概要
Apache HadoopやApache SparkなどのOSSを利用した、ビッグデータ分析が可能なAWSのサービスです。
簡単に言うとマネージド型 Hadoop フレームワーク
関連する用語
Hadoop
大規模データの蓄積・分析を分散処理技術によって実現するオープンソースのミドルウェアです
Spark
分散共有メモリの仕組みをもち、複数マシンでメモリを共有することで、機械学習のような同じ処理の繰り返し、同じデータを何度も使うような処理において、Hadoopと比較して大幅に高速だとされる。オープンソースのソフトウェアフレームワーク
Hive
Hadoop上に構築されたデータウェアハウス構築環境で、SQLライクな「HiveQL」を使ってデータの集約・問い合わせ・分析を行える。
Presto
Presto は複数のデータソースのクエリに役立ち、MySQL、Redshift、Hive と直接やりとりするためのコネクタも提供できる
Pig
Hiveと同じくHadoop上で動作するプログラムを作成できる。
スクリプト言語を使ってデータの集約・問い合わせ・分析を行える。
Apache Ranger
Rangerは、Hadoopコンポーネント全体での一貫性のあるセキュリティポリシーの定義、運営、管理を可能にする、集中的なプラットフォーム
EMRノートブック
クエリとコードを実行できるノートブックで視覚化できる
イメージ→https://paiza.io/ja/projects/new?language=python3
ブートストラップアクション
EMRによって起動されるノードに対して、起動時に任意の処理を追加で実行できる仕組み
ymコマンドなどで追加のソフトウェアなどを追加でインストールできる。
EMRはカスタムAMIが利用できないから
EMRの仕組み
とても簡潔にすると下記のような感じ
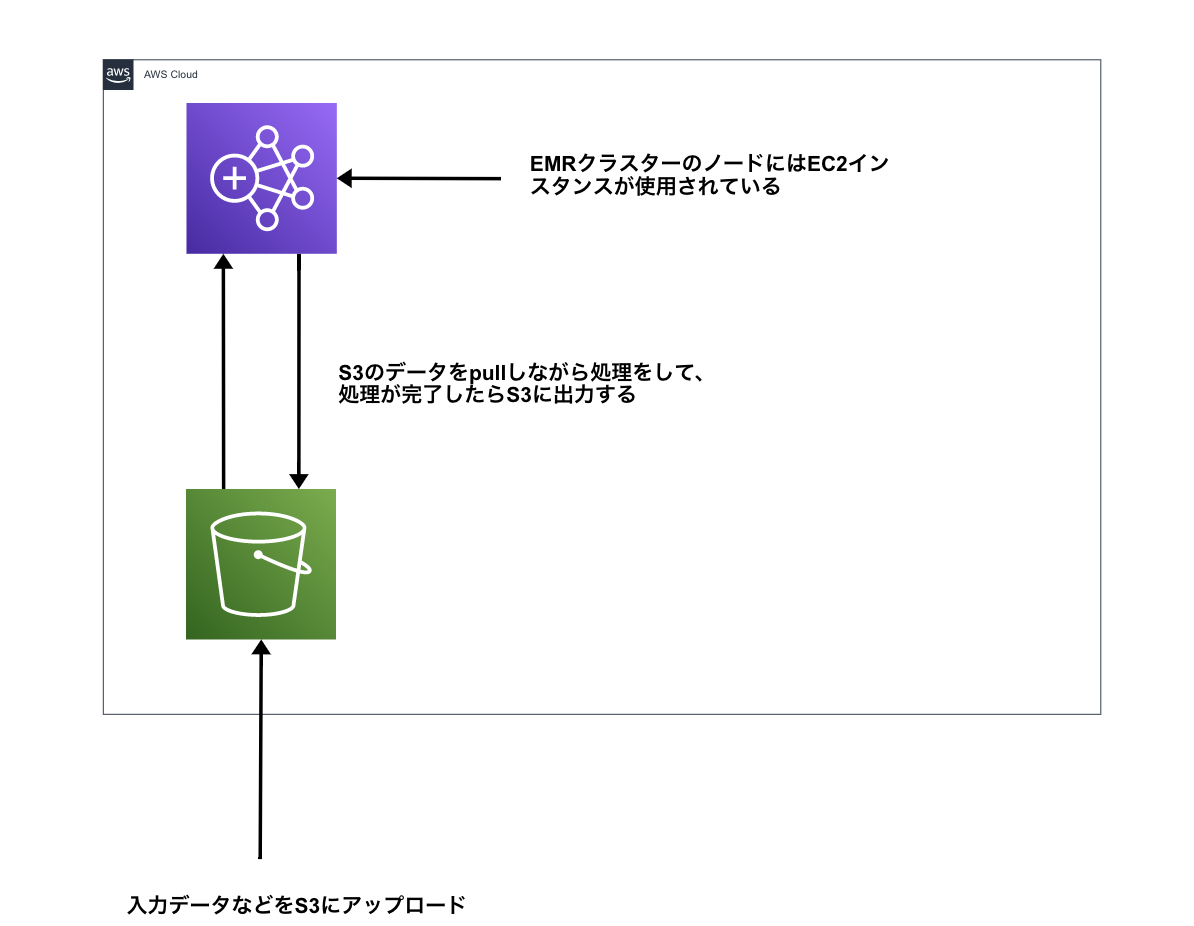
EMRクラスターの中
マスターノード
クラスターを管理する役目をしていて、インスタンスグループの健全性を監視などもする
コアノード
マスターノードによって管理されており、データノードデーモンを実行して、Hadoop Distributed File System (HDFS)の一部としてデータストレージを調整する。
タスクノード
タスクノードを使用して、Hadoop などのデータに対して並行計算タスクを実行するためノード
Hadoop Distributed File System (HDFS)
EMRクラスターでジョブ実行中の作業領域として使用するストレージ
クラスターでのコスト最適化
