1. はじめに
- 社内にナレッジベースがあり、文書の検索にはキーワードによる全文検索などを使用しているが、なかなか目的の情報が見つけられないという課題がある。
- 検索性を高める方法の検討のため、予め蓄積したデータに対して自然言語で検索できる仕組みである「Knowledge base for Amazon Bedrock」を試用し、どんな感じで検索できるのかを確認する。
2. やったこと
- 今回は練習のため、聖闘士星矢に関する文書(Wikipediaから)をS3に保存する。
- Knowledge base for Amazon Bedrockを作成し、保存した文書に対するベクトルデータベースを作成し、自然言語検索を可能にする。
- Lambda functions URLを作成し、インターネット経由での検索を可能にする。
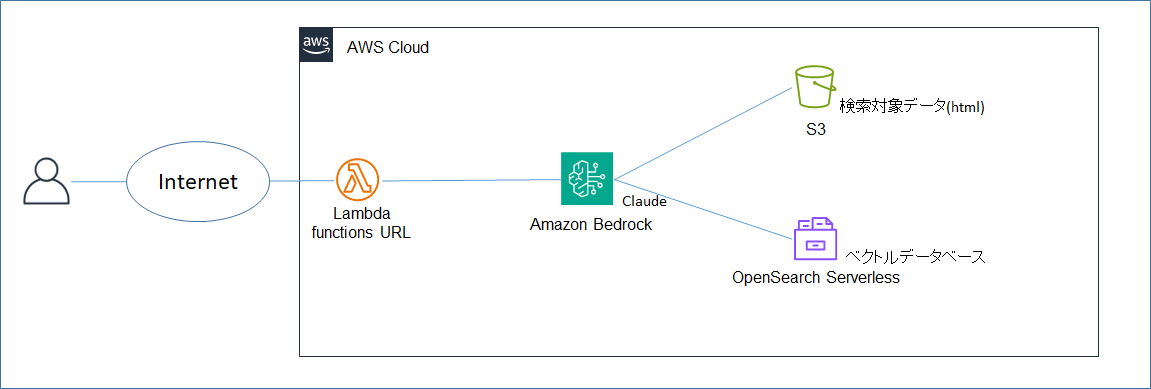
3. 構成図
4. 手順
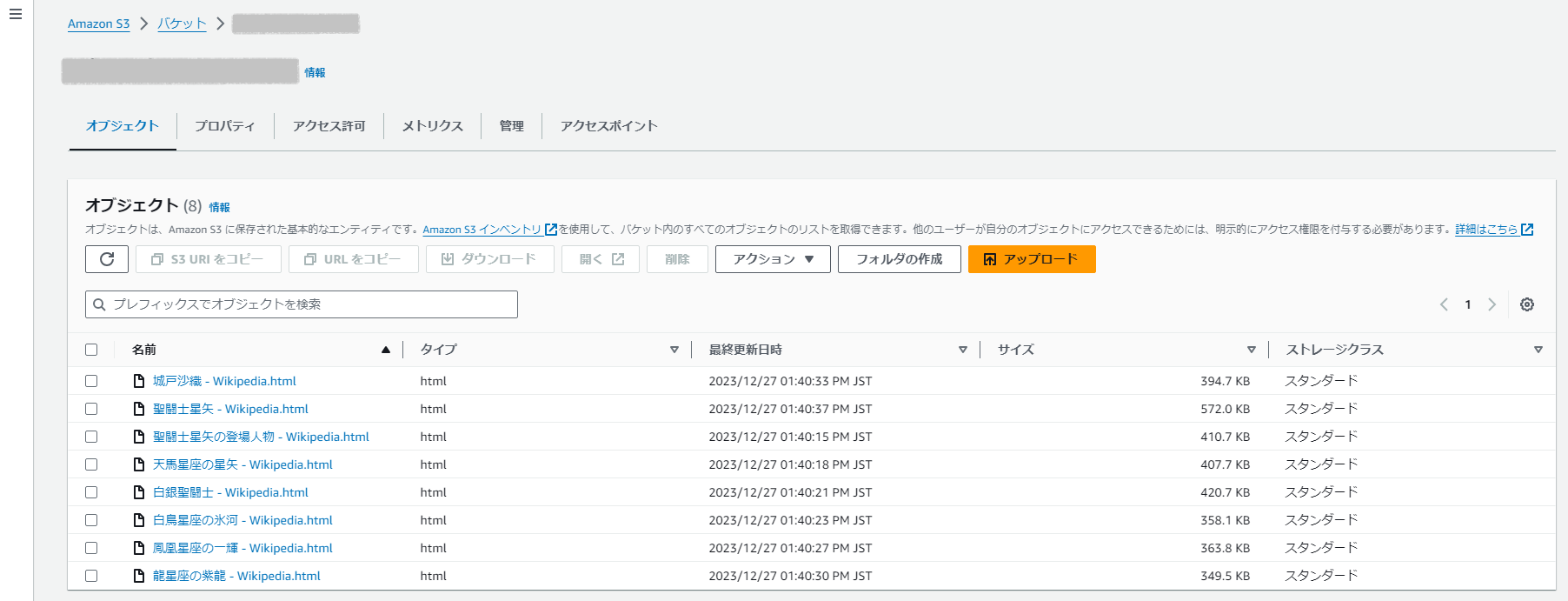
4.1 S3に文書を保存
- 検索対象とする文書をS3バケットに保存する。wikipediaの聖闘士星矢に関する主要なページ(トップページ及び主要人物のページなど。html形式)を8個保存する。
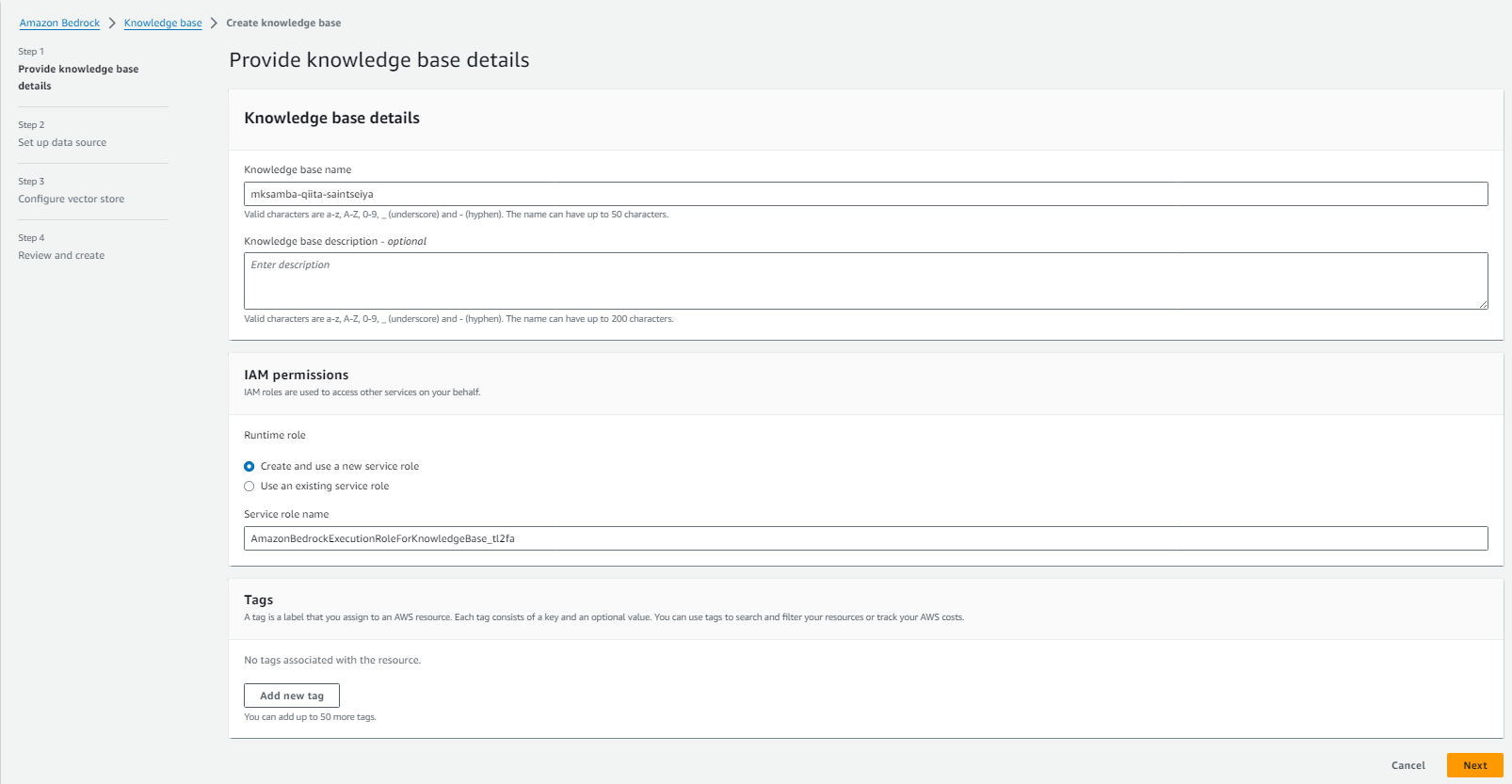
