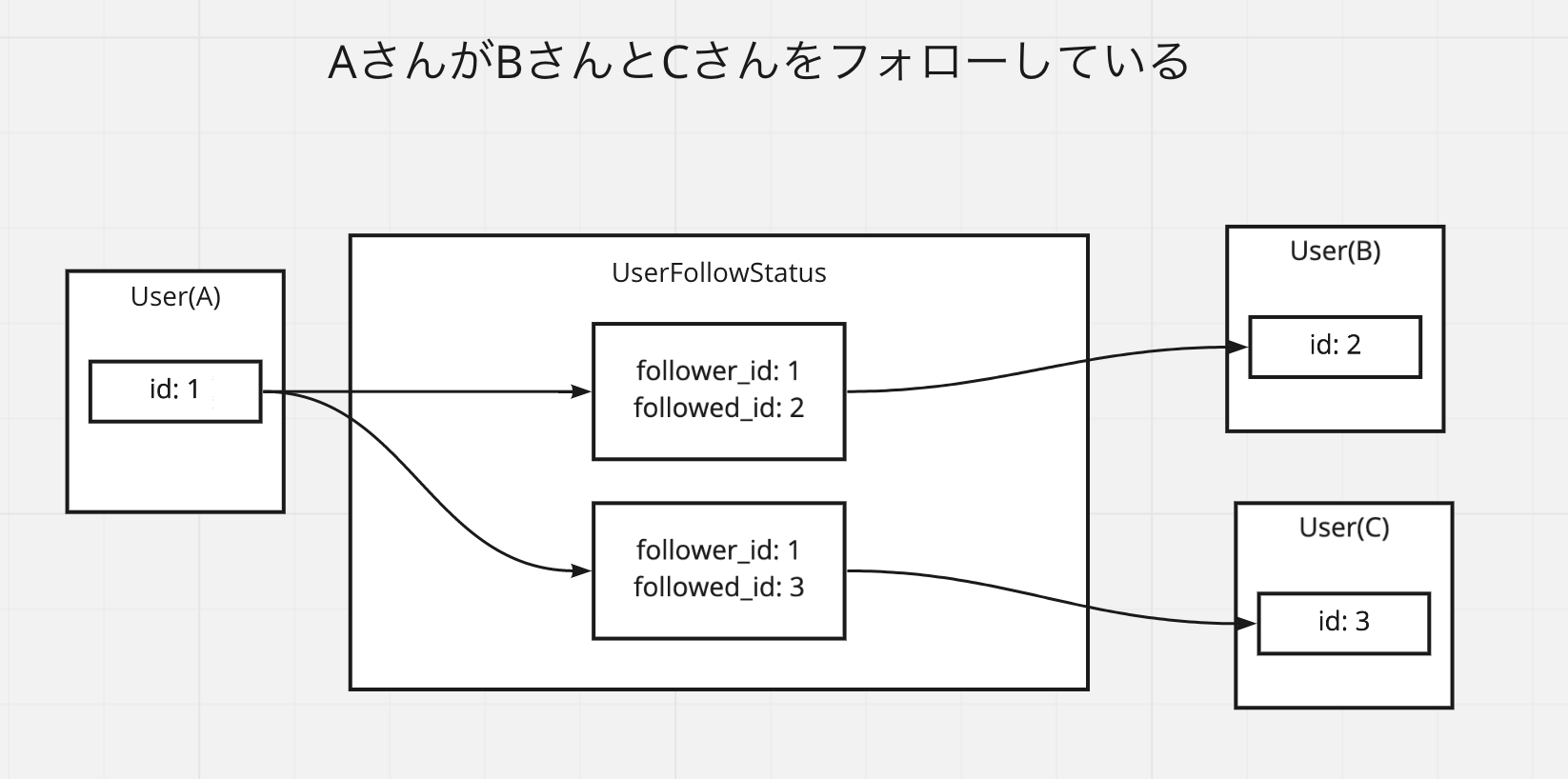
このとき以下のようなプログラムでそれぞれフォローしている相手、されている相手を取得できるようになる。
# Aさんがフォローしているユーザたち
user(A).following
# => [UserB, UserC]
# Bさんがフォローされているユーザたち
user(B).followers
# => [UserA]
なるけど、これを今暗記・コードを使い回す状態なのでもう少し整理する。
プログラムの関連
プログラムを並べるとこういう関係性になる。ちょっとわかるようで分からない…。
順序よく考える
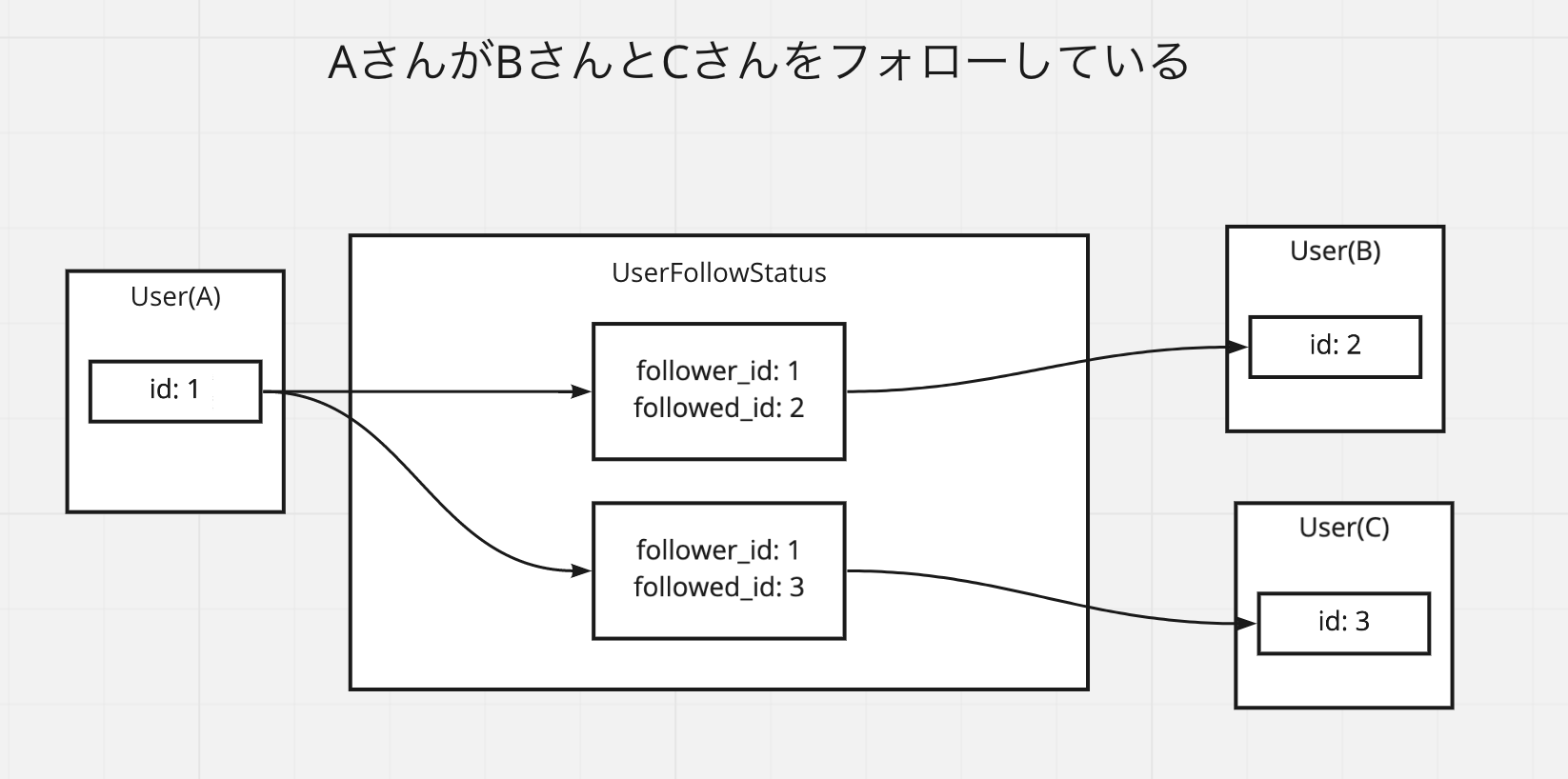
AさんがB,Cさんをフォローしているという状況
AさんがB,Cさんをフォローしているという状況を考える。
データは以下のように作成される。
これを has_many, belongs_to の2つだけを使ってまとめると以下になる
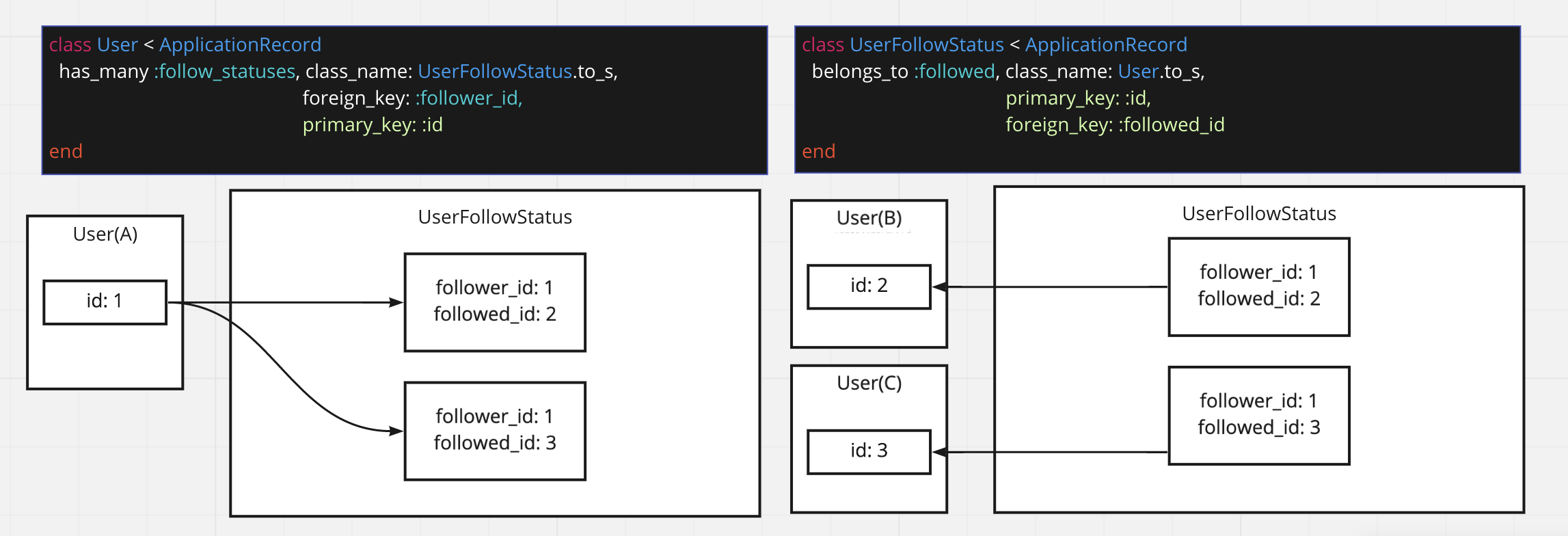
※緑色の字はRailsの命名規則に従っていれば省略可能なものですが、理解を深めるためにあえて記載しています
このときAさんがフォローしているB,Cさんを取得するには以下のプログラムを書けば良い
# 自分がフォロー側になっている関連データを取得
user.follow_statuses.map do |follow_status|
