はじめに
Amazon AthenaはAWSの分析関連サービスの1つで、S3に保存・蓄積したログに対してSQLクエリを投げて分析を行えるサービスです。分析基盤を整えたり分析サービスにログを転送したりする必要が無いため、簡単に利用できるのが特長です。
今回はAthenaを使ってこんなことできるよー、というのを紹介したいと思います。
※社内勉強会向け資料をQiita向けに修正して公開しています
ログ分析とAmazon Athena
ログ分析は定量的にユーザ行動を分析してサービスの改善に役立つだけでなく、障害時の調査にも役立つなど非常に便利です。ログ分析に利用されるサービスとしてはGoogle BigQueryやAmazon Redshiftなど様々なものがありますが、その中でAmazon Athenaの立ち位置を確認したいと思います。
ログ分析の流れ
ログ分析の基盤の概念図は下記のようになります。

この図からわかるように、考えることは多く、どのようなログを出すのか、どのように分析用のDBやストレージにデータを移すのか(ETL)、分析エンジンは何を使うのか、可視化のためにどのようなツールを利用するかなどの検討が必要です。
また初期は問題なく動作していてもデータ量が増えるうちに障害が起きたりログがドロップしてしまうなど多くの問題が出てきます。
そのため、多くの場合専門のチームが苦労をしながら分析基盤を構築・運用しています。
Amazon Athenaとは
Amazon Athenaはサーバレスな分析サービスで、S3に直接クエリを投げることができます。AWS上での分析としてはEMRやRedShiftなどがありますが、インスタンス管理などの手間があり導入にはハードルがありました。
Athenaでは分析エンジンがフルマネージドであり、ログ収集の仕組みやサーバ管理の必要がなく分析クエリを投げられます。

RDBのテーブルなどとのJOINは(データをS3に持ってこないと)できないためあくまで簡易的な分析にとどまりますが、ログを集計するというだけであればとても簡単に分析の仕組みが構築できます。

料金について
BigQueryなどと同じクエリ課金です。一歩間違えると爆死するので注意は必要です。
- ストレージ
- S3を利用するのでS3の保存料金のみ
- クエリ
- スキャンされたデータ 1 TB あたり 5 USD
- データ読み込み
- S3からの通常のデータ転送料金。AthenaとS3が同一リージョンなら転送料金はかからない。
使ってみる - ELB(CLB/ALB)のログを分析
Athenaのユースケースとして一番簡単で有用なのはELBのログ分析だと思っています。ここでは簡単に利用手順を紹介します。
1. S3バケットを作成し適切なアクセス権を付与
ドキュメントを参考にS3のバケットを作成し、アクセスログを有効化すると、15分毎にアクセスログが出力されます。
2. Athena でテーブルを作る
公式ドキュメントにそのまま利用できるクエリが載っているので、AWSマネージメントコンソールからAthenaのQueryエディタを開きこれを実行します。
3. クエリを実行
Athenaの実行エンジンPrestoは標準SQLなので通常のRDBMSへのクエリのように実行できます。
SELECT count(*)
FROM alb_logs
使ってみる - ELBログから様々なデータを取得する
ELBのログに出力されている内容はそこまで多くないものの、意外と色々取れたりします。
1. あるエンドポイントの日別アクセス数を調べる
SELECT date(from_iso8601_timestamp(time)),
count(*)
FROM default.alb_logs
WHERE request_url LIKE '%/users/sign_in'
AND date(from_iso8601_timestamp(time)) >= date('2017-12-01')
GROUP BY 1
ORDER BY 1;
2. 直近24時間の500エラーの発生数を調べる
SELECT elb_status_code,
count(*)
FROM default.alb_logs
WHERE from_iso8601_timestamp(time) >= date_add('day', -1, now())
AND elb_status_code >= '500'
GROUP BY 1
ORDER BY 1;
3. レスポンスに1.0s以上時間がかかっているエンドポイント一覧を出す
SELECT request_url,
count(*)
FROM alb_logs
WHERE target_processing_time >= 1
