1. はじめに
- re:Invent 2024 で発表された新サービスで、業務に役立ちそうなものを検証したい。
- AWS上のシステムに障害が発生した際、アプリの作りが悪いなどのユーザ(システム開発者)側の問題なのか、インスタンスが稼働しているハードウェアの障害などのAWS基盤側の問題なのか判断することが難しい場合がある。
- 「CloudWatch Network Flow Monitor」を使うと、AWS上のシステム内のトラフィックを監視することによりシステムの異常検知ができるだけでなく、異常発生時にはAWS基盤の問題なのかどうかが分かるかも、ということで、基本的な機能を確認して、どんな風に使えそうかを考える。
2024/12/20時点ではアドベンドカレンダー締め切りのため、取り急ぎ触ってみた内容とするが、随時不明点や間違いなど確認してアップデートしたい、、
2. CloudWatch Network Flow Monitorとは(自分の理解)
機能概要
- 「ワークロードインサイト」:設定を有効化したリージョンで、どこからどこへどのような通信が発生しているのかを全体的にとらえる機能。
- 「モニター」:主にAWSリージョン内(AZ内、AZ間など)において、指定したSRC/DST間のユーザトラフィック(現状TCPのみ)の通信量、RTT、再送についてのメトリクスを取得し表示する。また「Network Health Indicator」として、「モニター」として設定したSRC/DST間のAWS基盤の稼働状況(正常/異常)を表示する。
本サービスへの期待
- 自分としては、「Network Health Indicator」に注目している。