# 各データのフォロー先のユーザのデータを取得
follow_status.followed
end
# => [UserB, UserC]
この処理で発行されるSQLは下記
-- AさんのユーザIDである 1 が follower_id に設定されているデータ一覧を取得
UserFollowStatus Load (0.6ms) SELECT `user_follow_statuses`.* FROM `user_follow_statuses` WHERE `user_follow_statuses`.`follower_id` = 1
-- 取得されたデータの followed_id に入っているユーザID(Bさんの2, Cさんの3)でユーザデータを取得
User Load (0.7ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 2 LIMIT 1
User Load (0.7ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 3 LIMIT 1
※N+1問題が発生していますがわかりやすさのためそのままにしています
これを has_many through を利用すると以下のようにまとめられる
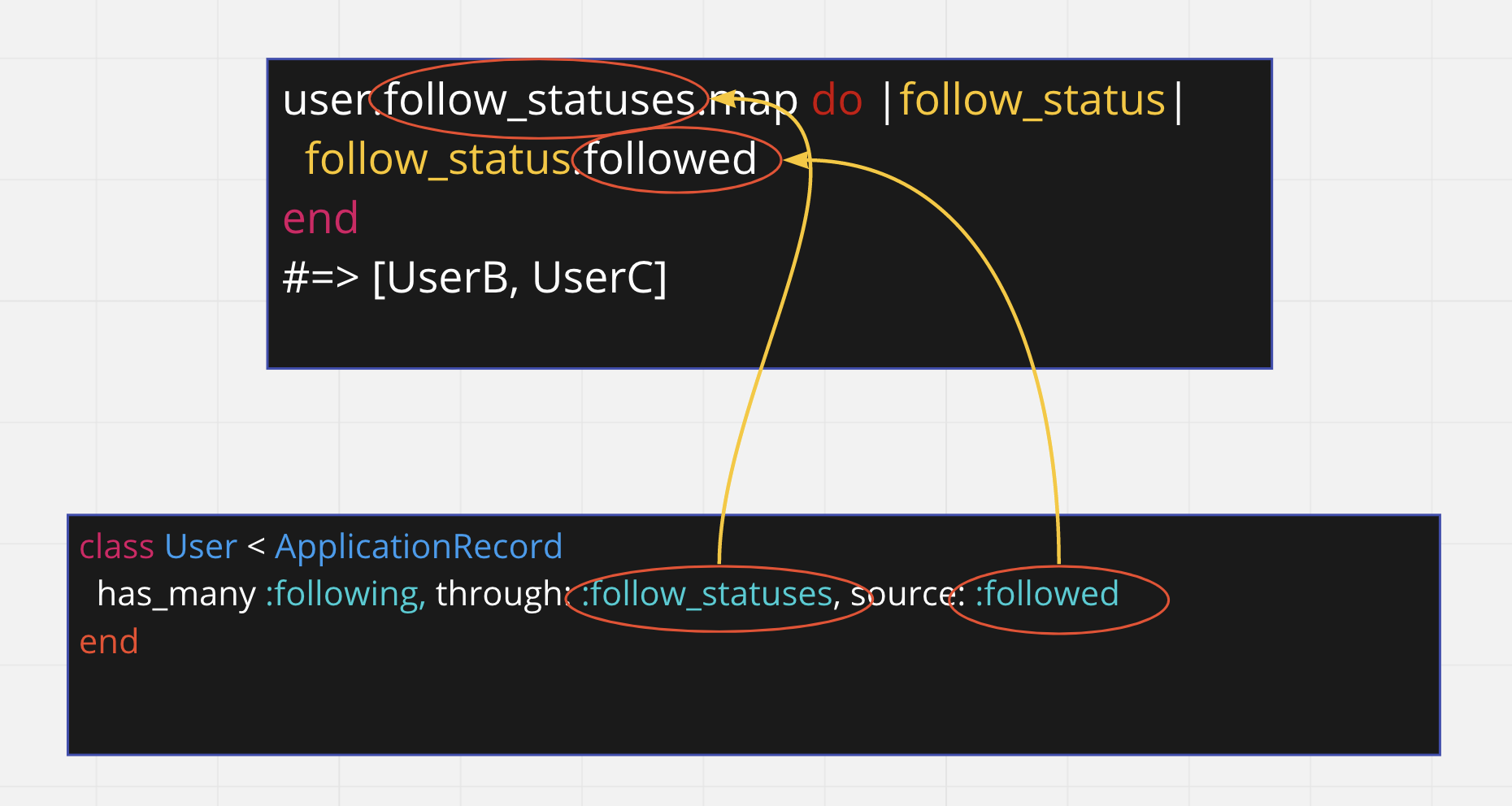
