前回の話では、3つの集合は、A, B, Cが別々の場所で入力され、自分の手元に送られてきた単なるテキストファイルという設定でした。
前回は、A~Cの、改行区切りの値を比較して、「どれが重複していて、どれが重複していないか」をチェックしたのですが、
今回は、すでに単一のテーブルにレコードになっているものを、検索条件で集合に分ける、ということをやってみたいと思います。
むしろ、前回よりもこちらの方がファイルメーカーらしい使い方かもしれません。
ファイルの動作と機能
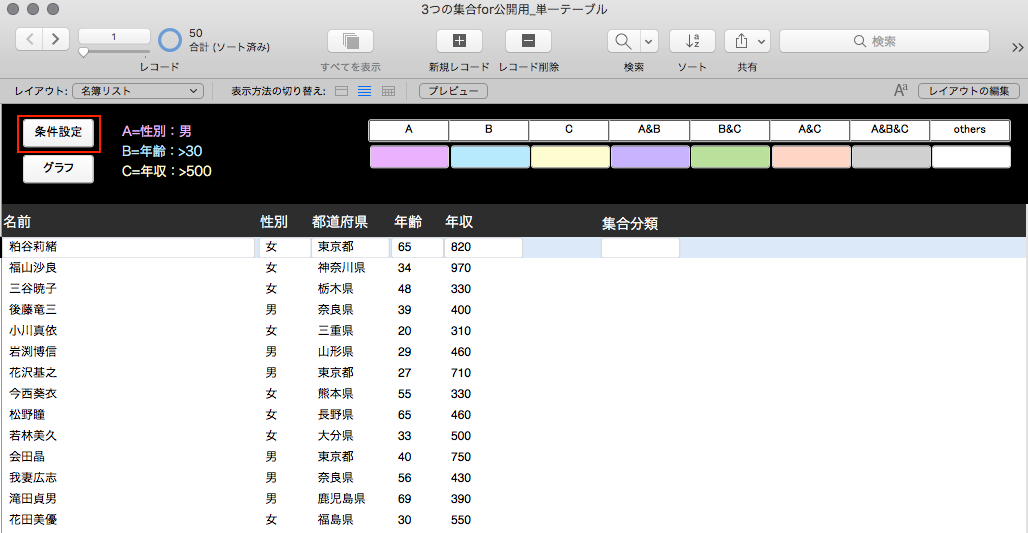
【図 起動時のキャプチャ】
起動時の画面はこんな感じです。
キャプチャを見ればわかりますが、前回の話で出てきた、
A:男性
B:30歳以上
C:年収500万円以上
というような条件を、検索でやってみましょう。
左上の「条件設定」ボタンを押すと、カードウインドウが開きます。
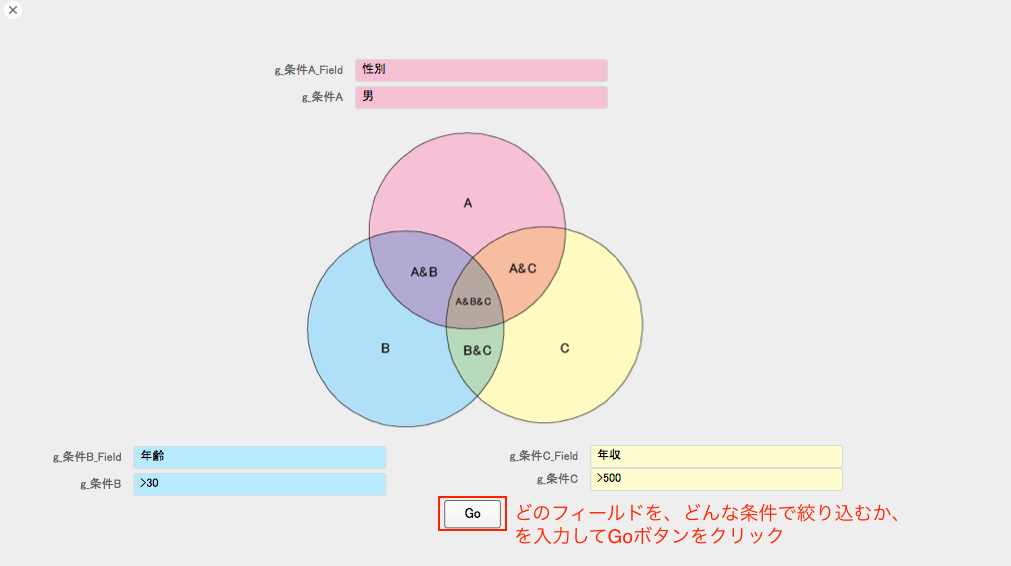
【図 検索条件のキャプチャ】
A, B, Cのそれぞれの条件を入力して(数字の条件式などは検索モードの時と同じ)、「Go」ボタンを押すと、「Aだけに適合する」、「Bだけに適合する」、「Cだけに適合する」、「AとBに適合する」、「AとCに適合する」、「BとCに適合する」、「ABC全てに適合する」、に色分けして分類してくれます。
(前回と異なる特徴として、今回は、「others=どの条件にも適合しない」、が含まれることが挙げられます)
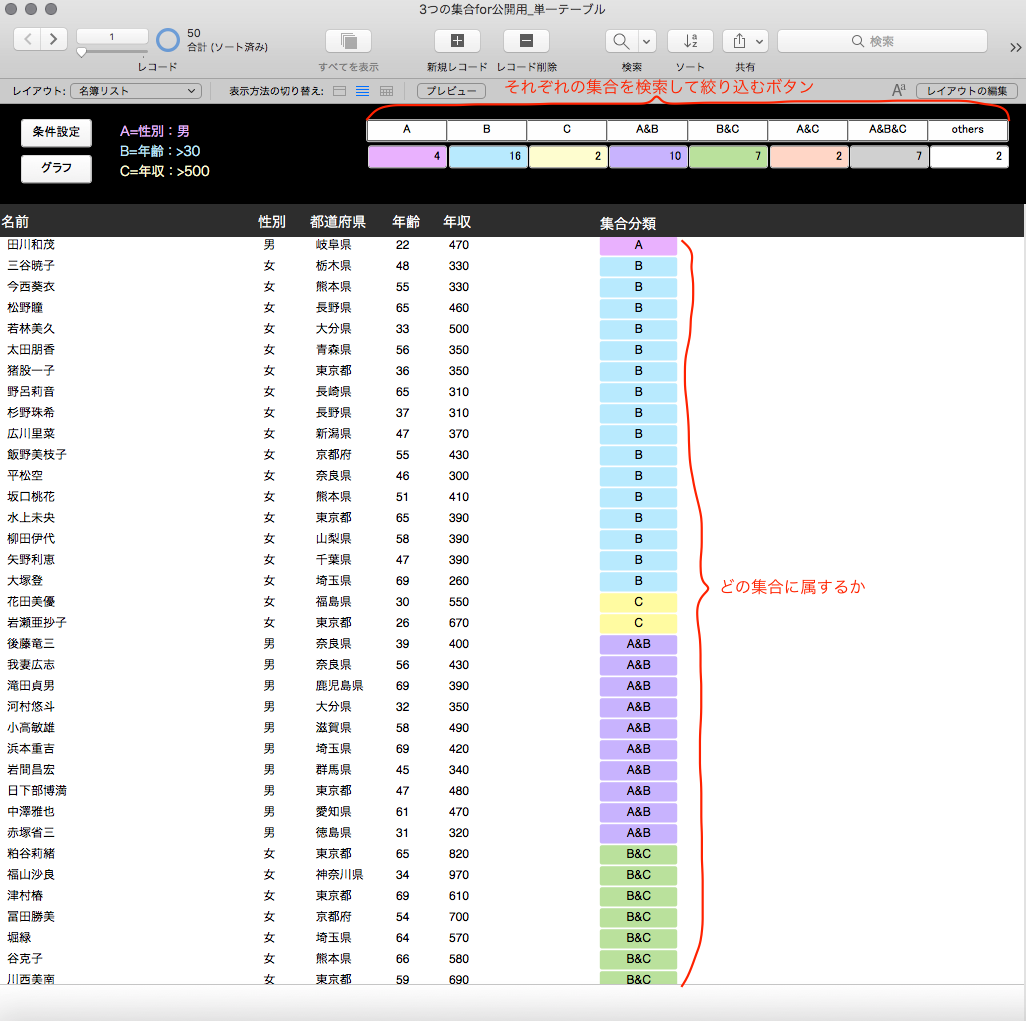
【図 分析結果】
また、上部ナビゲーション上の凡例(A, B, C・・・)は、ボタンになっているので、クリックするとその条件に適合するレコードを絞り込んで表示します。
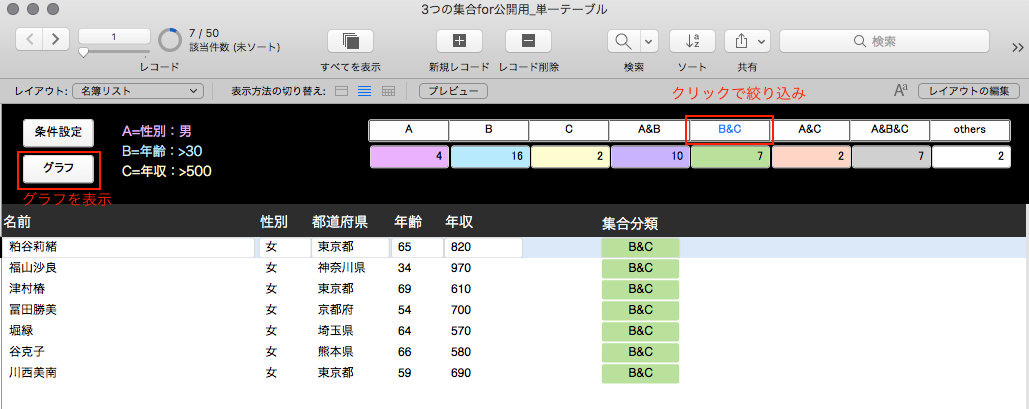