- 「モニター」を設定し、トラフィックのメトリクスに異常が見られた際、「Network Health Indicator」が正常のままであればユーザ起因の問題(アプリの作りなど)、「Network Health Indicator」が異常に変わっていればAWS基盤の障害というように、ユーザ起因なのかAWS基盤起因なのか、原因を切り分けることができることを期待している。
3. やったこと
- 複数のEC2インスタンス(構成図参照)に、Network Flow Monitorのエージェントをインストールする。
- wgetやiperf3などを用いて、AZ内/AZ間などのいくつかのパターンのトラフィックを発生させて、メトリクスデータを収集する。
- 「モニター」(SRC/DSTの指定による監視する範囲の定義)を設定し、メトリクスがどのように可視化できるのかを確認する。
こちらの記事「【AWS】Amazon CloudWatch Network Flow Monitorを最速で体験してみた【re:Invent2024】」で、気になっていたことがほとんど既に最速でやってあったが、改めて自分でも別観点で確認してみる。
4. 構成図

5. 設定手順
5.1 検証環境構築
- 構成図の環境を構築する。
- 同一VPC内に別AZ所属のsubnetを3つ作成する。
- インスタンス4個(Amazon Linux 2023)の起動
- 今回はインスタンスにEIPを付けていて、各種エンドポイントとの通信はIGW経由としており、インターフェースエンドポイントは作成していない。
- nginxのインストール、10MBのファイルの配置
- iperf3のインストール
- cronieのインストール(cronを使えるようにするため)
- iproute-tcのインストール(tcコマンドを使えるようにするため)
5.2 初期設定
- CloudWatch -> ネットワークモニタリング -> フローモニターを選択する。
