TD-Gammon でお試しの結果を書いておこう。
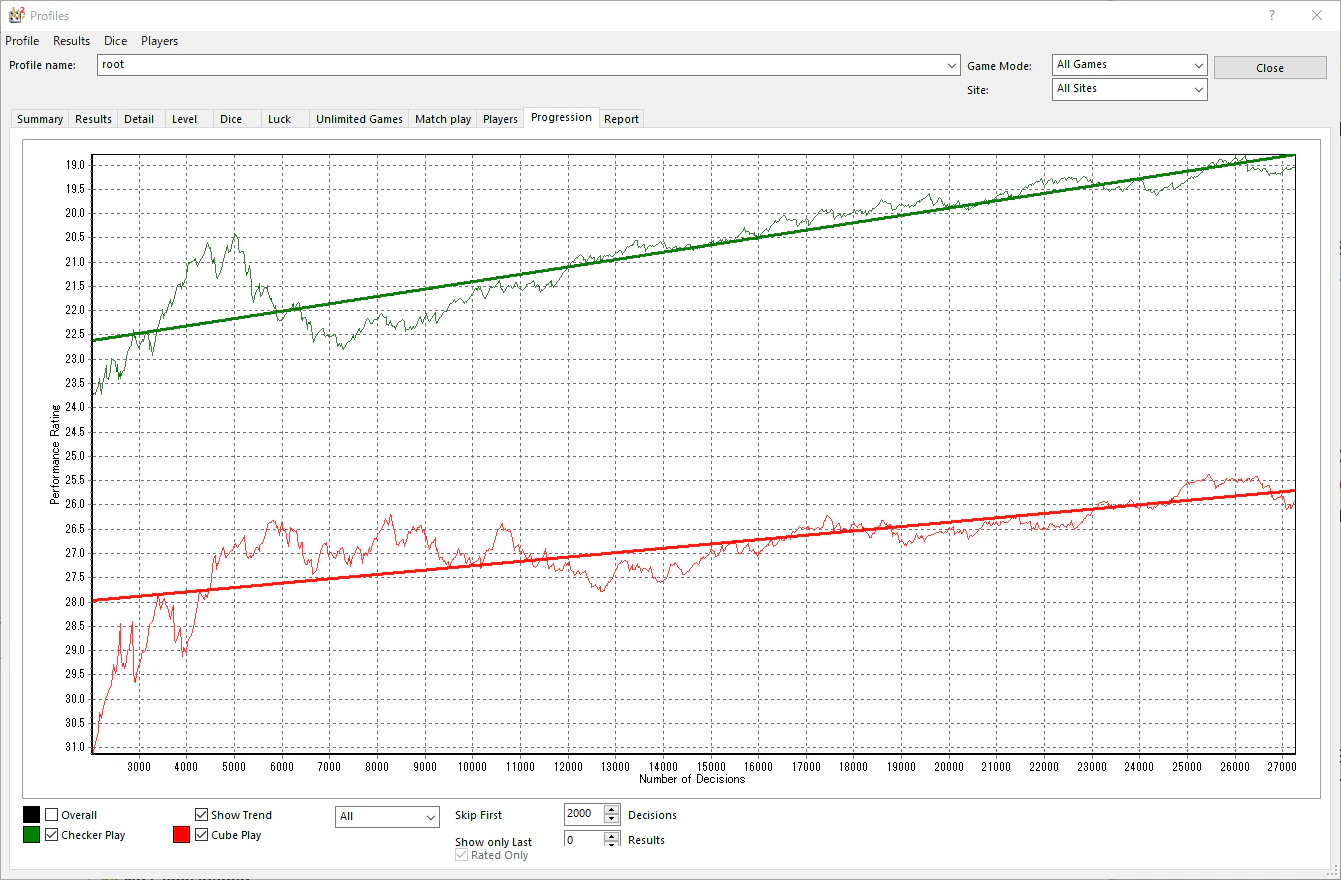
自己対戦を 1,000,000回繰り返した結果である。10万回学習するごとに、gnubgと100回対戦し、XGで解析した。ご覧の通りPRの改善傾向は続くものの、まだ初心者レベルである。