【図 ボタンによる絞り込み】
左端の「グラフ」ボタンを押すと、
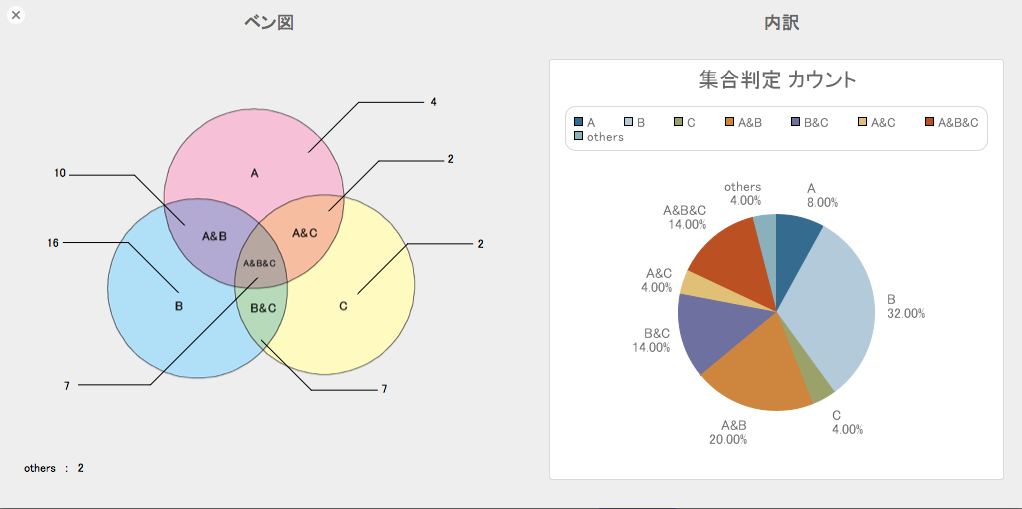
【図 ベン図と円グラフ】
前回と同じように、ベン図と、内訳の円グラフが表示されます。(othersはベン図の外側に表示されます。)
テーブル一覧
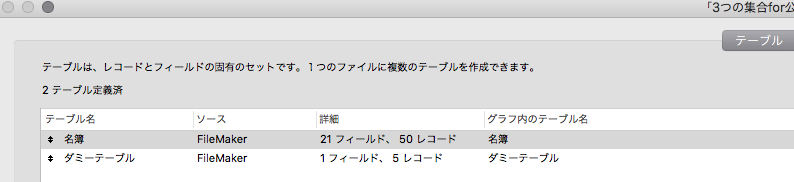
【図 テーブル一覧】
テーブルは2つ
ダミーテーブルは、フィールド名を値一覧にするためだけのテーブルなので、実際に使うテーブルは「名簿」テーブル1つです。
リレーションシップはありません。
フィールド定義
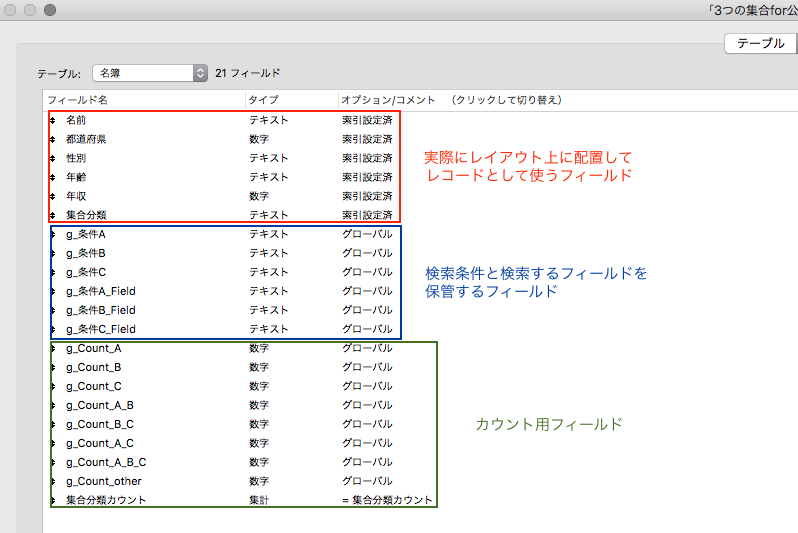
【図 フィールド定義】
特に難しいことはしていません。どのフィールドに、どの検索条件を適用するかをグローバルフィールドに格納しています。
スクリプト
Goボタンを押した時のスクリプトだけ、貼っておきます。
(検索条件を変えて検索を繰り返しているだけです)
スクリプト:Goボタン_条件設定→検索して分析
# グローバルフィールドの値に応じて、検索条件を設定
#
エラー処理 [ オン ]
#
# 条件Aのフィールド名と条件を保管
変数を設定 [ $FieldA ; 値: 名簿::g_条件A_Field ]
変数を設定 [ $FieldA ; 値: Get (レイアウトテーブル名) & "::" & 名簿::g_条件A_Field ]
変数を設定 [ $ConditionA ; 値: 名簿::g_条件A ]
#
# 条件Bのフィールド名と条件を保管
変数を設定 [ $FieldB ; 値: 名簿::g_条件B_Field ]
変数を設定 [ $FieldB ; 値: Get (レイアウトテーブル名) & "::" & 名簿::g_条件B_Field ]
変数を設定 [ $ConditionB ; 値: 名簿::g_条件B ]