- 対象のリージョンで初めて Network Flow Monitorを使用開始する際、確認画面が出るため、「ネットワークフローモニターを有効にする」を押して機能を有効化する。

5.3 エージェントのインストール
- 公式ドキュメント 「Install and manage agents for EC2 instances」に従ってインストールを行う。
IAMロールの作成
- 以下のIAMポリシーを含むIAMロールを作成し、インスタンスにアタッチする。
- CloudWatchNetworkFlowMonitorAgentPublishPolicy (Network Flow Monitorのエンドポイントへのメトリクスデータ送信を可能にするため)
- AmazonSSMManagedInstanceCore(Systems Managerからの操作をできるようにするため)
エージェントのインストール
- Systems Managerからエージェントをインストールする。
- 「ディストリビューター」の画面で、「AmazonCloudWatchNetworkFlowMonitorAgent」を選択して「パッケージの作成」を選択する。

- 「1回限りのインストール」を選択する。

- インストールしたいインスタンスを個別に選択し、ログ出力はCloudWatchにして「実行」する。

- インストールが成功したことを確認する。

5.4 モニターの作成
モニターとは
- トラフィックのSRCとDSTを指定して、監視する範囲を定める設定が「モニター」と呼ばれる。
- SRCとDSTは、最小単位が1つのsubnetであり、その他、複数のsubnetの組み合わせやVPCなどを指定できる。
- 今回は以下の5パターンのモニタを作成した。(1a内、1a-1c間、1a-1d間)
- SRC: subnet1a DST: subnet1a (同一subnet内の通信)
