Split (pd.Series.str.split)
Pythonのstr.splitと同様に指定の文字列で文字列を分割できます。
df = pd.DataFrame({"name" : ["a", "b", "c"],
"code": ["123.456.789", "234.567.890", "345.678.901"]})
df

df["code_split"] = df["code"].str.split(".")
df
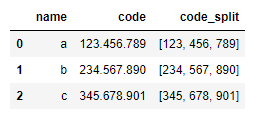
また、引数の"expand"をTrueに設定すると複数カラムに分割の結果を割り当てることができます。
df[["code_1", "code_2", "code_3"]] = df["code"].str.split(".", expand=True)
df

困ったこと
Splitした結果に加工を加えてもう一度1つの文字列にするときに何を使えばいいのか迷いました。
なぜかというと、Splitした結果が配列のように見えており、
pandasの配列の値の入ったカラムの扱い方などは知らなかったからです。
Join (pd.Series.str.join)
str.joinで当然のようにJoinできました。
PythonのString.joinと比べて、セパレータと配列は逆の位置になっています。
df["code_joined"] = df["code_split"].str.join(".")
df
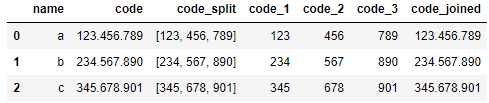
また、splitの結果の配列の各要素もstrから取得できました。
df["code_split"].str[0]
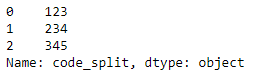
データ型がObjectであれば配列でも".str"からアクセスできるんですね。
勝手に掲げていた毎週更新が滞ったので4週目で滞ったので昨日5分ほど詰まったところの共有です。。。
この辺は公式ドキュメントにも記載されていました。
https://pandas.pydata.org/pandas-docs/stable/user_guide/text.html#text-string-methods
10 minutes to pandasをやってすぐ実務に移ってしまっていたので
この辺を勉強した方がいいのかもしれません…