つまり has_many で定義している follow_statuses を経由(through)して、
そこからさらに各データの followed で定義されている先のデータを取得している、といえる。
この定義により
# Aさんがフォローしているユーザたち
user(A).following
# => [UserB, UserC]
という簡潔にプログラムが記載できるようになる。
このとき発行されるSQLは下記のようになる。
SELECT `users`.* FROM `users` INNER JOIN `user_follow_statuses` ON `users`.`id` = `user_follow_statuses`.`followed_id` WHERE `user_follow_statuses`.`follower_id` = 1
これは単純に 簡潔になる だけではなく、以下のようなメリットも受けることができる
- N+1問題など気にしなくてもSQLの発行がすくなくなりDBのアクセス負荷を減らせる
- 戻り値が
ActiveRecord_Associations_CollectionProxyになり、クエリのメソッドチェーンができる
BさんがA,Cさんにフォローされているという状況
次にフォローされている状況を考える。
BさんはA,Cさんにフォローされている、とする。
データは以下のように作成される。
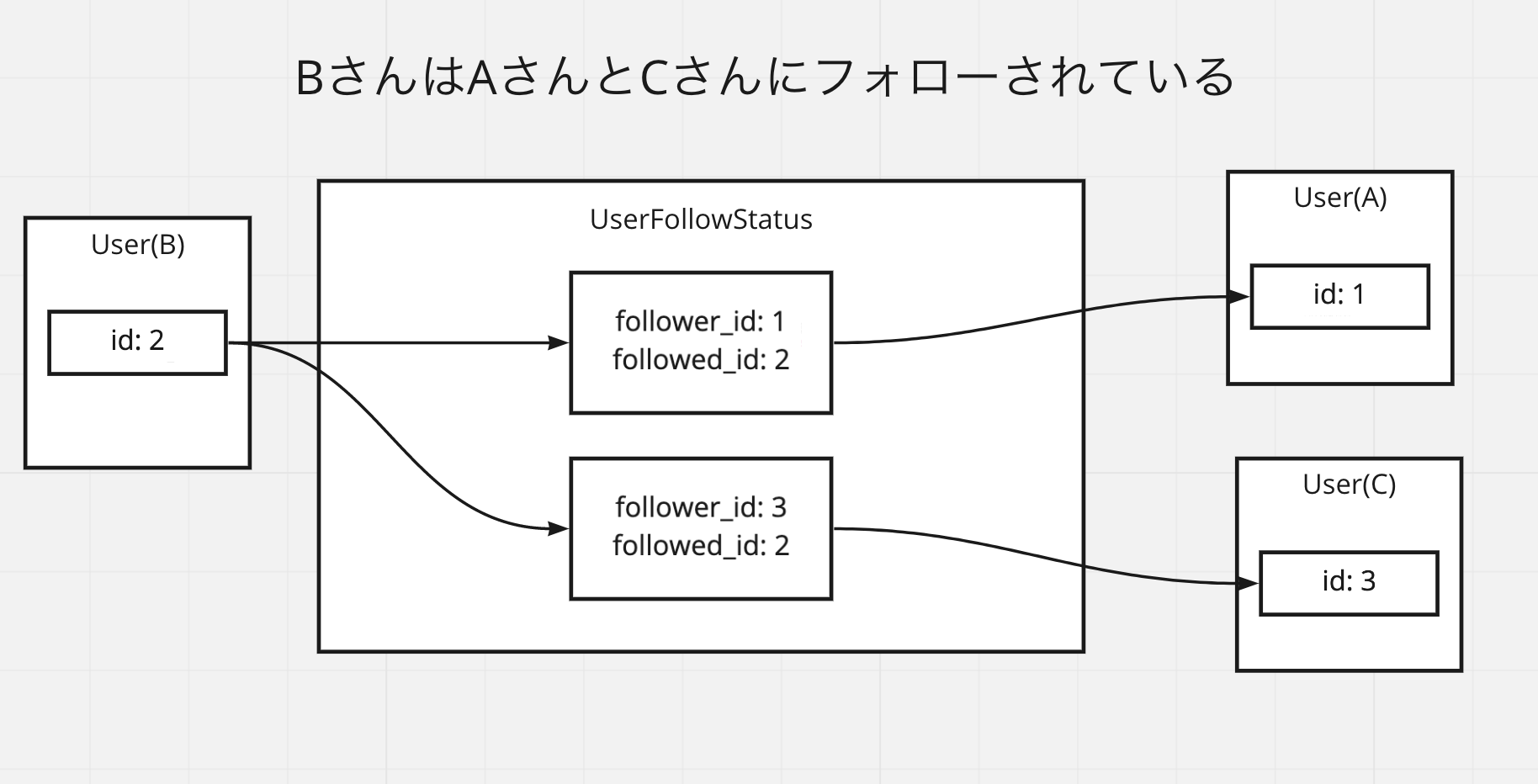
これを has_many, belongs_to の2つだけを使って考えると以下になる
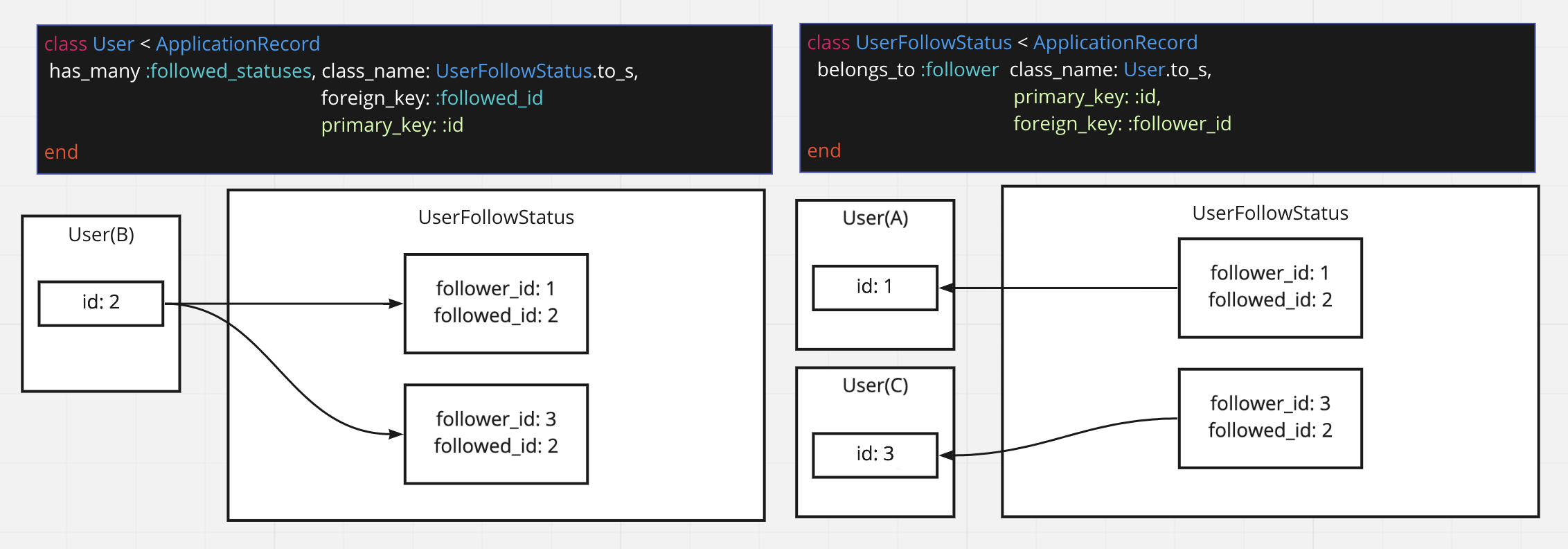
※緑色の字はRailsの命名規則に従っていれば省略可能なものですが、理解を深めるためにあえて記載しています
このときBさんがフォローされているA,Cさんを取得するには以下のプログラムを書けば良い
# Bさんがフォローされている側の関連テーブルのデータを取得
user.followed_statuses.map do |followed_status|
# フォローしているユーザのデータを取得
follow_status.follower
end
# => [UserA, UserC]
この処理で発行されるSQLは下記
-- BさんのユーザIDである 2 が followed_id に設定されているデータ一覧を取得
UserFollowStatus Load (0.9ms) SELECT `user_follow_statuses`.* FROM `user_follow_statuses` WHERE `user_follow_statuses`.`followed_id` = 2
-- 取得されたデータの follower_id に入っているユーザID(Aさんの1, Cさんの3)でユーザデータを取得