#
# 条件Cのフィールド名と条件を保管
変数を設定 [ $FieldC ; 値: 名簿::g_条件C_Field ]
変数を設定 [ $FieldC ; 値: Get (レイアウトテーブル名) & "::" & 名簿::g_条件C_Field ]
変数を設定 [ $ConditionC ; 値: 名簿::g_条件C ]
#
# レコードを確定して、カードウインドウを閉じる
レコード/検索条件確定 [ ダイアログあり: オフ ]
ウインドウを閉じる [ 現在のウインドウ ]
#
レイアウト切り替え [ 「名簿リスト」 (名簿) ; アニメーション: なし ]
#
# 条件Aだけで検索
検索モードに切り替え [ 一時停止: オフ ]
フィールドを名前で設定 [ $FieldA ; $ConditionA ]
検索実行 []
フィールド内容の全置換 [ ダイアログあり: オフ ; 名簿::集合分類 ; "A" ]
#
# 条件Bだけで検索
検索モードに切り替え [ 一時停止: オフ ]
フィールドを名前で設定 [ $FieldB ; $ConditionB ]
検索実行 []
フィールド内容の全置換 [ ダイアログあり: オフ ; 名簿::集合分類 ; "B" ]
#
# 条件Cだけで検索
検索モードに切り替え [ 一時停止: オフ ]
フィールドを名前で設定 [ $FieldC ; $ConditionC ]
検索実行 []
フィールド内容の全置換 [ ダイアログあり: オフ ; 名簿::集合分類 ; "C" ]
#
# 条件A&Bで検索
検索モードに切り替え [ 一時停止: オフ ]
フィールドを名前で設定 [ $FieldA ; $ConditionA ]
フィールドを名前で設定 [ $FieldB ; $ConditionB ]
検索実行 []
フィールド内容の全置換 [ ダイアログあり: オフ ; 名簿::集合分類 ; "A&B" ]
