この記事で行うこと
京都の名産品についてのテキストを分析し,名産品のこだわりについて調べたり,名産品の類似度を調べて似たものをオススメしてくれるようにできないかなと模索した内容
実行した環境&事前準備
ツール: MATLAB R2018a
ツールボックス: Text Analytics Toolbox
京都市オープンデータポータルサイト の 京都観光見もの情報 から csvファイル DSOURVENIR.csv を取得したデータをこのファイルを同じ階層に保存して読み込んでいます.
ストップワードは Slothlib から取得したものを stopwords_jp.txt として保存しています.
MeCab は MeCab.exe をコンパイルして dll をコールして使用しています.コンパイルして使用するための説明書 を参考にしました.
二つのメソッド loadMeCab, parsePOS は loadMeCab.m 内で定義されています.(最下部 reference を参照)
事前の設定
clear all; clc;
warning off
addpath(fullfile(pwd,'\libmecab_x64'))
データの読み込み
csvfile = 'DSOURVENIR.csv';
% データ読み込みの前に,detectImportOptions の SelectedVariableNames オプションを指定して読み込む列を指定
% (他の列は読み込まない)
opts = detectImportOptions(csvfile);
opts.SelectedVariableNames = {'Var9', 'Var13'};
% ヘッダが付いていないため,名産品の名前を names,説明を explanations として読み込み
data = readtable(csvfile, opts);
data.Properties.VariableNames = {'names', 'explanations'};
前処理1: MeCab の出力から必要情報のみを抽出し,使用できる形式に整形
% 形態素解析器 MeCab の dll の呼び出し
mcb = loadMeCab;
% データの分割と整形
% MeCab で出力された結果の1列目 (token) と2列目 (品詞) を抽出して解析に使用したい
for i=1:height(data)
% loadMeCab クラスの parsePOS メソッドを使って形態素解析を実行
allstr = string( parsePOS(mcb, data.explanations{i}) );
% 行ごとに分割
allwords_detailed = splitlines(allstr);
% 最後の2行を削除
allwords_detailed = allwords_detailed(1:end-2,:);
% スペースで区切られている内容を列に分割
mtx = split(allwords_detailed, ' ');
% comma が少ない (6個しかない) 行に comma を追加
num_comma = count(mtx(:,2), ',');
idx = (num_comma == 6);
mtx(idx,2) = strcat( mtx(idx,2), ",," );
% comma で区切られている内容を列に分割
mtx(:,2:10) = split(mtx(:,2), ',');
% 名詞のみの抽出し,ベクトルをひとまとめにして整形
idx = contains(mtx(:,2), "名詞");
wordvec(i,:) = strjoin( mtx(idx,1)' ) ;
end
WordCloud による可視化
wordcloud( wordvec );
% 句読点の削除
wordvec = erasePunctuation( wordvec );
% tokenization (文字列の連続であるテキストを,意味のある単位に分割)
tokenizedDoc = tokenizedDocument( wordvec );

京都ですよね.わかります.
「さ」「的」「もの」などは関係なさそうなので取り除きたい.ストップワードを定義して取り除く処理を行います.
前処理2: ストップワードの削除
% ストップワードの読み込み
stopword_file = 'stopwords_jp.txt';
stopWords_jp = import_stopwords(stopword_file);
tokenizedDoc = removeWords(tokenizedDoc, [stopWords_jp]);
単語のノーマライズ
tokenizedDoc = normalizeWords(tokenizedDoc);
bow = bagOfWords(tokenizedDoc)
% WordCloud による可視化
wordcloud(bow);

京都の名産品のこだわりは技術,伝統であり,有名なものは菓子,人形,料理,工芸なのでしょうか.
解析: 潜在的意味解析を使った名産品説明テキスト間の類似度の算出
% 潜在的なトピック数を3に設定
numComponents = 3;
% 特徴量強度指数を 0.5 に設定
exponent = 0.5;
mdl = fitlsa(bow, numComponents, ...
'FeatureStrengthExponent',exponent)
dscores = mdl.DocumentScores;
% 各名産品の類似度を,スコアベクトルにもとづいて描画
figure
dnum = [34 107 94 101];
dend = dscores(dnum,:);
quiver3(0,0,0, dend(1,1), dend(1,2), dend(1,3),'k')
hold on
quiver3(0,0,0, dend(2,1), dend(2,2), dend(2,3),'b')
quiver3(0,0,0, dend(3,1), dend(3,2), dend(3,3),'r')
quiver3(0,0,0, dend(4,1), dend(4,2), dend(4,3),'m')
hold off
title("Document Scores")
legend(["京漆器", "湯豆腐", "京湯葉","精進料理"],'Location','bestoutside')
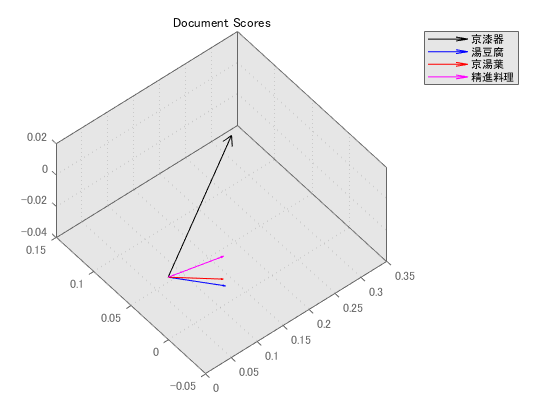
湯豆腐,京湯葉,精進料理と食べ物類は2次元目までのドキュメントスコアがほぼ同じ.京漆器だけ別世界となっている.
テキスト解析をやってみた所感
- 対象テキストがただの説明文だとあまりおもしろくない.逆に個性があったり感情が入っている文章は意外な結果がみれそう.
- Deep Learning (LSTMとか) を使ってみたいけれど,それを使うような難易度の高そうな分類や回帰の状況を作るのが難しい.
- 前処理が重要,手間がかかる.
- 京都に行きたい.
reference
Simple TextMiner を参考に,クラスを作成して loadMeCab.m として保存しました.
(Simple TextMiner は parse.m など既存の関数名と重複する関数があったため)
classdef loadMeCab < handle
%% properties
properties
vname ={...
'Surface', 'PartsOfSpeech', 'POS_SubType1', 'POS_SubType2', 'POS_SubType3', ...
'ConjugatedForm', 'Conjugation', 'OriginalForm', 'Reading', 'Pronunciation'};
vdesc = {...
'表層型', '品詞', '品詞細分類1', '品詞細分類2', '品詞細分類3', ...
'活用形', '活用型', '原形', '読み', '発音'};
mecab
end
%% methods
methods(Static)
function loadLibrary()
if ~libisloaded('libmecab')
fname_library = 'libmecab.dll';
fname_header = 'mecab.h';
[notfound,warnings] = loadlibrary(fname_library, fname_header)
end
end
end
%%
methods
function obj = loadMeCab()
obj.loadLibrary
argv = libpointer('stringPtrPtr', {'MeCab'});
argc = 1;
obj.mecab = calllib('libmecab', 'mecab_new', argc, argv);
end
%%
function result = parsePOS(obj, input)
result = calllib('libmecab', 'mecab_sparse_tostr', obj.mecab, input);
end
%%
function delete(obj)
calllib('libmecab', 'mecab_destroy', obj.mecab)
end
end
end