目次
1 Word2Vecとは
[1-1 CBOW(Continuous Bag-of-Words)](#1-1-CBOW(Continuous Bag-of-Words))
1-2 Skip-gram
2 実装
2-1 文章の前処理
2-2 形態素解析
2-3 Word2Vecを用いた学習
2-3-1 モデルの作成
2-3-2 分散表現の確認
2-3-3 単語同士の演算
1 Word2Vecとは
Word2Vecとは、分散表現を作成するための技術です。
CBOW(Continuous Bag-of-Words)あるいは、Skip-gramというニューラルネットワークが用いられます。
分散表現を行うことで単語を実数ベクトル化し、単語を定量的に表現することができます。
これにより類似単語を算出することや、単語のベクトル計算が可能になります。
例えば、単語同士を足し算・引き算することで以下のように計算することができます。
saw - see + eat = ate
これは、seeの過去形であるsawからseeを引いて、eatを足し合わせることでeatの過去形であるateを得ることができました。
また、こういったことを加法構成性と呼びます。
1-1 CBOW(Continuous Bag-of-Words)
CBOWは前後の単語から対象の単語を予測するニューラルネットワークです。
学習に要する時間がskip-gramよりも短いところが特徴です。
CBOWの概略を以下の図1で示します。
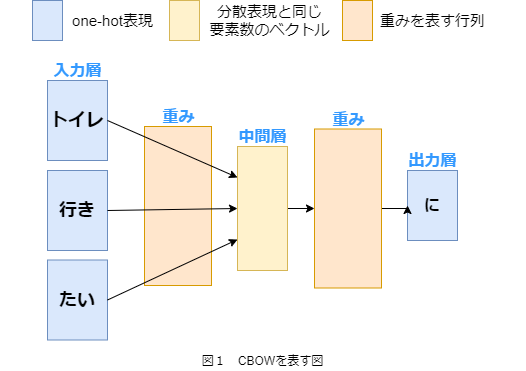
図1において、入力層と出力層の青いブロックはone-hot表現という単語を0と1からなるベクトルで表現されたものです。
中間層の黄色のブロックは分散表現というベクトルで表現されたものです。
分散表現は単語間の関連性や類似度に基づく200要素程度の実数ベクトルで、単語を表現することができます。
最後にオレンジ色のブロックは重みを表しており、
学習により各単語に対応する分散表現が並んだ行列になります。
1-2 Skip-gram
Skip-gramは対象の単語から前後の単語を予測するニューラルネットワークです。
CBOWより学習に時間はかかるが、精度が高いことで知られています。
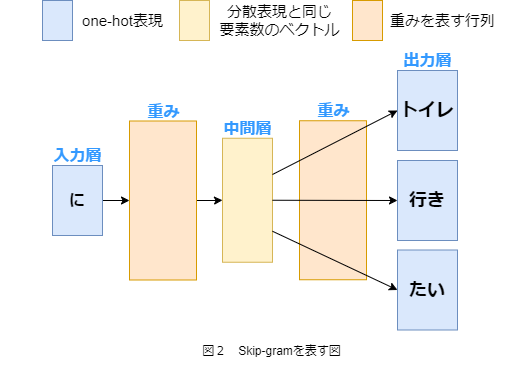
Skip-gramにおいてもCBOWと同様なブロックが並んでいます。
2 実装
今回は青空文庫-ジーキル博士とハイド氏の怪事件を用いて学習を行います。
2-1 前処理
まずは文章の前処理として不要な部分を削除します。
from janome.tokenizer import Tokenizer
import re
with open("jekyll_to_hyde.txt", mode="r", encoding="shift_jis") as f:
jth_orig = f.read()
jth = re.sub("「[^」]+」", "", jth_orig)
jth = re.sub("[[^]]+]", "", jth)
jth = re.sub("[ \n]", "", jth)
separator = "。"
jth_list = jth.split("。")
jth_list.pop()
jth_list = [s+separator for s in jth_list]
print(jth_list[:3])
['弁護士のアッタスン氏は、いかつい顔をした男で、微笑なぞ決して浮かべたことがなかった。', '話をする時は冷ややかで、口数も少なく、話下手だった。', '感情はあまり外に出さなかった。']
2-2 形態素解析
続いて形態素解析を行います。
形態素解析については「JanomeとMecabを使って形態素解析してみる」でざっくりと紹介しています。
tokenizer = Tokenizer()
jth_words = []
for s in jth_list:
jth_words.append(list(tokenizer.tokenize(s, wakati=True)))
print(jth_words[0])
['弁護士', 'の', 'アッタスン', '氏', 'は', '、', 'いかつい', '顔', 'を', 'し', 'た', '男', 'で', '、', '微笑', 'なぞ', '決して', '浮かべ', 'た', 'こと', 'が', 'なかっ', 'た', '。']
2-3 Word2Vecを用いた学習
2-3-1 モデルの作成
pythonライブラリのgensimを用いることで簡単にWord2Vecのモデルを作成することができます。
モデルの作成にあたってパラメータを設定します。
| パラメータ | 意味 |
|---|---|
| size | 中間層のニューロンの数 |
| min_count | 指定した値以下の出現回数の単語を無視 |
| window | 対象単語の前後の単語数 |
| iter | epochs数 |
| sg | Skip-gramを使うかどうか(CBOW:0, Skip-gram:1) |
epoch数とは学習データを何回使用するかを示すパラメータです。
