はじめに
手持ちの技術に 強化学習 をプラスしてみたい!と思い、
100行で動くシンプルな壁打ちゲームを作り、実応用への足がかりを作りました。
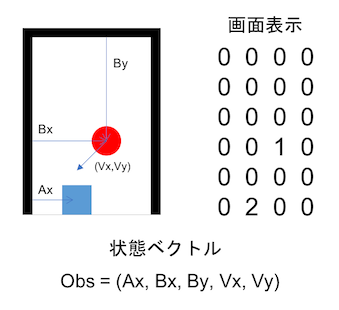
こんな感じのボールが落ちてくるのを跳ね返し続けるゲームを作ります。
ボールは斜めに移動して左右上の壁に反射します。
OpenAI/Gymのサンプルは動いたけど、その後どうしたらいいか分からない!
そんな方のための実践チュートリアルです。
できること
chainerベースの強化学習フレームワークchainerRLを使って、
実問題への適用を見据えた実装方法を身につける。
シミュレータの作成方法や、データの食わせ方を重点的に解説。
前提知識
-
問題に強化学習を適用したい
- python基礎知識
- chainerのネットワークの書き方
-
チューニングしたい
- 強化学習基礎知識
- 深層学習のチューニング知識
環境
- pipが使える環境
手順
環境構築
基本的なpythonモジュール以外に、今回は必要なのは以下の2つです。
$ pip install chainer
$ pip install chainerrl
実行
いきなりですが、こちらが今回使用するソースコードの全てになりますので、
とりあえず実行してみましょう。
main.py
import chainer, chainerrl
import chainer.functions as F
import chainer.links as L
import numpy as np
class Board():
def reset(self):
self.boardW, self.boardH = (4,6)
self.actNum = 3 #0:left 1:stay 2:right
self.obs = np.array([0] * 5, dtype=np.float32)
self.barPosX = np.random.randint(0, self.boardW)
self.ballPosX = np.random.randint(0, self.boardW)
self.ballPosY = 0
self.ballSpeedX = np.random.choice([-1,1])
self.ballSpeedY = 1
self.setObs()
self.count = 0
self.reward, self.done, self.info = 0, False, 0
return self.obs
def step(self, action):
self.barPosX = np.clip(self.barPosX + action - 1, 0, self.boardW - 1)
if (self.ballPosX == (self.boardW - 1)) and (self.ballSpeedX == 1): self.ballSpeedX *= -1
if (self.ballPosX == 0) and (self.ballSpeedX == -1): self.ballSpeedX *= -1
if (self.ballPosY == 0) and (self.ballSpeedY == -1): self.ballSpeedY *= -1
if (self.ballPosY == (self.boardH - 2)) and (self.ballSpeedY == 1) and (self.ballPosX == self.barPosX): self.ballSpeedY *= -1
self.ballPosX += self.ballSpeedX
self.ballPosY += self.ballSpeedY
self.setObs()
self.check()
return self.obs, self.reward, self.done, self.info
def setObs(self):
self.obs[0] = self.barPosX
self.obs[1] = self.ballPosX
self.obs[2] = self.ballPosY
self.obs[3] = self.ballSpeedX
self.obs[4] = self.ballSpeedY
def check(self):
self.reward = 1
if ( self.ballPosY == (self.boardH - 1) ): #ball miss
self.reward = -1
self.done = True
def get_random(self):
self.count += 1
return np.random.randint(0, self.actNum)
def show(self):
board = np.zeros((self.boardH,self.boardW),dtype="uint8")
board[self.boardH - 1, self.barPosX] += 2 #bar pos
board[self.ballPosY, self.ballPosX] += 1 #ball pos
print board
class QFunction(chainer.Chain):
def __init__(self, obs_size, n_actions, n_hidden_channels=50):
super(QFunction,self).__init__()
with self.init_scope():
self.l0 = L.Linear(obs_size, n_hidden_channels)
self.l1 = L.Linear(n_hidden_channels, n_hidden_channels)
self.l2 = L.Linear(n_hidden_channels, n_actions)
def __call__(self, x, test=False):
h = F.tanh(self.l0(x))
h = F.tanh(self.l1(h))
return chainerrl.action_value.DiscreteActionValue(self.l2(h))
if __name__ == '__main__':
env = Board()
obs = env.reset()
q_func = QFunction(len(obs), env.actNum)
optimizer = chainer.optimizers.Adam(eps=1e-2)
optimizer.setup(q_func)
explorer = chainerrl.explorers.ConstantEpsilonGreedy(
epsilon=0.3, random_action_func=env.get_random)
replay_buffer = chainerrl.replay_buffer.ReplayBuffer(capacity=10 ** 6)
phi = lambda x: x.astype(np.float32, copy=False)
agent = chainerrl.agents.DoubleDQN(
q_func, optimizer, replay_buffer, 0.95, explorer,
replay_start_size=500, update_interval=1,
target_update_interval=100, phi=phi)
n_episodes = 2000
max_episode_len = 20
for i in range(n_episodes):
obs = env.reset()
reward = 0
done = False
R = 0 # return (sum of rewards)
t = 0 # time step
while not done and t < max_episode_len:
action = agent.act_and_train(obs.copy(), reward)
obs, reward, done, _ = env.step(action)
R += reward
t += 1
print('train episode:', i,'R:', R,'count:',env.count,'step:',t,'statistics:', agent.get_statistics())
agent.stop_episode_and_train(obs.copy(), reward, done)
obs = env.reset()
done = False
R = 0
while not done and R < 400:
action = agent.act(obs)
obs, r, done, _ = env.step(action)
R += r
env.show()
print('test episode R:', R)
agent.stop_episode()
agent.save('dqn')
実行してみます。
実行結果
$ python main.py
...