- SRC: subnet1a DST: subnet1c
- SRC: subnet1c DST: subnet1a
- SRC: subnet1a DST: subnet1d
- SRC: subnet1d DST: subnet1a
モニターの作成
-
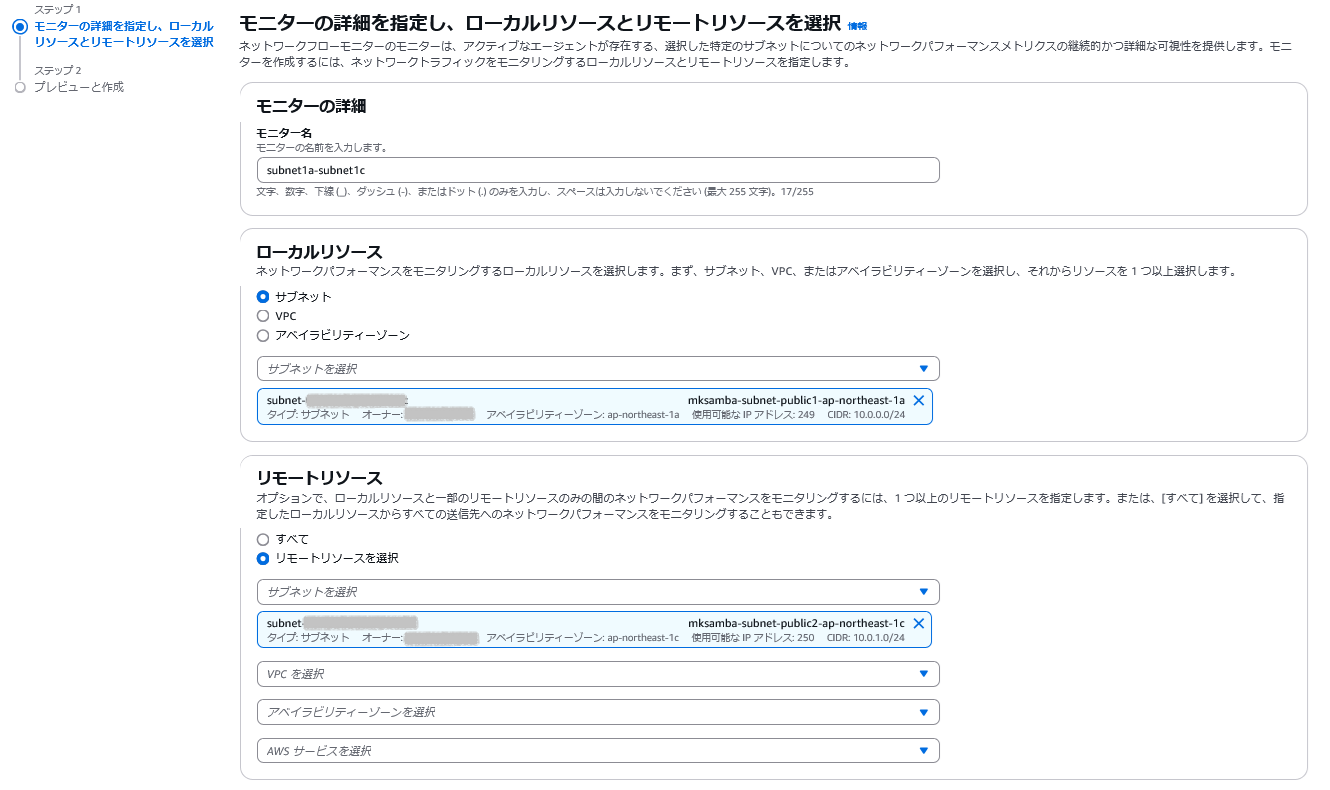
モニターの作成手順は以下(例として、SRC: subnet1a、DST: subnet1cを設定する場合)。
-
「モニターの作成」を選択する。

-
「ローカルリソース」(SRC)、「リモートリソース」(DST)を指定してモニタを作成する。
6. 検証用トラフィックの生成と結果の表示
- 検証用のトラフィックを流し、それらがどのように表示されるのかを確認する。
6.1 httpトラフィック
トラフィック内容

- AZ-1aのnginxサーバに対して、AZ-1a, AZ-1c, AZ-1dのクライアントから10分に1回、10MBのファイルを取得する。
# 試験用10MBファイルの作成(nginxサーバにて)
[ec2-user@ip-10-0-0-80 ~]$ fallocate -l 10M 10M.txt
# 10分おきにファイルをhttpで取得(クライアントにて)
[ec2-user@ip-10-0-0-44 ~]$ crontab -l
0,10,20,30,40,50 * * * * /usr/bin/wget -P /home/ec2-user/ http://10.0.0.80/10M.txt
ワークロードインサイトでの表示
- ワークロードインサイトの「AZ内」を確認する。
- 「転送されるデータ」が20MBとなっているが、メトリクスの集計単位が10分間であり、AZ-1a内でのnginxサーバ、wgetクライアント間で10分に1回10MBのダウンロードを行っていることから、2台分の合計で20MBということになる。
