まえがき
こんにちは。
最近業務で機械学習を取り入れたシステムを作ることになりまして、一から勉強してます。
とりあえず会社の研修やら、オライリージャパン出版「ゼロから作るDeepLearning」やらで一通り基礎的な内容を学んだので、続いて実践としてKaggleをはじめることにしました。
まずはscikit-learnの基本的な操作を覚えるところまでなので大した内容ではありませんが、備忘録としてまとめます。
(自分の記事よりもすばらしくまとめている方が他にたくさんいますが、まぁ自分なりにまとめるのも勉強ということで一つ)
何かアドバイスやご指摘がございましたら送っていただけると幸いです。
以下のコードは全てJupyter-notebookで実行してます。
pythonは3系です。
ライブラリ等含めて全て2019年4月ごろの最新版を使ってます。
でははじめます。
本文
ライブラリのインストール
import pandas as pd
import numpy as np
# 以下scikit-learn
from sklearn import preprocessing # データを数値に置き換えたり、onehot表現に変えたりするときに使うやつ
from sklearn import linear_model # 回帰分析のやつ
from sklearn.tree import DecisionTreeClassifier # 決定木分析のやつ(ランダムフォレストはこいつでできるできる)
from sklearn.metrics import (roc_curve, auc, accuracy_score) # 作ったモデルの精度はかるのに使うやつ
とりあえず今回使ったライブラリをまとめておきました。
分析する際には必要に応じて適宜読み込む形でいいと思います。
データの読み込みと確認
必要なデータをデータフレームに読み込みます。
csvファイルはKaggleから持ってきたものです。
train_df = pd.read_csv('train.csv') # モデル作成用
