はじめに
ALB+Fargateという構成で動くWebサービスのスケールアウトが遅く、メディア露出や
DM配信によるスパイクアクセスに耐えられない、という問題があり改善策を検討していた
ところ下記記事を見つけました。
爆速でFargateをスケールさせる「aws-fargate-fast-autoscaler」を試してみた
簡単に動作原理を説明すると、Fargateをオートスケールさせる場合、通常はECSのターゲット追跡
スケーリングポリシーなどを利用しECSサービスにおけるCloudWatchメトリクスとアラームを利用して
タスク数などを制御します。
ただ、この場合、CloudWatchメトリクスからアラーム発報までにどうしてもタイムラグが有り数秒単位
でのスケーリングが難しく基本は分単位でのスケーリングとなっていました。
そこを、この「aws-fargate-fast-autoscaler」では、Step Functionsを利用して3秒毎に
Fargateタスクへのコネクション数を取得し、その結果に応じて即ecs service updateでタスク数の
上限を引き上げることで、ターゲット追跡スケーリングポリシーでは実現できない高速なスケーリングを
実現しています。
これを導入するか検討した結果、後述する理由により自作ツールを作ることにしました。
(nginxのstub_statusで検知するというアイデアは面白いのでそのまま活用しています!)
この記事はそのツール紹介です。
自作する理由
- 最大実行時間の制限が1年
- Step Functions版は、1年を超えて連続稼働できない
- コスト抑えたい
- Step Functions版は、月あたり約65USDかかる
- 自作ツールだと月額11USD程度
- 複数サービスに対応したい
- Step Functions版は、対象URLが1つ
- 弊社では
ALB+Fargate構成の複数Webサービスを運用しているため
fast-autoscaler紹介
概要
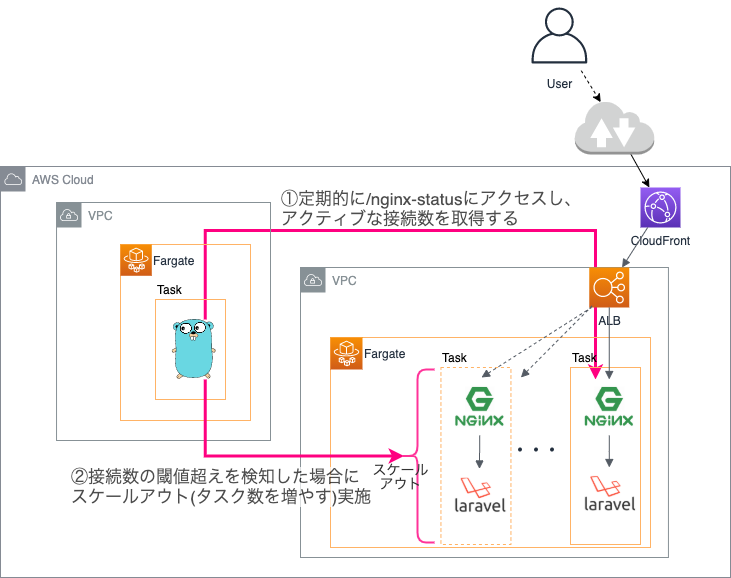
/nginx-status(stub_status)に定期的にアクセスし、Active Connectionsの値を取得し
閾値を超えていた場合にスケールアウトルールに従いタスク数を変更し、Slack通知します。
対象となるURL/閾値/Slack通知要WebhookURLは、起動時にパラメータストアから取得します。
コードはこちら
処理フロー
- コンテナ起動時にパラメータストアから設定情報(json形式,詳細後述)を取得
- 指定された
/nginx-statusURLにリクエスト送信し、Active Connectionsの値を確認 - 閾値を超えていた場合)
->スケールアウト実行->/nginx-statusチェック停止->猶予期間経過後チェック再開 - 閾値を超えていない場合)
->一定周期での/nginx-statusチェックを継続
処理イメージ
使い方
セットアップ手順
CloudFormationテンプレートを使用して、パラメータストア、IAMロール、ECSタスク定義、
ECSクラスタ、ECSサービスを作ります。
-
CloudFormationテンプレートをダウンロード
curl -sLO https://raw.githubusercontent.com/senbazuru/fast-autoscaler/master/cfn-template.yml
- CloudFormationコンソールで上記テンプレートを使用してスタックを作成
- スタック名(=ECSクラスタ/サービス名)を指定(任意)
- 以降、fast-autoscalerを指定した前提で記載
- あとは、コンテナが動くVPC、Subnet、SGを環境に合わせて指定して作成する
<img width="600" alt="cfn.png" src="https://qiita-image-store.s3.ap-northeast-1.amazonaws.com/0/51108/b269a9f5-9088-7c94-2002-66a909da0a42.png">
作成した時点ではパラメータストアの設定が空なので、CloudWatchLogsにはエラーが
出ている状態ですが問題ありません。
- パラメータストアの設定を編集
- `/ecs/fast-autoscaler/config.json`という名前のパラメータを編集
- 後述する設定情報の説明を参照して書き換えて保存
- 設定変更を反映
- awscliでタスクを停止(その後自動的に起動されることで設定が反映される)
```
export AWS_PROFILE={AWSクレデンシャルのプロファイル名}
TASK_ID=$(aws ecs list-tasks --cluster fast-autoscaler | jq -r '.taskArns[]' | awk -F/ '{print $NF}')
aws ecs stop-task --cluster fast-autoscaler --task ${TASK_ID}