User Load (1.0ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 1 LIMIT 1
User Load (0.9ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 3 LIMIT 1
※N+1問題が発生していますがわかりやすさのためそのままにしています
これも同様に has_many through を利用すると以下のようにまとめられる
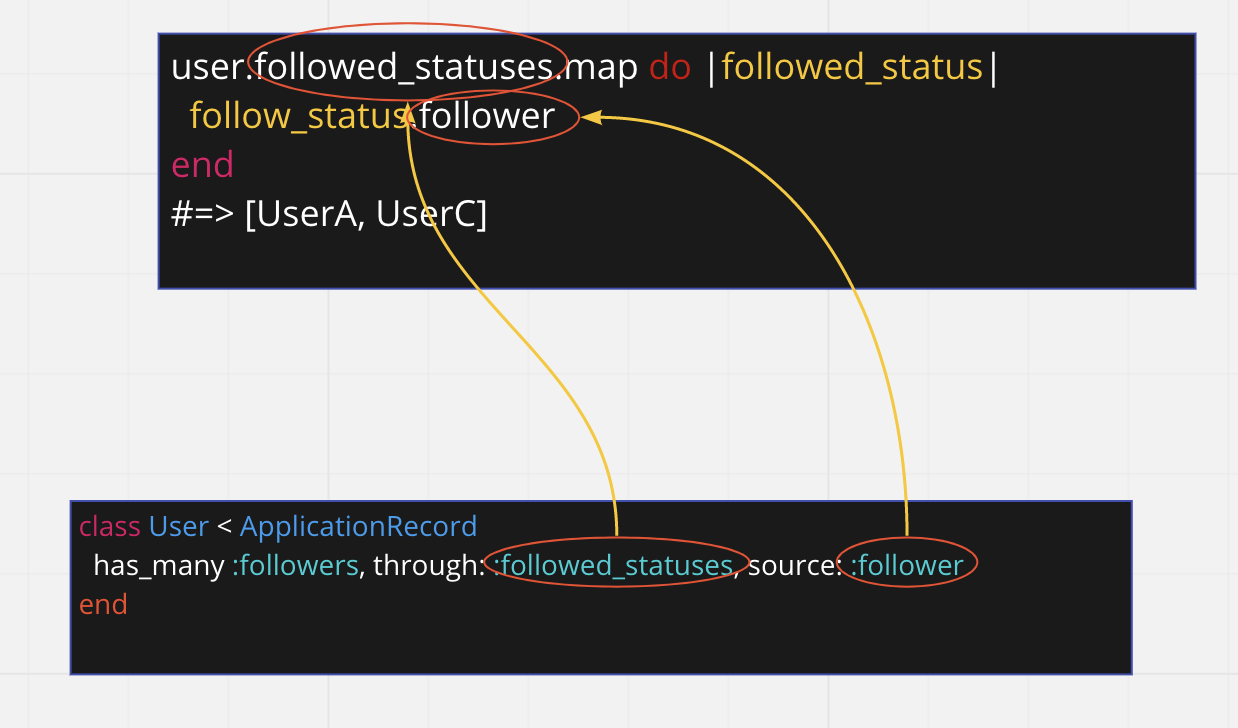
よって
# Bさんがフォローされているユーザたち
user(B).followers
# => [UserA, UserC]
という簡潔にプログラムが記載できるようになる。
このとき発行されるSQLは下記のようになる。
SELECT `users`.* FROM `users` INNER JOIN `user_follow_statuses` ON `users`.`id` = `user_follow_statuses`.`follower_id` WHERE `user_follow_statuses`.`followed_id` = 2
こちらもフォローのときと同じようにメリットを受けられる
ということでこれらをひっくるめて冒頭のコードが出来上がるし、以下のような関連の図ができあがる