- 1回だけ再送信があった様子(たまたま?)。
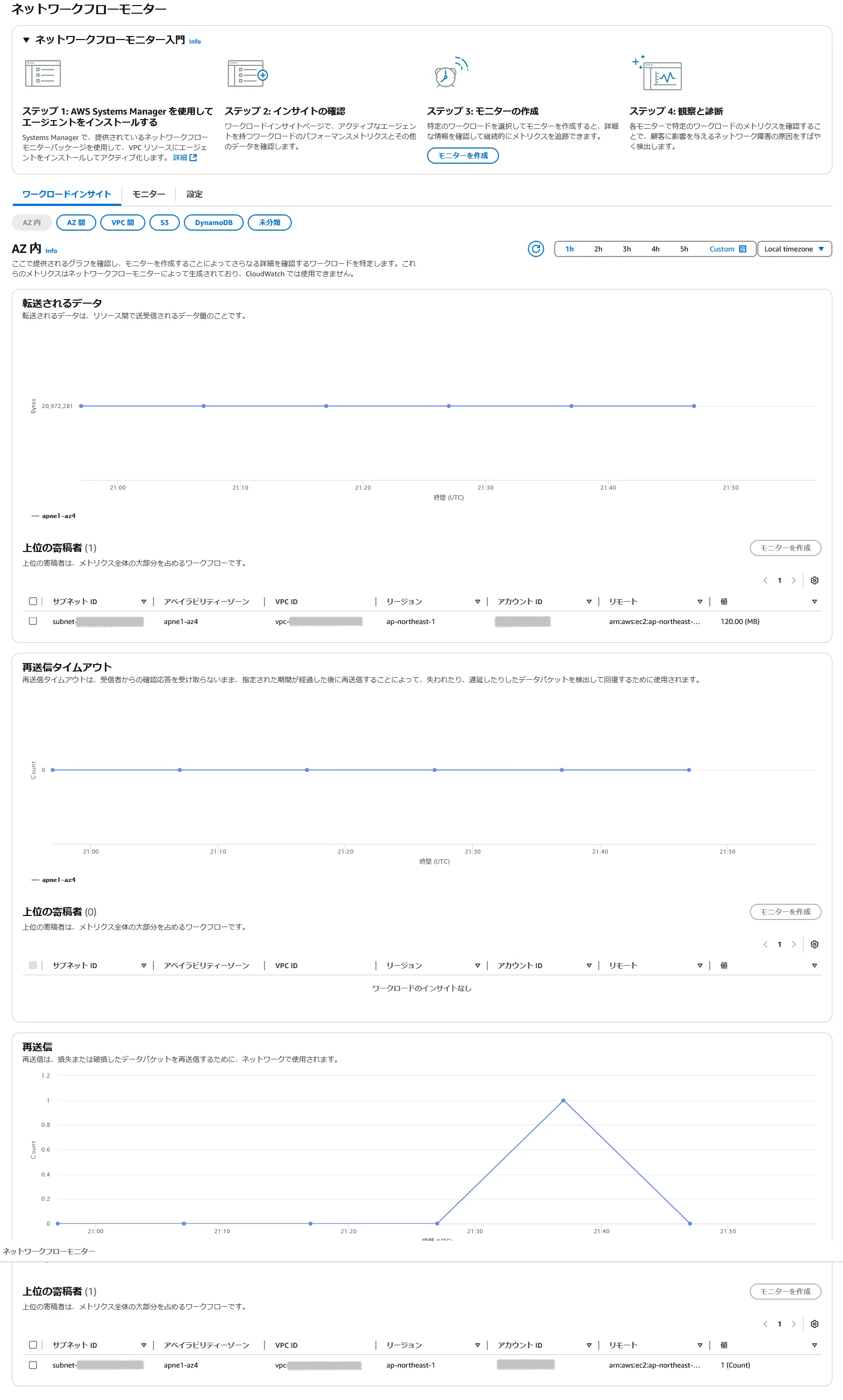
- ワークロードインサイトの「AZ間」を確認する。
- apne1-az4(=AZ-1a)は、AZ-1a/AZ-1c間とAZ-1a/AZ-1d間の2つのトラフィックの分がカウントされるため、他のAZの倍のトラフィックがあるとカウントされることになる。

モニターでの表示
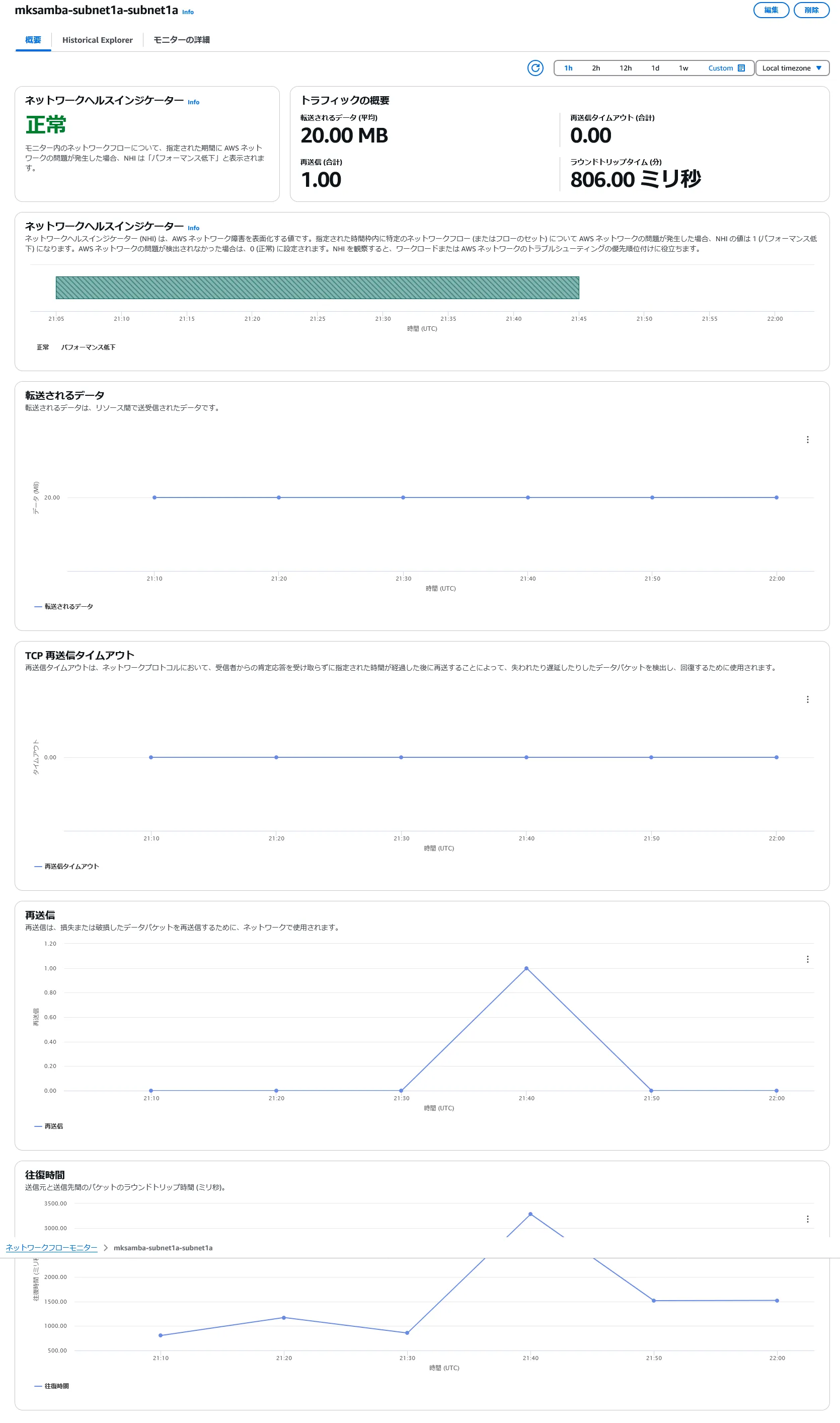
- Subnet-1a/Subnet-1a(同一subnet内トラフィック)のモニターを確認する。
- ワークロードインサイト同様、メトリクスの集計単位10分間のところ、10分に1回10MBのダウンロードを行っており、2台それぞれで通信データ量10MBずつとカウントされ、合計の通信データ量が20MBとなっている様子。
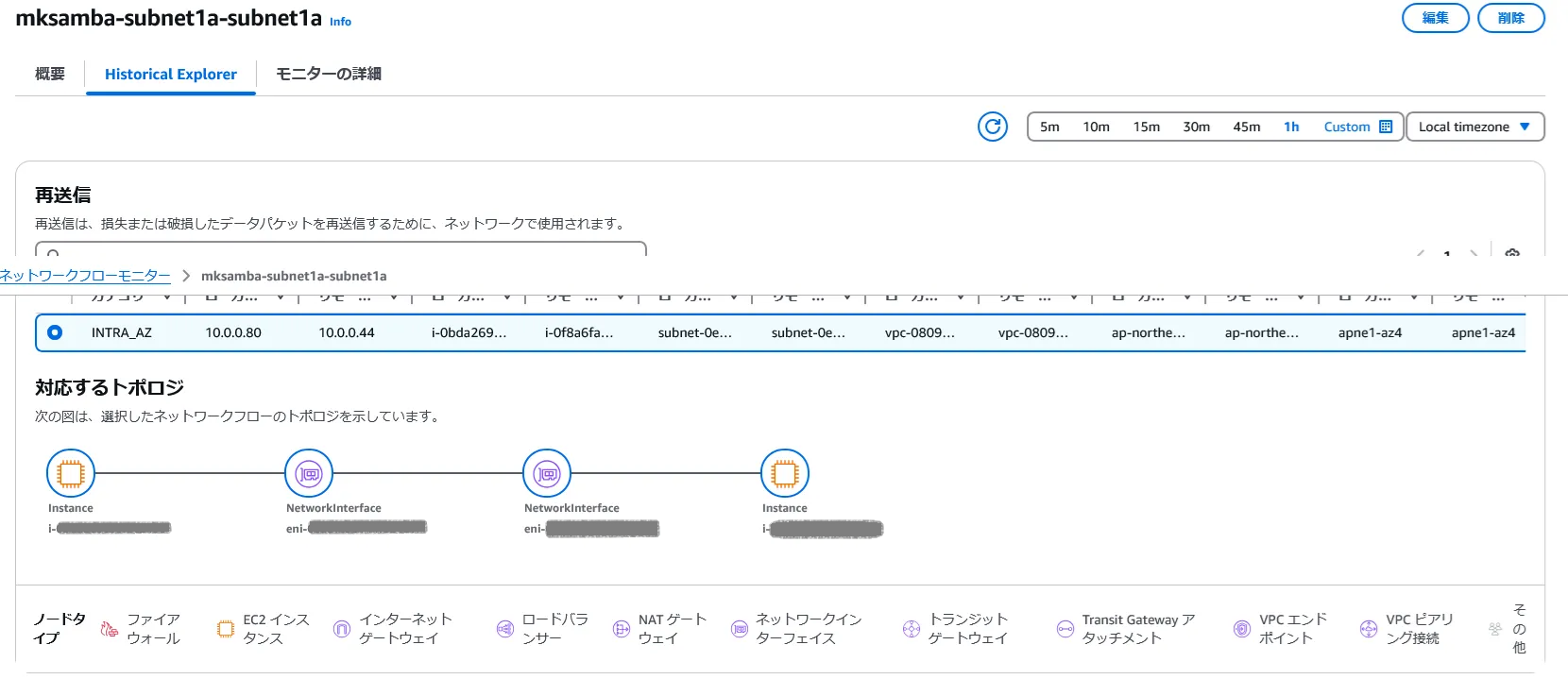
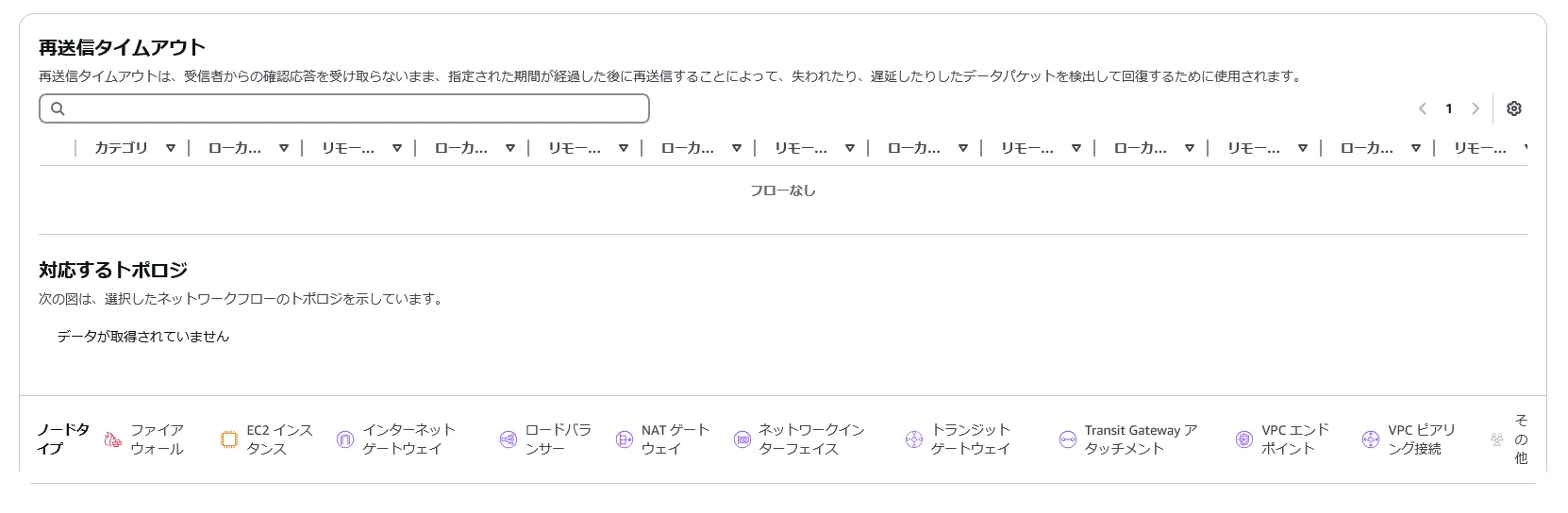
- 再送信があると、Histrical Explorerのところにトポロジが表示され、インスタンス名、ENI名といったSRC/DST間で経由するAWSリソース名が表示される。
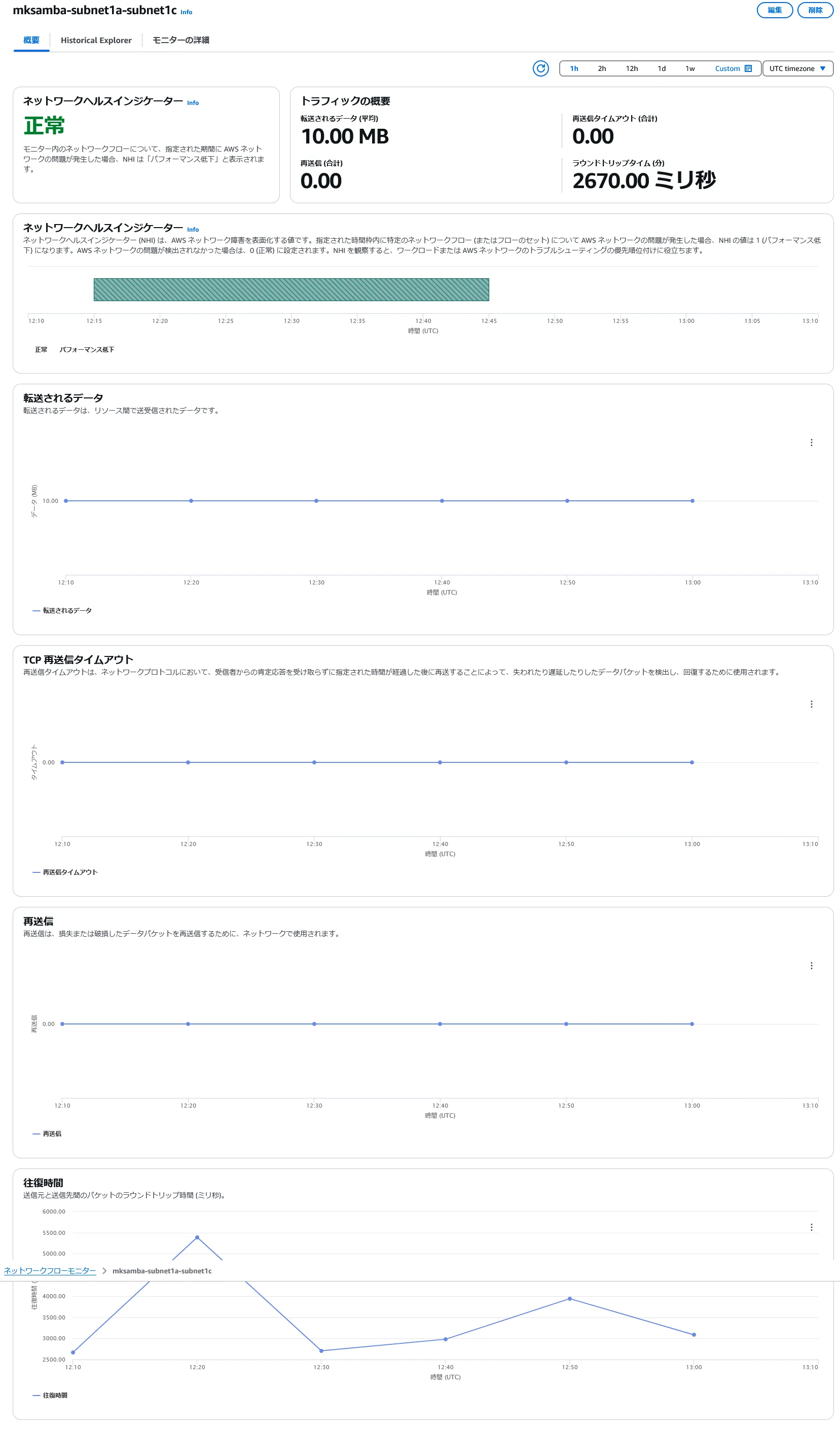
- Subnet-1c/Subnet-1a(別AZのsubnet間トラフィック)のモニターを確認する。
- この場合、メトリクスの集計単位10分間のところ、10分に1回10MBのダウンロードを行っているが、前項のSubnet-1a/Subnet-1aのモニターとは異なり、通信データ量は10MBとカウントされる。
