glbic-ptmalloc2のメモ
glibcの勉強した内容をこちらに備忘録として載せておきます。
間違っている記述などあれば指摘をしていただけるとありがたいです。
また、後半になるにつれ、精神の疲労により、語尾がおかしいところが多々あるかもしれません。
目をつぶってくだされば幸いです。
ここに貼っている画像は全て引用したものですので、もちろんこの記事も著作権はございません。
次はheap領域でのexploitの記事でも上げようかなと思います
メモリ領域の確保のシステムコールについて

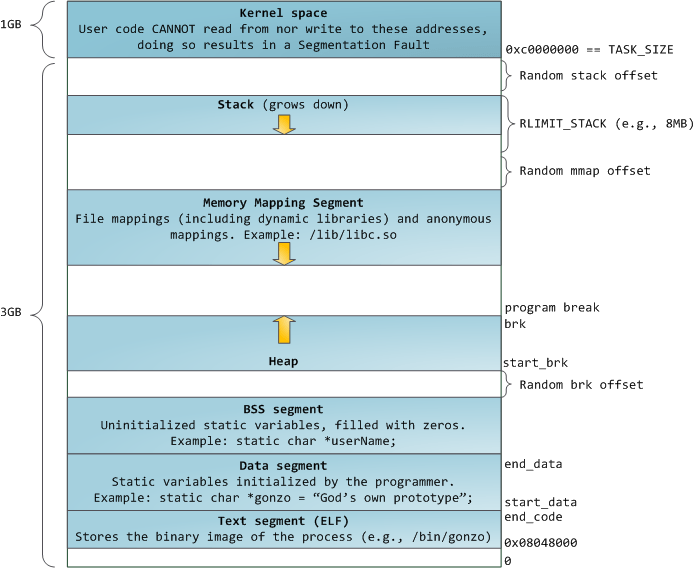
メモリ領域確保について以下の2つの方法がある
brk
brkはprogram break locationの値を動かしてheap領域を操作する。0で埋められていない
- ASLRオフ時
data/bss segmentの終わりとbrk、start_brkの位置が同じ - ASLRオン時
start_brk,brkはdata/bss segementの終わり + ランダムな値(要するに下駄を履かせている状態)
mmap
mmapはプライベートなアノニマスなセグメントをプロセス用に作りだす。そして0で全て埋められている
FREE CHUNK METADATAについて
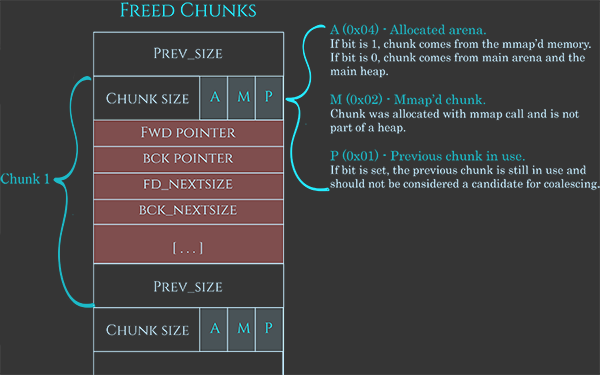
heap領域におけるチャンクの割当て
紛らわしいことに、これらのbinは一つの配列にひとまとめに管理されている

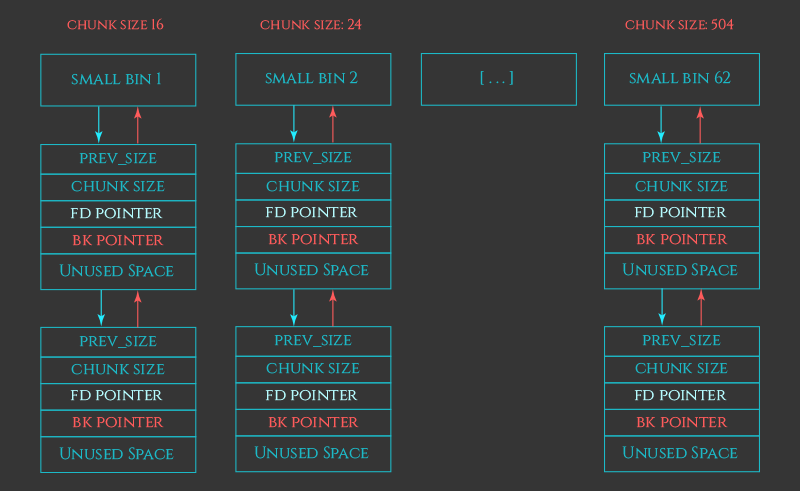
1. small bin
62個のbinがありそれぞれには同じサイズのチャンクが格納されている。
それぞれのチャンクのサイズは32bitOSでは512bytes未満で、64bitOSでは1024bytes未満である。
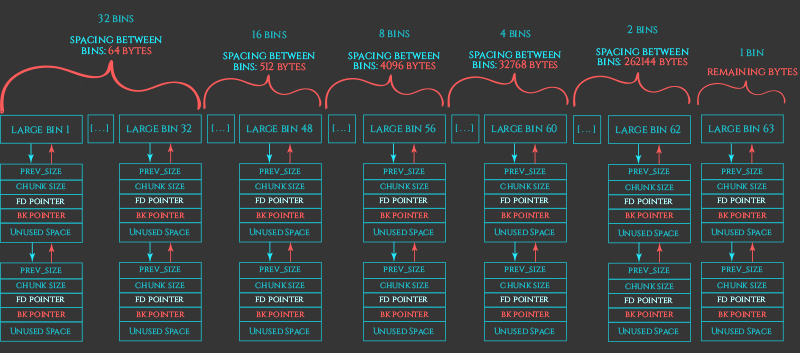
2. large bin
small-binではとれない大きなサイズを取りたいときに使われる。
そしてそのサイズはsmall-binのサイズと他のlarge-binのサイズと重複しないようになっている。
手動的に割り当てるためsmall-binに比べ遅いが、多くのプログラムでは頻繁に小さなサイズを確保することが多いためあまり使われるものではない
