わざわざベンチマークをやったのを公開してる方もいるので、
フレームワークのバージョンなど少し古い
convnet-benchmarks
https://github.com/soumith/convnet-benchmarks
>すべてのパブリックオープンソースのコンビネーション実装の簡単なベンチマーク。 要約は以下のセクションで提供されています。
マシーン:6-core Intel Core i7-5930K CPU @ 3.50GHz + NVIDIA Titan X + Ubuntu 14.04 x86_64
Imagenet受賞者のベンチマーキング
私はいくつかの人気のイメージネットモデルを選び、完全なフォワード+バックワードパスの時間を計る。私は10回以上の時間を平均しています。私はドロップアウトとソフトマックスの層を無視しました。
記法
入力は{batch_size} x {num_filters} x {filter_width} x {filter_height}と記述されます。 ここで、batch_sizeはミニバッチで使用される画像の数、num_filtersは画像内のチャンネル数、filter_widthは画像の幅、filter_heightは画像の高さです。
メモ
CuDNNベンチマークは、Torchバインディングを使用して実行されます。 Caffeバインディングや他のライブラリのバインディングを使っても同じことができます。 このメモは、Caffe(ネイティブ)とTorch(ネイティブ)が既定のフォールバックとして存在するコンボリューションカーネルであることを明確にするためのものです。 TensorFlowやChainerのようなフレームワークのいくつかはCuDNNでベンチマークされていますが、明示的に言及されていないため、これらのフレームワーク全体がより高速であると考えるかもしれません。
AlexNet (One Weird Trick paper) - Input 128x3x224x224
| Library | Class | Time (ms) | forward (ms) | backward (ms) |
|---|---|---|---|---|
| CuDNN[R4]-fp16 (Torch) | cudnn.SpatialConvolution | 71 | 25 | 46 |
| Nervana-neon-fp16 | ConvLayer | 78 | 25 | 52 |
| CuDNN[R4]-fp32 (Torch) | cudnn.SpatialConvolution | 81 | 27 | 53 |
| TensorFlow | conv2d | 81 | 26 | 55 |
| Nervana-neon-fp32 | ConvLayer | 87 | 28 | 58 |
| fbfft (Torch) | fbnn.SpatialConvolution | 104 | 31 | 72 |
| Chainer | Convolution2D | 177 | 40 | 136 |
| cudaconvnet2* | ConvLayer | 177 | 42 | 135 |
| CuDNN[R2] * | cudnn.SpatialConvolution | 231 | 70 | 161 |
| Caffe (native) | ConvolutionLayer | 324 | 121 | 203 |
| Torch-7 (native) | SpatialConvolutionMM | 342 | 132 | 210 |
| CL-nn (Torch) | SpatialConvolutionMM | 963 | 388 | 574 |
| Caffe-CLGreenTea | ConvolutionLayer | 1442 | 210 | 1232 |
Overfeat [fast] - Input 128x3x231x231
| Library | Class | Time (ms) | forward (ms) | backward (ms) |
|---|---|---|---|---|
| Nervana-neon-fp16 | ConvLayer | 176 | 58 | 118 |
| Nervana-neon-fp32 | ConvLayer | 211 | 69 | 141 |
| CuDNN[R4]-fp16 (Torch) | cudnn.SpatialConvolution | 242 | 86 | 156 |
| CuDNN[R4]-fp32 (Torch) | cudnn.SpatialConvolution | 268 | 94 | 174 |
| TensorFlow | conv2d | 279 | 90 | 189 |
| fbfft (Torch) | SpatialConvolutionCuFFT | 342 | 114 | 227 |
| Chainer | Convolution2D | 620 | 135 | 484 |
| cudaconvnet2* | ConvLayer | 723 | 176 | 547 |
| CuDNN[R2] * | cudnn.SpatialConvolution | 810 | 234 | 576 |
| Caffe | ConvolutionLayer | 823 | 355 | 468 |
| Torch-7 (native) | SpatialConvolutionMM | 878 | 379 | 499 |
| CL-nn (Torch) | SpatialConvolutionMM | 963 | 388 | 574 |
| Caffe-CLGreenTea | ConvolutionLayer | 2857 | 616 | 2240 |
OxfordNet [Model-A] - Input 64x3x224x224
| Library | Class | Time (ms) | forward (ms) | backward (ms) |
|---|---|---|---|---|
| Nervana-neon-fp16 | ConvLayer | 254 | 82 | 171 |
| Nervana-neon-fp32 | ConvLayer | 320 | 103 | 217 |
| CuDNN[R4]-fp16 (Torch) | cudnn.SpatialConvolution | 471 | 140 | 331 |