- また、ラウンドトリップタイムもAZ内の場合と比較して大きくなっている。(このラウンドトリップタイムの測定ロジックが不明だが)
6.2 iperf3 トラフィック
トラフィック内容

- httpよりもバースト性のあるトラフィックを試すため、AZ-1aのiperf3サーバに対しAZ-1cのiperf3クライアントから20秒間トラフィックを送信する。
# iperf3コマンド(クライアント側)
[ec2-user@ip-10-0-1-182 ~]$ iperf3 -c 10.0.0.80 -t 20
Connecting to host 10.0.0.80, port 5201
[ 5] local 10.0.1.182 port 47288 connected to 10.0.0.80 port 5201
[ ID] Interval Transfer Bitrate Retr Cwnd
[ 5] 0.00-1.00 sec 122 MBytes 1.02 Gbits/sec 0 865 KBytes
[ 5] 1.00-2.00 sec 122 MBytes 1.02 Gbits/sec 0 909 KBytes
~中略~
[ 5] 18.00-19.00 sec 122 MBytes 1.02 Gbits/sec 0 1.31 MBytes
[ 5] 19.00-20.00 sec 120 MBytes 1.01 Gbits/sec 0 1.31 MBytes
---
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-20.00 sec 2.37 GBytes 1.02 Gbits/sec 0 sender
[ 5] 0.00-20.00 sec 2.36 GBytes 1.02 Gbits/sec receiver
iperf Done.
