12.1 目的:パフォーマンスを最適化する
パフォーマンスの最適化にはインデックスが重要だよね。
インデックスを使おう。
12.2 アンチパターン:闇雲にインデックスを使用する
さあ、インデックスを使ってみよう!
しかし、もしもインデックスに対する正しい知識が無いと以下の3パターンにハマりがち。
- インデックスを全く使わない。
「インデックス怖い!!オーバーヘッド怖い!!」
- インデックスを全テーブルに定義する。
「インデックスがあれば絶対に安心だ(フラグ」
- インデックスを適切に定義していても、SQLがクソ。
「無敵のインデックスでなんとかしてくださいよぉ〜〜〜〜!!」
以下、それぞれについて詳しく見て行きましょう。
12.2.1 ケース1:インデックス恐怖症
インデックス恐怖症の患者たちは、何かと「オーバーヘッドが〜オーバーヘッドが〜」と宣いますが、世の中のすべてのオーバーヘッドが悪いわけではありません。
オーバーヘッド:(INSERT/UPDATE/DELETE時の、インデックスの更新にかかるパフォーマンスコスト)。
悪いのはあくまで「無駄なオーバーヘッド」であり、ひいてはそれを生み出す無駄なインデックスなのです。
適切なインデックスのためのオーバーヘッドは、速度の対価として払うべきコストです。
例えば私達エンジニアは、直接利益を生み出すコードの他にも、そのテストコードなどの直接的にはお金を生み出さないコードも書きますね。
それらは直接利益を生み出すコードを支えるために必要な、払うべきコストなのです。
12.2.2 ケース2:インデックス狂信者
「インデックスが万能なんやったら、なんでもインデックスでお願いしますわ!とりあえずインデックスで!ガハハ!」
CREATE TABLE Mikosan (
miko_id SERIAL PRIMARY KEY,
date_joined DATE NOT NULL,
description VARCHAR(128) NOT NULL,
status VARCHAR(10) NOT NULL,
hours NUMERIC(9.2),
INDEX(miko_id),
INDEX(description),
INDEX(hours),
INDEX(miko_id, date_joined, status)
);
mysql> show index from Mikosan;
+---------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| mikosan | 0 | PRIMARY | 1 | miko_id | A | 0 | NULL | NULL | | BTREE | | |
| mikosan | 0 | miko_id | 1 | miko_id | A | 0 | NULL | NULL | | BTREE | | |
| mikosan | 1 | miko_id_2 | 1 | miko_id | A | 0 | NULL | NULL | | BTREE | | |
| mikosan | 1 | description | 1 | description | A | 0 | NULL | NULL | | BTREE | | |
| mikosan | 1 | hours | 1 | hours | A | 0 | NULL | NULL | YES | BTREE | | |
| mikosan | 1 | miko_id_3 | 1 | miko_id | A | 0 | NULL | NULL | | BTREE | | |
| mikosan | 1 | miko_id_3 | 2 | date_joined | A | 0 | NULL | NULL | | BTREE | | |
| mikosan | 1 | miko_id_3 | 3 | status | A | 0 | NULL | NULL | | BTREE | | |
+---------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
8 rows in set (0.00 sec)
無駄無駄無駄無駄無駄無駄無駄無駄無駄無駄ァ!!!
show index の読み方は後述する。
12.2.3 ケース3:クソSQL生産機としての人生
CREATE INDEX TelephoneBook ON Accounts(last_name, first_name);
SELECT * FROM Accounts ORDER BY first_name, last_name;
SELECT * FROM Bugs WHERE MONTH(date_reported) = 4;
--Date型のカラムは、YYYY-MM-DD の順番で並んでいるため、MM からの参照だと各YYYYを全て見なければならず、インデックスが使えない。
SELECT * FROM Accounts WHERE first_name = 'Sugamon';
SELECT * FROM Bugs WHERE description LIKE '%crash%';
12.3 アンチパターンのある風景
- 「このクエリ、どうやったら速くなる?」
こういう曖昧な質問は、「そうスね〜、とりあえずインデックスじゃないスか?」という答えの温床。
「これこれこういう値の入ったテーブルで、こういうSQLを打つんだけど、どうしたら速くなるかな?」というような具体的な質問をしましょう。
-
「インデックスはオーバーヘッドが〜」「INSERT/UPDATEが遅くなるって何かの本で見て〜」
-
「全部のカラムにインデックスはってみたのに速くならないんだけど!!おたくのRDBMSは壊れているんじゃないかしら!?!?!」
前者は先述のケース1、後者はケース2に当てはまる、思考停止である。
12.4 このアンチパターンを用いて良い場合などありません
12.5 解決策:「MENTOR」の原則に基づくべし。さすれば道は開かれん。
M/E/N/T/O/R それぞれの頭文字を取った工程を実践して、適切なインデックスを定義しよう。
12.5.1 Measure(測定)
まずクエリの実行にかかる時間を計測する。
MySQL なら
- スロークエリログ 参考
- 「1 row in set (0.01 sec)」
達人曰く、「クエリの声に耳を澄ますと、スロークエリログから「助けて…」と声がするのがわかる」。
SELECT SQL_NO_CACHE hoge_column FORM piyo_TBL ...