| CuDNN[R4]-fp32 (Torch) | cudnn.SpatialConvolution | 529 | 162 | 366 |
| TensorFlow | conv2d | 540 | 158 | 382 |
| Chainer | Convolution2D | 885 | 251 | 632 |
| fbfft (Torch) | SpatialConvolutionCuFFT | 1092 | 355 | 737 |
| cudaconvnet2* | ConvLayer | 1229 | 408 | 821 |
| CuDNN[R2] * | cudnn.SpatialConvolution | 1099 | 342 | 757 |
| Caffe | ConvolutionLayer | 1068 | 323 | 745 |
| Torch-7 (native) | SpatialConvolutionMM | 1105 | 350 | 755 |
| CL-nn (Torch) | SpatialConvolutionMM | 3437 | 875 | 2562 |
| Caffe-CLGreenTea | ConvolutionLayer | 5620 | 988 | 4632 |
GoogleNet V1 - Input 128x3x224x224
| Library | Class | Time (ms) | forward (ms) | backward (ms) |
|---|---|---|---|---|
| Nervana-neon-fp16 | ConvLayer | 230 | 72 | 157 |
| Nervana-neon-fp32 | ConvLayer | 270 | 84 | 186 |
| TensorFlow | conv2d | 445 | 135 | 310 |
| CuDNN[R4]-fp16 (Torch) | cudnn.SpatialConvolution | 462 | 112 | 349 |
| CuDNN[R4]-fp32 (Torch) | cudnn.SpatialConvolution | 470 | 130 | 340 |
| Chainer | Convolution2D | 687 | 189 | 497 |
| Caffe | ConvolutionLayer | 1935 | 786 | 1148 |
| CL-nn (Torch) | SpatialConvolutionMM | 7016 | 3027 | 3988 |
| Caffe-CLGreenTea | ConvolutionLayer | 9462 | 746 | 8716 |
レイヤーごとベンチマーク (Last Updated April 2015)
Spatial Convolution layer (3D input 3D output, densely connected)
forward + backprop (wrt input and weights)
| Original Library | Class/Function Benchmarked | Time (ms) | forward (ms) | backward (ms) |
|---|---|---|---|---|
| fbfft | SpatialConvolutionCuFFT | 256 | 101 | 155 |
| cuda-convnet2 * | ConvLayer | 977 | 201 | 776 |
| cuda-convnet** | pylearn2.cuda_convnet | 1077 | 312 | 765 |
| CuDNN R2 * | cudnn.SpatialConvolution | 1019 | 269 | 750 |
| Theano | CorrMM | 1225 | 407 | 818 |
| Caffe | ConvolutionLayer | 1231 | 396 | 835 |
| Torch-7 | SpatialConvolutionMM | 1265 | 418 | 877 |
| DeepCL | ConvolutionLayer | 6280 | 2648 | 3632 |
| cherry-picking**** | best per layer | 235 | 79 | 155 |
This table is NOT UPDATED For TITAN-X. These numbers below were on Titan Black and are here only for informational and legacy purposes.
| Original Library | Class/Function Benchmarked | Time (ms) | forward (ms) | backward (ms) |
|---|---|---|---|---|
| Theano (experimental)*** | conv2d_fft | 1178 | 304 | 874 |
| Torch-7 | nn.SpatialConvolutionBHWD | 1892 | 581 | 1311 |
| ccv | ccv_convnet_layer | 809+bw | 809 | |
| Theano (legacy) | conv2d | 70774 | 3833 | 66941 |
- * indicates that the library was tested with Torch bindings of the specific kernels.
- ** indicates that the library was tested with Pylearn2 bindings.
- *** This is an experimental module which used FFT to calculate convolutions. It uses a lot of memory according to @benanne
- **** The last row shows results obtainable when choosing the best-performing library for each layer.