データの情報を確認します。
train_df.info() # データフレームの情報を確認
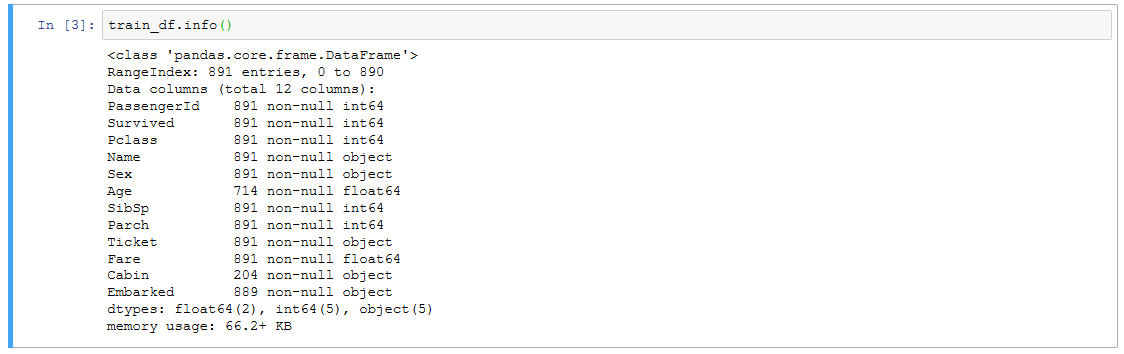
これでデータの行数列数とか、列のデータ型とかが見れます。
それぞれの列は
PassengerId :一意のキー
survival :生存 0 = No, 1 = Yes
pclass :チケットの階級 1 = 1st, 2 = 2nd, 3 = 3rd
sex :性別
Age :年齢
sibsp :一緒に乗った兄弟/配偶者の数
parch :一緒に乗った両親/子供の数
ticket :チケット番号
fare :旅客運賃
cabin :部屋番号
embarked :乗船した港 C = シェルブール, Q = クイーンズタウン, S = サウサンプトン
を意味してるらしいです。
データの中身も確認します。
train_df.head(10) # 先頭数行だけ見る、列名の確認とかに便利(引数入れなくてもデフォルトで5行表示)
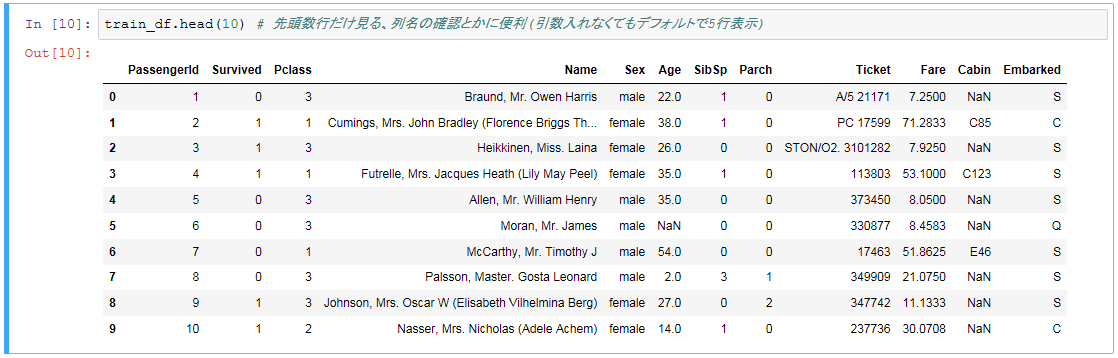
どうやらAgeとかCabinにNaN(中身が空、未設定、欠損値)のデータがあるみたいです。
どれぐらいNaNがあるか見てみます。
train_df.isnull().sum() # isnullでNaNの判定、その結果の数を合計して表示
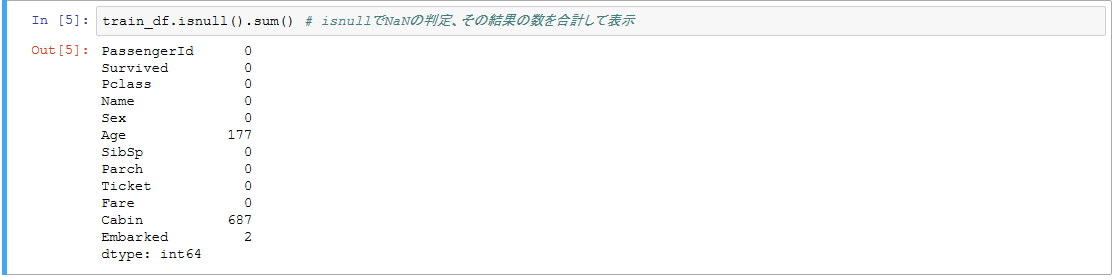
CabinはNaNが結構多いですね。
Ageもそこそこあるので、後ほど何らかの対策を行う必要がありそうです。
文字列データの処理
次に、データの関係性などを調べる前に、文字列データを使わないデータと数値に置換するデータとに振り分けます。
Nameはユニークな値が多いから数値の置換は必要ないかな?
名前をどう使えばいいのかわからないので、とりあえず今回は除外します。
Sexは使えそうなので置換します。
Ticket番号は・・・何らかの規則があれば使えるかも?