12.5.2 Explain(解析)
EXPLAIN 構文を使って、QEP(query execution plan)レポートを表示する。
EXPLAIN SELECT * FROM hoge_tbl WHERE ...
QEP レポートの例
mysql> EXPLAIN Select (Select miko_id from Mikosan) mikomiko_id, m.description from Mikosan m INNER JOIN Mikosan m2 ON m.miko_id = m2.hours WHERE m.description LIKE '%miko%';
+----+-------------+---------+-------+-------------------------------------+-------------+---------+---------------------------+------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------+-------+-------------------------------------+-------------+---------+---------------------------+------+--------------------------+
| 1 | PRIMARY | m | index | PRIMARY,miko_id,miko_id_2,miko_id_3 | description | 130 | NULL | 1 | Using where; Using index |
| 1 | PRIMARY | m2 | ref | hours | hours | 5 | sql_antipattern.m.miko_id | 1 | Using where; Using index |
| 2 | SUBQUERY | Mikosan | index | NULL | hours | 5 | NULL | 1 | Using index |
+----+-------------+---------+-------+-------------------------------------+-------------+---------+---------------------------+------+--------------------------+
3 rows in set (0.00 sec)
QEP レポートの読み方は後述する。
12.5.3 Nominate(指名)
QEP レポートを読んで自分で考えるか、または自動で修正提案してくれるツールを使う。
「クエリを遅くしている犯人はお前だ!!」という意味で「指名」なのだと思われる。
MySQL Enterprise Query Analyzer
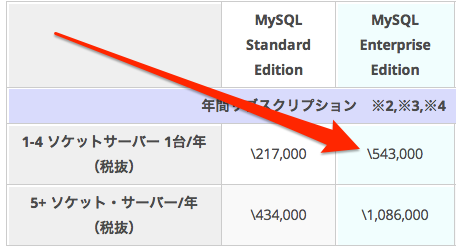
た、高い!!

サキーラ様「金のない輩はせいぜいドキュメントをよく読むがいい、ホーッホッホッホ」
12.5.4 Test(テスト)
修正したクエリを、再度実行してみて時間を計測する。
納得が出来るまで M/E/N の工程を繰り返す。
12.5.5 Optimize(最適化)
インデックスをキャッシュメモリに載せられるならそうしたほうが速くなる。
とはいえ使用可能なメモリ量との兼ね合いになるので、インデックスの容量を確認して行うこと。
参考:MySQL とメモリに関するまとめ
参考:MySQL 5.1 リファレンス・マニュアル - 12.5.5.4. LOAD INDEX INTO CACHE 構文
--LOAD INDEX INTO CACHE 構文は、MyISAM でしか使えません
LOAD INDEX INTO CACHE index_1, index_2 ...