- L1 - Input:
128x128Batch-size128, Feature maps:3->96, Kernel Size:11x11, Stride:1x1 - L2 - Input:
64x64Batch-size128, Feature maps:64->128, Kernel Size:9x9, Stride:1x1 - L3 - Input:
32x32Batch-size128, Feature maps:128->128, Kernel Size:9x9, Stride:1x1 - L4 - Input:
16x16Batch-size128, Feature maps:128->128, Kernel Size:7x7, Stride:1x1 - L5 - Input:
13x13Batch-size128, Feature maps:384->384, Kernel Size:3x3, Stride:1x1 - The table is ranked according to the total time forward+backward calls for layers (L1 + L2 + L3 + L4 + L5)
Breakdown
forward
Columns L1, L2, L3, L4, L5, Total are times in milliseconds
| Original Library | Class/Function Benchmarked | L1 | L2 | L3 | L4 | L5 | Total |
|---|---|---|---|---|---|---|---|
| fbfft | SpatialConvolutionCuFFT | 57 | 27 | 6 | 2 | 9 | 101 |
| cuda-convnet2 * | ConvLayer | 36 | 113 | 40 | 4 | 8 | 201 |
| cuda-convnet** | pylearn2.cuda_convnet | 38 | 183 | 68 | 7 | 16 | 312 |
| CuDNN R2 | cudnn.SpatialConvolution | 56 | 143 | 53 | 6 | 11 | 269 |
| Theano | CorrMM | 91 | 143 | 121 | 24 | 28 | 407 |
| Caffe | ConvolutionLayer<Dtype> | 93 | 136 | 116 | 24 | 27 | 396 |
| Torch-7 | nn.SpatialConvolutionMM | 94 | 149 | 123 | 24 | 28 | 418 |
| DeepCL | ConvolutionLayer | 738 | 1241 | 518 | 47 | 104 | 2648 |
| cherry-picking**** | best per layer | 36 | 27 | 6 | 2 | 8 | 79 |
backward (gradInput + gradWeight)
Columns L1, L2, L3, L4, L5, Total are times in milliseconds