応用: 条件を付ける
さらに応用としてユーザのフォローに種別を追加する。
例えばこのフォローに「名前のみ閲覧可能」「投稿も閲覧可能」というタイプを持たせる。
以下がデータベースのテーブル構造。
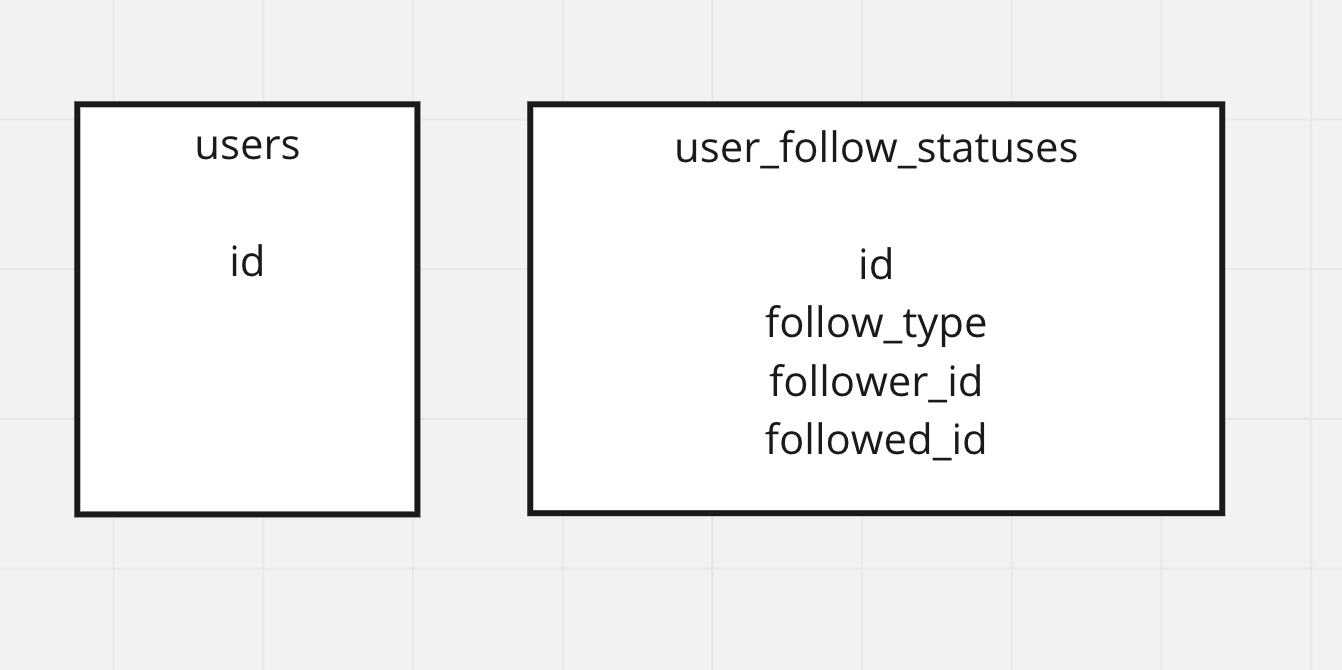
- follow_type: 0=名前のみ閲覧可能
- follow_type: 1=投稿も閲覧可能
とする。
このとき「名前のみ閲覧可能なフォローしているユーザ一覧」の関連を定義する
コード
class User < ApplicationRecord
has_many :name_only_follow_statuses, -> { where(follow_type: 0) },
class_name: UserFollowStatus.to_s,
foreign_key: :follower_id,
primary_key: :id
has_many :name_only_following, through: :name_only_follow_statuses, source: :followed
end
順序よく考える
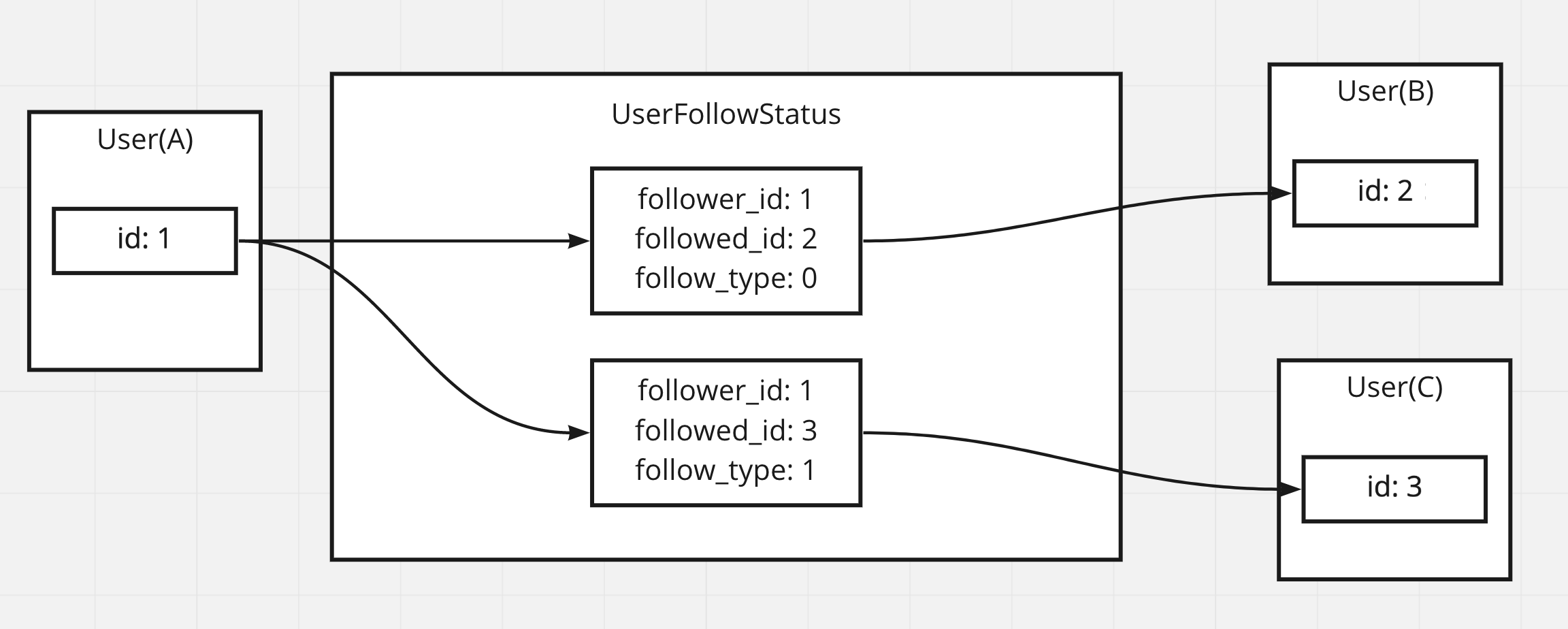
- AさんがB,Cさんをフォローしている
- Bさんは名前のみ閲覧可能(typeが0)
- Cさんは投稿も閲覧可能(typeが1)