マスターノード、コアノードはオンデマンドインスタンやリザーブドインスタンスなどを使用して、タスクノードにはスポットインスタンスなどを使用することでコスト最適化ができる
EMRの特徴
コストのが低い
10ノードのEMRクラスターの使用を1時間あたり0.15USDで使用することができます。
クラスター自体処理されると削除されるので待機時間などの料金もかかりません
伸縮性
クラスターサイズをAuto Scalingで何千台の多さで自動で増減することができます。
使用性が良い
マネージドなので自分が1から設定しなくてもAWSでよしなにやってくれる。
特定のサーバに不具合が出た場合もAutoScalingなどの対応で短時間で解決ができる
EMRの使い所
- 大量のデータを処理する
- 続々とデータが追加される
- 分散処理
試験でよくある問題対策
データの圧縮アルゴリズム
- bzip2のような分割されているものや、snappyのような高圧縮処理の圧縮アルゴリズムを使う
暗号化
保管時の暗号化
- サーバー側の暗号化 or クライアント側の暗号化
転送時の暗号化
- EMR クラスターノードと Amazon S3 間で伝送中の EMRFS オブジェクトをTLSによる暗号化を行う
ローカルディスクでの暗号化
- HDFSの暗号化とLUKSの暗号化
- EBS ルートデバイスボリュームを暗号化するには、カスタムAMI を指定する
Apache Sparkでのパフォーマンス改善
- S3Slelectを使用して必要なデータのみを取得する
- Apache Spark DataDramesを使用して分散したデータを列に戻す
ブートストラップアクションの活用
- Hadoopの設定を上書きする
- 利用したいライブラリのインストールやエイリアスの設定
- タイムゾーンの変更など
- Gangliaをインストールして利用する
EMRへのアクセス権限
- EMRには複数のIAMロールを紐付けることができず、ユーザーごとのアクセス権の切り替えなどもできない
- Glueリソースポリシーを使いデータカタログへのアクセス権を制御する
内容については随時更新します
間違っているところなどありましたら是非コメントいただきたいです:bow
参考にさせていただいた記事
https://oss.nttdata.com/hadoop/hadoop.html
https://www.skyarch.net/column/amazon-emr/
https://dev.classmethod.jp/articles/beginner-what-is-emr-overview/
https://zenn.dev/mn87/articles/00825e91124796