キューブアクションは学習していないので改善する余地が無いはずだが、グラフは若干右上がりである。おそらく、ムーブが改善するにつれ、キューブエラー場面のエラー値が小さくなっているのだろう。
棋譜を確認すると、botのプレイには大きく2つの問題があった。
"ギャモン"を知らない
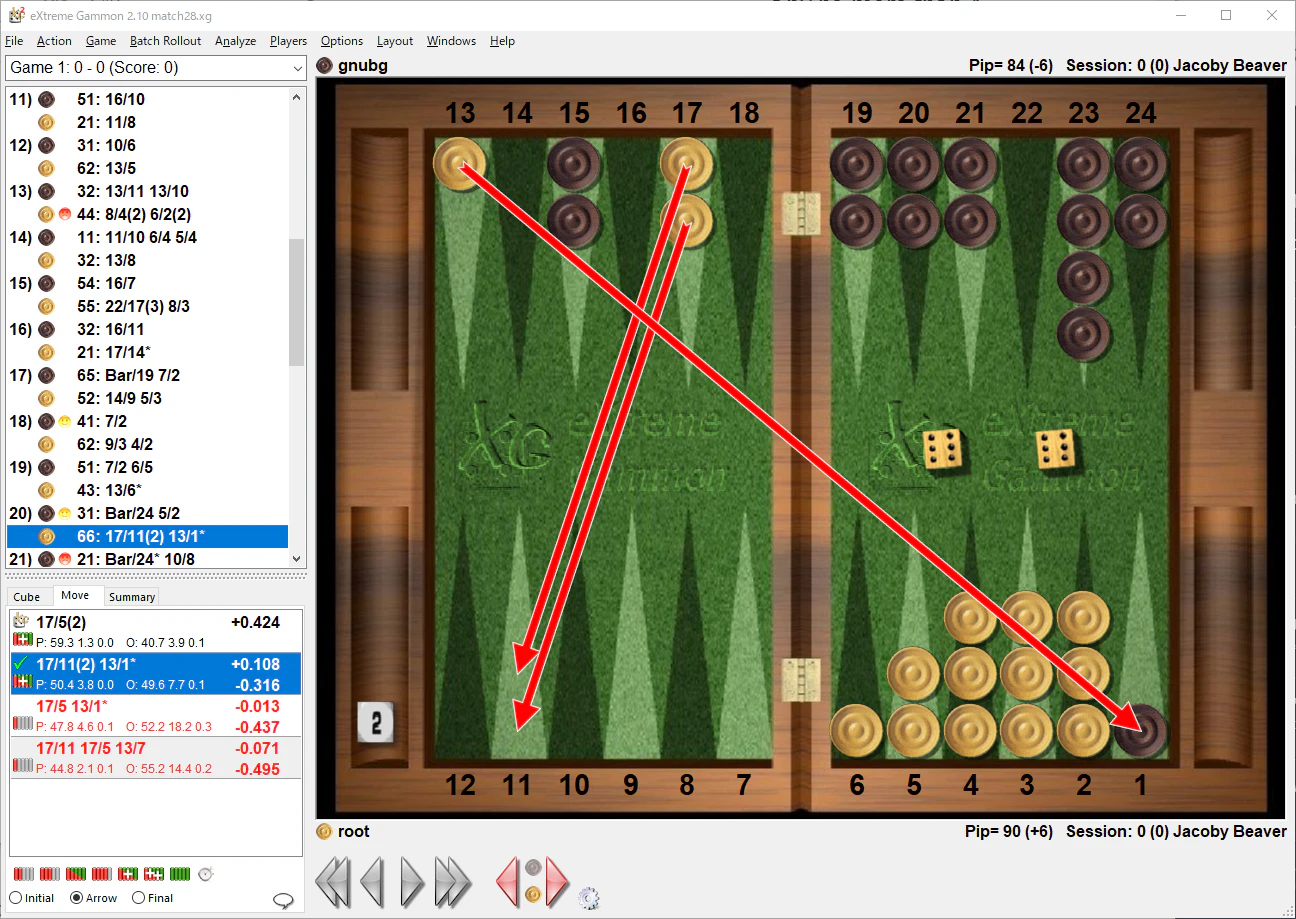