('train episode:', 52, 'R:', 3, 'count:', 3, 'step:', 5, 'statistics:', [(u'average_q', 0.24567883822999628), (u'average_loss', 0)])
('train episode:', 53, 'R:', 11, 'count:', 3, 'step:', 13, 'statistics:', [(u'average_q', 0.25106125202616203), (u'average_loss', 0)])
('train episode:', 54, 'R:', 3, 'count:', 2, 'step:', 5, 'statistics:', [(u'average_q', 0.25317720807478716), (u'average_loss', 0)])
('train episode:', 55, 'R:', 11, 'count:', 6, 'step:', 13, 'statistics:', [(u'average_q', 0.2577657894875707), (u'average_loss', 0.02516701301910641)])
('train episode:', 56, 'R:', 11, 'count:', 6, 'step:', 13, 'statistics:', [(u'average_q', 0.2655705760612799), (u'average_loss', 0.08972413337488144)])
('train episode:', 57, 'R:', 35, 'count:', 13, 'step:', 37, 'statistics:', [(u'average_q', 0.3048601307220809), (u'average_loss', 0.1785357757540371)])
('train episode:', 58, 'R:', 3, 'count:', 1, 'step:', 5, 'statistics:', [(u'average_q', 0.31081320388353867), (u'average_loss', 0.1808825276270996)])
('train episode:', 59, 'R:', 11, 'count:', 8, 'step:', 13, 'statistics:', [(u'average_q', 0.32634025431816477), (u'average_loss', 0.19655909918389508)])
('train episode:', 60, 'R:', 11, 'count:', 4, 'step:', 13, 'statistics:', [(u'average_q', 0.34320583453654874), (u'average_loss', 0.21036073665818963)])
...
[[0 0 0 0]
[0 1 0 0]
[0 0 0 0]
[0 0 0 0]
[0 0 0 0]
[0 0 0 2]]
[[1 0 0 0]
[0 0 0 0]
[0 0 0 0]
[0 0 0 0]
[0 0 0 0]
[0 0 0 2]]
('test episode R:', 400)
2000回の学習が走ったあとに、学習したエージェントが実際のゲームをプレイしてくれます。
400ステップでタイムアウトするまでボールを打ち続けていることから、うまく学習できたと言えるでしょう。
ここからは各行の詳細説明です。
必要モジュールの導入1〜4
import chainer, chainerrl
import chainer.functions as F
import chainer.links as L
import numpy as np
さきほどインストールしたchainerとchainerRLをimportしましょう。
次にゲームの盤面を定義していきます。
分かりやすいようにコメントを入れていきます。
Boardクラス5〜48行目
class Board():
def reset(self):
self.boardW, self.boardH = (4,6) #ゲーム画面のサイズ
self.actNum = 3 #0:left 1:stay 2:right #バーが取れる動きの数
self.obs = np.array([0] * 5, dtype=np.float32) #エージェントが観測できる状態ベクトル
self.barPosX = np.random.randint(0, self.boardW) #バーの初期位置X
self.ballPosX = np.random.randint(0, self.boardW) #ボールの初期位置X
self.ballPosY = 0 #ボールの初期位置Y
self.ballSpeedX = np.random.choice([-1,1]) #ボールの水平方向初期速度
self.ballSpeedY = 1 #ボールの下向き初期速度
self.setObs() #バーとボールの位置を状態ベクトルに反映
self.count = 0
self.reward, self.done, self.info = 0, False, 0
return self.obs
def step(self, action):
#バーの位置更新
self.barPosX = np.clip(self.barPosX + action - 1, 0, self.boardW - 1)
#ボールの反射計算
#右壁反射
if (self.ballPosX == (self.boardW - 1)) and (self.ballSpeedX == 1):
self.ballSpeedX *= -1
#左壁反射
if (self.ballPosX == 0) and (self.ballSpeedX == -1):
self.ballSpeedX *= -1
#上壁反射
if (self.ballPosY == 0) and (self.ballSpeedY == -1):
self.ballSpeedY *= -1
#バーにあたって反射
if (self.ballPosY == (self.boardH - 2)) and (self.ballSpeedY == 1) and (self.ballPosX == self.barPosX):
self.ballSpeedY *= -1
#ボールの位置更新
self.ballPosX += self.ballSpeedX
self.ballPosY += self.ballSpeedY
self.setObs() #状態ベクトルへの反映
self.check() #失敗の確認
return self.obs, self.reward, self.done, self.info
def setObs(self): #状態ベクトルへの反映