まぁよくわからないのでこれも今回は除外で。
Cabinは、部屋の位置とかと結び付けたら使えるかな?。
ただNaNが多いのでこれも今回は除外で。
Embarkedは何に使えるかよくわかりませんが、簡単に置換できそうなのでとりあえずやっておきますかね。
ではデータを数値に置換します。
まずは除外するデータを消します。
train_df2 = train_df.drop(['Name', 'Ticket', 'Cabin'], axis=1) # 削除
train_df2.head()
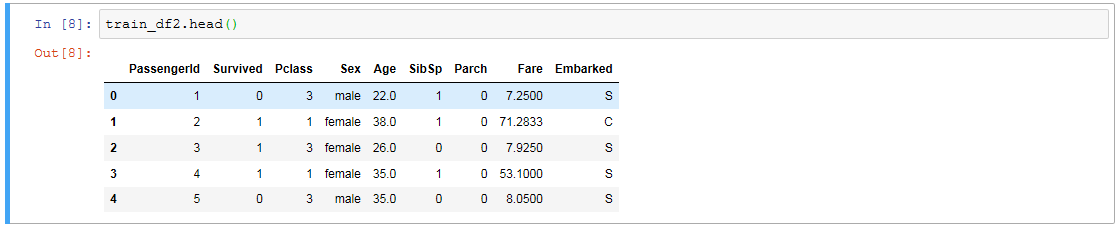
続いて文字列のデータを数値に置換しますが、欠損値があるとLabelEncoderが動かないので先に欠損値を最頻値(最頻データ?)で穴埋めしときます。
# 最頻値で穴埋め
# fillnaはNaNに好きな値を入れられる関数、固定値とか、数値のデータなら平均値、中央値、最頻値とかを簡単にいれられる
# 今回は文字列のデータなのでvalue_countsで要素の種類ごとの数を数えて、一番出現数の多いデータで穴埋め
train_df2['Embarked'] = train_df2['Embarked'].fillna(train_df2['Embarked'].value_counts().index[0])
そして数値に置換します。
# replace関数で置換するやり方
# train_df2['Sex'] = train_df2['Sex'].replace('male',0).replace('female',1)
# train_df2['Embarked'] = train_df2['Embarked'].replace('C',0).replace('Q',1).replace('S',2)
# LabelEncoderを使うやり方、今回はこっち使います
# 欠損値があると使えないけど、どの値をどの値に置き換えるかの指定がいらないので便利
enc_cols = np.array([])
le = preprocessing.LabelEncoder()
for col in ['Sex', 'Embarked']:
le.fit(train_df2[col])
enc_cols = np.append(enc_cols, le.classes_) # 置換後のラベル名を保持
train_df2[col] = le.transform(train_df2[col])
train_df2.head()
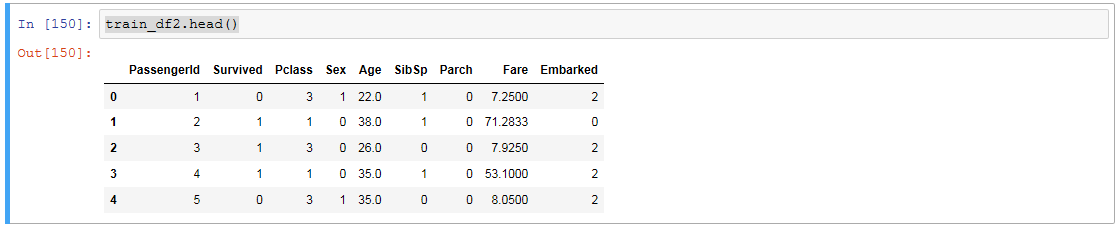
いい感じに数値になりました。
しかしこのままだとデータに大小関係が生まれてしまうので、onehot表現にします。