データは以下のように作成される。
これも同様に has_many, belongs_to の2つだけを使ってこの関連を考えると以下になる

※has_many には条件をブロックオブジェクトで渡すことができる
※belongs_to 側は応用前と変更がないので省略
同様にこれをそのままプログラムで書くと以下のようになる
user.name_only_follow_statuses.map do |followed_status|
followed_status.followed
end
# => [UserB]
発行されるSQLは下記。
-- ユーザAのidである1が follower_id にあるものを検索
-- かつ follow_typeが0(=名前だけ閲覧可能)のデータだけを検索
UserFollowStatus Load (1.0ms) SELECT `user_follow_statuses`.* FROM `user_follow_statuses` WHERE `user_follow_statuses`.`follower_id` = 1 AND `user_follow_statuses`.`follow_type` = 0
-- 取得した結果であるユーザB(idが2)のユーザデータを取得
User Load (0.7ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 2 LIMIT 1
これを has_many through を利用すると以下のようにまとめられる
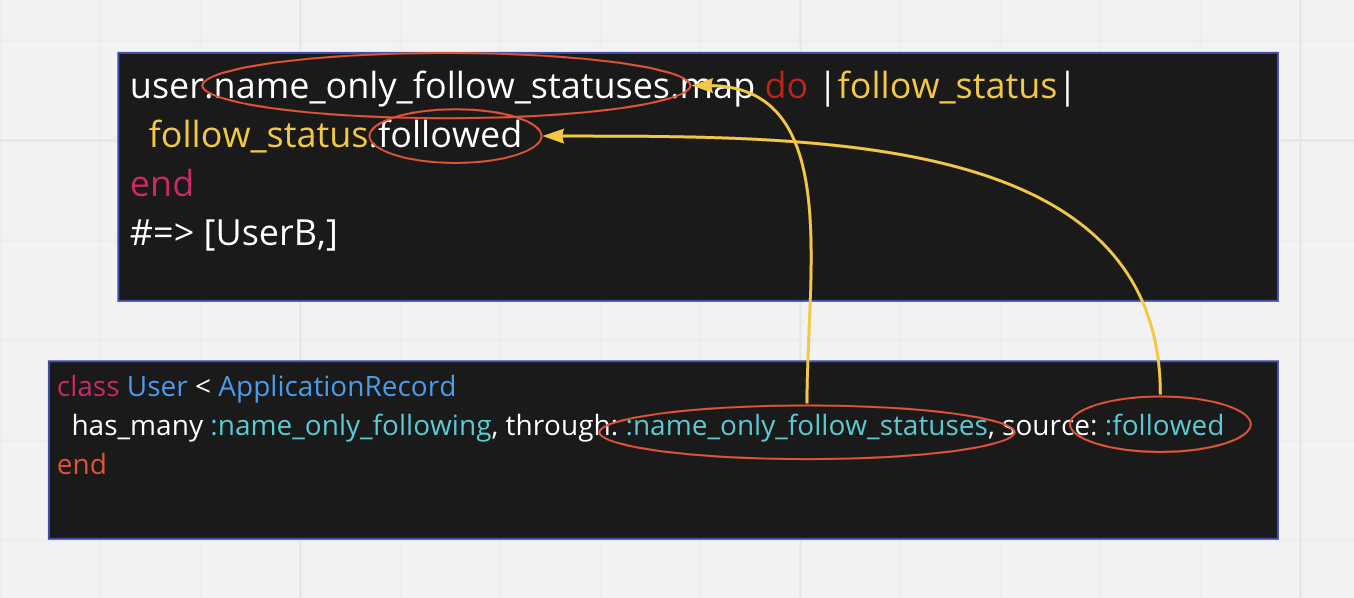
よって
# Aさんが名前のみ閲覧可能でフォローしているユーザたち
user(A).name_only_following
# => [UserB]
という簡潔にプログラムが記載できるようになる。
このとき発行されるSQLは下記のようになる。
SELECT `users`.* FROM `users` INNER JOIN `user_follow_statuses` ON `users`.`id` = `user_follow_statuses`.`followed_id` WHERE `user_follow_statuses`.`follower_id` = 1 AND `user_follow_statuses`.`follow_type` = 0
ということで、以下の2ステップで条件付きの多:多も可能となる
- 1.関連テーブルになる関連先に条件を付けた、新しい has_many を定義
- 2.上記1で定義した関連で has_many through を定義する
Tips
- この関連テーブルのリレーションは基本的に
dependent: :destroyを付けておいた方が良いよ!
まとめ
- 多:多はそんなに怖くない!(と思う)