はじめに
少し前、こちらのイベントに登壇させていただきました。
https://connpass.com/event/318555/
その際に発表したスライドの内容を本記事にまとめました。
生成AIのインパクトとWatsonx.ai
まず、セッション前に私と生成AIの関わりについてお話しします。
近年の生成AIで私に大きなインパクトを与えたのは、2022年末に登場したChatGPTです。
その自然な応答とある程度の回答精度に驚き、今後、ビジネスで多く活用されると感じました。
一方で、今までの経験でデータ基盤やBIツールの仕事を通して接してきた、国内企業は、データを外部に接続することへ警戒感を持つことが多いと感じていました。
そんな中で、昨年Watsonx.aiが登場しました。この製品はIBM Cloud上で動作しますが、自社のアカウント内で完結する生成AI実行環境を提供します。そのため、データを外部に繋ぐことへ抵抗がある企業に非常に相性が良いと私は感じました。
今回は、機会があり、Watsonx.aiとWatsonx.dataに追加されたベクトルデータベースであるMilvusを利用して、社内のデータを活用した対話型AIのデモをNotebookとPythonスクリプトで作成しましたので、そのナレッジを紹介させていただきます。
社内のデータ活用としてのRAG
自然な回答に驚いた大規模言語モデル(LLM)にも問題点はあります。
LLMはインターネットに公開されている情報等から学習している情報以外の情報については適切な回答ができません。
ここまで、社内のデータ活用というキーワードを用いてきましたが、RAG(Retrieval-Augmented Generation:拡張検索生成)という技術を使って、LLMに「自社独自の情報」や「今日のニュース」などの学習していない情報の検索が可能になります。
外部情報データベースに問い合わせる際の外部情報DBにはベクトルデータベースというデータベースが使われます。
RAGで利用されるベクトルデータベースとは
前項最後に書きましたが、外部情報DBに使われるベクトルデータベースについても簡単に説明します。
RAGでは、質問に対する関連情報を効率的に検索する必要があります。ベクトルデータベースは、類似検索を迅速に行うことができます。質問やドキュメントをベクトルとして表現し、類似度計算により関連性の高い情報を特定します。
ベクトルデータベースは、単語やフレーズの意味的な類似性を捉えるためにトレーニングされた埋め込み(エンベディング)モデルを使用します。これにより、単なるキーワードマッチングではなく、意味的に関連する情報を取得することができます。例えば、「会社の場所」と「会社の住所」は異なる表現ですが、ベクトル空間では近接しています。
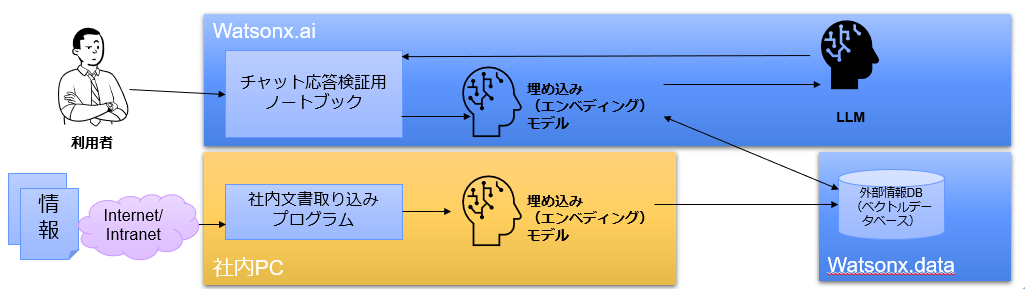
データ活用AIチャットデモ環境の概要
今回はノートブックとPythonスクリプトを作成しました。
それぞれについて、簡単に解説します。
- 社内文書取り込みプログラム(Pythonスクリプト)
Webサイトの情報を取得し、埋め込みモデルを利用してサイト内文書をベクトル化し、Watsonx.dataで提供されるベクトルデータベース(Milvus)に格納します。 - チャット応答検証用ノートブック
Watsonx.aiのプロジェクト上に作成したノートブックとなります。
言語モデルに質問を投げ、その返答を確認するための動作検証環境として作りました。
社内文書取り込みプログラム(Pythonスクリプト)
このプログラムについて
社内の仮想マシンに小規模なLinux仮想マシンを作ってベクトルデータベースへのインポートの為の社内文書クローラーとする想定で作成しました。
Watsonx.dataのMilvusを利用していますが、オンプレのコンテナ等でも接続定義の変更で利用できます。
このような短いスクリプトで、ベクトルデータベースへの読み込みは可能です。
もう少し機能を盛り込んで、更新があった場合は再読み込みさせるなどの対応も可能かと思います。
環境にインストールしているモジュール
langchain 0.1.16
langchain-community 0.0.38
langchain-core 0.1.52
langchain-ibm 0.1.3
langchain-text-splitters 0.0.1
langdetect 1.0.9
langsmith 0.1.49
pymilvus 2.4.0
selenium 4.18.1
semantic-version 2.10.0
unstructured 0.13.7
unstructured-client 0.22.0
urllib3 2.1.0
これらを入れるために依存関係で必要なものは適時インストールしてください。
コード
import os
from langchain_community.document_loaders import SeleniumURLLoader
from langchain.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Milvus
from dotenv import load_dotenv
# wslib.download_file('config_dojo.env')
load_dotenv('config_dojo.env')
MILVUS_HOST=os.getenv("MILVUS_HOST", None)
MILVUS_PORT=os.getenv("MILVUS_PORT", None)
MILVUS_USER=os.getenv("MILVUS_USER", None)
MILVUS_PASSWORD=os.getenv("MILVUS_PASSWORD", None)