4.2 Knowledge base for Amazon Bedrock の作成
-
Knowledge base for Amazon Bedrock を作成する。2023/12時点で北バージニア(us-east-1)とオレゴン(us-west-2)のみ利用可能。今回はオレゴン(us-west-2)で作成している。
-
Amazon Bedrock > Knowledge base -> Create knowledge base で、Knowledge baseを作成する。最初に名前を指定し、ロールは新規作成する。
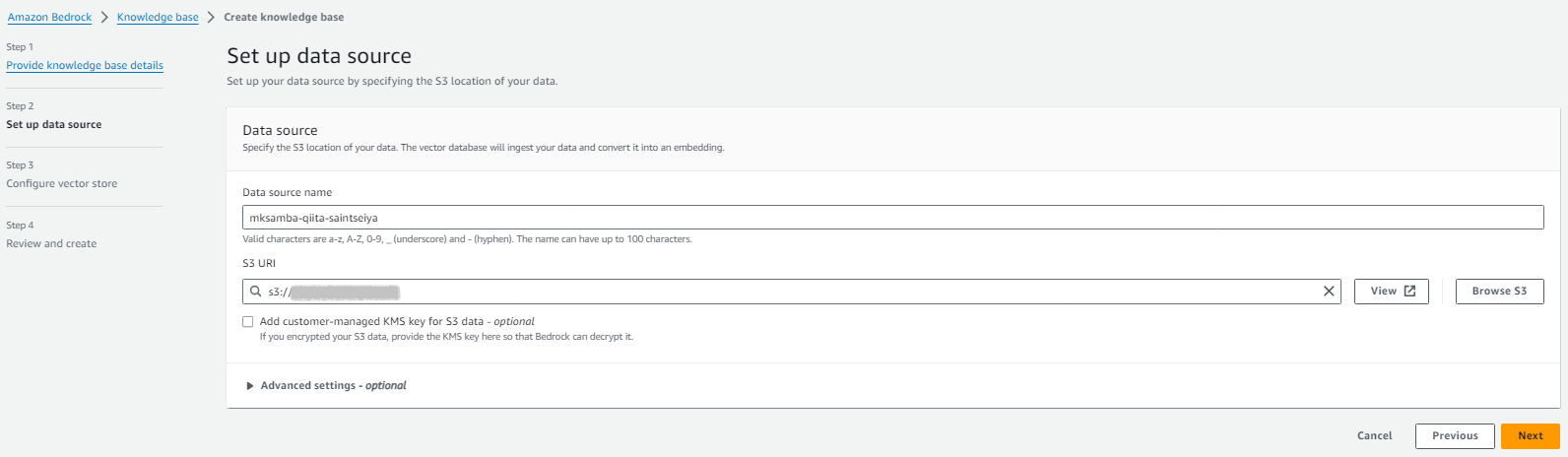
- 検索対象文書を入れたS3バケットを指定する。
-
Vector Databaseの作成方法を指定する。デフォルトでは OpenSearch Serverless が自動で使用される。
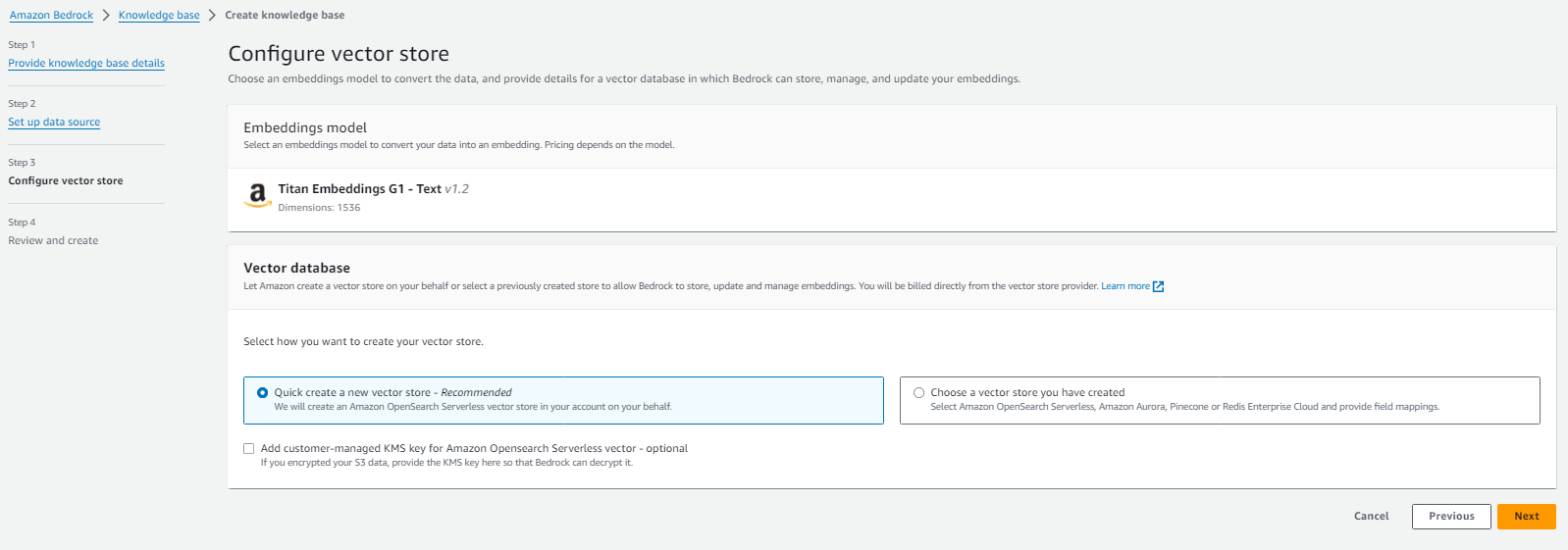
-
内容を確認してCreateすると、Knowledge base for Bedrock 及び OpenSearch Serverlessのリソースが作成される。
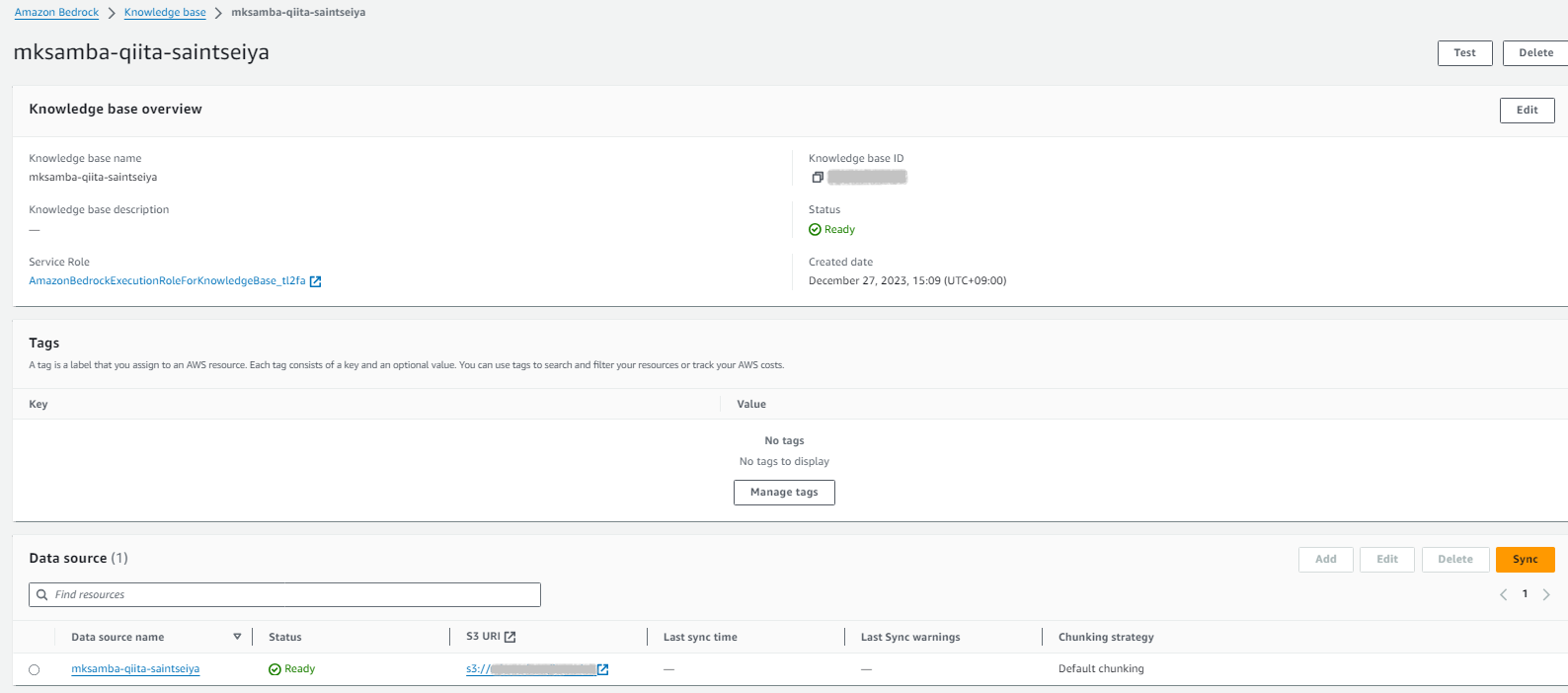
- 初回の「Sync」を行い、データを同期させる。8個のファイルが認識されていることを確認する。