#
# 条件B&Cで検索
検索モードに切り替え [ 一時停止: オフ ]
フィールドを名前で設定 [ $FieldB ; $ConditionB ]
フィールドを名前で設定 [ $FieldC ; $ConditionC ]
検索実行 []
フィールド内容の全置換 [ ダイアログあり: オフ ; 名簿::集合分類 ; "B&C" ]
#
# 条件A&Cで検索
検索モードに切り替え [ 一時停止: オフ ]
フィールドを名前で設定 [ $FieldA ; $ConditionA ]
フィールドを名前で設定 [ $FieldC ; $ConditionC ]
検索実行 []
フィールド内容の全置換 [ ダイアログあり: オフ ; 名簿::集合分類 ; "A&C" ]
#
# 条件A&B&Cで検索
検索モードに切り替え [ 一時停止: オフ ]
フィールドを名前で設定 [ $FieldA ; $ConditionA ]
フィールドを名前で設定 [ $FieldB ; $ConditionB ]
フィールドを名前で設定 [ $FieldC ; $ConditionC ]
検索実行 []
フィールド内容の全置換 [ ダイアログあり: オフ ; 名簿::集合分類 ; "A&B&C" ]
#
# その他、を検索
検索実行 [ 記憶する ]
フィールド内容の全置換 [ ダイアログあり: オフ ; 名簿::集合分類 ; "others" ]
#
# それぞれの集合に属するレコード数をカウント
検索実行 [ 記憶する ]
フィールド設定 [ 名簿::g_Count_A ; Get(対象レコード数) ]
検索実行 [ 記憶する ]
フィールド設定 [ 名簿::g_Count_B ; Get(対象レコード数) ]
検索実行 [ 記憶する ]
フィールド設定 [ 名簿::g_Count_C ; Get(対象レコード数) ]
検索実行 [ 記憶する ]