| Original Library | Class/Function Benchmarked | L1 | L2 | L3 | L4 | L5 | Total |
|---|---|---|---|---|---|---|---|
| fbfft | SpatialConvolutionCuFFT | 76 | 45 | 12 | 4 | 18 | 155 |
| cuda-convnet2 * | ConvLayer | 103 | 467 | 162 | 15 | 29 | 776 |
| cuda-convnet** | pylearn2.cuda_convnet | 136 | 433 | 147 | 15 | 34 | 765 |
| CuDNN R2 | cudnn.SpatialConvolution | 139 | 401 | 159 | 19 | 32 | 750 |
| Theano | CorrMM | 179 | 405 | 174 | 29 | 31 | 818 |
| Caffe | ConvolutionLayer<Dtype> | 200 | 405 | 172 | 28 | 30 | 835 |
| Torch-7 | nn.SpatialConvolutionMM | 206 | 432 | 178 | 29 | 32 | 877 |
| DeepCL | ConvolutionLayer | 484 | 2144 | 747 | 59 | 198 | 3632 |
| cherry-picking**** | best per layer | 76 | 45 | 12 | 4 | 18 | 155 |
2017年2月15日
http://www.svds.com/getting-started-deep-learning/
必要に応じてフレームワークを選べという話。
SVDSでは、私たちのR&Dチームは、学習の画像認識から音声認識まで、さまざまな深層学習技術を調査してきました。 データの取り込み、モデルの作成、モデルのパフォーマンス評価を行うためのパイプラインを構築する必要がありました。 しかし、どの技術が利用可能であるかを調査したところ、新しい深層学習プロジェクトを開始するための簡潔な要約文書は見つかりませんでした。
私たちにツールを提供するオープンソースコミュニティに還元する1つの方法は、他の人が私たちの経験を活用する方法でそれらのツールを評価して選ぶのを助けることです。 私たちは、私たちの決定に基づいたさまざまな基準の説明とともに、以下のチャートを提供します。
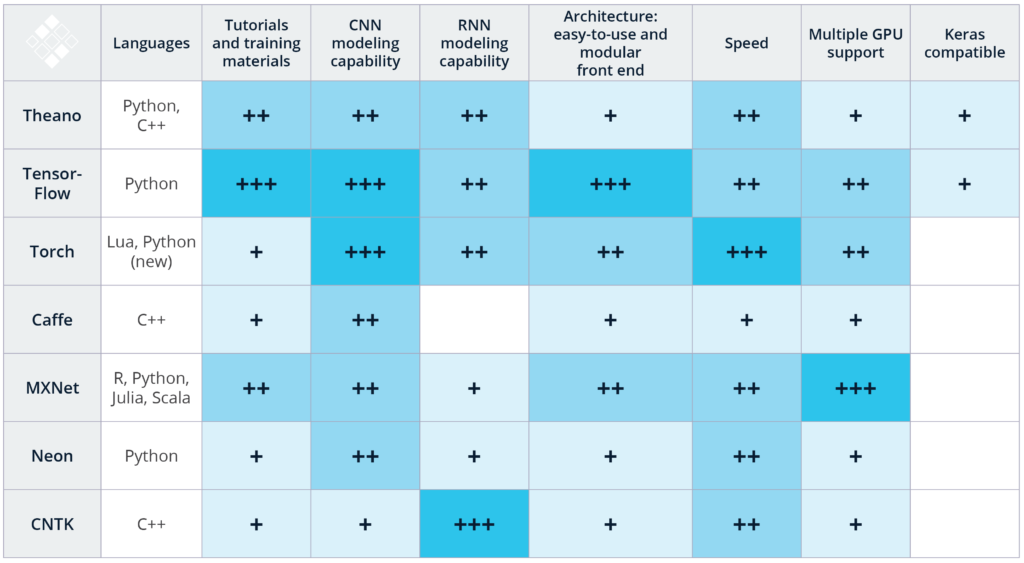
これらのランキングは、これらのテクノロジのイメージ認識アプリケーションと音声認識アプリケーションの主観的な経験と、公開されているベンチマーク調査の組み合わせです。 以下に得点を説明します:
言語:深層学習を始めるときは、よく知っている言語をサポートするフレームワークを使用することをお勧めします。 たとえば、Caffe(C ++)とTorch(Lua)はコードベース用のPythonバインディングを持っています(PyTorchは2017年1月にリリースされています)。しかし、これらの技術を使用するには、それぞれC ++またはLuaに熟達していることをお勧めします。 これと比較して、TensorFlowとMXNetは多言語サポートを提供しており、C ++に習熟していなくてもこの技術を利用することができます。