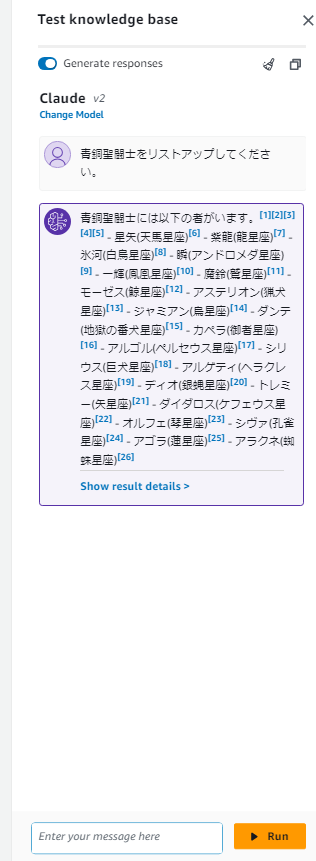
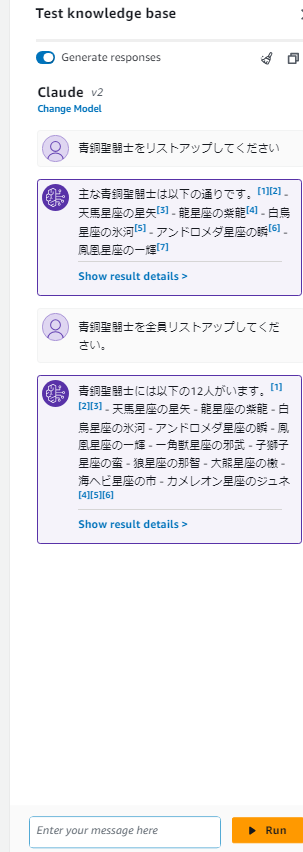
- マネコン上でQ&Aを試してみる。「Test knowledge base」から、モデルで「Claude v2」を選択し、質問文を入力する。「青銅聖闘士をリストアップしてください」の質問に対して、情報が不十分なため白銀聖闘士が混ざった回答となってしまった。
4.3 検索対象データの更新
- Wikipediaの「青銅聖闘士」のページを追加でダウンロードし、S3に保存し、再度Syncを行う。

- 同じ質問をすると、今度は正確な回答が得られた。
4.4 Lambda Functions URLの作成
- このままだとマネコンの中でしか検索ができないため、インターネット経由でアクセス可能とするように、Lambda Functions URL を作成する。
- LambdaからKnowledge base for Amazon Bedrock を呼び出す方法については、こちらの記事「BedrockのKnowledge base、OpenSearch Serverless、S3、Lambdaを利用し、RAGを実装してみた #AWSreInvent」を参照した。
- ポイントとしては以下の通り。(詳細はリンク先の記事を参照)