フィールド設定 [ 名簿::g_Count_A_B ; Get(対象レコード数) ]
検索実行 [ 記憶する ]
フィールド設定 [ 名簿::g_Count_B_C ; Get(対象レコード数) ]
検索実行 [ 記憶する ]
フィールド設定 [ 名簿::g_Count_A_C ; Get(対象レコード数) ]
検索実行 [ 記憶する ]
フィールド設定 [ 名簿::g_Count_A_B_C ; Get(対象レコード数) ]
#
# その他、をカウント
検索実行 [ 記憶する ]
フィールド設定 [ 名簿::g_Count_other ; If ( Get(最終エラー)=401 ; 0 ; Get(対象レコード数) ) ]
#
全レコードを表示
レコードのソート [ 記憶する ; ダイアログあり: オフ ]
レコード/検索条件/ページへ移動 [ 最初の ]
#
サンプルファイルをダウンロードして、検索条件を変えるなり、データを入れ替えるなりして使ってみてください。
[サンプルファイル:3つの集合for公開用_単一テーブル.fmp12]
(https://drive.google.com/file/d/1fcXGmi8liGsWcit3rDgMlvhmhud91oap/view?usp=sharing)
人工知能との関係
2回に分けて、ファイルメーカーを使って集合(の積)について考えてみたつもりです。(筆者は集合論についても人工知能についても、素人です。詳しく知りたい方は、成書などをご覧ください)
いったい、これが人工知能と何の関係が? と疑問を持たれた方も多いと思いますので、その部分に答えておきます。
あくまで自分のやり方ですが、いわゆる人工知能(ここでは一般的な「教師あり機械学習」の成果としての知能を指します)に知識を与えて、その精度を高めたいとき、それらの知識を今回のように「集合同士としてぶつける」ことを試みることがあります。「分類問題」といわれるものの一部です。
どんなときに使うか?