# OneHotEncoderという便利なものがあり簡単にできます
one_hot_encoder = preprocessing.OneHotEncoder()
one_hot_encoder.fit(train_df2[['Sex', 'Embarked']])
enc_df = pd.DataFrame(one_hot_encoder.transform(train_df2[['Sex', 'Embarked']]).toarray()) # 変換 → 配列化 → データフレーム化
enc_df.columns = enc_cols # ラベル名をさっき残しておいた置換後のものに変更
enc_df.head()
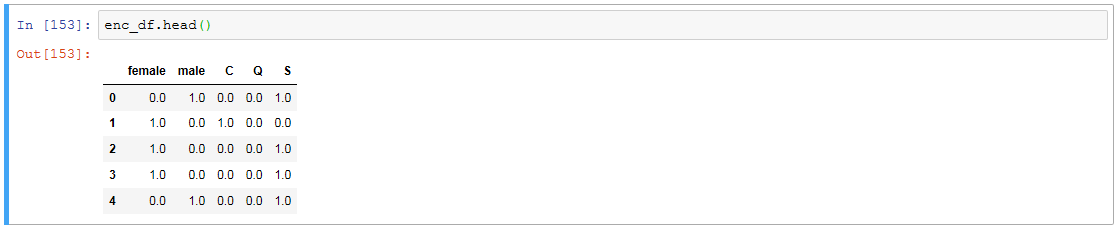
あとはこれを元のデータフレームにくっつけて、いらなくなった列を消します。
train_df2 = pd.concat([train_df2, enc_df], axis=1) # 結合
train_df2 = train_df2.drop(['Sex', 'Embarked'], axis=1) # 削除
train_df2.head()
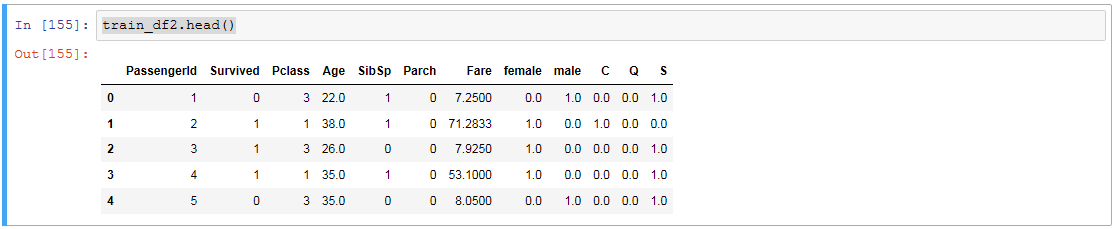
train_df2.isnull().sum()
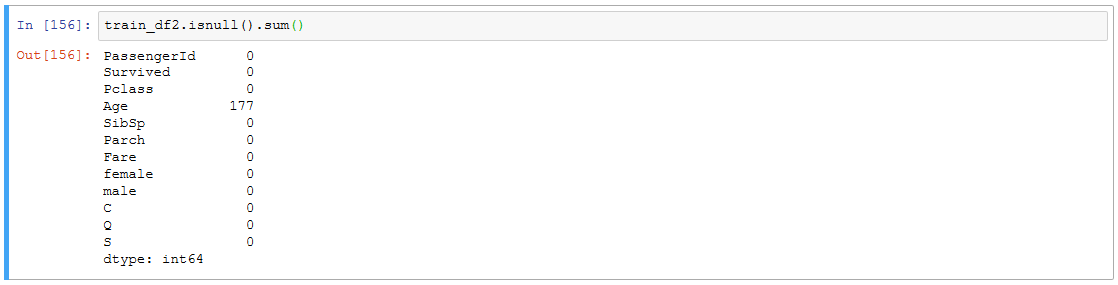
こんな感じになりました。
とりあえずデータは使える形になった感がありますが、AgeのNaNが気になります。
Ageの欠損値をどう扱うかは、一旦値のSurvivedへの影響度などを見たうえで決めていきます。
というわけで一度、各値同士の相関でも調べてみます。
データ間の相関関係の把握と欠損値の処理
train_df2.drop('PassengerId', axis=1).corr() # 列同士の相関を表示(PassengerIdはただのIDなので見ない)
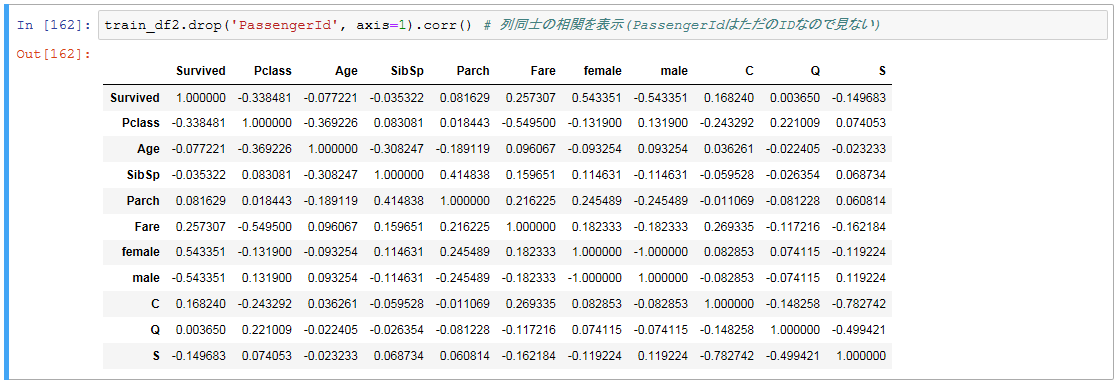
改めて各列の意味はこれです。
survival :生存 0 = No, 1 = Yes
pclass :チケットの階級 1 = 1st, 2 = 2nd, 3 = 3rd
Age :年齢
sibsp :一緒に乗った兄弟/配偶者の数
parch :一緒に乗った両親/子供の数
fare :旅客運賃
female :女性
male :男性
C,Q,S :乗船した港 C = シェルブール, Q = クイーンズタウン, S = サウサンプトン
こうしてみると、男性か女性かでかなり違いがあるみたいですね。
救命ボートに乗せるときにレディーファーストが働いたのかな?