バックギャモンでは、普通に勝つと1点が得られるが、特定の条件を満たすとギャモン勝ち=2点、バックギャモン勝ち=3点が得られる。今回お試しした実装では、勝った時の reward は常に1点で、ギャモン勝ちをしようが見返りがないのである。よってギャモンを目指す手や、ギャモンセーブする手が見過ごされる傾向にあると思った。
5ゾロブリッツが覚醒していない図。
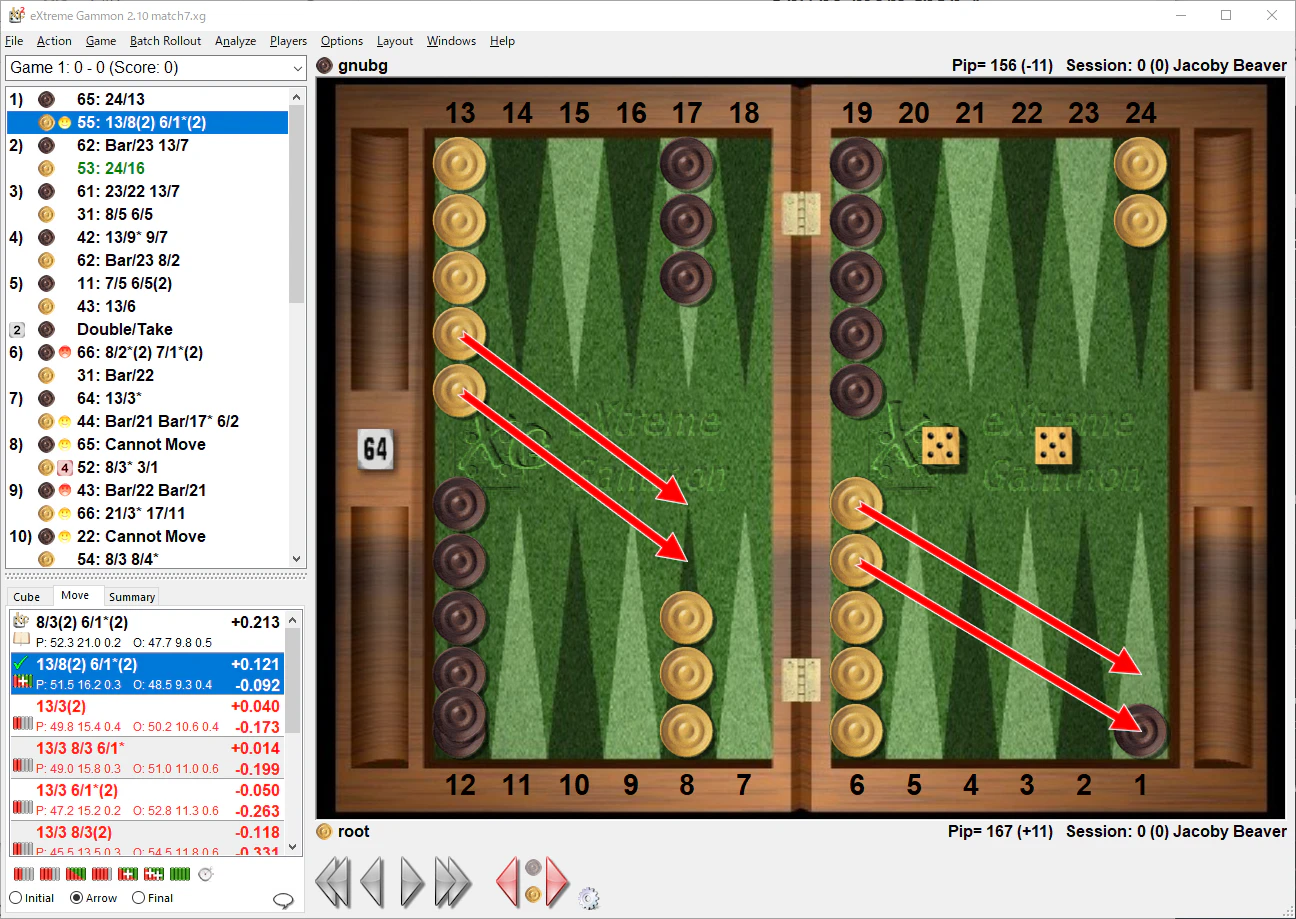