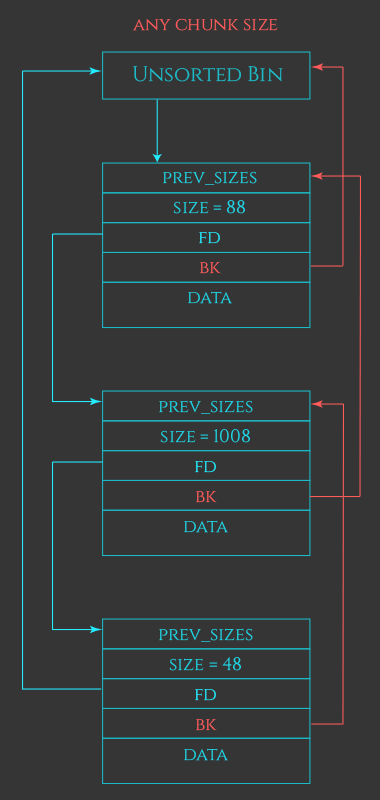
3. UNSORTED bin
以上の基本的なアルゴリズムをさらに最適化するためにunsorted-binというcacheレイヤーが存在する。 これは多くのプログラムを観察したときにfree and allocateは一度に一気に行われることが多いことからそれ用の場所を作ったら都合がいいだろうとのことで作られた。
ここでは以下を簡潔に説明する。
上のような一度に一気に行われる場合では、解決済みの大きなサイズのチャンクのそれぞれをもう一度正しいbinに置く前に、freeされたチャンクたちをマージしておくことでいくつかのオーバーヘッドを回避することができる。
また最近開放された割当てを高速で返すことができれば多くのプロセスで高速化を図れる。
このようにheap-managerはfreedチャンクを新しく即座に正しいbinに置く代わりにそれらを近くのチャンクと合体させてunsorted linked listにぶん投げている。
mallocではunsorted-binのチャンク達がmallocで要求されるsizeに適していたら即座にそれを返し、もし違ったらsmall-binかlarge-binにぶん投げている
4. Fast-bin
fast-binは以上の3つの基本的なbinの上に重ねられたさらなる最適化されたもの。
fast-binは基本的に、最近リリースされた小さなチャンクを「高速ターンアラウンドキュー」に保持し、チャンクを意図的にライブに保ち、チャンクを隣接するものとマージしないため、そのチャンクサイズのmallocリクエストがすぐに届いた場合にすぐに再利用できる。
small-binのようにfastbinではチャンクサイズごとに場所がある。
fast-binはそれぞれ16,24,32,40,48,56,64,72,80 and 88 bytesとチャンクとチャンクメタデータをカバーする10個存在する.
small-binと違いfast-binは隣接するチャンクがマージされない。
これは次のチャンクの最初に'P'bitをsetすることで実装されます。(ここらへんはFREE CHUNK METADATAを参照)
fast-binではチャンクサイズが決まっているので自動的にソートされるので挿入と除去がめっちゃ早い。また、fast-binのチャンクはマージされる候補にない.