GROUP BY 1
ORDER BY 2 DESC ;
4. ユーザ単位の行動ログを出す
Cookieは出せないのでIPから。連続したアクセスだとポートも同じになるのでそこまで入れても良い。
SELECT *
FROM alb_logs
WHERE client_ip = 'xx.xxx.xxx.xxx'
AND timestamp '2017-12-24 21:00' <= from_iso8601_timestamp(time)
AND from_iso8601_timestamp(time) <= timestamp '2017-12-25 06:00';
5. あるページにアクセスした後、次にどのページに移動しているかを調べる
3回joinしているのでちょっとわかりづらい。これもIPがユーザー毎にユニークと仮定しているので正確ではない。
SELECT d.*
FROM
(SELECT b.client_ip,
min(b.time) AS time
FROM
(SELECT *
FROM alb_logs
WHERE request_url LIKE '%/users/sign_in') a
JOIN alb_logs b
ON a.time < b.time
GROUP BY 1 ) c
JOIN alb_logs d
ON c.client_ip = d.client_ip
AND c.time = d.time
ORDER BY d.time
運用してみる
Athenaについて何となくわかってもらえたでしょうか。次に、実際に運用するときのためにいくつか補足しておきます。
パーティションを切る
ログデータはすぐにTB級の大きなデータとなります。データをWHERE句で絞るにしてもデータにアクセスしないことには絞込はできませんので、Athenaは基本的には保存されている全てのデータにアクセスしてしまいます。
これを防ぐためにパーティションを作って運用します。パーティションを作成するにはCREATE TABLEでPARTITIONED BYでパーティションのキーを指定しておきます。
CREATE EXTERNAL TABLE IF NOT EXISTS table_name (
type string,
`timestamp` string,
elb string,
client_ip string,
client_port int,
target_ip string,
target_port int,
request_processing_time double,
target_processing_time double,
response_processing_time double,
elb_status_code string,
target_status_code string,
received_bytes bigint,
sent_bytes bigint,
request_verb string,
url string,
protocol string,
user_agent string,
ssl_cipher string,
ssl_protocol string,
target_group_arn string,
trace_id string )
PARTITIONED BY(d string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe' WITH SERDEPROPERTIES ( 'serialization.format' = '1',
'input.regex' = '([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*):([0-9]*) ([.0-9]*) ([.0-9]*) ([.0-9]*) (-|[0-9]*) (-|[0-9]*) ([-0-9]*) ([-0-9]*) \\\"([^ ]*) ([^ ]*) (- |[^ ]*)\\\" (\"[^\"]*\") ([A-Z0-9-]+) ([A-Za-z0-9.-]*) ([^ ]*) ([^ ]*)$' )
LOCATION
's3://bucket_name/prefix/AWSLogs/123456789012/elasticloadbalancing/ap-northeast-1/'
実際のパーティションの構築るには2種類の方法があります。
1.ファイルの保存パスにパーティションの情報を入れる(Hiveフォーマット)
s3のkeyを例えば s3://bucket_name/AWSLogs/123456789012/d=2017-12-24/asdf.logという形で保存します。
