1. 初めに
迷路を強化学習(Q-learning)で解きます.
コードはpythonで書きます.
2. 迷路を定義
0 : スタート
16 : ゴール
ー : 壁
他のマスは適当に番号を付けた(後で使う使うため)
|-|-|-|-|-|-|-|
|-|:-:|:-:|:-:|:-:|:-:|-|
|-|0
スタート|-|6|11|12|-|
|-|1|-|7|-|13|-|
|-|2|5|8|-|14|-|
|-|3|-|9|-|15|-|
|-|4|-|10|-|16
ゴール|-|
|-|-|-|-|-|-|-|
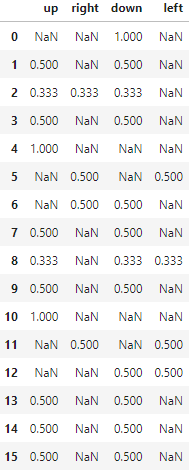
3. 行動価値関数(Q値)の初期値を定義
行動価値関数のテーブルを作る.
今回はCSVで作って,それを読み込む.
#up right down left
meiro_env = pd.read_csv("meiro_env.csv")
meiro_env = meiro_env.replace(0, np.nan)
meiro_env
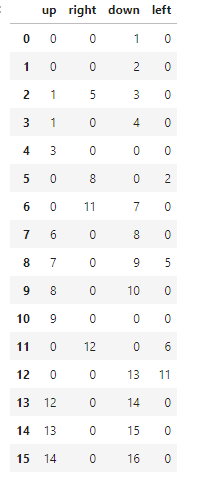
次に行動した後の位置のcsvを作る.
meiro_next_act = pd.read_csv("meiro_next_act.csv")
meiro_next_act
4. Q-learning
Qラーニングは以下の式で表される.
詳細は割愛.
$$
Q(s_t,a_t)←(1-\alpha)Q(s_t,a_t)+\alpha(r_{t+1}+\gamma maxQ(s_{t+1},a_{t+1}))
$$
5. 学習結果
学習(エピソード)が進むにつれて最適値に収束していく.
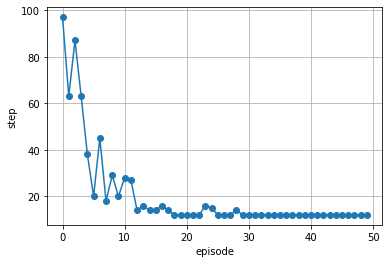
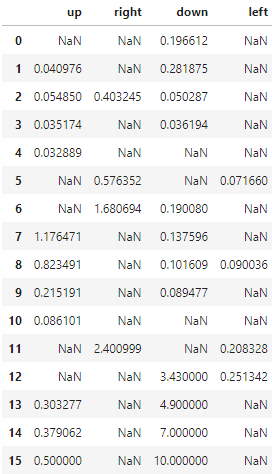
以下に学習後のQ値の更新結果も示す.
6. Q-leaning コード
# ハイパーパラメータ
gamma = 0.7
alpha = 0.5
epsiron = 0.3
# 初期値
pos_now = 0
step = 0
# 報酬
reward = 10
steps = []
for episode in range(50):
while True:
# epsiron greedy法
random_value = random.random()
if random_value>epsiron :
# print("Q値更新")
# 行動
act = meiro_env[pos_now:pos_now+1].max().sort_values(ascending=False)
act_now = act.index[0]
# maxQのときの位置
max_Q_pos = meiro_next_act[act_now][pos_now]
# maxQ(s,t)
max_Q = meiro_env[max_Q_pos:max_Q_pos+1].max().sort_values(ascending=False)[0]
# display(meiro_env[pos_now:pos_now+1])
if max_Q_pos==16:
meiro_env[act_now][pos_now] = (1-alpha)*meiro_env[act_now][pos_now] + alpha*reward
else :
meiro_env[act_now][pos_now] = (1-alpha)*meiro_env[act_now][pos_now] + alpha*gamma*max_Q
pos_now = max_Q_pos
# display(meiro_env[pos_now:pos_now+1])
# print("Next position : ",pos_now)
else:
# print("ランダム")
act_choise = meiro_env[pos_now:pos_now+1].dropna(axis=1).columns.tolist()
act_now = random.choice(act_choise)
pos_now = meiro_next_act[act_now][pos_now]
# print("Next position : ",pos_now)
# ステップ数カウント
step = step+1
print(step)
# ステップ数が100でスタートに戻す
if step == 100:
if (len(steps)==0)or(min(steps)==100):
meiro_env = pd.read_csv("meiro_env.csv")
meiro_env = meiro_env.replace(0, np.nan)
else:
meiro_env = meiro_env_
steps.append(step)
step = 0
pos_now = 0
break
# ゴール到達でスタートに戻す
if pos_now == 16:
steps.append(step)
pos_now = 0
epsiron = epsiron-0.01
step=0
meiro_env_ = meiro_env
break