あとはチケットの階級とか値段もまぁまぁ影響してます。
金持ちは優先されたのか、それとも部屋の場所的に助かりやすかったんですかね。
年齢はそんなに関係ないのかな?
まぁよくわからないんでとりあえず欠損部分には最頻値とかいれときますかね。
乗船場所による違いはなんですかね。
チケットの値段とか階級と相関がややあるんで、地域による貧富の格差かな?もしくは案内された部屋の場所?
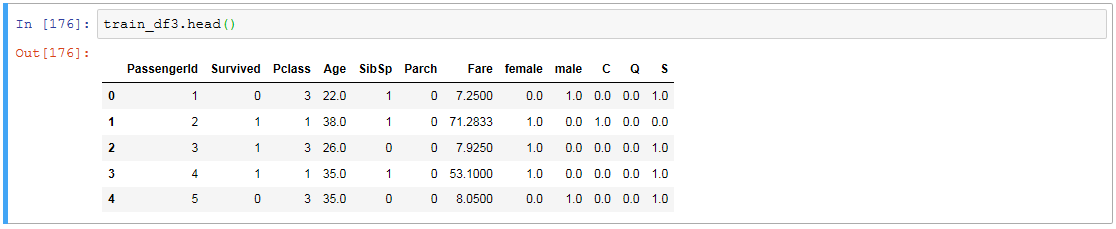
というわけでとりあえず年齢は最頻値で穴埋めしときます。(あとで別の方法とるかもしれないのでデータフレームは別にしときます)
train_df3 = train_df2
train_df3['Age'] = train_df3['Age'].fillna(train_df3['Age'].mode().iloc[0])
train_df3.head()
train_df3.isnull().sum()
モデルの作成
では一旦このタイミングでランダムフォレストで分類してみます。
# まずは変数になる部分と目的になる部分に分けます
X = train_df3.iloc[:, 2:] # PclassからSまで
y = train_df3.iloc[:, 1:2] # Survivedだけ
clf = DecisionTreeClassifier(random_state=0) # ランダムフォレストを定義、random_state=0で毎回同じ結果になる
clf = clf.fit(X, y) # モデル作成
一応訓練データの的中率を見てみます。本来なら訓練データとテストデータを別にして、テストデータの的中率を図るのが普通です。
pred = clf.predict(X) # 作ったモデル動かす
fpr, tpr, thresholds = roc_curve(y, pred, pos_label=1)
auc(fpr, tpr)
accuracy_score(pred, y)

テストデータの予測
では、いよいよテストデータから生存予測を行います。
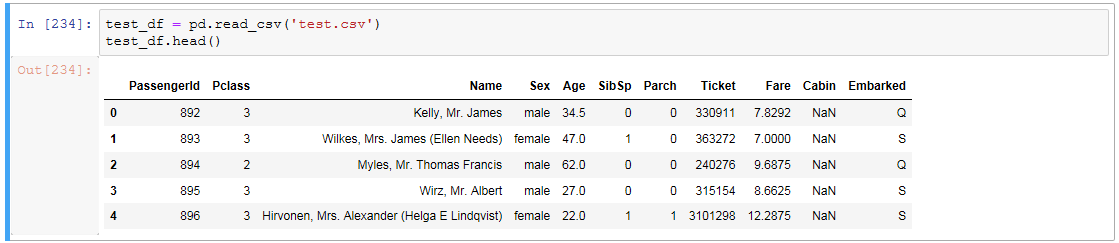