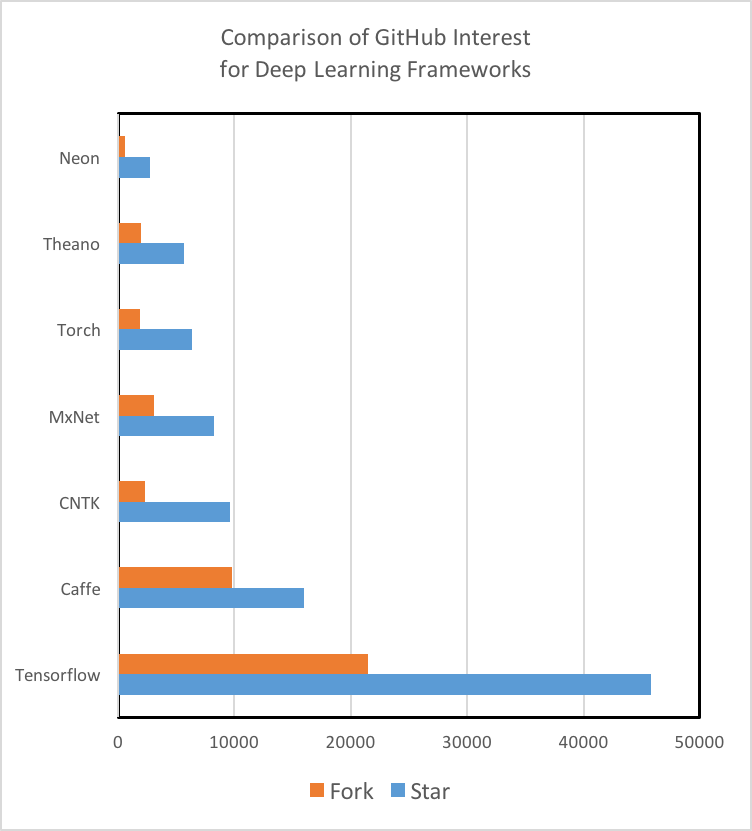
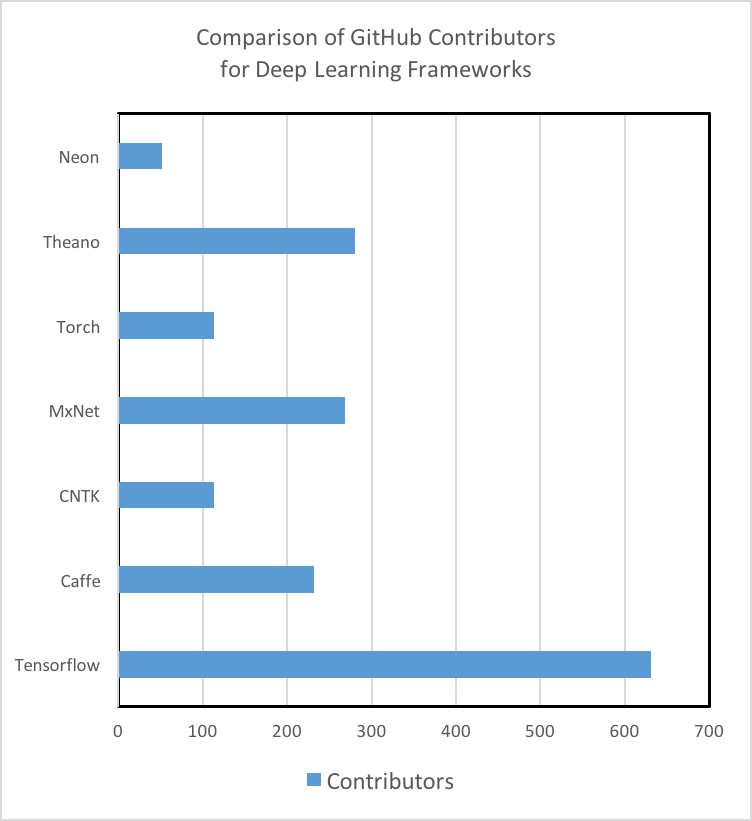
チュートリアルとトレーニング教材:チュートリアルの質と量、および入門用資料を徹底的に変える深層学習技術。 Theano、TensorFlow、Torch、およびMXNetには、理解しやすく実装するためのチュートリアルが十分に文書化されています。 MicrosoftのCNTKとIntelのNervana Neonは強力なツールですが、私たちは初心者向けの資料を探すのに苦労しました。 さらに、GitHubコミュニティの関与は、ツールの将来の開発だけでなく、StackOverflowやリポジトリのGit Issuesを検索することで、問題やバグをどの程度解決できるかを示す指標となります。 TensorFlowは、チュートリアルの量、トレーニング資料、および開発者とユーザーのコミュニティに関する800ポンドのゴリラであることに注意することが重要です。
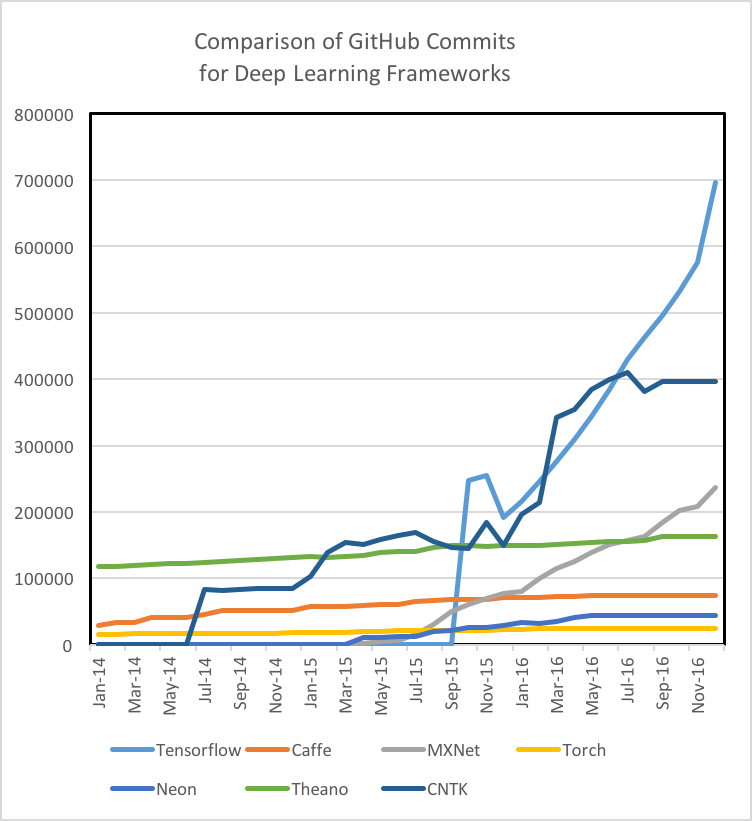
CNNモデリング能力:畳み込みニューラルネットワーク(CNN)は、画像認識、推薦エンジン、および自然言語処理に使用される。 CNNは、初期データ量を所定のクラススコアの出力スコアに変換する一連の異なるレイヤーで構成されています(詳細は、Eugenio Culurcielloのニューラルネットワークアーキテクチャの概要を参照してください)。 CNNは、自律車両のステアリング角度を出力するモデルなどの回帰分析にも使用できます。テクノロジーのCNNモデリング機能にいくつかの機能が含まれていると考えています。これらの機能には、モデルを定義するための機会スペース、事前作成されたレイヤーの可用性、これらのレイヤーを接続するためのツールと関数が含まれます。 Theano、Caffe、MXNetのCNNモデリング能力は素晴らしいです。つまり、TensorFlowのInceptionV3モデルとTorchの優れたCNNリソース(使いやすい時間的畳み込みを含む)は、CNNモデリング機能のためにこれらの2つの技術を別々にしています。
RNNモデリング能力:音声認識、時系列予測、画像キャプション、および逐次情報の処理を必要とする他のタスクにはリカレントニューラルネットワーク(RNN)が使用されます。あらかじめ構築されたRNNモデルはCNNほどの数ではありませんので、RNNディープ学習プロジェクトをお持ちであれば、RNNモデルが以前に実装されており、特定のテクノロジでオープンソースとなっているものを検討することが重要です。たとえば、CaffeにはRNNのリソースがほとんどなく、MicrosoftのCNTKとTorchには十分なRNNチュートリアルと事前構築されたモデルがあります。 vanilla TensorFlowにはRNNの素材がいくつかありますが、TFLearnとKerasにはTensorFlowを活用したRNNのサンプルが数多く含まれています。