LH_CERTFILE='presto.crt'
# Milvusに読み込ませるURLリスト
urls = [
"https://www.example.com/kaishajoho.html",
"https://www.example.com/kaishajoho/gaiyou.html",
"https://www.example.com/kaishajoho/jigyou.html",
"https://www.example.com/kaishajoho/rinen.html",
"https://www.example.com/kaishajoho/access.html",
"https://www.example.com/kaishajoho/policy.html"
]
loader = SeleniumURLLoader(urls=urls)
data = loader.load()
# ベクトル化するときに使うモデルを指定
embeddings = HuggingFaceEmbeddings(model_name="intfloat/multilingual-e5-base")
# 接続情報の定義
my_connection_args ={
'host': MILVUS_HOST,
'port': MILVUS_PORT,
'user': MILVUS_USER,
'password': MILVUS_PASSWORD,
'server_pem_path': LH_CERTFILE,
'secure':True,
'server_name':'watsonxdata'
}
# ベクトルデータベースにロード
vector_db = Milvus.from_documents(
data,
embeddings,
connection_args=my_connection_args,
drop_old=True,
collection_name = 'LangChainCollection'
)
設定ファイル
# Watsonx.ai側の情報
PROJECT_ID=Watsonx.aiのプロジェクトIDを指定します。WebUIから確認できます。
ACCESS_TOKEN=アクセストークンを指定します。
IBM_CLOUD_URL=自身が利用しているIBMクラウドのリージョンごとのURLを指定します。
API_KEY=APIキーを指定します。
# Watsonx.data側の接続情報(milvusの情報)
MILVUS_HOST=Milvusのホストを指定します。
MILVUS_PORT=Milvusのポートを指定します。
MILVUS_USER=Milvusに接続するユーザーを指定します。
MILVUS_PASSWORD=上記ユーザーのパスワードを指定します。
利用しているモジュールなどの解説
- langchain_community
外部URLローダーであるSeleniumURLLoaderとベクトルデータストアとしてMilvusを利用するためのものを読み込んでいます。
SeleniumURLLoaderで上記リストのURLを読み込みます。
このローダーを選択した理由はJavaScriptなどが組み込まれていたりするChrome等のブラウザを前提としたページも読み込むことができ、Unstructuredというもので、ページ内の必要な文章情報を解析できると解説されていたので利用しました。 - langchain_embeddings
ベクトル化のための埋め込みモデルを利用するためのものを読み込んでいます。
今回は日本語の文書も扱うことができるオープンソースモデルであるmultilingual-e5-baseを利用しています。
他にも選択できるモデルはあるので、今後それぞれの特徴や性能を学んでいきたいと思います。 - langchain_ibm
Watsonx.aiのLLMを利用するために読み込んでいます - langchain
RetrievalQAというRAGを利用するためのものを読み込んでいます。 - langchain_core
strOutputParserはLLMの出力を文字列に変換するもの、PromptTemplateは特定の単語を空けたテンプレートを作成します。
RunnablePassthroughはユーザーからの質問とRAGからの回答を辞書型のデータにしてプロンプトに渡すときに利用します。 - Milvusについて
今回利用したMilvusはWatsonx.dataの検証環境に含まれるものを利用しました
チャット応答検証用ノートブック
Watsonx.aiのプロジェクトに作ったPythonノートブックです。
社内でデータ活用を推進するチームがチーム内での試行錯誤をするために利用することを想定し、作成しました。
具体的にはプロンプト内容を変更したり、大規模言語モデルを切り替えての動作確認を想定しています。
コード
コードブロックごとにWatsonx.aiのJupyterNotebookに入力してください。
# 必要になるモジュールの取得
!pip install langchain_ibm
!pip install langchain_community
!pip install langchain
!pip install langchain_core
!pip install sentence_transformers
!pip install pymilvus==2.3.7
このセルを実行後、Kernelのリスタートを必ず行ってください。
# モジュールのロード
import os
from langchain_ibm.llms import WatsonxLLM
from langchain_community.vectorstores import Milvus