test_df = pd.read_csv('test.csv') # テスト用データ
test_df.head()
test_df.isnull().sum()
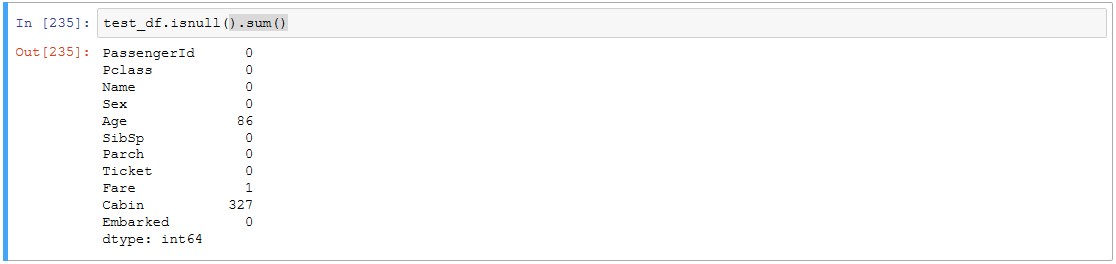
テストデータの中身はこんな感じです。
survivalが無いだけで他は訓練用データと同じです。
ここから生存予測を行い、Kaggleに提出できる形にデータを整形すれば完了です。
では上でやったデータ加工と同じことをテストデータにも行います。
# 余分なの消して
test_df2 = test_df.drop(['Name', 'Ticket', 'Cabin'], axis=1)
# 文字列の列を数値変換 → onehot表現にして
enc_cols = np.array([])
le = preprocessing.LabelEncoder()
for col in ['Sex', 'Embarked']:
le.fit(test_df2[col])
enc_cols = np.append(enc_cols, le.classes_)
test_df2[col] = le.transform(test_df2[col])
one_hot_encoder = preprocessing.OneHotEncoder()
one_hot_encoder.fit(test_df2[['Sex', 'Embarked']])
enc_df = pd.DataFrame(one_hot_encoder.transform(test_df2[['Sex', 'Embarked']]).toarray())
enc_df.columns = enc_cols
# onehotにしたのを元のデータフレームとくっつける
test_df2 = pd.concat([test_df2, enc_df], axis=1)
test_df2 = test_df2.drop(['Sex', 'Embarked'], axis=1)
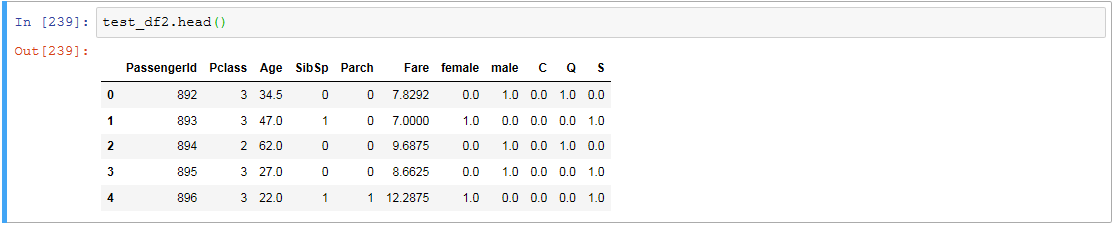
test_df2.head()
test_df2.isnull().sum()