設定情報
- json形式でパラメータストアに保存
- タイプはString or SecureStringどちらでもOK
- 上述CFnで作成した場合はStringになります
{
"Services": [
{
"StatusUrl":"https://example-a.com/nginx-status",
"StatusAuthName":"Status-Auth-Key",
"StatusAuthValue":"hogefuga",
"ScaleoutThreshold":100,
"EcsClusterName":"example-app",
"EcsServiceName":"example-app",
"SlackWebhookUrl":"https://hooks.slack.com/services/XXXXXXXXX/XXXXXXXXX/xxxxxxxx"
},
{
"StatusUrl":"https://example-b-1234567890.ap-northeast-1.elb.amazonaws.com/nginx-status",
"ScaleoutThreshold":150,
"MinDesiredCount":2,
"CheckInterval":10,
"EcsClusterName":"example-app-b",
"EcsServiceName":"example-app-b"
}
]
}
| フィールド名 | 説明 | 必須 | デフォルト | 例 |
|---|---|---|---|---|
| StatusUrl | nginx-statusのURL | ○ | https://example-a.com/nginx-status | |
| StatusAuthName | 認証用HTTPヘッダ名 | Status-Auth-Key | ||
| StatusAuthValue | 認証用HTTPヘッダ値 | hogefuga | ||
| ScaleoutThreshold | スケールアウト発動するActiveConnectionsの閾値 | 150 | 150 | |
| MinDesiredCount | スケールアウト時に現在のタスク数とみなす最小数 | 5 | 5 | |
| CheckInterval | nginx-statusをチェックする間隔(秒) | 3 | 3 | |
| EcsClusterName | ECSクラスタ名 | ○ | example-app | |
| EcsServiceName | ECSサービス名 | ○ | example-app | |
| SlackWebhookUrl | Slack通知用WebhookURL | https://hooks.slack.com/services/XXXXXXXXX/XXXXXXXXX/xxxxxxxx |
補足
- StatusUrlには
nginxに到達できるドメイン+stub_statusパスを指定してください- verifyをスキップするので、SSL証明書のコモンネームとの不一致は許容されます
(つまり、ALBドメイン名を直接指定可能)
- verifyをスキップするので、SSL証明書のコモンネームとの不一致は許容されます
- スケールアウトは現在のタスク数を2倍にします
- ただし、現在のタスク数が1の場合に2倍にしても2にしかならずスケール不足となる可能性があります
その場合はMinDesiredCountを指定してください。この値をタスク数の下限値として動作します例)現在タスク数=3、MinDesiredCount=5の場合、3<5なので現在のタスク数を5とみなし、その2倍の10にDesiredCountを変更します。
- ただし、現在のタスク数が1の場合に2倍にしても2にしかならずスケール不足となる可能性があります
- StatusAuthName/StatusAuthValueで指定した値が
/nginx-statusへのリクエストにヘッダとして追加されます- fast-autoscaler以外から
/nginx-statusへのリクエストを防ぐため
ALBルーティング設定のヘッダ認証で使用します
- fast-autoscaler以外から
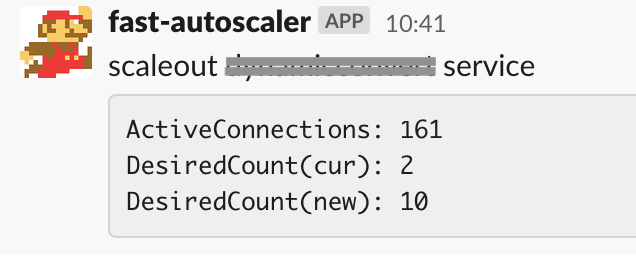
- SlackWebhookUrlに指定があればスケールアウト時にSlackに通知を行います
- 下記イメージ
効果(例)
リクエスト数が急増し負荷がかかったために応答速度が遅延し始めていますが、その直後に
fast-autoscalerがスケールアウト(タスク数2->10)したことですぐに正常な応答速度に
戻っていることがわかります!
その後は、ターゲット追跡スケーリングポリシーでタスク数が徐々に減っています。
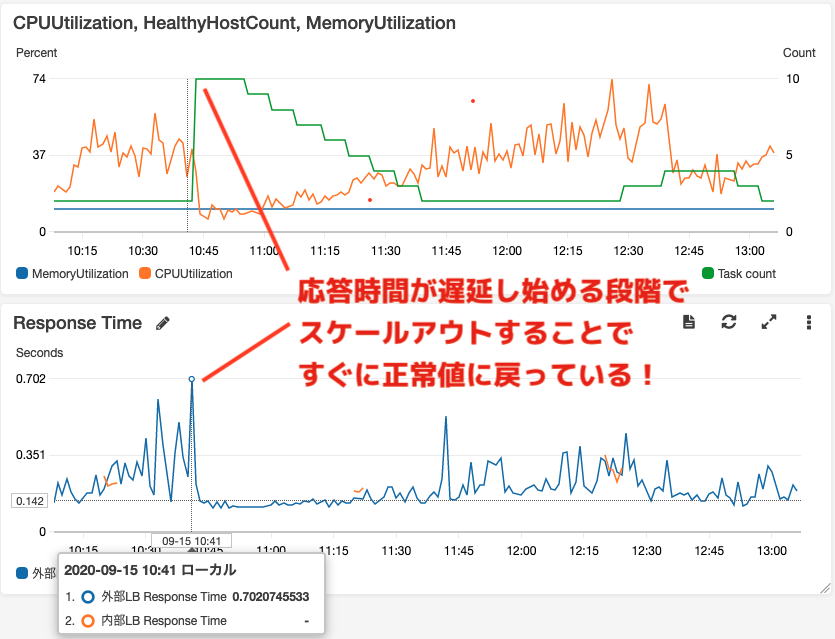
上がCPU/Mem使用率(左軸)、タスク数(右軸)
下が応答時間 のグラフ
まとめ
これで安心して眠れます!
もしよければお使いください。