from langchain.chains import RetrievalQA
from langchain.embeddings import HuggingFaceEmbeddings
from langchain_core.prompts.prompt import PromptTemplate
from langchain_core.runnables.passthrough import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
# 変数定義
project_id = Watsonx.aiのプロジェクトIDを指定します。WebUIから確認できます。
ibmcloudurl = 自身が利用しているIBMクラウドのリージョンごとのURLを指定します。
apikey = APIキーを指定します。
MILVUS_HOST = Milvusのホストを指定します。
MILVUS_PORT = Milvusのポートを指定します。
MILVUS_USER = Milvusに接続するユーザーを指定します。
MILVUS_PASSWORD = 'xx'
LH_CERTFILE = 上記ユーザーのパスワードを指定します
#証明書ファイルの作成
crttxt = """\
-----BEGIN CERTIFICATE-----
Watsonx.dataのマニュアルに記載のある方法で自己証明書を取得し、ここにペーストしてください。
-----END CERTIFICATE-----
"""
with open("presto.crt", "w") as f:
f.write(crttxt)
f.close()
# チャット応答に使う言語モデルの設定
model_id = 'meta-llama/llama-3-70b-instruct'
params = {
'decoding_method': 'sample',
'max_new_tokens': 4096,
'top_k': 50,
'top_p': 1,
'repetition_penalty': 1
}
llm = WatsonxLLM(
model_id=model_id,
project_id=project_id,
url=ibmcloudurl,
params=params,
apikey=apikey
)
今回はMeta社がリリースした新しい言語モデルであるLlama3を利用しています。以下はパラメータのメモです
- Decoding_method
greedyとsimpleから選択 - max_new_tokens
生成する最大トークン数 - top_k
モデルが考慮する次の選択肢の候補数を制限 - top_p
選択肢の累積確率で選択を制限 - repetition_penalty
すでに生成された文脈や単語に対してのペナルティを与える。反復防止に効果的
# Milvusへの接続情報定義
my_connection_args ={
'host': MILVUS_HOST,
'port': MILVUS_PORT,
'user': MILVUS_USER,
'password': MILVUS_PASSWORD,
'server_pem_path': LH_CERTFILE,
'secure':True,
'server_name':'watsonxdata'
}
# LangChainのEmbeddingsでベクトル化した時のモデルを利用し、Milvusに接続
# ベクトル化するときに使ったモデルを指定
embeddings = HuggingFaceEmbeddings(model_name="intfloat/multilingual-e5-base")
vector_db = Milvus(
embeddings,
connection_args=my_connection_args,
collection_name = 'LangChainCollection'
)
#ベクトルDBをレトリバー(参照先)として指定
retriever = vector_db.as_retriever()
#プロンプトを指定
template = """
<|begin_of_text|>
<|start_header_id|>system<|end_header_id|>あなたは慎重なアシスタントです。あなたは慎重に指示に従います。あなたは親切で無害で、倫理的なガイドラインに従い、前向きな行動ができます。必ず日本語で回答してください。<|eot_id|>
<|start_header_id|>user<|end_header_id|>
{context}
Human: {question}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
"""
prompt = PromptTemplate(template=template, input_variables=['history', 'user'])
chain = {"context": retriever, "question": RunnablePassthrough() }| prompt | llm | StrOutputParser()
チャットテスト
下記のようなセルを実行することで、チャットの動作確認ができます。
プロンプト指定のセルを編集し再実行することにより、動作の変化を確認することができます。
chain.invoke("A社という会社の場所は?")
回答例
'A社は、東京都千代田区神田和泉町…に本社を置いています。'
今後の展望
今後はGradioやStreamlitを活用してWebUIを使ったデモ等の準備をしていきたいと考えています。