アーキテクチャ:特定のフレームワークで新しいモデルを作成し、訓練するには、使いやすくモジュール式のフロントエンドを持つことが重要です。 TensorFlow、Torch、およびMXNetは、開発を容易にする簡単でモジュラーなアーキテクチャを備えています。これとは対照的に、Caffeなどのフレームワークでは、新しいレイヤーを作成するために多大な労力が必要です。特にTensorFlowは、TensorBoardのWeb GUIアプリケーションが含まれているため、トレーニング中およびトレーニング後にデバッグと監視が容易であることがわかりました。
スピード:TorchとNervanaは、オープンソースの畳み込みニューラルネットワークベンチマークテストで最も優れたパフォーマンスを示しています。ほとんどのテストでTensorFlowのパフォーマンスは同等でしたが、CaffeとTheanoは遅れていました。マイクロソフトのCNTKは、RNNの最速のトレーニング時間が最も短いと主張しています。 Theano、Torch、TensorFlowをRNNと直接比較した別の調査では、Theanoが3つの中で最高のパフォーマンスを発揮することが示されました。
複数のGPUサポート:ほとんどのディープラーニングアプリケーションでは、顕著な数の浮動小数点演算(FLOP)が必要です。たとえば、BaiduのDeepSpeech認識モデルでは、10秒間のExaFLOPを訓練します。それは> 10e18計算です! NVIDIAのPascal TitanXなどの主要なグラフィックスプロセッシングユニット(GPU)は11秒9のFLOPを1秒間に実行できるため、十分に大きなデータセットで新しいモデルを訓練するには1週間以上かかります。モデルを構築するのにかかる時間を短縮するために、複数のマシンにまたがる複数のGPUが必要です。幸いにも、上記の技術のほとんどがこのサポートを提供しています。特に、MXNetには、最も最適化されたマルチGPUエンジンが搭載されていると報告されています。
Keras互換性:Kerasは、迅速な学習プロトタイプ作成を行うための高レベルライブラリです。われわれは、データ・サイエンティストを深層学習に慣れさせるための素晴らしいツールであることを発見しました。 Kerasは現在、2つのバックエンド、TensorFlowとTheanoをサポートしており、今後TensorFlowの正式サポートを受ける予定です。 Kerasは、複数のバックエンドで使用できるフロントエンドとしてKerasが引き続き存在することを著者が最近明示したことを考えれば、高水準ライブラリにとっては良い選択です。
深層学習を開始することに興味がある場合は、自分のチームのスキルを評価し、最初にプロジェクトのニーズを評価することをおすすめします。たとえば、Python中心のチームによる画像認識アプリケーションでは、豊富なドキュメント、適切なパフォーマンス、優れたプロトタイピングツールを備えたTensorFlowをお勧めします。ルアの有能なクライアントチームと連携してRNNをプロダクションに拡張するには、優れた速度とRNNモデリング機能をトーチにお勧めします。
将来、私たちのモデルをスケールアップする際の課題をいくつか議論します。これらの課題には、複数のマシンでのGPU使用の最適化と、深層学習パイプラインのためのCMU SphinxやKaldiなどのオープンソースライブラリの適応が含まれます。