インデックスサイズの確認は show table status で行う。
Index_length 列にbyte単位で表示される。
mysql> show table status WHERE Name = 'max_index'\G
*************************** 1. row ***************************
Name: max_index
Engine: InnoDB
Version: 10
Row_format: Compact
Rows: 0
Avg_row_length: 0
Data_length: 16384
Max_data_length: 0
Index_length: 65536
Data_free: 0
Auto_increment: 1
Create_time: 2014-11-05 23:57:36
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment:
1 row in set (0.00 sec)
mysql> show table status WHERE Name = 'no_index'\G
*************************** 1. row ***************************
Name: no_index
Engine: InnoDB
Version: 10
Row_format: Compact
Rows: 0
Avg_row_length: 0
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: 1
Create_time: 2014-11-05 23:57:02
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment:
1 row in set (0.00 sec)
12.5.6 Rebuild(再構築)
インデックスのメンテナンスを行う必要がある。
MySQL なら、
- ANALYZE TABLE hoge_tbl
- OPTIMIZE TABLE hoge_tbl
を行う。
12.5.6.1 ANALYZE TABLE とは
インデックスの持つ「Cardinaly」要素を更新するコマンド。
Cardinaly はカラムの持つ値の種類と全レコードの件数の比率であり、例えば値が2種類しか含まれないカラムを含んだレコードが10億行会った場合、Cardinaly はとても低く(2:10億)、値が1万通りあるカラムを含んだレコードが1万行ある場合、Cardinalyは高い(10000:10000)。
Cardinaly が高い場合、インデックスが有効に働くと判断出来るため、クエリの実行にインデックスを使用する確率が上がる(らしい)。
InnoDB では自動的に実施しているので手動での実行は不要。
しかも、テーブル内を全件取得して更新しているわけではなく、ランダムに8回(8回が計測に必要十分な回数とのこと)サンプリングした結果で計測し、更新しているので処理に時間的なコストもパフォーマンスコストもかからない(書き込みのテーブルロックはかかるが、リードロックはかからない)。
MyISAM では定期的に手動で実施する必要がある。
MyISAM の ANALYZE TABLE では、テーブルにリードロックがかかる。
12.5.6.2 OPTIMIZE TABLE とは
テーブルレコードの再構築(主キーの順番での全件再挿入)。
何が嬉しいかと言うと、InnoDB の場合には MVCC(multi version concurrency controll)の仕組み上、Delete されたレコードの過去のバージョンの情報が無駄に残ってしまう。
それらが削除出来るので、容量が少なくなる。
MyISAM では断片化したインデックスの再構築を行う。
InnoDB では OPTIMIZE TABLE hoge_tbl を実行すると、ALTER TABLE hoge_tbl (空のALTER TABLE)が実行される。
参考:漢のコンピュータ道
まとめ
インデックスを恐るるなかれ。
心を強く持ち、インデックスの暗黒面(使わない、使いすぎる、使えていない)に落ちてはいけない。
本来やらなければならない「MENTOR」を、見て見ぬふりし続けた結果弊害が起こる、夏休みの宿題のようなアンチパターンですね。
あと「Nominate」は略語「MENTOR」にするために頑張って単語探した感がある。
おまけ:show index の読み方
mysql> show index from max_index;
+-----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| max_index | 0 | id | 1 | id | A | 0 | NULL | NULL | | BTREE | | |
| max_index | 1 | id_2 | 1 | id | A | 0 | NULL | NULL | | BTREE | | |
| max_index | 1 | string | 1 | string | A | 0 | NULL | NULL | YES | BTREE | | |
| max_index | 1 | hiduke | 1 | hiduke | A | 0 | NULL | NULL | YES | BTREE | | |
| max_index | 1 | id_3 | 1 | id | A | 0 | NULL | NULL | | BTREE | | |
| max_index | 1 | id_3 | 2 | string | A | 0 | NULL | NULL | YES | BTREE | | |
| max_index | 1 | id_3 | 3 | hiduke | A | 0 | NULL | NULL | YES | BTREE | | |
+-----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
7 rows in set (0.00 sec)
- Table テーブル名
- Non_unique インデックス内で重複を許すか否か(0:許さない 1:許す)。
- Key_name インデックス名
- Seq_in_index インデックス内のカラムシーケンス番号。複合インデックスの場合、1から加算されていく。
- Column_name カラム名
- Collation インデックス内でカラムの値をどのようにソートするか(A:昇順 Null:ソートしない)。
- Cardinaly 濃度。前述。
- Sub_part 部分インデックスされていた場合は文字数。全体インデックスではNull。
- Packed どのようにパック(?)するか
- Null カラムにNullが含まれるならYes。それ以外はNo。
- Index_type BTREE とか RTREE とか
- Comment コメント
- Index_comment
--コメントをつける
ADD UNIQUE INDEX `name` (name) COMMENT 'hoge';
--コメントの更新は無いので、一度 Drop してから Add する
InnoDB では show index すると ANALYSE TABLE が走るそうで、テーブル数が多いとそれなりに時間がかかってしまうので注意。
おまけ:QEP レポートの読み方
漢のコンピュータ道の記事 を読もう!