この状態で次のコマンドを実行すると自動でパーティションが認識されます。
MSCK REPAIR TABLE impressions
2.ALTER TABLEを実行する
ELBのログなどAWSが自動で保存するログは上記のような形式で保存できないので、直接パーティションを作成します。
ALTER TABLE elb_logs
ADD PARTITION (d='2017-12-24')
LOCATION 's3://bucket/prefix/AWSLogs/123456789012/elasticloadbalancing/ap-northeast-1/2017/12/24/'
これらを毎日実行するようなLambdaなどを作成して運用することになります。
BIツールを利用する
Athenaを実行するだけだと生データが手に入るだけなので、必要に応じてグラフにしたりといったことが必要になるかと思います。
ExcelやGoogle SpreadSheetでも良いですが、BI(Business Intelligence)ツールと呼ばれるものを使って定期的なクエリ実行やその可視化、通知などを実現できます。
Athenaに対応しているものではAWSのサービスの一つであるQuickSightやRedashがあります。
列指向フォーマットについて
データ量が増大してくると、クエリの実行時間が増えると同時にお金もかかるようになってきます。そんな時に利用を検討したいのが列指向フォーマットです。
列指向フォーマットでは列単位でデータを取り出せるため、JOINやWHEREを行う際にすべてのデータを取り出す必要がありません。そのため、高速にかつ低料金でクエリを実行できます。
通常のログは行単位で出力されているため、あらかじめ変換処理を行う必要があります。これにはEMRを利用する方法がAWSで解説されているので、大量データに対して頻繁にクエリを行う際は利用を検討してみてください。
アプリケーションのログを分析する(CloudWatch Logsの場合)
ここまではELBのログでここまでできる的な内容でしたが、実際にはアプリケーションが出力したログを利用したくなります。とにかくS3に集めれば良いのでFluentdなどで集めればOKです。
ただ最近はECSやElastic Beanstalkを使っているとCloudWatch Logsに集約しているケースも増えてきているのではないかと思います。この場合S3に持っていくのが微妙に手間になってきます。CloudWatch LogsではS3にログをエクスポートできますが、通常では特定のログをフィルタをして出力したいと思うので、少し工夫が必要になります。
例えば下記のような構成です。
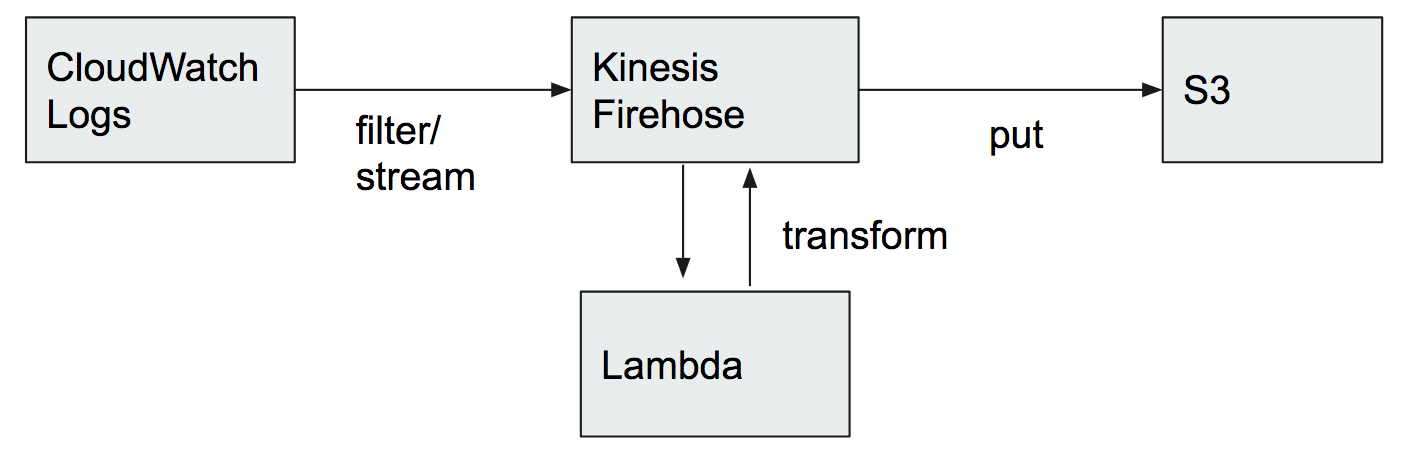
こちらについては https://aws.amazon.com/jp/blogs/news/analyzing-vpc-flow-logs-with-amazon-kinesis-firehose-amazon-athena-and-amazon-quicksight/ この記事などが参考になります。
おわりに
Amazon Athenaの使い方について自分の持っている知識をまとめてみました。Athenaの利用までの簡単さはログ分析の導入としては非常にハードルが低く、とても有用だと思っています。
他の分析サービスとどう違うのかとかは難しいところですが、AthenaはManagedなPrestoであってそれ以上ではなく、EMRやRedshiftの方が上位互換的に機能が多いので、Athenaで出来ないことが出てきたら他を使うとかでも良いのかなぁと思っています。(ここは詳しい人に教えて貰いたいところ。。)
S3 Selectという機能も出てきてS3ログの分析が更に柔軟になっていく予感もありますのでその導入としてのAmazon Athenaを触ってみてはいかがでしょうか。
注意事項
- ELBログについて
- ベストエフォート型のため、全てのログの取得は保証されていません
- ELBのログはUTCで保存するのでJSTの日付とはパーティションがずれます
- ログは15分ごとにまとめられるので 23:45〜23:59 頃のログは翌日のパーティションに入ってしまいます
参考資料
- AWS Black Belt Online Seminar「Amazon Athena」の資料およびQA公開
- Amazon Athena のパフォーマンスチューニング Tips トップ 10
- ビッグデータ処理データベースの全体像と使い分け
- 現場で運用する視点から見た Amazon Athena