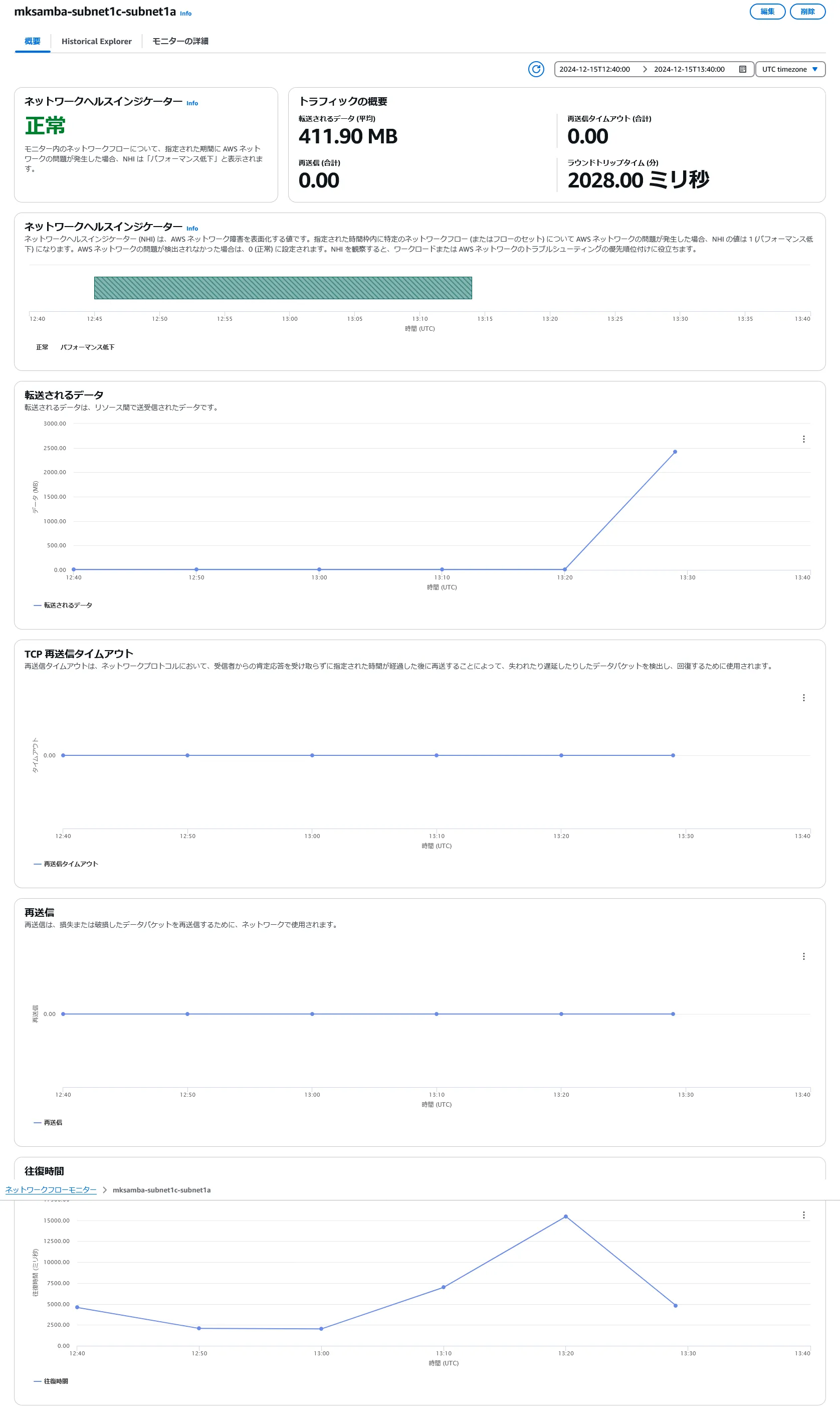
モニターでの表示
- subnet-1c/subnet-1a のモニタにて、iperf3実行時の通信データ量(約2.4GB)が測定できている。バーストトラフィックではあるが再送信は発生していない。
6.3 iperf3 トラフィック(パケロス追加)
トラフィック内容
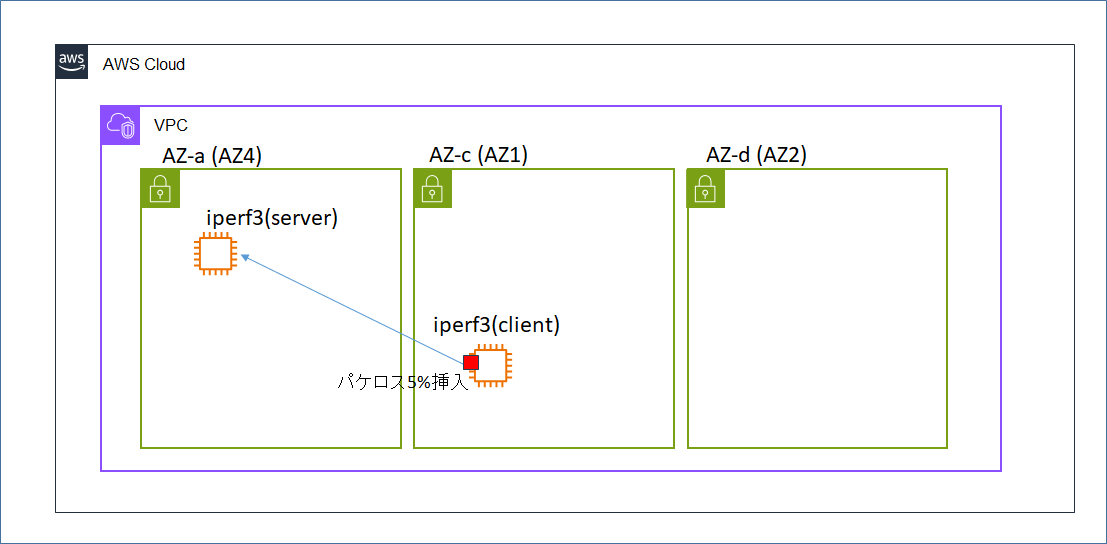
- 前項との違いとして、再送信を発生させるため、iperf3クライアント側でtcコマンドを用いてパケロス5%を挿入する。
# パケロス5%の挿入
sudo tc qdisc add dev enX0 root netem loss 5%
# パケロス挿入の解除
sudo tc qdisc del dev enX0 root
# iperf3コマンド(クライアント側)
[ec2-user@ip-10-0-1-182 ~]$ iperf3 -c 10.0.0.80 -t 20
Connecting to host 10.0.0.80, port 5201
[ 5] local 10.0.1.182 port 52476 connected to 10.0.0.80 port 5201
[ ID] Interval Transfer Bitrate Retr Cwnd
[ 5] 0.00-1.00 sec 26.1 MBytes 219 Mbits/sec 182 131 KBytes
[ 5] 1.00-2.00 sec 12.4 MBytes 104 Mbits/sec 81 52.4 KBytes
~中略~
[ 5] 18.00-19.00 sec 13.4 MBytes 112 Mbits/sec 78 8.74 KBytes
[ 5] 19.00-20.00 sec 13.4 MBytes 112 Mbits/sec 86 69.9 KBytes
---
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-20.00 sec 368 MBytes 154 Mbits/sec 2199 sender
[ 5] 0.00-20.00 sec 366 MBytes 154 Mbits/sec receiver
iperf Done.