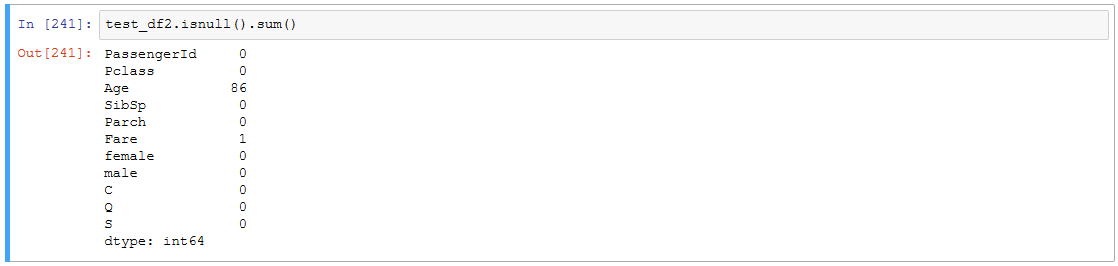
AgeとFareに欠損値があるので最頻値で適当に穴埋めしときます。
for col in ['Age', 'Fare']:
test_df2[col] = test_df2[col].fillna(test_df2[col].mode().iloc[0])
データの加工が終わったので、あとは予測を行います。
# 変数をセットして
test_X = test_df2.iloc[:, 1:] # PclassからSまで
# さっき作ったモデルを使う
pred = clf.predict(test_X)
# 予測された値とIDをくっつけてKaggleに提出できる形に成形
df_pred = pd.DataFrame(pred) # データフレームに変換
df_pred.columns = ['Survived'] # ラベル変えて
df_pred = pd.concat([test_df2['PassengerId'], df_pred], axis=1) # PassengerIdをくっつける
df_pred.head()
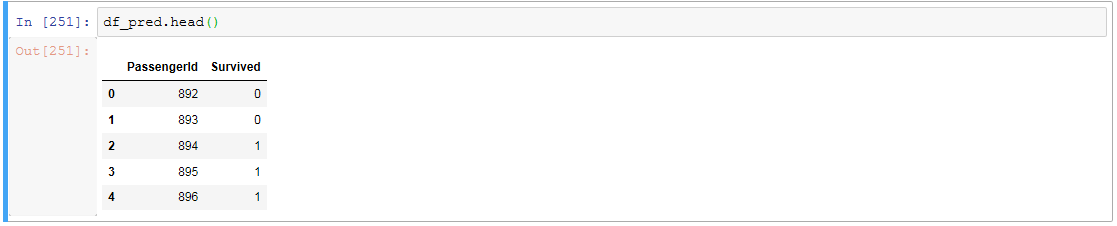
提出できる形になったので、あとはCSVに吐き出します。
df_pred.to_csv('result.csv', index=False)
さて、いざ結果は・・・
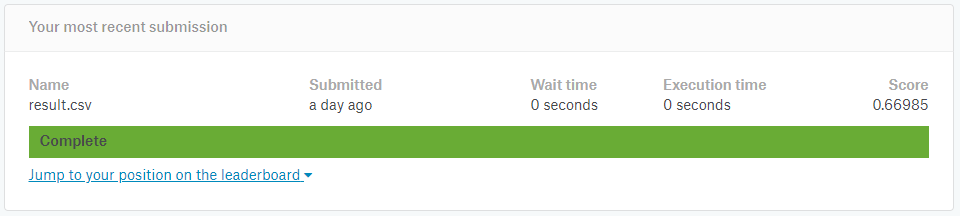
0.66985
全然ダメですね。 まぁ今回はお試しなのでこんなもので。
一応これはきれいに整えたやつで、最初は年齢の穴埋めに重回帰分析したりもしてたんですが、それでもスコアは0.7ぐらいでした。
先は長いですねぇ。
あとがき
データ分析の基礎的な仕組みなんかは本読みながら実際に作って覚えられたので、まぁまぁわかった気になってたんですが、実践となるとやっぱり違いますね。
主にデータの前処理あたりの知識、技術が全く足りてないと実感しました。
内容自体は面白いので、今後も続けていければと思います。
今は業務とかKaggleで機械学習やってますが、いずれはディープラーニング使ったシステムとか構築してみたいですねぇ。