PowerAutomateでワークフローを作っているとき、ExcelテーブルやSPOリストから取得したレコードを、そのレコード内の特定の列の値をキーにしてグルーピングしたい、ということがたまにあります。
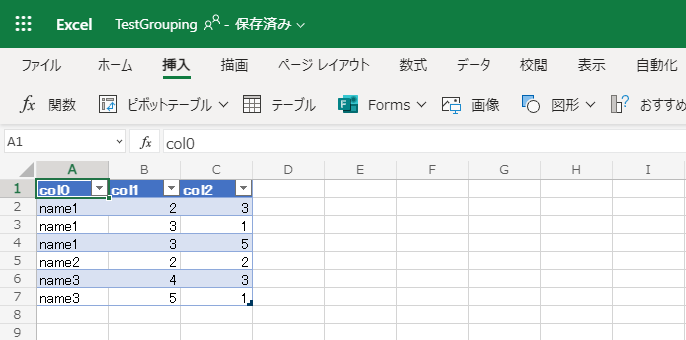
例えば、以下のようなテーブルないしリストから取得したレコードセット(データ型のイメージとしては Array<{[key: string]: any}> )があっとき:
| col0 | col1 | col2 |
|---|---|---|
| "name1" | 2 | 3 |
| "name1" | 3 | 1 |
| "name1" | 3 | 5 |
| "name2" | 2 | 2 |
| "name3" | 4 | 3 |
| "name3" | 5 | 1 |
col0 の値をキーにグルーピングをして、この値をキー、同じ値を持つレコードのセットを値とするマップをつくったり(データ型のイメージとしては { [key: string]: Array<{[key: string]: any}> } ):

col0 の値が同じレコードの件数を求めたり(データ型のイメージとしては { [key: string]: number } ):

col0 の値が同じレコード同士で col2 の値を合算たり(データ型のイメージとしてはこれも { [key: string]: number } ):

あとはグルーピングとは少し異なりますが、 col0 の値に一意性があると仮定するか、重複したら最初の1件以外は捨ててよしという前提をつけて、 col0 をキーにレコードを検索できるようにマップをつくったり(データ型のイメージとしては { [key: string]: {[key: string]: any} } ):