fast-binの欠点としてはチャンクは本当にfreeされたわけではなく、またマージされないこと、徐々にメモリのフラグメントが起こる。
この欠点を解決するためにheap-mangaerは定期的に"flush"と呼ばれる動作をする。これにより、fast-binの各エントリが実際に開放され、隣接する空きチャンクとマージされ、mallocで後で使用できるようにunsorted-binに配置される
5. TCACHE (PER-THREAD CACHE) BINS
heap-mangaerが最後に割当の高速化に使用する最後の最適化は"tacache" allocatorと呼ばれるもの
これについて説明する前にtcacheが解決するための問題について見てみる
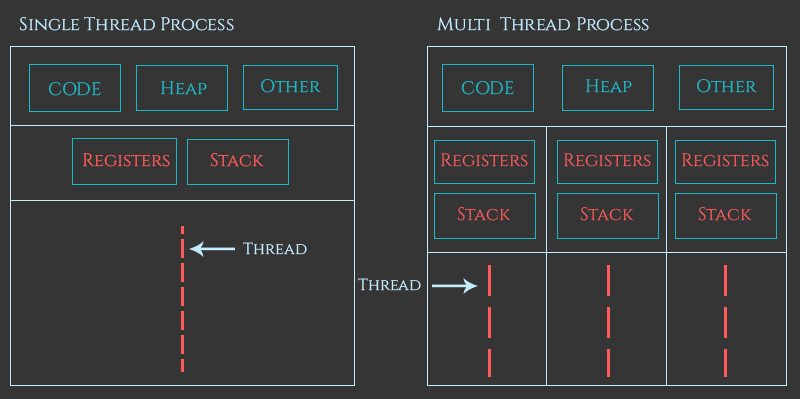
コンピュータの上で動くプロセスたちは同じ時間に一つ、もしくは多くのスレッドを起動しているはずだ。
複数のスレッドを持つことで、プロセスは複数の同時操作を実行できる。
特定のプロセスの各スレッドは同じアドレス空間を共有する。つまり、各スレッドはメモリ内の同じコードとデータを見ることができる。(webサーバなんかをイメージすると良い)
各スレッドは、一時的なローカル変数を格納するために独自のレジスタとスタックを取得するけど、グローバル変数やヒープなどのリソースはすべてのスレッド間で共有される
ヒープなどのグローバルなリソースへのアクセスの調整は複雑なトピックで,これがハッカーによって攻撃される要因を作り出す。
通常、リソースの共有の競合状態を解決するにはそれぞれの使用状態を管理して一方がリソースを使用していた場合に、他はリソースを使用できなくするといういわゆるロック機能を使うがこれはlock contentionという非常に時間と資源を無駄にしてしまう事態に陥ってしまう可能性があることを意味する。
多くのグローバルな変数ではこれは許容できるコストとされるが、全てのスレッドによって継続的に使われるヒープ領域の場合はこのコストはプログラム全体の大きな速度ダウンに繋がってしまう。
heap-managerは主にこの問題をスレッドごとのアリーナ(それぞれのスレッドがあるしきい値にヒットするまで自分自身のアリーナを使う)を使うことによって解決する。
tcacheはスレッド自身のロックのコストを減らすために計画されたもの
この機能はglibc2.26から追加され、デフォルトになってる。(--disable-experimental-mallocで無効にすることができる)
まぁようするにtcacheはスレッドごとのキャッシュってこった。
スレッドごとのキャッシュは、小さなチャンクのスレッドごとのビンをすぐに使用できるようにすることで、割り当てを高速化する。そうなれば、スレッドがチャンクを要求したときに、スレッドのtcacheで使用可能なチャンクがある場合、ヒープロックを待つ必要なしに割り当てを処理できるぜー。
デフォルトではそれぞれのスレッドが64個の単一リンクのtcache-binを持ってる
各ビンには、64ビットシステムでは24〜1032バイト、32ビットシステムでは12〜516バイトの範囲の最大7つの同じサイズのチャンクが含まれる。
結局どうやってチャンクはtcache-binに入るの?
チャンクが開放されたとき、heap-managerはチャンクのサイズがtcache-binの対応するサイズに適しているかどうか見る。
fast-binのようにtcache-binのチャンクは"in use"が割り振られていて(次のチャンクに"p" bitを割り振る)、隣接する開放済みチャンクと結合しない
チャンクサイズが満杯なtcacheな場合はheap-lockをかけて今までと同じ方法を取る
heap-managerのalocationの一連の流れ(まとめ)
1. 対応するサイズのチャンクがtcache-binにあれば、即座にそのチャンクを返す
2. もし、そのリクエストが膨大なら、mmapを介してオフヒープのチャンクを割り当てる
3. それ以外の場合はarena-heapをロックして以下の手順を取る
1. fastbin/smallbinを試す
もし対応するfast-binが存在すればそこからチャンクを取得する。
fast-binに存在しなかった場合はsmall-binから探す
2.すべての延期された解放を解決する
それ以外の場合は、fast-binのエントリを「真に解放」し、それらの統合されたチャンクをunsorted-binに移動する。
unsorted-binのエントリを確認する。もし適していた場合は止める。
そうでなかった場合はunsorted-binをsmall-binやlarge-binに割り振る
3. デフォルトの戦略に切り替える
チャンクサイズがlarge-binに対応している場合は、対応するlarge-binを今すぐ検索します。
4. スクラッチから新しいチャンクを作る
使えるチャンクがなかった時、ヒープのトップからチャンクを撮ってくることを試みる。
もしヒープのトップに十分な空きがなかった場合はsbrkを使ってheap領域を拡大する。
アドレス空間で他の何かに遭遇したためにヒープの先頭を拡張できない場合は、mmapを使用して不連続な拡張を作成し、そこから割り当てる