モニターでの表示
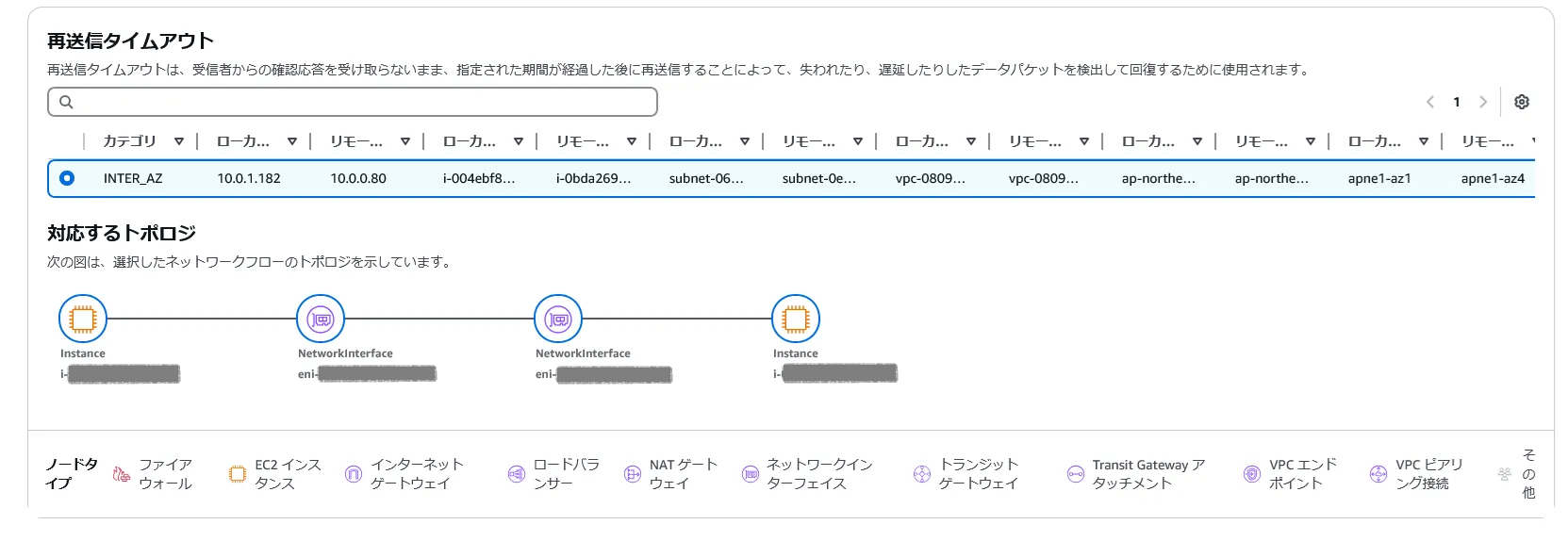
- 再送信及び再送信タイムアウトが発生した。再送信数のカウントはiperf3コマンドの結果として表示されている数とも近い値。
- 今回は自分で障害を挿入したが、仮に何もしていないのに再送信数が上がるなどの問題が発生した場合、Network Health Indicator を見て、ユーザ側の問題なのか、AWS基盤の問題なのかを判別することになる。


6. 所感
- 取り急ぎざっくり使ってみたが、値の意味など不明点もあるためもう少し仕様を確認したい。(どのようなトラフィックがあるとどのように表示されるのかの理解や、RTT値の計算方法など)
- 今回はEC2インスタンスにインストールするタイプの検証をしたが、次はEKS上で動作させるタイプの検証を行いたい(インストール手順などがだいぶ異なるため)。
- Network Health Indicator(AWS基盤の状態表示)は常に正常(緑色)。AWS内でハードウェア故障とかが発生して、異常になるところを見てみたい。