ギャモンセーブなんて教わってませんの図。

ベアオフが下手くそ
理由は定かではないが、ベアインやベアオフで大きなエラーが散見される。gnubg や XG は、ベアオフデータベースなるものが存在し、終盤ではニューラルネットに頼っていないようだ。
以下よりもっと単純なポジションでエラーしている例もある。
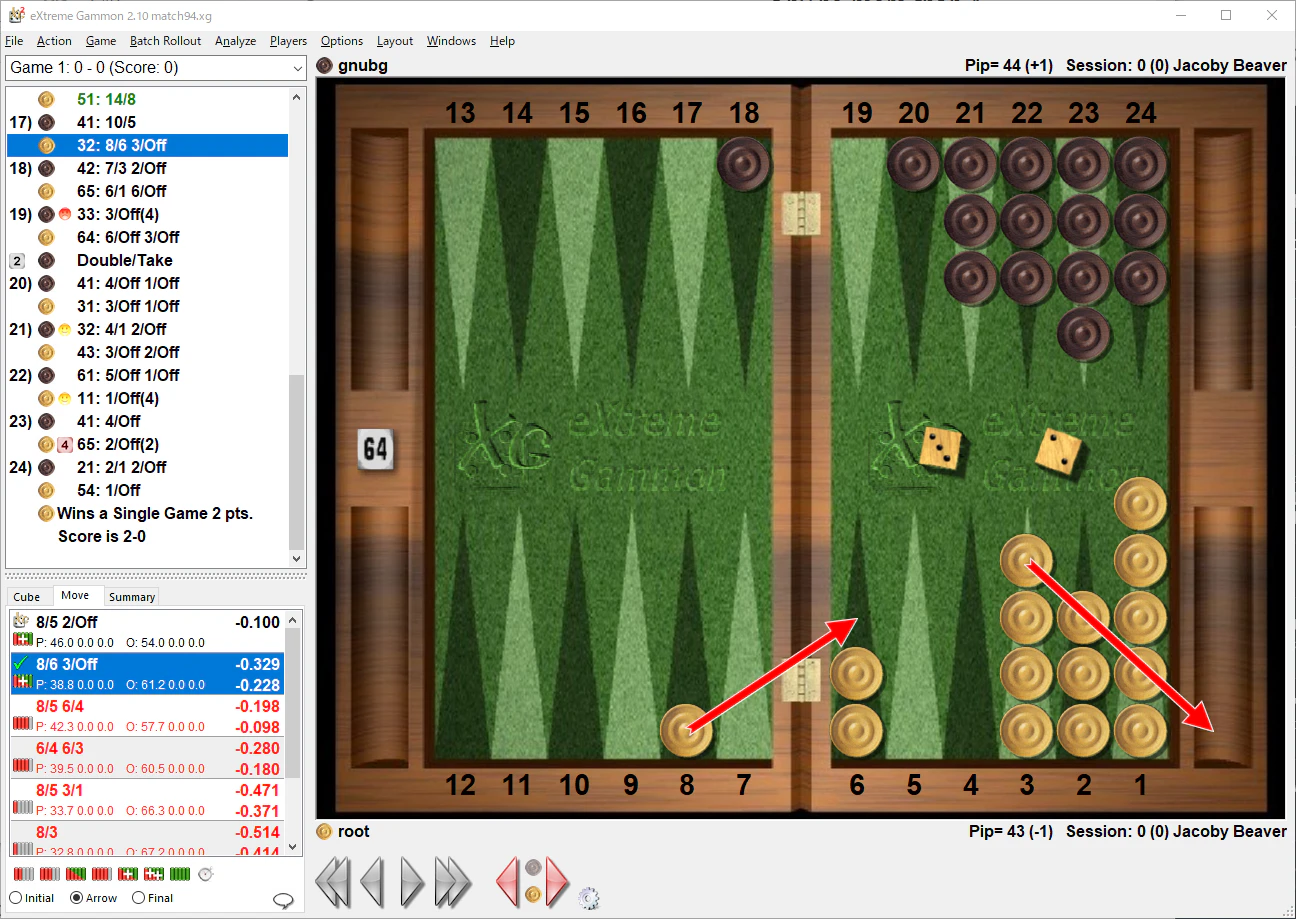
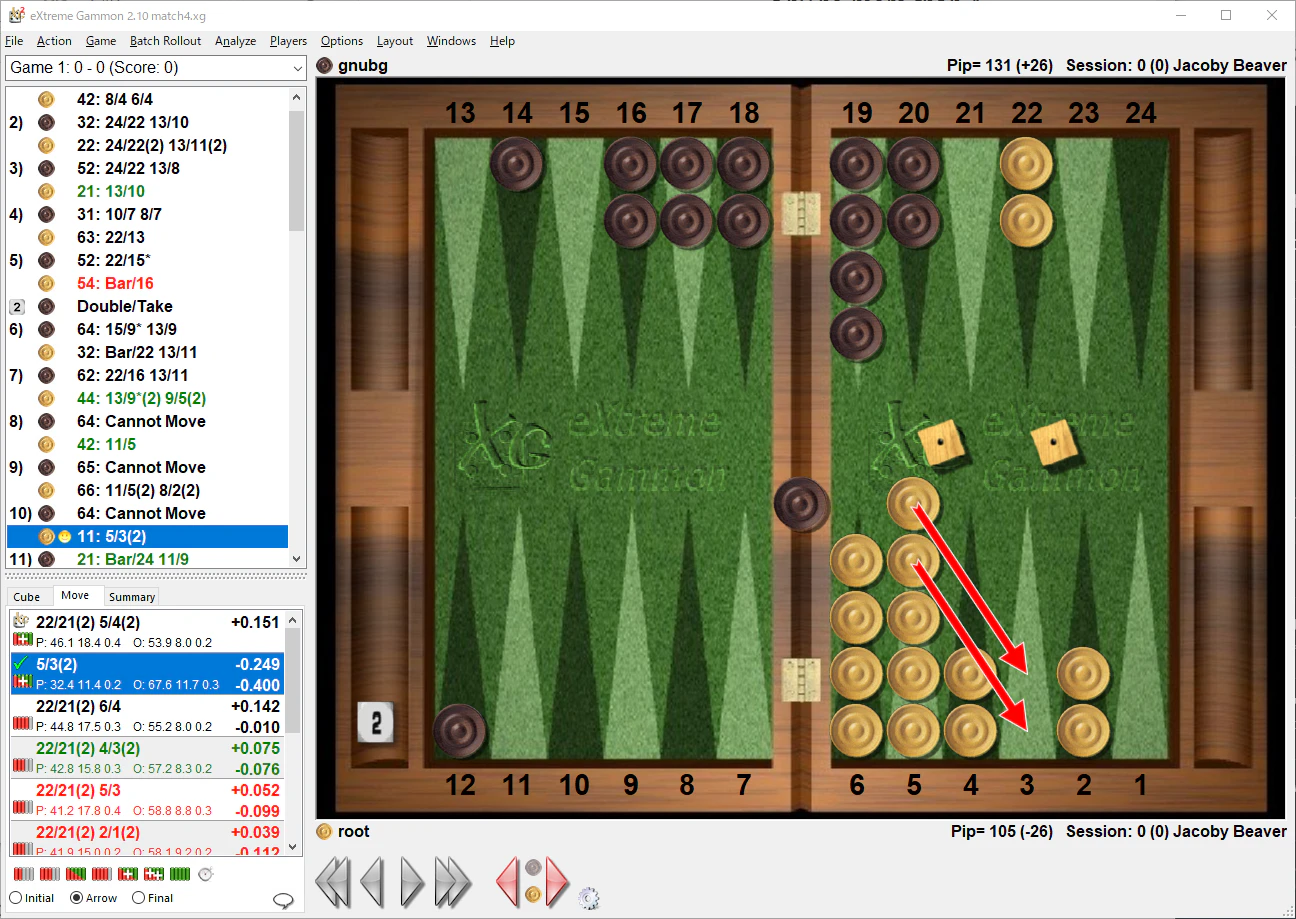
とにかく、まだまだですね
この子が弟子だったら、破門にしたいようなムーブが山盛りです。
これから
TD-Gammonでの学習はこれくらいにして、強化学習理論の勉強や Agent の実装、または使える既存の実装を吟味していこうと思います。