Problem
ところで、PowerAutomate では今のところ、こうした配列構造からマップ構造(辞書構造)を作るアクションや関数は提供されていません。組み込みのアクションの中にある「選択」(select)は配列構造から配列構造を作り出すだけです。
Solution
解決策の1つは、Office Scriptsです。Office Scriptsの機能を使えば、TypeScriptの表現力を借りて配列構造からマップ構造への変換が簡単に行なえます。
この方法のメリットは速度とワークフローがすっきりすることで、デメリットはグルーピング処理がPowerAutomateのワークフローの「外で」行われることとフローの理解にTypeScriptの読解力が必要ということです。
解決策のもう1つは、PowerAutomateが組み込みで提供するアクションを組み合わせてなんとかするというものです。
この方法のメリットはグルーピング処理がPowerAutomateのフローの「内で」完結しTypeScriptの読解力が不要であることで、デメリットは速度とワークフローがごちゃつくことです。
プランA: Office Scriptsを使用する
Office Scriptsの main 関数は、例えば、次のようになるでしょう:
function main(workbook: ExcelScript.Workbook, records: object[], key: string)
{
const keySelector = (record: {}) => `${records[groupBy]}`;
const valueSelector = (groupRecords: object[]) => {
/* ...ここにレコードを集約するロジックを記載... */
return 0/* 集約結果 */;
};
const map: any = {};
new Set<string>(records.map(keySelector)).forEach(
group => {
map[group] = valueSelector(
records.filter((r: any) => r[groupBy] === group)
);
}
);
return JSON.stringify(map);
}
餅は餅屋に。シンプルです。
フロー外にロジックが出てしまう点やTypeScriptの読解力が必要になってしまう点をどう考えるか次第で、この方法を採用/不採用を決めることになるでしょう。
プランB: アクションを組み合わせる
先に、フローの全体像を示してから、個々のアクションについて説明していきます:
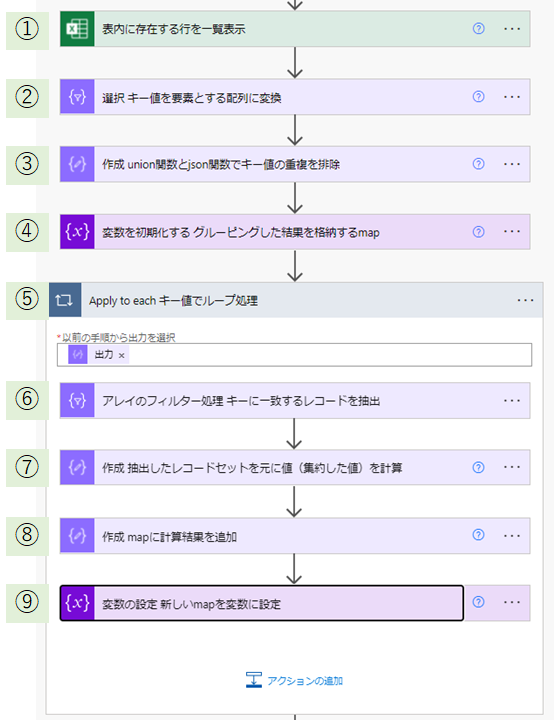
①何はともあれデータを取ってきます。ここではExcelテーブルから先程表組みで示したサンプルデータのレコードセットを取得しています。
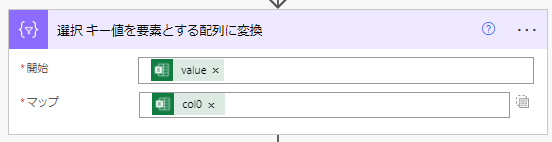
②「選択」アクションを用いて、レコードセットの各レコードが持つキー値を要素とする配列(この時点では同じキー値の重複を含む)に変換します。
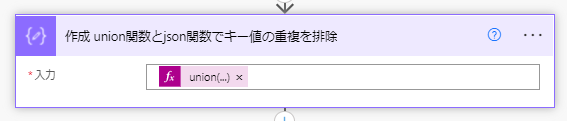
③ 「作成」アクションと関数を用いて、キー値の配列から重複を排除します。
式は次のように記述します: union(body('選択_キー値を要素とする配列に変換'),json('[]')) 。
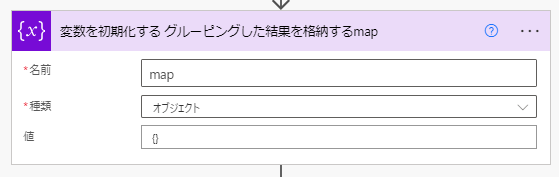
④ このあとのループ処理でグルーピングし集約処理した結果を格納するためのオブジェクト型変数 map を初期化します。
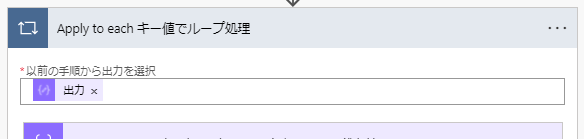
⑤「Apply to each」アクションを用いて、 ③ で作成したキー値の配列の要素ごとに処理を行います。
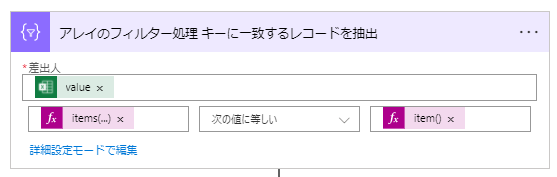
⑥「アレイのフィルター処理」アクションを用いて ① で取得したレコードセットから キー値が一致するレコードを抽出します。
「Apply to each」と「アレイの~」で実質二重のループ処理になるので「現在の要素」の区別が重要です。右辺:左辺 = items('Apply_to_each_キー値でループ処理'):item()['col0'] 。
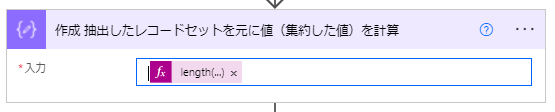
⑦「作成」アクションを用いて ⑥ の抽出結果のレコードセットを元に集約処理を行います。
今回は件数を数えています: length(body('アレイのフィルター処理_キーに一致するレコードを抽出')) 。
⑧「作成」アクションを用いて ⑦ の計算結果を ④ の map に追加します。
オブジェクトのプロパティ追加は次のようにします: addProperty(variables('map'),items('Apply_to_each_キー値でループ処理'),outputs('作成_抽出したレコードセットを元に値(集約した値)を計算')) 。

⑨「変数の設定」アクションを用いて ⑧ の計算結果を ④ の map に再代入します。
addProperty 関数は引数のオブジェクトそのものを変更するのではなく、オブジェクトのコピーに変更を適用して出力します(副作用を発生させない)。このため今回の例では再代入が必要になります。
今回、⑦ではレコードの件数を数えて出力していますが length(body(⑥))、レコードセットそのものを返したり body(⑥)、ここでレコードセットの1件目を取り出したり first(body(⑥)) することもできます。
特定の列の値を合算する
特定の列の値を集計するときは少し厄介で、xml 関数と xpath 関数の力を借ります:
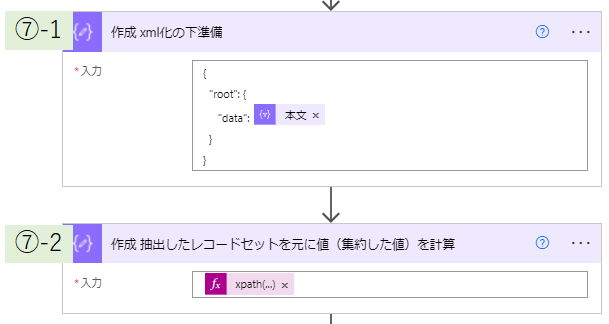
⑦-1 「作成」アクションを用いて(新規) xml 関数が処理できるようにレコードセットの配列をくるむオブジェクトを作ります。
⑦-2 「作成」アクションを用いて(既存) ⑦-1 で作成したオブジェクトをXML化したあと、XPathを用いて 特定の列(この例では col2)の値を合算します。
式は次のようになります: xpath(xml(outputs('作成_xml化の下準備')),'sum(//col2)') 。
XPathでもできない場合、「Apply to each」の入れ子をせざるをえないでしょう。
PowerAutomateの組み込みアクションを組み合わせて用いる方法はお世辞にもシンプルとは言い難いものですが、Office Scriptsの利用があまり好ましくないと考えられる場合は仕方ありません、ごちゃごちゃしてしまう問題はグルーピング処理全体を「スコープ」でくるんでしまうなどして誤魔化しましょう。