self.obs[0] = self.barPosX
self.obs[1] = self.ballPosX
self.obs[2] = self.ballPosY
self.obs[3] = self.ballSpeedX
self.obs[4] = self.ballSpeedY
def check(self): #失敗の確認
self.reward = 1
if ( self.ballPosY == (self.boardH - 1) ):
self.reward = -1 #マイナスの報酬
self.done = True #終了させる
def get_random(self): #探索のためのランダムアクション
self.count += 1
return np.random.randint(0, self.actNum)
def show(self): #状態を描画
board = np.zeros((self.boardH,self.boardW),dtype="uint8")
board[self.boardH - 1, self.barPosX] += 2 #bar pos
board[self.ballPosY, self.ballPosX] += 1 #ball pos
print board
次に状態を観測してアクションを決定するQ関数を定義します。
Q関数クラス49〜59行目
class QFunction(chainer.Chain):
def __init__(self, obs_size, n_actions, n_hidden_channels=50): #層の初期化
super(QFunction,self).__init__()
#obs_size 状態ベクトルの長さ(入力要素数)
#n_actions 選択可能な行動の数(出力要素数)
with self.init_scope():
self.l0 = L.Linear(obs_size, n_hidden_channels)
self.l1 = L.Linear(n_hidden_channels, n_hidden_channels)
self.l2 = L.Linear(n_hidden_channels, n_actions)
def __call__(self, x, test=False): #行動の選択
h = F.tanh(self.l0(x))
h = F.tanh(self.l1(h))
return chainerrl.action_value.DiscreteActionValue(self.l2(h)) #ヒストグラム中で最も可能性が高い行動を選ぶ
最後に盤面とQ関数を利用した、学習とテストのコードです。
メイン関数61〜100行目
if __name__ == '__main__':
#環境の構築
env = Board()
obs = env.reset()
#Q関数生成
q_func = QFunction(len(obs), env.actNum)
#学習収束アルゴリズムの設定 これは一般的なDeepLearningでも出てくる話ですね。
optimizer = chainer.optimizers.Adam(eps=1e-2)
optimizer.setup(q_func)
#ランダムに探索する時の設定
#正解にたどり着くために、学習時はランダムに動くことも必要です。
#0.3の割合で、環境を見ずに、取れるアクションの中からランダムに決定することを設定しています。
explorer = chainerrl.explorers.ConstantEpsilonGreedy(
epsilon=0.3, random_action_func=env.get_random)
#状態データを貯めるためのバッファの設定
#DQNは、ReplayBuuferといって、実行順序による学習の偏りを防ぐために実行した状態とアクションを貯めておいてから、そこから学習データを作成します。
replay_buffer = chainerrl.replay_buffer.ReplayBuffer(capacity=10 ** 6)
phi = lambda x: x.astype(np.float32, copy=False)
#エージェントの作成
#どのQ関数を使用するか、収束アルゴリズムは何か、ReplayBufferはどれを使うか、ランダムに探索する時のアルゴリズムなどを設定してエージェントを作成します。
agent = chainerrl.agents.DoubleDQN(
q_func, optimizer, replay_buffer, 0.95, explorer,
replay_start_size=500, update_interval=1,
target_update_interval=100, phi=phi)
#学習回数のパラメータ設定
n_episodes = 2000 #学習回数
max_episode_len = 20 #一回の学習でのステップ数
#学習の開始
for i in range(n_episodes):
obs = env.reset() #環境を毎回リセット
reward = 0
done = False
R = 0 # 報酬の合計用変数
t = 0 # 実行ステップ数
while not done and t < max_episode_len:
action = agent.act_and_train(obs.copy(), reward) #アクションの決定+学習
# ここでobsにcopyを入れるのが重要 これがないとこのケースでは学習できない。
# copyを渡しておかないと中身が書き換えられてしまうのかもしれません。
obs, reward, done, _ = env.step(action) #ステップ実行
R += reward #報酬を累計
t += 1
print('train episode:', i,'R:', R,'count:',env.count,'step:',t,'statistics:', agent.get_statistics())
agent.stop_episode_and_train(obs.copy(), reward, done)
#ここまでが学習です。
#学習結果のテスト開始
obs = env.reset() #環境初期化
done = False
R = 0
while not done and R < 400: #ボールを落とすか、報酬合計が400になるまで実行
action = agent.act(obs)
obs, r, done, _ = env.step(action)
R += r
env.show()
print('test episode R:', R)
agent.stop_episode()
agent.save('dqn') #環境を保存
以上です、chainerRLを使って、それ以外の部分は全て実装することができました。