St_Hakky’s blog - エポック(epoch)数とは【機械学習 / Deep Learning】に詳しい解説がありますので参考にしてください。
from gensim.models import word2vec
model = word2vec.Word2Vec(
jth_words,
size=100,
min_count=2,
window=5,
iter=20,
sg=0
)
2-3-2 分散表現の確認
print("分散表現の形状:\n{}".format(model.wv.vectors.shape))
print("分散表現:\n{}".format(model.wv.vectors))
分散表現の形状:
(1816, 100)
分散表現:
[[-0.29037765 0.18757686 0.12180115 ... -0.34453118 0.13222824
0.21604794]
[-0.33285522 0.175814 0.33072886 ... -0.1328826 -0.05856552
0.0324605 ]
[-0.11637706 0.38059843 0.4641297 ... -0.17083107 -0.40879136
0.20536262]
...
[-0.03460616 0.04954998 0.08151696 ... -0.02548153 -0.0407201
0.03769527]
[-0.03091142 0.04769895 0.09626182 ... -0.00936304 -0.05432918
0.02119827]
[-0.04336037 0.06070961 0.13772444 ... -0.0173093 -0.07817657
0.0190126 ]]
この場合、1816の単語が存在し、分散表現のベクトルの要素数は100になっています。
また、index2wordで単語のリストを取得することができます。
これを用いて最初の10単語を表示みます。
print("初めの10単語:\n{}".format(model.wv.index2word[:10]))
初めの5単語:
['の', '、', 'た', 'は', 'に', '。', 'て', 'を', 'が', 'で']
2-3-3 単語同士の演算
most_similarメソッドでは対象の単語に対する類似度の高い単語を降順で表示できます。
手紙に近い単語は何なのかを見ていきましょう。
for x in model.most_similar("手紙"):
print(x)
('ロンドン', 0.9996036291122437)
('やはり', 0.9992313981056213)
('永久', 0.9991883039474487)
('話', 0.9991743564605713)
('我々', 0.9990351796150208)
('ただ', 0.9989936351776123)
('六', 0.998958945274353)
('善い', 0.9989539980888367)
('ずつ', 0.9989365339279175)
('店', 0.9989135265350342)
ロンドンや話、我々などの単語が上位に出てきました。
次に単語同士の計算をしてみます。
positive=では足し算を、negative=では引き算ができます。
手紙+人間を計算してみます。
model.wv.most_similar(positive=["手紙", "人間"])
[('今', 0.9991933107376099),
('として', 0.9987269043922424),
('しかも', 0.9986646175384521),
('ずっと', 0.9986602067947388),
('薬', 0.9986456036567688),
('ただ', 0.998503565788269),
('立場', 0.9984672665596008),
('性質', 0.9984337091445923),
('うち', 0.9982945919036865),
('後', 0.9981254935264587)]
今回の学習では手紙と人間を足し合わせると今や薬になるそうです。
場所+夢-話の場合はどうなるでしょう。
model.wv.most_similar(positive=["場所", "夢"], negative=["話"])
[('いつも', 0.9920538067817688),
('暖炉', 0.9920322299003601),
('広間', 0.9917836785316467),
('邸宅', 0.9916156530380249),
('よ', 0.9916147589683533),
('大きな', 0.9915117621421814),
('愛情', 0.9913535118103027),
('それでも', 0.9912907481193542),
('前記', 0.9912028312683105),
('こういう', 0.9910838603973389)]
暖炉や広間、愛情が上位にあがりました。
言われてみれば、静かで夢のある空間と考えられなくもない(?)
以上がWord2Vecを用いた学習です。
非常に面白い内容なのでもっと深堀して勉強していきたいですね。