- Lambda関数にBedrockを操作できる権限(IAMロール)を付与する。
- そのままだとboto3が古くてbedrockの呼び出しができないため、boto3をLayerでインポートする。
- 回答の生成に20秒くらいかかるため、タイムアウトはそれなりに延ばしておく。
- 今回、オレゴン(us-west-2)を使用しているが、Claude v2が使用できず、やむを得ずClaude Instant v1を指定する。
- Functions URLを有効にして、ブラウザから質問を入力できるようにしたコードの内容は以下の通り。
lambda_function.py
import boto3
import json
bedrock_agent_runtime_client = boto3.client('bedrock-agent-runtime')
def lambda_handler(event, context):
question = event.get('queryStringParameters', {}).get('question')
print(question)
# 自分のKnowledge Base IDを指定
knowledge_base_id = 'XXXXXXXXXX'
# BedrockのモデルにはClaude instant v1を使用
modelArn = 'arn:aws:bedrock:us-west-2::foundation-model/anthropic.claude-instant-v1'
prompt = f"""
以下の質問に日本語で回答してください。
【質問】
{question}
"""
response = bedrock_agent_runtime_client.retrieve_and_generate(
input={
'text': prompt,
},
retrieveAndGenerateConfiguration={
'type': 'KNOWLEDGE_BASE',
'knowledgeBaseConfiguration': {
'knowledgeBaseId': knowledge_base_id,
'modelArn': modelArn,
}
}
)
#回答の部分のみを抽出
print("Received response:" + json.dumps(response, ensure_ascii=False))
answer = response['output']['text']
htmlbase1 = """
<html lang="ja">
<head>
<meta charset="UTF-8">
<title>Question</title>
</head>
<body>
"""
# フォームの送信先として自分(Functions URL)を指定
htmlbase2 = """
<form action="https://xxxxxxxxxxxxxxxxxxxx.lambda-url.us-west-2.on.aws/" method="get">
<label>question</label><br>
<input type="name" name="question" style="width:300px; height:60px;"><br>
<input type="submit" value="SEND">
</form>
</body>
</html>
"""
html = htmlbase1 + answer + htmlbase2
return {
'statusCode': 200,
'headers': {
'Content-Type': 'text/html',
},
'body': html,
}
- ブラウザからFunctions URLのURLにアクセスして、インターネット経由で質問の入力及び回答の表示が可能。(Claude Instant v1に変更したせいか回答内容がマネコンでの作業時とは異なる)
(質問の入力)

(回答の表示)

5. 所感
- ある程度正確な、意味のある回答が得られ、結構実用レベルなのかなと感じた。社内ドキュメントをデータソースとして、業務として活用することに取り組みたい。