- 重複を省きたいとき
教師データに重複があると、処理速度に影響が出たり、ストレージを圧迫したりします。どこが重複しているか、をサッと見つけて処理できると便利です。
- より確からしい知識を得たいとき
教師データ・学習データの中には、ノイズ・タイプミスもあり、間違いもあります。複数のAIが別々に獲得した知識を集合としてぶつけることで、ノイズをあぶり出し、より確からしい知識、普遍的な知識を得ることができるはずです。たとえば、データAに「三国志」という登録があり、データBにも「三国志」があるけれど、データCに「三国史」という登録があれば、「これはタイプミスじゃないか?」と疑うきっかけになります。単純な例ですが、AI同士の合議制、が可能になります。
- 特徴的な知識を取り出したいとき
「Aさんが作ったAIだけに含まれ、その他のAIには含まれない知識」を取り出すと、そのAIに特徴的な部分を抽出することができます。
たとえば、Aが政治学、Bが経済学、Cが社会学、の文献から作り出した知識だとすると、隣接する似たような分野同士で「似ていない部分はどこか」を抽出したことになり、Aだけに出現する知識は「政治学だけに特徴的な知識」となります。
おわりに
現在の人工知能に用いられる教師データは、ほとんどがテキストファイルやCSVなど、汎用性があり加工がしやすい形式になっています。
しかし、加工しやすい反面、それらはグラフィカルなUIを持っておらず、その中身や全体像を把握しにくい、というデメリットがあります。ファイルメーカーなら、そのデメリットを補う形で、全体像や傾向を把握し、確認しながら「次の一手」を考えやすくなるでしょう。テキストファイルやCSVの読み込み、書き出しにも問題はありません。
このような集合の和や集合の積を求める処理は他のプログラミング言語でもよく実装されているようです。
(私は詳しくは知りませんが、python+tableauが使えれば、もっといろんなことをできそうですし、Google Chart APIなどもベン図自体を生成する機能があるようです。)
しかし、ファイルメーカーの優れた点は、初級者にも敷居が低く、短時間で設計・実装できることに加えて、何といっても、データベースと直結していて、グラフィカル・直感的な表示が可能なところです。
また、書くコードの量もpythonなどと比べると格段に少ないでしょう。
汎用性を持った大規模なAIは、すでに大企業が巨額の投資をして開発されており、ディープラーニングなどと比べれば、このような「教師あり学習による丁寧な蓄積」は、吹けば飛ぶような、ほとんど意味のないものと思えるかもしれません。
しかし、大規模な学習によって得られる結果は、必然的に最大公約数的で大ざっぱなものになりがちなので、細かい目的を正確に達成するためのチューニングには、コツコツと積み重ねを続けるしかないのではないでしょうか?
私見ですが、これから遠くない将来には、個人や用途に合わせて、細かい人工知能を組み合わせて使う、「ひとりひとつ(以上)のAIを持つ時代」が訪れると筆者は考えており、そのためにも、このような「ユーザーが、手元で、見える形で、細かい集合をぶつけたり、差分をとったりする仕組み」は有効だと考えています。
AdventCalendarの記事としては随分長くなってしまいましたが、最後まで読んでいただいた方、ありがとうございました。